[Перевод] Дружим ORDER BY с индексами

Привет, Хабр!
Я потихоньку перевожу статьи Маркуса Винанда из блога use the index luke.
Первой статьей в цикле был манифест Маркуса о важности использования безофсетной пагинации на ключах. Мы рассмотрели всего один пример, как этот подход работает на практике. В этой и следующих статьях я буду обосновывать такой подход — с графиками и примерами, как все любят.
Начнем с самого начала. В этой статье будет разбор pipelined order by. Мы рассмотрим, что это такое, как достичь и в чем преимущества такого подхода. В следующей статье поговорим про top-N синтаксис и его связь с pipelined order by. И уже потом перейдем к пагинации, которая будет внутри себя использовать все ранее описанные подходы, и тогда станет понятно, как это все работает внутри и почему это действительно круто.
Стоит заметить, что оригинальные материалы довольно старые по меркам нашей индустрии: статья про инструментальную поддержку обновлялась последний раз в конце 2017. Поэтому, если у вас есть информация о том, что изменилось за это время, — пишите в комментариях. Я обязательно все проверю и исправлю, в том числе сообщу автору блога.
Все свои комментарии и примечания я оставляю с пометкой «прим.», чтобы разделить слова автора и свои собственные. Кроме того, я позволил себе вольность набросать запросы и скрипты для PostgreSQL — мне кажется, это достаточно актуальная база данных, чтобы включить ее в примеры. Скрипт целиком на Гитхабе.
Введение
SQL-запросы, использующие order by, могут избегать явной сортировки результата, если выражение попадает в существующий индекс. Это происходит при условии, что последний предоставляет запрашиваемый порядок записей. Однако это так же значит, что индекс, который покрывает выражение where в запросе, должен покрывать порядок сортировки в order by.
Прим.: Для примера пусть задана таблица продаж. В ней создано два атрибута: sale_date, то есть дата продажи (только дата, без времени), и product_id — айди вида товара, который был продан; sale_date при этом покрыт индексом.
Рассмотрим следующий запрос, который выбирает вчерашние заказы, сортируя их сначала по дате, а затем по айди продукта:
SELECT sale_date, product_id, quantity
FROM sales
WHERE sale_date = TRUNC(sysdate) - INTERVAL '1' DAY
ORDER BY sale_date, product_idКак уже было сказано, sale_date покрыт индексом и этот индекс может быть использован в условии where. Но база все равно должна явно отсортировать записи, чтобы удовлетворить order by в запросе.
Планы выполнения:
Explain Plan
------------------------------------------------------------
ID | Operation | Rows | Cost
1 | RETURN | | 682
2 | TBSCAN | 394 of 394 (100.00%) | 682
3 | SORT | 394 of 394 (100.00%) | 682
4 | FETCH SALES | 394 of 394 (100.00%) | 682
5 | IXSCAN SALES_DATE | 394 of 1009326 ( .04%) | 19
Predicate Information
5 - START (Q1.SALE_DATE = (CURRENT DATE - 1 DAYS))
STOP (Q1.SALE_DATE = (CURRENT DATE - 1 DAYS))Из-за специфики DB2 выражение where немного меняется: WHERE sale_date = CURRENT_DATE — 1 DAY. Но суть остается такая же.
---------------------------------------------------------------
|Id | Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 | SELECT STATEMENT | | 320 | 18 |
| 1 | SORT ORDER BY | | 320 | 18 |
| 2 | TABLE ACCESS BY INDEX ROWID| SALES | 320 | 17 |
|*3 | INDEX RANGE SCAN | SALES_DATE | 320 | 3 |
---------------------------------------------------------------Sort (cost=27862.15..28359.74 rows=199034 width=16) (actual time=259.075..370.953 rows=200000 loops=1)
Sort Key: product_id
Sort Method: external merge Disk: 5872kB
-> Index Scan using sales_date on sales (cost=0.42..6942.52 rows=199034 width=16) (actual time=0.030..121.512 rows=200000 loops=1)
Index Cond: (sale_date = '2020-01-05 00:00:00'::timestamp without time zone)
Planning Time: 0.226 ms
Execution Time: 458.083 msОракловый index range scan всегда предоставляет записи в том порядке, в котором они указаны в индексе. Чтобы использовать это в свою пользу, нам придется немного изменить индекс:
DROP INDEX sales_date
CREATE INDEX sales_dt_pr ON sales (sale_date, product_id)
SELECT sale_date, product_id, quantity
FROM sales
WHERE sale_date = TRUNC(sysdate) - INTERVAL '1' DAY
ORDER BY sale_date, product_idПланы выполнения с новым индексом:
Explain Plan
-----------------------------------------------------------
ID | Operation | Rows | Cost
1 | RETURN | | 688
2 | FETCH SALES | 394 of 394 (100.00%) | 688
3 | IXSCAN SALES_DT_PR | 394 of 1009326 ( .04%) | 24
Predicate Information
3 - START (Q1.SALE_DATE = (CURRENT DATE - 1 DAYS))
STOP (Q1.SALE_DATE = (CURRENT DATE - 1 DAYS))---------------------------------------------------------------
|Id | Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 | SELECT STATEMENT | | 320 | 300 |
| 1 | TABLE ACCESS BY INDEX ROWID| SALES | 320 | 300 |
|*2 | INDEX RANGE SCAN | SALES_DT_PR | 320 | 4 |
---------------------------------------------------------------Index Scan using sales_dt_pr on sales (cost=0.42..18413.96 rows=199034 width=16) (actual time=0.043..206.096 rows=200000 loops=1)
Index Cond: (sale_date = '2020-01-05 00:00:00'::timestamp without time zone)
Planning Time: 0.259 ms
Execution Time: 295.872 msКак можно заметить, операция sort order by исчезла из плана, хотя запрос мы не меняли и в нем до сих пор содержится order by. База решила использовать проход по индексу и пропустить этап явной сортировки.
Неочевидные индексы
Хотя новый план выполнения имеет меньше операций, его стоимость значительно выше (прим.: в Oracle), потому что фактор кластеризации нового индекса хуже. Тут также надо заметить, что стоимость (cost value) не всегда хороший показатель эффективности выполнения запроса (прим.: под катом вкратце рассказывается, почему так).
Прим.: Фактор кластеризации показывает, насколько точно порядок записей в индексе совпадает с их порядком в таблице.
База данных Oracle старается держать фактор кластеризации на минимуме с помощью псевдостолбца ROWID, который определяет порядок записей в индексе. В тот момент, когда две индексируемые записи имеют одинаковый ключ, ROWID решает, каким будет их конечный порядок. Получается, что индекс, в свою очередь, также упорядочивается согласно порядку записей в таблице. Следовательно, он имеет минимально возможный фактор кластеризации.
При добавлении дополнительного столбца в индекс мы добавляем новый критерий сортировки перед ROWID. База данных при этом свободна в выравнивании элементов индекса согласно порядку в таблице, поэтому фактор кластеризации индекса становится только хуже.
Несмотря на это, все еще возможно, что индекс слабо, но все-таки соответствует порядку в таблице. Продажи, относящиеся к одному дню, вероятно, все еще кластеризованы вместе как в таблице, так и в индексе — даже если их последовательность уже не совпадает. БД вынуждена читать одни и те же блоки таблицы несколько раз в разном порядке при использовании индекса sale_dt_pr. Тем не менее на производительность это может влиять намного меньше, чем вычисленная стоимость в плане выполнения, так как частые запросы к одним и тем же данным попадут в кэш и будут обрабатываться намного быстрее.
В нашем случае достаточно, чтобы сканируемый индекс был отсортирован согласно order by. Следовательно, такой подход будет работать в запросе, где мы хотим сортировать только по столбцу product_id:
SELECT sale_date, product_id, quantity
FROM sales
WHERE sale_date = TRUNC(sysdate) - INTERVAL '1' DAY
ORDER BY product_idНа рисунке ниже можем заметить, что product_id — единственный уместный критерий сортировки в сканируемом индексе при таком запросе (прим.: так как дата за один день всегда одинакова для всех записей в этот день). Следовательно, порядок индекса совпадает с порядком в order by в данном диапазоне индекса, поэтому база может опустить явную сортировку.
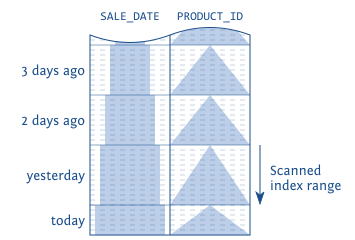
Порядок сортировки в соответствующих диапазонах индекса
Прим.: Здесь нужно немного пояснить рисунок. На нем изображено покрытие таблицы индексом и то, как этот индекс разбивается на области. Можно заметить, что дата за один день (столбец именно с датой, без времени) остается без изменений. Но, так как товары могут повторяться (product_id указывает на айди типа товара в таблице товаров) как внутри одной даты, так и между разными датами (например, условный товар-1 был продан вчера 5 раз и сегодня 2 раза). Из-за такой особенности можем получить разные неприятные последствия при попытке попасть в индекс.
Наше заигрывание с индексами иногда может приводить к непредвиденным последствиям. Например, когда изменением условия where мы расширяем область сканирования индекса:
SELECT sale_date, product_id, quantity
FROM sales
WHERE sale_date >= TRUNC(sysdate) - INTERVAL '1' DAY
ORDER BY product_idДанный запрос получает уже не только вчерашние записи о продажах, но все записи, начиная со вчерашнего дня. Это значит, что запрос уже покрывает больше одной даты. При этом получается, что записи сортируются не только по product_id (прим.: так как в запрос попадают два дня, а нам интересно увидеть сортировку только по айди товара, то все id записей за эти дни объединяются и из-за того, что отсортированы они только в одном диапазоне индекса — за конкретный день, то их приходится еще раз явно сортировать). Если снова вернемся к картинке выше и расширим сканируемую область индекса до самого низа, то увидим, что у нас повторно появляются меньшие значения с product_id. База данных, как следствие, должна применить явную сортировку, чтобы удовлетворить order by.
Планы выполнения:
Explain Plan
-------------------------------------------------------------
ID | Operation | Rows | Cost
1 | RETURN | | 688
2 | TBSCAN | 394 of 394 (100.00%) | 688
3 | SORT | 394 of 394 (100.00%) | 688
4 | FETCH SALES | 394 of 394 (100.00%) | 688
5 | IXSCAN SALES_DT_PR | 394 of 1009326 ( .04%) | 24
Predicate Information
5 - START ((CURRENT DATE - 1 DAYS) <= Q1.SALE_DATE)---------------------------------------------------------------
|Id |Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 |SELECT STATEMENT | | 320 | 301 |
| 1 | SORT ORDER BY | | 320 | 301 |
| 2 | TABLE ACCESS BY INDEX ROWID| SALES | 320 | 300 |
|*3 | INDEX RANGE SCAN | SALES_DT_PR | 320 | 4 |
---------------------------------------------------------------Sort (cost=34388.50..34886.08 rows=199034 width=16) (actual time=258.029..367.186 rows=200001 loops=1)
Sort Key: product_id
Sort Method: external merge Disk: 5872kB
-> Bitmap Heap Scan on sales (cost=4610.94..13468.86 rows=199034 width=16) (actual time=19.947..122.290 rows=200001 loops=1)
Recheck Cond: (sale_date >= '2020-01-05 00:00:00'::timestamp without time zone)
Heap Blocks: exact=1275
-> Bitmap Index Scan on sales_dt_pr (cost=0.00..4561.18 rows=199034 width=0) (actual time=19.742..19.742 rows=200001 loops=1)
Index Cond: (sale_date >= '2020-01-05 00:00:00'::timestamp without time zone)
Planning Time: 0.141 ms
Execution Time: 452.337 msЧто же тогда делать со всем этим безобразием?
Если БД использует сортировку, хотя вы ожидаете конвейерное выполнение (pipeline execution), то это может означать две вещи:
- План выполнения с явной сортировкой имеет меньшую стоимость, поэтому оптимизатор предпочел выбрать его.
- Порядок записей в сканируемом диапазоне индекса не удовлетворяет выражению в order by.
Самый простой способ определить, что что-то пошло не так, — подставить в order by полное покрытие индекса. Таким образом мы выравниваем весь запрос по индексу, чтобы исключить второй вариант. В результате, если база продолжает использовать явную сортировку, значит, оптимизатор предпочитает такой план из-за его меньшей стоимости. Если же сортировка пропала, то это свидетельствует о невозможности использовать индекс в order by.
В любом случае хочется понимать, можно ли получить конвейер в конкретном случае и как это сделать. Для этого также подойдет выполнение запроса с полным попаданием в индекс в order by и инспекция плана выполнения. Зачастую удается обнаружить ложное восприятие индекса и то, что он не соответствует требованию order by. Поэтому БД не может использовать его в конкретном запросе.
Заключение
Если оптимизатор предпочитает явную сортировку ввиду ее более низкой стоимости, то это обычно происходит потому, что оптимизатор оценивает план выполнения целиком. Другими словами, оптимизатор выбирает тот план, который отдает последнюю запись результата быстрее. Если БД обнаруживает, что запрашиваются не все данные, а, например, только первые N записей, то вероятнее, что конвейер будет выбран в качестве оптимального подхода, если он, конечно же, возможен. Этот случай мы рассмотрим в следующей статье про top-N записей.
Источник: https://use-the-index-luke.com/sql/sorting-grouping/indexed-order-by
Автор: Markus Winand
