[Перевод] Эксплойтинг браузера Chrome, часть 2: знакомство с Ignition, Sparkplug и компиляцией JIT в TurboFan
В моём предыдущем посте мы впервые погрузились в мир эксплойтинга браузеров, рассмотрев несколько сложных тем, которые были необходимы для освоения фундаментальных знаний. В основном мы изучили внутреннюю работу JavaScript и V8, разобравшись, что такое объекты map и shape, как эти объекты структурированы в памяти; мы рассмотрели базовые оптимизации памяти наподобие маркировки указателей и сжатия указателей. Также мы затронули тему конвейера компилятора, интерпретатора байт-кода и оптимизации кода.
Если вы ещё не прочитали тот пост, то крайне рекомендую это сделать. В противном случае вы можете запутаться и совершенно не разберётесь в некоторых из тем, представленных в этом посте, поскольку мы продолжаем изучение на основе знаний из первой части, расширяя их.
В сегодняшнем посте мы вернёмся к конвейеру компилятора и ещё глубже разберём некоторые из рассмотренных ранее концепций: байт-код V8, компиляцию кода и оптимизацию кода. В целом, мы рассмотрим происходящее внутри Ignition, Sparkplug и TurboFan, поскольку они критически важны для понимания того, как определённые «фичи» могут привести к появлению багов, которые можно эксплойтить.
Мы обсудим следующие темы:
- Модель безопасности Chrome
- Многопроцессная архитектура «песочницы»
- Isolate and Context движка V8
- Интерпретатор Ignition
- Разбираемся с байт-кодом V8
- Разбираемся с регистровой машиной
- Sparkplug
- 1:1 Mapping
- TurboFan
- Компиляция Just-In-Time (JIT)
- Спекулятивная оптимизация и предохранители типов
- Feedback Lattice
- Промежуточное представление «море узлов»
- Стандартные оптимизации
- Typer
- Анализ диапазонов
- Bounds Checking Elimination (BCE)
- Устранение избыточности
- Другие оптимизации
- Оптимизация контроля
- Анализ псевдонимов и глобальное перечисление значений
- Dead Code Elimination (DCE)
- Распространённые уязвимости компилятора JIT
Итак, прочитав этот длинный и страшный список сложных тем, давайте глубоко вдохнём и приступим!
Примечание: многие подсвеченные пути кода являются ссылками. При нажатии на эти ссылки вы попадёте в соответствующую часть исходного кода Chromium, чтобы изучить его внимательнее.Кроме того, уделите время чтению комментариев к коду. Исходный код Chromium, несмотря на свою сложность, содержит довольно неплохие комментарии, которые помогут вам в понимании того, что это за часть кода и что она делает.
Прежде чем мы погрузимся в разбор сложностей конвейера компилятора, процесса выполнения оптимизаций и мест возможного возникновения багов, сначала нам нужно сделать шаг назад и рассмотреть картину в целом. Хотя конвейер компилятора играет важную роль в выполнении JavaScript, это лишь одна часть головоломки всей архитектуры браузеров.
Как мы видели, V8 может работать как автономное приложение, но в целом в браузере V8 на самом деле встроен в Chrome и используется другим движком при помощи привязок. Из-за этого нам нужно разобраться в нюансах обработки кода на JavaScript в приложении, так как эта информация критически важна для понимания проблем безопасности внутри браузера.
Чтобы мы могли увидеть эту «картину в целом» и собрать воедино все кусочки пазла, нам нужно начать с понимания модели безопасности Chrome. Ведь в конечном итоге эта серия постов посвящена внутренностям браузера и его эксплойтингу. Поэтому чтобы лучше понять, почему одни баги тривиальнее других, и почему эксплойт всего лишь одного бага может не привести к прямому удалённому исполнению кода, нам нужно понять архитектуру Chromium.
Как мы знаем, движки JavaScript — неотъемлемая часть исполнения JavaScript-кода в системах. Хотя они играют очень важную роль в обеспечении скорости и эффективности браузеров, также они могут открывать возможности для вылетов браузера, зависания приложений и даже угроз безопасности. Однако движки JavaScript — это не единственная часть браузера, которая может иметь проблемы или уязвимости. Множество других компонентов, например, API, движки рендеринга HTML и CSS, тоже могут иметь проблемы со стабильностью и уязвимости, которые потенциально можно подвергнуть эксплойтингу, случайно или намеренно.
Практически невозможно создать движок JavaScript или рендеринга, который никогда не вылетает. Также практически невозможно создавать подобные движки так, чтобы они были полностью безопасны и защищены от багов и уязвимостей, особенно потому, что большинство этих компонентов программируется на языке C++ со статической типизацией, которому приходится работать с динамической природой веб-приложений.
Как же Chrome справляется с этой «невозможной» задачей эффективной работы браузера, параллельно обеспечивая безопасность самого браузера, системы и её пользователей? Двумя способами: при помощи многопроцессной архитектуры и «песочницы».
Многопроцессная архитектура «песочницы»
Многопроцессная архитектура Chromium — это архитектура, использующая множество процессов для защиты браузера от проблем нестабильности и багов, которые могут возникать из-за движка JavaScript, движка рендеринга или других компонентов. Chromium также ограничивает доступ между этими процессами, позволяя общаться друг с другом только отдельным процессам. Такой тип архитектуры можно рассматривать как внедрение в приложение защиты памяти и управления доступом.
В целом, браузеры имеют один основной процесс, выполняющий UI и управляющий всеми остальными процессами. Он называется browser process или browser для краткости. Процессы, занимающиеся веб-контентом, называются renderer process или renderer. Эти процессы рендеринга используют Blink — опенсорсный движок рендеринга Chrome. Blink реализует множество других библиотек, помогающих ему работать, например, Skia — опенсорсную библиотеку 2D-графики и, разумеется, V8 для JavaScript.
И тут всё становится немного сложнее. В Chrome каждое новое окно или вкладка открываются в новом процессе, который обычно бывает новым процессом рендеринга. Этот новый процесс рендеринга имеет глобальный объект RenderProcess, управляющий общением с родительским процессом браузера и хранящий глобальное состояние веб-страницы или приложения в этом окне или вкладке. В свою очередь, основной процесс браузера хранит соответствующий объект RenderProcessHost для каждого рендерера, управляющий состоянием браузера и общением с рендерером.
Чтобы выполнять общение между этими процессами, Chromium использует или легаси-систему IPC, или Mojo. Я не буду вдаваться в подробности их работы, потому что, откровенно говоря, архитектура и схема обмена данными в Chrome сами по себе могут стать темой для отдельного поста. Читатель может пройти по ссылкам и провести собственное исследование.
Чтобы нагляднее представить то, о чём мы только что говорили, команда разработчиков Chromium создала показанную ниже схему с высокоуровневым описанием многопроцессной архитектуры.

Кроме того, что каждый из этих рендереров находится в собственном процессе, Chrome также пользуется возможностью ограничения доступа процессов к системным ресурсам при помощи «песочниц». Создавая «песочницу» для каждого из процессов, Chrome может гарантировать, что доступ рендереров к сетевым ресурсам будет осуществляться только через диспетчер сетевых сервисов, выполняемый в основном процессе. Кроме того, он может ограничивать доступ процессов к файловой системе, а также к дисплею, кукам и вводу пользователя.
В целом, это ограничивает возможности атакующего при получении возможности удалённого исполнения кода в процессе рендерера. По сути, без эксплойтинга или добавления в цепочку другого бага, или выхода из «песочницы» он не сможет вносить сохраняющиесяся в компьютере изменения или получить доступ к информации из других окон и вкладок, например, к вводу пользователя и кукам.
Здесь я не буду вдаваться в подробности, поскольку это отвлечёт нас от темы поста. Однако я крайне рекомендую подробно прочитать документацию Chromium Windows Sandbox Architecture, чтобы не только понимать принципы архитектуры, но и лучше разобраться в схеме обмена данными брокера и целевого процесса.
Как же всё это выглядит на практике? Мы можем увидеть практический пример, зайдя в Chrome, открыв две вкладки и запустив Process Monitor. Изначально мы увидим, что Chrome имеет один родительский процесс (browser) и несколько дочерних, как показано на скриншоте.
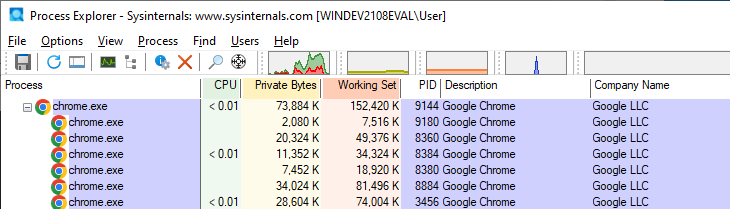
Если теперь мы посмотрим на основной родительский процесс и сравним его с дочерним, то заметим, что другие процессы выполняются с другими параметрами командной строки. В нашем примере мы видим, что дочерний процесс (справа) имеет тип renderer и соответствует родительскому процессу browser (слева). Здорово, правда?
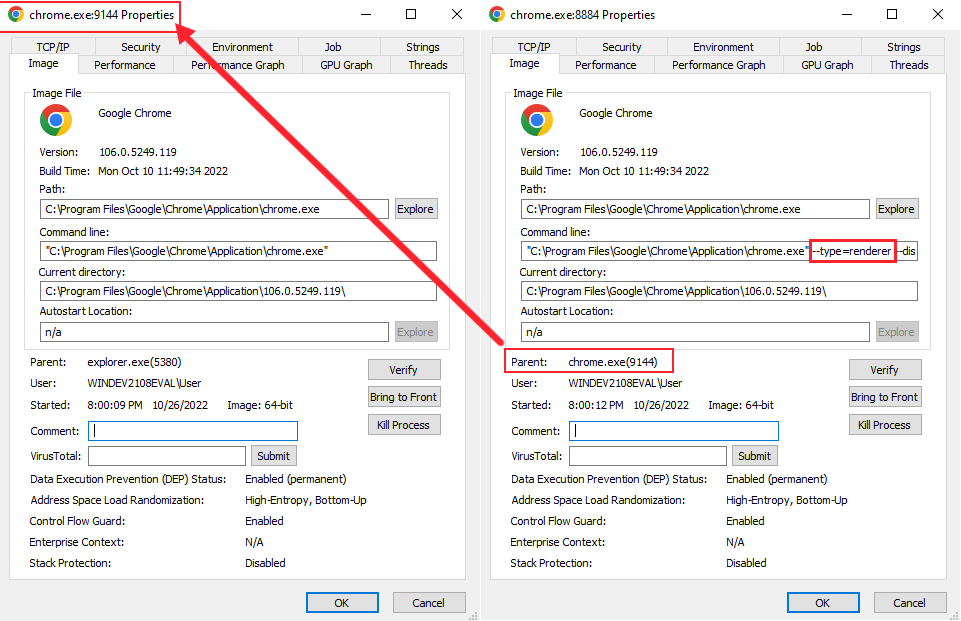
После этого объяснения вы можете задать вопрос: как всё это связано с V8 и JavaScript? Ну, если вы были внимательны, то могли заметить в описании движка рендерера Blink ключевой момент: он реализует V8.
Если вы, как хороший студент, уделили время чтению документации Blink, то немного о нём узнали. В документации говорится, что Blink выполняется в каждом процессе рендерера и имеет один основной поток, обрабатывающий JavaScript, DOM, CSS, вычисления стиля и расположения элементов. Кроме того, Blink может создавать множество потоков «воркеров» для выполнения дополнительных скриптов, расширений и так далее.
В общем случае каждый поток Blink выполняет собственный экземпляр V8. Почему? Ну, как вы знаете, в отдельном окне или вкладке может выполняться очень много кода JavaScript — не только для страницы, но и для различных iframe с рекламой, кнопками и так далее. В итоге, каждый из этих скриптов и iframe имеет отдельный контекст JavaScript, поэтому должен быть способ предотвратить манипуляции одного скрипта с объектами в другом.
Чтобы «изолировать» контекст одного скрипта от другого, V8 реализует концепцию под названием Isolate and Context, о которой мы сейчас и поговорим.
Isolate and Context движка V8
В V8 Isolate — это концепция экземпляра или «виртуальной машины», представляющей одну среду исполнения JavaScript. Она включает в себя диспетчер кучи, сборщик мусора и так далее. В Blink isolate и потоки имеют соотношение 1:1, где один isolate связан с основным потоком, а другой isolate связан с одним потоком воркера.
Context соответствует глобальному корневому объекту, который хранит состояние виртуальной машины и используется для компиляции и исполнения скриптов в одном экземпляре V8. Грубо говоря, один объект окна соответствует одному контексту. А поскольку каждый кадр имеет объект окна, в процессе рендерера потенциально может быть множество контекстов. Isolate и контексты на протяжении срока жизни isolate имеют соотношение 1: N, конкретный isolate или экземпляр интерпретирует и компилирует множество контекстов.
Это значит, что каждый раз, когда нужно исполнить JavaScript, мы должны убедиться, что находимся в соответствующем контексте при помощи GetCurrentContext (), иначе произойдёт или утечка объектов JavaScript, или их перезапись, что потенциально может вызвать проблему безопасности.
В Chrome объект среды выполнения v8::Isolate реализован в v8/include/v8-isolate.h, а объект v8::Context реализован в v8/include/v8-context.h. Воспользовавшись нашими знаниями, мы можем на высоком уровне визуализировать среду выполнения и наследование контекста в Chrome:
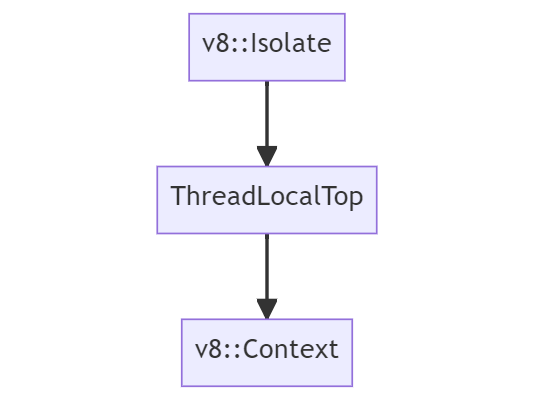
Если бы хотите узнать подробнее о работе Isolate and Context, то рекомендую прочитать Design of V8 Bindings и Getting Started with Embedding V8.
Теперь, получив общее понимание архитектуры Chromium, и осознавая, что весь код JavaScript не исполняется в одном экземпляре движка V8, мы наконец можем вернуться в конвейер компилятора и продолжить погружение в тему.
Мы начнём с разбора интерпретатора V8 под названием Ignition.
В качестве повтора первой части статьи давайте взглянем на высокоуровневую схему конвейера компиляции V8, чтобы знать, где именно мы находимся внутри этого конвейера.

В части первой мы уже рассказывали о токенах и абстрактных синтаксических деревьях (AST), а также вкратце рассмотрели то, как парсится AST с последующей трансляцией в байт-код внутри интерпретатора. Сейчас я хочу рассказать о байт-коде V8, так как генерируемый интерпретатором байт-код — критически важный строительный кирпичик, составляющий любую функциональность JavaScript. Кроме того, когда Ignition компилирует байт-код, он также собирает данные профилирования и обратной связи при каждом выполнении функции JavaScript. Эти данные обратной связи в дальнейшем используются TurboFan для генерации оптимизированного для JIT машинного кода.
Но прежде чем мы начнём разбираться, как структурирован байт-код, нам нужно понять, как Ignition реализует свою «регистровую машину». Каждый байт-код представляет свои вводы и выводы в виде операндов регистра, поэтому нам нужно знать, где эти вводы и выводы располагаются в стеке. Это поможет нам лучше визуализировать и понять кадры стека, которые создаются в V8.
Разбираемся с регистровой машиной
Как мы знаем, интерпретатор Ignition — это интерпретатор на основе регистров с регистром-аккумулятором. Эти «регистры» на самом деле не являются традиционными регистрами машины, как можно подумать. Это отдельные слоты в регистровом файле, распределяемом как часть кадра стека функции. По сути, они являются «виртуальными» регистрами. Как мы увидим ниже, байт-коды могут указывать эти регистры ввода и вывода, с которыми могут оперировать их аргументы.
Ignition состоит из набора обработчиков байт-кода, написанных высокоуровневым машинно-независимым ассемблерным кодом. Эти обработчики реализованы классом CodeStubAssembler и скомпилированы бэкендом TurboFan при компиляции браузера. В целом, каждый из этих обработчиков занимается конкретным байт-кодом, а затем передаёт управление обработчику следующего байт-кода.
Пример обработчика байт-кода LdaZero, или «Load Zero to Accumulator» («записать ноль в аккумулятор») из v8/src/interpreter/interpreter-generator.cc представлен ниже.
// LdaZero
// Запись литерального "0" в аккумулятор.
IGNITION_HANDLER(LdaZero, InterpreterAssembler)
{
TNode zero_value = NumberConstant(0.0);
SetAccumulator(zero_value);
Dispatch();
}
Когда V8 создаёт новый isolate, он загружает обработчики из файла снэпшота, созданного во время сборки. Isolate также содержит глобальную таблицу вызовов интерпретатора, содержащую указатель объекта кода на каждый обработчик байт-кода, индексированный по значению байт-кода. В общем случае эта таблица вызовов является простым enum.
Чтобы байт-код был выполнен Ignition, функция JavaScript сначала преобразуется в байт-код из AST BytecodeGenerator. Этот генератор обходит AST и создаёт соответствующий байт-код для каждого узла AST, вызывая функцию GenerateBytecode.
Этот байт-код затем ассоциируется с функций (которая является объектом JSFunction) в поле свойства, называемом объектом SharedFunctionInfo. Затем code_entry_point функций JavaScript присваивается встроенная заглушка InterpreterEntryTrampoline.
Вход в заглушку InterpreterEntryTrampoline выполняется при вызове функции JavaScript, она отвечает за подготовку соответствующего кадра стека интерпретатора, а также вызывает обработчик байт-кода интерпретатора для первого байт-кода функции. Затем при помощи интерпретатора Ignition он начинает исполнение или «интерпретацию» функции, происходящую в файле исходников v8/src/builtins/x64/builtins-x64.cc.
В частности, в строках 1255–1387 файла builtins-x64.cc функции Builtins::Generate_InterpreterPushArgsThenCallImpl и Builtins::Generate_InterpreterPushArgsThenConstructImpl отвечают за дальнейшее построение кадра стека интерпретатора, передавая аргументы и состояние функции в стек.
Я не буду особо вдаваться в генератор байт-кода, однако если вы хотите расширить свои знания, то рекомендую прочитать раздел Ignition Design Documentation: Bytecode Generation, дающий лучшее представление о том, как это работает изнутри. В этом разделе я хочу подробнее рассказать о распределении регистров и создании кадра стека для функции.
Как же генерируется этот кадр стека?
При генерации байт-кода BytecodeGenerator также распределяет регистры в регистровом файле функции для локальных переменных, указателей объектов контекста и временных значений, необходимых для вычисления выражений.
Заглушка InterpreterEntryTrampoline обрабатывает изначальное создание кадра стека, а затем распределяет пространство в кадре стека для регистрового файла. Эта заглушка также записывает undefined во все регистры этого регистрового файла, чтобы сборщик мусора (Garbage Collector, GC) не видел никаких невалидных (то есть немаркированных) указателей при обходе стека.
Байт-код работает с этими регистрами, указывая это в своих операндах, после чего Ignition загружает или сохраняет данные из конкретного слота стека, связанного с регистром. Так как индексы регистров напрямую отображаются на слоты кадра стека функции, Ignition может непосредственно получать доступ к другим слотам в стеке, например, к контексту и аргументам, переданным вместе с функцией.
Пример того, как выглядит кадр стека для функции, показан ниже (изображение создано командой Chromium). Обратите внимание на «Interpreter Stack Frame». Это стек кадра, созданный заглушкой InterpreterEntryTrampoline.
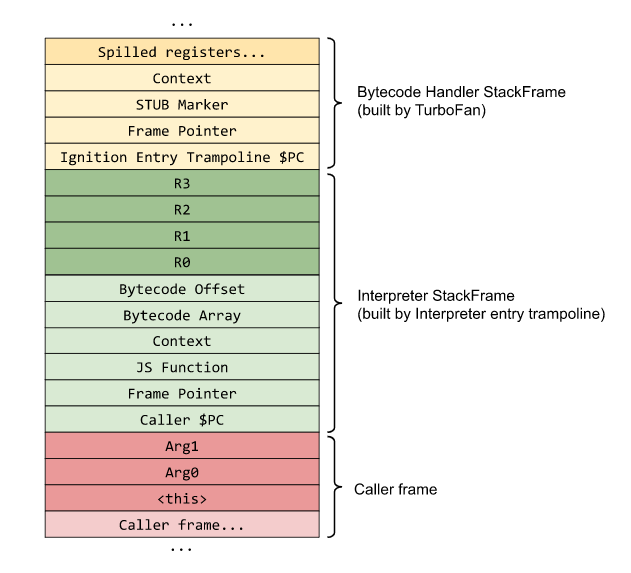
Как видите, все аргументы функции отмечены красным, а локальные переменные и временные переменные для вычисления выражений — зелёным.
Светло-зелёная часть содержит текущий объект контекста Isolates, счётчик указателей вызывающего оператора и указатель на объект JSFunction. Этот указатель на JSFunction также известен как замыкание, ссылающееся на контекст функций, объект SharedFunctionInfo, а также на другие методы доступа наподобие FeedbackVector. Ниже показан пример того, как этот JSFunction выглядит в памяти.
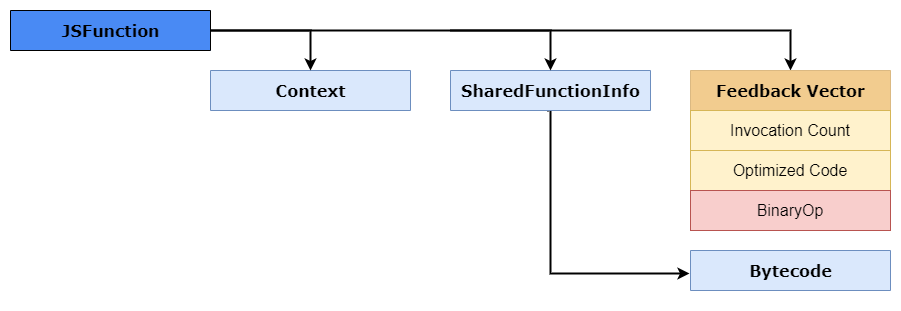
Также можно заметить, что в кадре стека отсутствует регистр накопителя. Так получилось, потому что регистр аккумулятора при вызовах функций постоянно изменяется, в этом случае он хранится в интерпретаторе как регистр состояния. На этот регистр состояния указывает Frame Pointer (FP), который также хранит указатель стека и счётчик кадра.
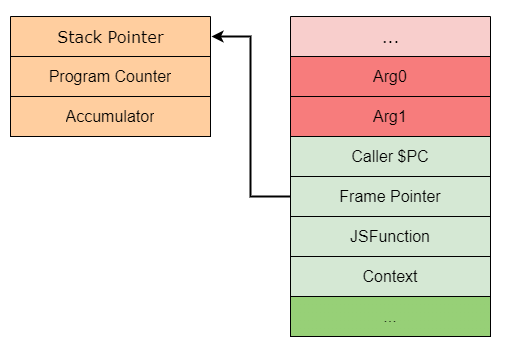
Вернувшись к первому примеру кадра стека, вы также заметите, что там есть указатель на Bytecode Array. Этот BytecodeArray представляет собой последовательность байт-кодов интерпретатора для конкретной функции в кадре стека. Изначально каждый байт-код является enum, где индекс байт-кода хранит соответствующий обработчик (как и говорилось ранее).
Пример этого BytecodeArray показан в v8/src/objects/code.h, а фрагмент этого кода представлен ниже.
// BytecodeArray представляет собой последовательность байт-кодов интерпретатора.
class BytecodeArray
: public TorqueGeneratedBytecodeArray {
public:
static constexpr int SizeFor(int length) {
return OBJECT_POINTER_ALIGN(kHeaderSize + length);
}
inline byte get(int index) const;
inline void set(int index, byte value);
inline Address GetFirstBytecodeAddress();
inline int32_t frame_size() const;
inline void set_frame_size(int32_t frame_size);
Как видите, функция GetFirstBytecodeAddress() отвечает за получение первого адреса байт-кода в массиве. Как она находит этот адрес?
Давайте вкратце рассмотрим байт-код, сгенерированный для var num = 42.
d8> var num = 42;
[generated bytecode for function: (0x03650025a599 )]
Bytecode length: 18
Parameter count 1
Register count 3
Frame size 24
Bytecode age: 0
000003650025A61E @ 0 : 13 00 LdaConstant [0]
000003650025A620 @ 2 : c4 Star1
000003650025A621 @ 3 : 19 fe f8 Mov , r2
000003650025A624 @ 6 : 66 5f 01 f9 02 CallRuntime [DeclareGlobals], r1-r2
000003650025A629 @ 11 : 0d 2a LdaSmi [42]
000003650025A62B @ 13 : 23 01 00 StaGlobal [1], [0]
000003650025A62E @ 16 : 0e LdaUndefined
000003650025A62F @ 17 : aa Return
Не беспокойтесь о том, что значит каждый из этих байт-кодов, мы объясним это чуть позже. Посмотрите на первую строку массива байт-кодов, она сохраняет LdaConstant. Слева мы видим 13 00. Шестнадцатеричное число 0x13 — это перечислитель байт-кода, обозначающий, где должен находиться обработчик этого байт-кода.
После получения SetBytecodeHandler() будет вызвана с байт-кодом, операндами и enum её обработки. Эта функция находится внутри файла v8/src/interpreter/interpreter.cc; пример этой функции показан ниже.
void Interpreter::SetBytecodeHandler(Bytecode bytecode,
OperandScale operand_scale,
CodeT handler) {
DCHECK(handler.is_off_heap_trampoline());
DCHECK(handler.kind() == CodeKind::BYTECODE_HANDLER);
size_t index = GetDispatchTableIndex(bytecode, operand_scale);
dispatch_table_[index] = handler.InstructionStart();
}
size_t Interpreter::GetDispatchTableIndex(Bytecode bytecode,
OperandScale operand_scale) {
static const size_t kEntriesPerOperandScale = 1u << kBitsPerByte;
size_t index = static_cast(bytecode);
return index + BytecodeOperands::OperandScaleAsIndex(operand_scale) *
kEntriesPerOperandScale;
}
Как видите, dispatch_table_[index] вычисляет индекс байт-кода из таблицы вызовов, которая хранится в физическом регистре, и в итоге инициирует или финализирует функцию Dispatch() для выполнения байт-кода.
Массив байт-кодов также содержит Constant Pool Pointer, хранящий объекты кучи, на которые в сгенерированном байт-коде ссылаются как на константы, например, строки и integer. Пул констант является FixedArray указателей на объекты кучи. Пример этого указателя на BytecodeArray и его пул констант объектов кучи показан ниже.
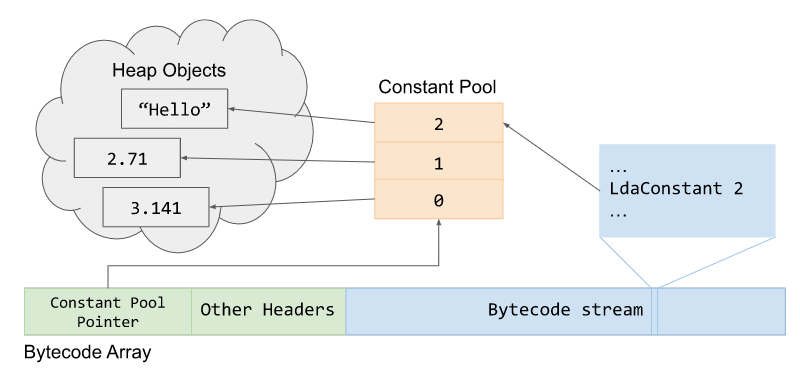
Прежде чем продолжить, я хотел бы также упомянуть, что заглушка InterpreterEntryTrampoline имеет фиксированные регистры машины, используемые Ignition. Эти регистры расположены внутри файла v8/src/codegen/x64/register-x64.h.
Пример этих регистров показан ниже, к интересующим нас добавлены комментарии.
// Определяет методы {RegisterName} для типов регистров.
DEFINE_REGISTER_NAMES(Register, GENERAL_REGISTERS)
DEFINE_REGISTER_NAMES(XMMRegister, DOUBLE_REGISTERS)
DEFINE_REGISTER_NAMES(YMMRegister, YMM_REGISTERS)
// Даёт псевдонимы регистрам для соответствия стандартам вызова.
constexpr Register kReturnRegister0 = rax;
constexpr Register kReturnRegister1 = rdx;
constexpr Register kReturnRegister2 = r8;
constexpr Register kJSFunctionRegister = rdi;
// Указывает на текущий объект контекста
constexpr Register kContextRegister = rsi;
constexpr Register kAllocateSizeRegister = rdx;
// Сохраняет косвенный регистр аккумулятора интерпретатора
constexpr Register kInterpreterAccumulatorRegister = rax;
// Текущее смещение выполнения в BytecodeArray
constexpr Register kInterpreterBytecodeOffsetRegister = r9;
// Указывает на начало интерпретируемого объекта BytecodeArray
constexpr Register kInterpreterBytecodeArrayRegister = r12;
// Указывает на таблицу вызовов интерпретатора, используемую для вызова обработчика следующего байт-кода
constexpr Register kInterpreterDispatchTableRegister = r15;
Разобравшись с этим, погрузимся в изучение байт-кода V8 и того, как операнд байт-кода взаимодействует с регистровым файлом.
Разбираемся с байт-кодом V8
Как говорилось в части первой, в V8 есть несколько сотен байт-кодов, и все они определены в файле заголовка v8/src/interpreter/bytecodes.h. Как мы вскоре увидим, каждый из этих байт-кодов указывает свои операнды ввода и вывода в виде регистров регистрового файла. Кроме того, многие из опкодов начинаются с Lda или Sta, где a обозначает аккумулятор.
Например, давайте рассмотрим определение байт-кода LdaSmi:
V(LdaSmi, ImplicitRegisterUse::kWriteAccumulator, OperandType::kImm)
Как видите, LdaSmi записывает (Load) (отсюда Ld) значение в регистр аккумулятора. В данном случае он записывает операнд kImm, являющийся signed byte, который соответствует Smi, или Small Integer в имени байт-кода. В итоге, этот байт-код записывает small integer в регистр аккумулятора.
Стоит заметить, что список операндов и их типов определён в файле заголовка v8/src/interpreter/bytecode-operands.h.
Итак, имея эту базовую информацию, давайте рассмотрим байт-код настоящей функции на JavaScript. Для начала запустим d8 с флагом --print-bytecode, чтобы можно было просматривать байт-код. После этого введём произвольный код на JavaScript и несколько раз нажмём на Enter. Это нужно потому, что V8 является «ленивым» движком, поэтому не будет компилировать то, что ему не нужно. Но поскольку мы используем string и числа в первый раз, он компилирует библиотеки наподобие Stringify, что поначалу приводит к огромному количеству выводимых данных.
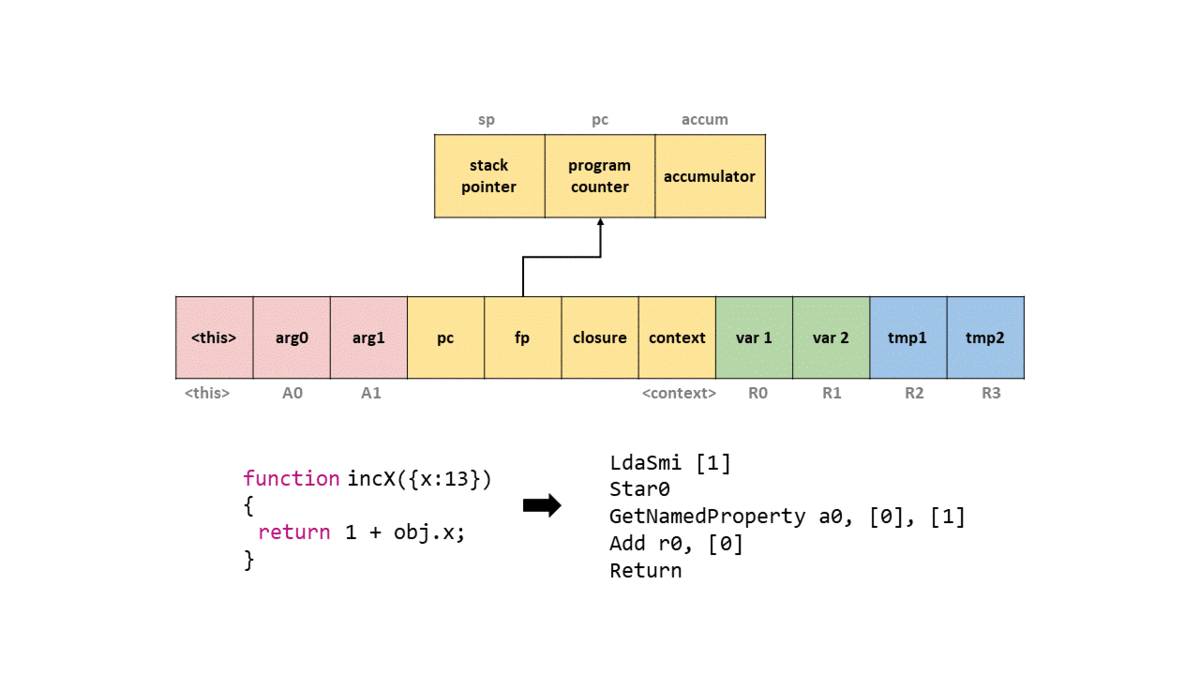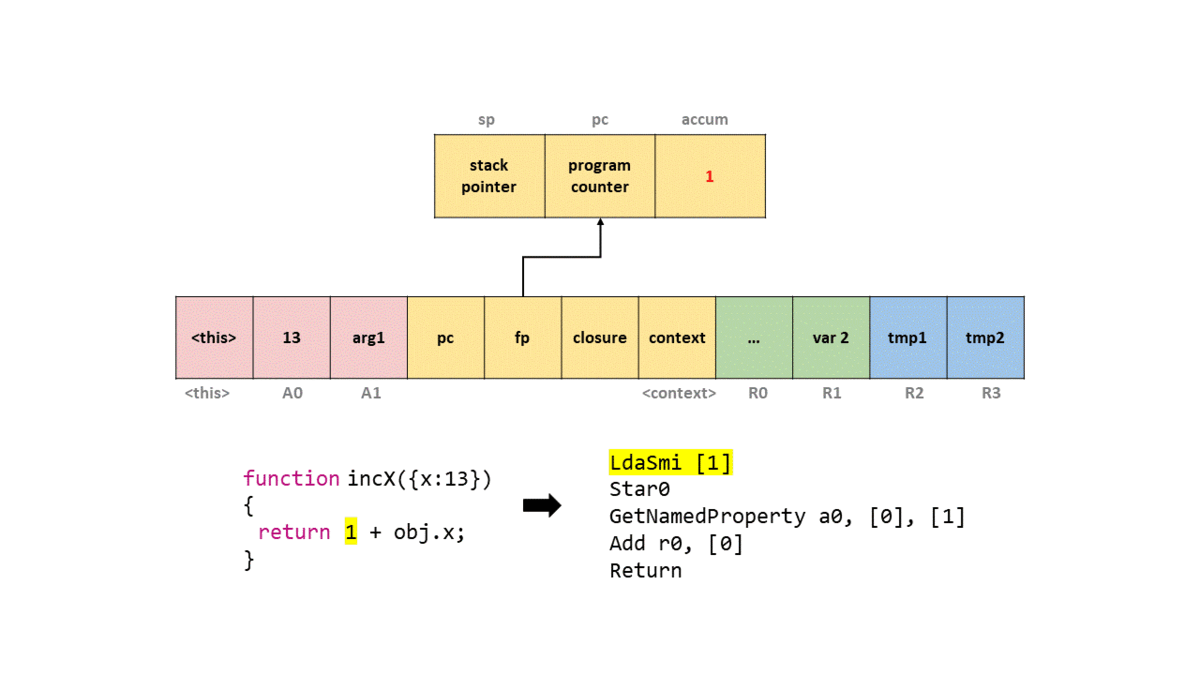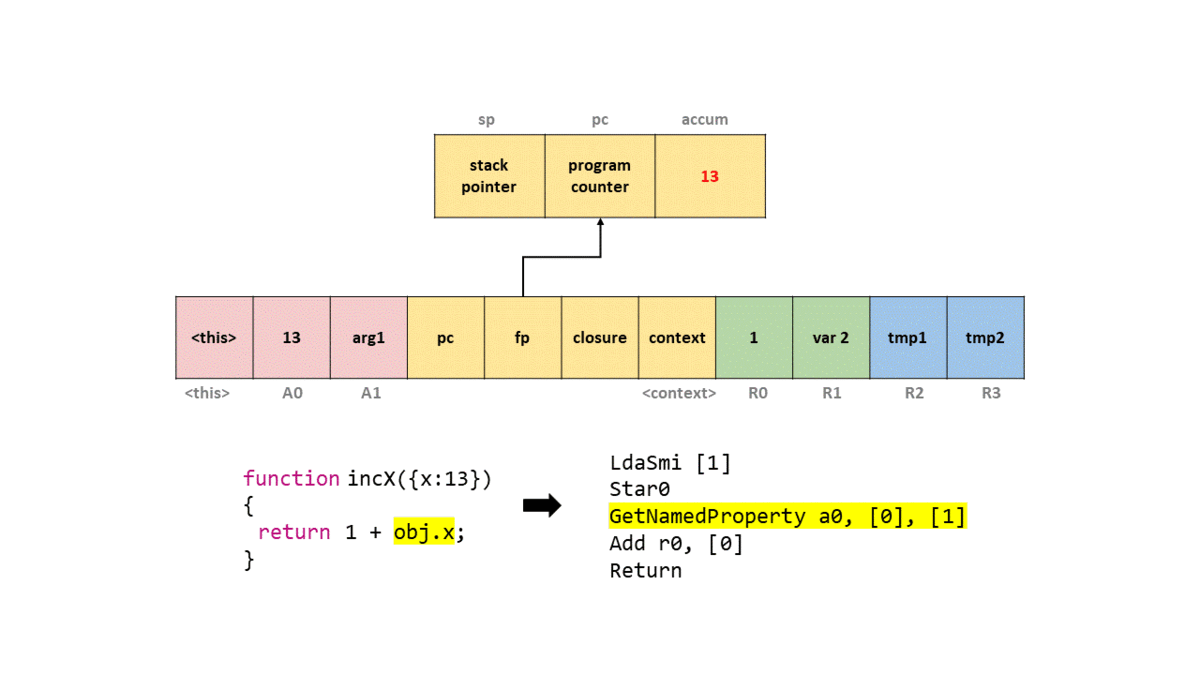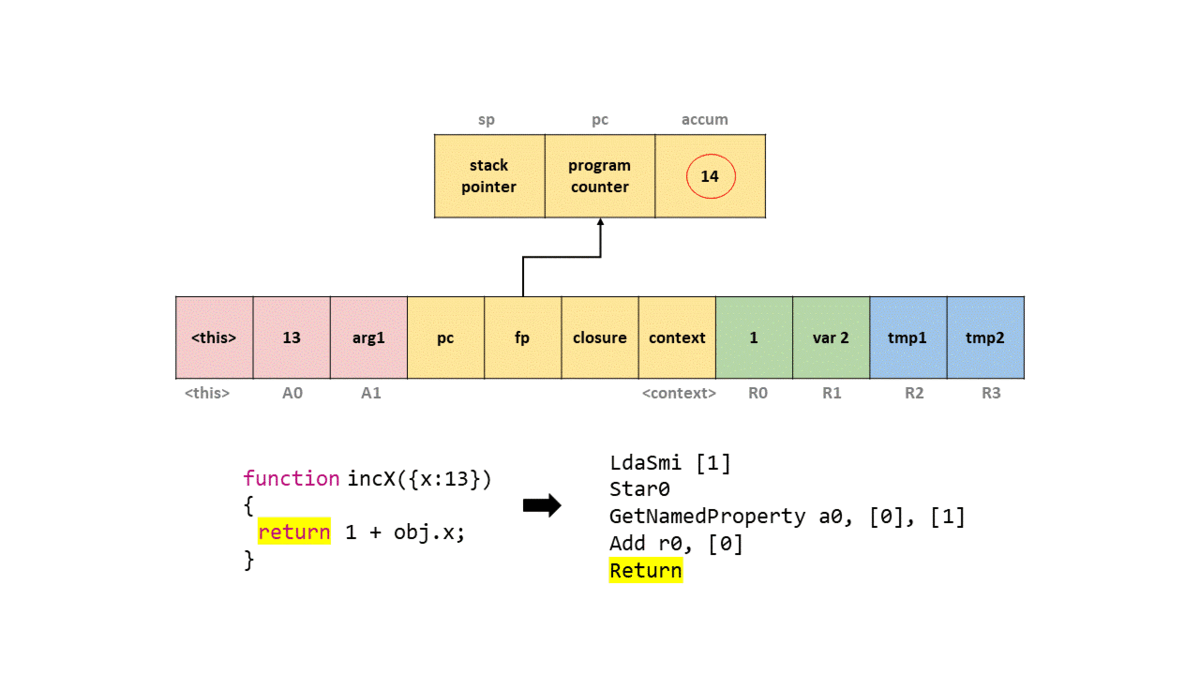
После этого создадим простую функцию JavaScript incX, которая будет выполнять инкремент свойства объекта x на единицу, и возвращать его. Функция будет выглядеть так.
function incX(obj) { return 1 + obj.x; }
Это сгенерирует байт-код, но не будем о нём беспокоиться. Теперь давайте вызовем эту функцию с объектом, у которого свойству x присвоено свойство, и просмотрим сгенерированный код.
d8> incX({x:13});
...
[generated bytecode for function: incX (0x026c0025ab65 )]
Bytecode length: 11
Parameter count 2
Register count 1
Frame size 8
Bytecode age: 0
0000026C0025ACC6 @ 0 : 0d 01 LdaSmi [1]
0000026C0025ACC8 @ 2 : c5 Star0
0000026C0025ACC9 @ 3 : 2d 03 00 01 GetNamedProperty a0, [0], [1]
0000026C0025ACCD @ 7 : 39 fa 00 Add r0, [0]
0000026C0025ACD0 @ 10 : aa Return
Constant pool (size = 1)
0000026C0025AC99: [FixedArray] in OldSpace
- map: 0x026c00002231
- length: 1
0: 0x026c000041ed
Handler Table (size = 0)
Source Position Table (size = 0)
14
Нас интересует только часть, относящаяся к байт-коду. Сначала обратим внимание, что этот байт-код находится в объекте SharedFunctionInfo, о котором мы говорили выше! Мы видим, что вызывается LdaSmi, записывающая small integer со значением 1 в регистр аккумулятора.
Далее мы вызываем Star0, сохраняющую (поэтому и St) значение в аккумулятор (поэтому и a) в регистре r0. То есть в этом случае мы записываем 1 в r0.
Байт-код GetNameProperty получает именованное свойство из a0 и сохраняет его в аккумулятор, который будет иметь значение 13. a0 относится к i-тому аргументу функции. То есть если мы передали a,b,x и хотим записать x, то в операнде байт-кода должно быть указано a2, поскольку нам нужен второй аргумент функции (вспомним, что это массив аргументов). В этом случае a0 будет искать именованное свойство в таблице, где индекс 0 отображается на x.
- length: 1
0: 0x026c000041ed
Если вкратце, это байт-код, записывающий obj.x. Другой операнд [0] называется feedback vector (вектор обратной связи), он содержит информацию среды выполнения и данные shape объекта, используемые TurboFan для оптимизации.
Далее мы прибавляем (Add) значение в регистре r0 к аккумулятору, что даёт нам значение 14. Затем мы вызываем Return, который возвращает значение в аккумуляторе, и выходим из функции.
Чтобы вы могли представить это в кадре стека, я создал GIF того, что происходит в упрощённом стеке с каждой командой байт-кода.
Как видите, хотя байт-коды немного загадочны, после того, как мы разберёмся, что делает каждый из них, их будет довольно легко понять и исследовать. Если вы хотите больше узнать о байт-коде V8, рекомендую прочитать JavaScript Bytecode — v8 Ignition Instructions, в котором рассматривается большая часть операций.
Теперь, когда у нас есть приличное понимание того, как Ignition генерирует и исполняет наш код на JavaScript в виде байт-кода, настало время рассмотреть часть конвейера компилятора V8, относящуюся к компиляции. Начнём мы с Sparkplug, поскольку его довольно легко понять, ведь он выполняет лишь небольшую модификацию уже сгенерированного байт-кода и стека в целях оптимизации.
Как мы знаем из части первой, Sparkplug — это очень быстрый неоптимизирующий компилятор движка V8, расположенный между Ignition и TurboFan. По сути, Sparkplug на самом деле не компилятор, а больше похож на транспилятор, преобразующий байт-код Ignition в машинный код для его нативного выполнения. Кроме того, это неоптимизирующий компилятор, поэтому он не вносит особых оптимизаций, поскольку этим занимается TurboFan.
Так почему же Sparkplug настолько быстр? Он быстр, потому что жульничает. Во-первых, компилируемые им функции уже были скомпилированы в байт-код, и, как мы знаем, Ignition уже проделал всю сложную работу с переменной дискретностью, управлением потоком и так далее. В этом случае, Sparkplug выполняет компиляцию из байт-кода, а не из исходников на JavaScript.
Во-вторых, Sparkplug не создаёт промежуточного представления (intermediate representation, IR), как это делает большинство компиляторов (о чём мы узнаем позже). В данном случае. Sparkplug выполняет компиляцию в машинный код за один линейный проход по байт-коду. Это явление имеет общее название 1:1 mapping.
Любопытно, что Sparkplug, по сути, во многом является простым оператором switch внутри цикла for, который выполняет вызовы фиксированного байт-кода, а затем генерирует машинный код. Эту реализацию можно увидеть в файле исходников v8/src/baseline/baseline-compiler.cc.
Пример функции генерации машинного кода Sparkplug показан ниже.
switch (iterator().current_bytecode()) {
#define BYTECODE_CASE(name, ...) \
case interpreter::Bytecode::k##name: \
Visit##name(); \
break;
BYTECODE_LIST(BYTECODE_CASE)
#undef BYTECODE_CASE
}
Как же Sparkplug генерирует этот машинный код? Разумеется, он снова жульничает. Sparkplug сам по себе генерирует очень мало кода, вместо этого он просто вызывает встроенные функции байт-кода, вход в которые обычно выполняется InterpreterEntryTrampoline с последующей обработкой в v8/src/builtins/x64/builtins-x64.cc.
Вспомним, что когда мы говорили о Ignition, в объекте JSFunction упоминалось замыкание, связанное с «оптимизированным кодом». По сути, Sparkplug хранит там встроенную функцию байт-кода, а при выполнении функции вместо вызова байт-кода мы вызываем непосредственно встроенную функцию.
Теперь вы уже наверно думаете, что Sparkplug, по сути, является просто интерпретатором с громким именем, и вы не ошибаетесь. Sparkplug фактически занимается просто сериализацией исполнения интерпретатора, вызывая те же встроенные функции. Однако это позволяет функции JavaScript работать быстрее, поскольку благодаря этому мы можем избежать излишних затрат в интерпретаторе наподобие декодирования опкодов и поиска в таблице вызовов байт-кода, что позволяет нам уменьшить объём использования CPU, перейдя из движка эмуляции к нативному исполнению.
Чтобы чуть больше узнать о том, как работают эти встроенные функции, рекомендую прочитать Short Builtin Calls.
1:1 Mapping
1:1 mapping Sparkplug связано не только с тем, как оно компилирует байт-код Ignition в разновидность машинного кода; это связано и с кадрами стека. Как мы знаем, каждой части конвейера компилятора нужно хранить состояние функции. И как мы уже видели в V8, состояния функций JavaScript сохраняются в кадры стека Ignition сохранением текущей вызываемой функции, контекста, с которой она вызывается, количества переданных аргументов, указателя на массив байт-кодов, и так далее.
Как мы знаем, Ignition — это интерпретатор на основе регистров. Он имеет виртуальные регистры, используемые для аргументов функций, а также как вводы и выводы для операндов байт-кода. Чтобы Sparkplug был быстрым и ему не приходилось самостоятельно заниматься распределением регистров, он повторно использует кадры регистров Ignition, что, в свою очередь, позволяет Sparkplug «отзеркаливать» поведение интерпретатора и стек. Благодаря этому Sparkplug не требуется никакое отображение между двумя кадрами, поэтому эти кадры стека совместимы почти 1:1.
Стоит заметить, что я сказал «почти» — существует одно небольшое различие между кадрами стека Ignition и Sparkplug. И это различие заключается в том, что Sparkplug не нужно хранить слот смещения байт-кода в регистровом файле, поскольку код Sparkplug создаётся непосредственно из байт-кода. Вместо этого он заменяет его на кэшированный вектор обратной связи.
Пример сравнения этих двух кадров стека показан на изображении ниже, взятом из документации по Ignition.
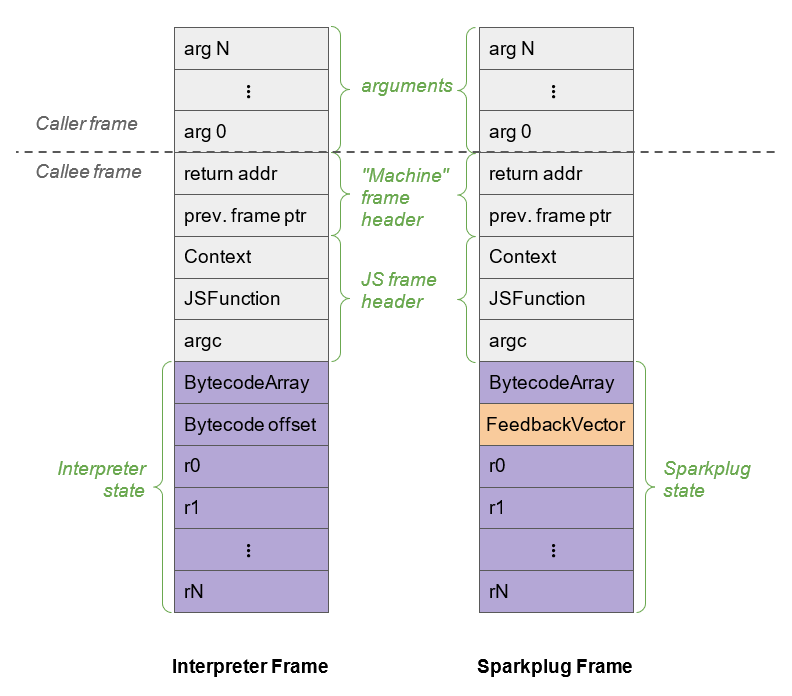
Так зачем же Sparkplug нужно создавать и хранить структуру кадра стека, схожего с кадром стека Ignition? По одной причине, и это основная причина того, как работают Sparkplug и Turbofan — они выполняют так называемую on-stack replacement (OSR) (замену в стеке). OSR — это возможность замены текущего исполняемого кода другой версией. В данном случае, когда Ignition видит, что функция JavaScript используется часто, он отправляет её в Sparkplug для ускорения.
После того, как Sparkplug сериализирует байт-коды в их встроенные функции, он заменяет кадр стека интерпретатора для этой конкретной функции. При обходе и исполнении стека код переходит непосредственно в Sparkplug, а не исполняется в эмулируемом стеке Ignition. А поскольку кадры «отзеркаливаются», это, по сути, позволяет V8 переключаться между кодом интерпретатора и Sparkplug практически с нулевыми лишними тратами на трансляцию кадра.
Прежде чем мы двинемся дальше, мне бы хотелось упомянуть аспект безопасности Sparkplug. В общем случае, вероятность проблемы безопасности в самом сгенерированном коде мала. Угроза безопасности в Sparkplug выше в том, как интерпретируется структура кадров стека Ignition, что может привести к type confusion или к исполнению кода в стеке.
Один из примеров подобного — Issue 1179595, имевшая потенциальное RCE из-за недопустимой проверки количества регистров. Также сложность есть и в том, как Sparkplug выполняет инвертирование битов RX/WX. Однако я не буду вдаваться в подробности, поскольку на самом деле это не очень важно и такие баги не играют важной роли в нашей серии статей.
Итак, теперь мы понимаем, как работают Ignition и Sparkplug. Настало время углубиться в конвейер компилятора и в понимание оптимизирующего компилятора TurboFan.
TurboFan — это компилятор Just-In-Time (JIT) движка V8, сочетающий интересную концепцию непосредственного представления «море узлов» (Sea of Nodes) с многоуровневым конвейером трансляции и оптимизации, помогающим TurboFan генерировать более качественный машинный код из байт-кода. Если вы в процессе чтения статьи изучаете код и документацию, то знаете, что TurboFan — это гораздо больше, чем просто компилятор.
TurboFan отвечает за обработчики байт-кода
