[Перевод] Доступен новый JIT: теперь с поддержкой SIMD
От переводчика Лично я просто невероятно обрадовался новой возможности. Как раз не так давно одолел Pro .Net Perfomance, в которой одна из глав была посвящена параллельности, и векторизации в частности. Вывод, сделанный авторами: «К сожалению, использование векторизации возможно исключительно на С++, выполнение кода на видеокарте — возможно и средствами .Net, однако C++ AMP оставляет любые управляемые библиотеки GPGPU далеко позади, поэтому, к сожалению, в данных задачах рекомендуем использовать подключаемые C++ сборки.» Поэтому рад сообщить, что по крайней мере одна проблема решена. Что ж, приступим! Вступление Быстродействие процессоров более не подчиняется закону Мура. Поэтому для увеличения производительности приложений, все важнее использовать параллелизацию. Или, как говорил Герб Саттер, «бесплатного супа больше не будет» (The free lunch is over, отсылка к статье The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software, перевод на хабре)
Можно подумать, что использование задачеориентированного программирования (например, в случае .Net — TPL, прим. пер.) или обычных потоков уже решает эту проблему. В то время как многопоточность, безусловно, является важной задачей, нужно понимать, что по-прежнему важно оптимизировать код, выполняющийся на каждом отдельном ядре. SIMD это технология, которая использует распараллеливание данных на уровне процессора. Многопоточность и SIMD дополняют друг друга: многопоточность позволяет распараллеливать работу на несколько ядер процессора, в то время как SIMD позволяет распараллеливать работу в пределах одного ядра.
Сегодня мы рады объявить о новой превью-версии RyuJIT, которая обеспечивает функциональность SIMD. SIMD API доступен через новый пакет NuGet, Microsoft.Bcl.Simd, который также выпущен в виде превью.
Вот пример, как вы можете его использовать:
// Initalize some vectors
Vector
// The next line will leverage SIMD to perform the // addition of multiple elements in parallel:
Vector

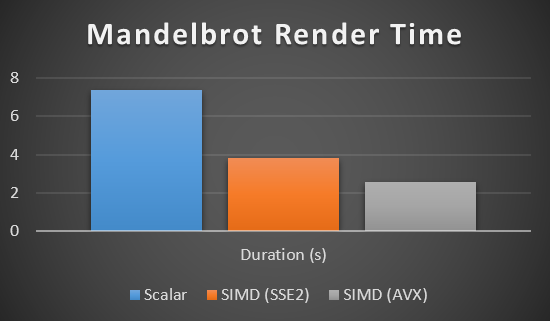
Он настолько популярен, потому что, за исключением некоторых видов приложений, SIMD существенно ускоряет работу кода. Например, производительность рендеринга множества Мандельброта можно ощутимо улучшить с помощью SIMD: в 2–3 раза (если процессор поддерживает SSE2), и в 4–5 раз (если процессор поддерживает AVX).
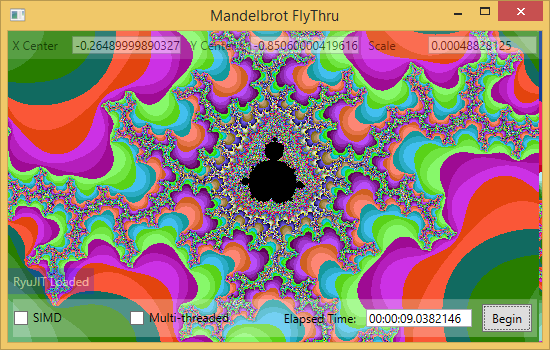
Введение в SIMD SIMD расшифровывается как «одна команда, множество данных» (отечественный вариант — ОКМД, прим. пер). Это набор инструкций процессора, которые позволяют работать над векторами вместо скаляров. За счет этого возможно параллельное выполнение математических операций над множеством данных.
SIMD позволяет распараллеливать данные на уровне процессора, используя высокоуровневые средства. Например, представьте, что у вас есть множество чисел, и к каждому нужно прибавить какое-то значение. Обычно, для решения этой задачи пишется цикл, который выполняет эту операцию последовательно для каждого элемента:
float[] values = GetValues (); float increment = GetIncrement ();
// Perform increment operation as manual loop: for (int i = 0; i < values.Length; i++) { values[i] += increment; } SIMD же позволяет прибавлять несколько значений одновременно, используя специфические инструкции CPU. Обычно это выглядит, как операция над вектором:
Vector
// Perform addition as a vector operation:
Vector
Вот упрощенная модель того, как работает SIMD на уровне процессора:
В процессоре есть специальные SIMD регистры. Они имеют фиксированный размер. Например, для SSE2, размер 128 бит. Процессор также имеет специальные SIMD-инструкции, зависящие от размера операнда. С точки зрения процессора, данные в SIMD регистре являются просто набором бит. Однако, разработчик хочет интерпретировать эти биты как, ну скажем, набор 32-битных целых чисел. Для этой цели в процессоре есть инструкции, специфичные для выполняемой операции (например, сложения), и типа операнда (например, 32-битного целого) Одна из многих областей, где SIMD является весьма полезным — это графика и игры, так как:
Эти приложения выполняют очень много вычислений. Большинство структур данных уже представлены как векторы. Однако SIMD применим к любому типу приложения, которое выполняет числовые операции на большом наборе значений. Сюда же можно отнести научные расчеты и финансыПроектирование SIMD для. NET Большинство .NET разработчиков не должно писать CPU-зависимый код. Вместо этого CLR абстрагирует аппаратное обеспечение, предоставляя виртуальную машину, которая переводит свой код в машинные команды либо во время выполнения (JIT), либо во время установки (NGEN). Оставляя генерацию кода CLR, вы можете использовать один и тот же MSIL код на разных компьютерах с разными процессорами, не отказываясь от оптимизаций, специфических для данного конкретного CPU.
Это разделение является тем, что позволяет использовать библиотечную экосистему, потому что это чрезвычайно упрощает повторное использование кода. Мы считаем, что библиотечная экосистема является главной причиной того, что .NET является такой продуктивной средой.
Для того чтобы сохранить это разделение, мы должны были придумать такую модель программирования для SIMD, которая бы позволила выразить векторные операции без привязки к конкретной реализации процессора, например SSE2. Мы придумали модель, которая обеспечивает две категории векторных типов:

Эти две категории мы называем JIT-«встроенными типами». Это означает, что JIT знает об этих типах и трактует их особым образом при генерации машинного кода. Тем не менее, все типы также разработаны для безупречной работы в тех случаях, когда оборудование не поддерживает SIMD (что встречается сегодня довольно редко) или приложение не использует эту версию RyuJIT. Наша цель заключается в обеспечении приемлимой производительности даже в тех случаях, когда она примерно такая же, как и для последовательного написанный кода. К сожалению, в этом превью мы пока этого не достигли.
Векторы с фиксированным размером Давайте сперва поговорим о векторах фиксированного размера. Есть много приложений, которые уже определяют свои собственные векторные типы, особенно графические приложения, такие как игры или рэйтрэйсеры (ray tracer). В большинстве случаев эти приложения используют значения с плавающей запятой и одинарной точностью.
Ключевым аспектом является то, что эти векторы имеют определенное количество элементов, как правило, два, три или четыре. Двухэлементные векторы часто используется для представления точки или подобных объектов, таких как комплексные числа. Векторы с тремя и четырьмя элементами, как правило, используется для 3D (4-й элемент используется, чтобы сделать математическую работу [Очевидно, речь идет о том, что в 3D-моделировании преобразования используют четырехмерные матрицы XYZ1, прим. пер]). Суть в том, что эти задачи используют векторы с определенным количеством элементов.
Чтобы получить представление о том, как эти типы выглядят, посмотрим на упрощенную версию Vector3f:
public struct Vector3f { public Vector3f (float value); public Vector3f (float x, float y, float z); public float X { get; } public float Y { get; } public float Z { get; } public static bool operator ==(Vector3f left, Vector3f right); public static bool operator!=(Vector3f left, Vector3f right); // With SIMD, these element wise operations are done in parallel: public static Vector3f operator +(Vector3f left, Vector3f right); public static Vector3f operator -(Vector3f left, Vector3f right); public static Vector3f operator -(Vector3f value); public static Vector3f operator *(Vector3f left, Vector3f right); public static Vector3f operator *(Vector3f left, float right); public static Vector3f operator *(float left, Vector3f right); public static Vector3f operator /(Vector3f left, Vector3f right); } Я хотел бы подчеркнуть следующие аспекты:
Мы разработали векторы фиксированного размера, так что они могут легко заменить те, которые определены приложениях. По соображениям производительности, мы определили эти типы, как неизменяемые типы значений. Идея состоит в том, что после замены вашего вектора нашим, ваше приложение будет вести себя так же, за исключением того, что оно будет работает быстрее. Для получения более подробной информации, посмотрите на наш пример приложения трассировки лучей. Векторы с аппаратно-зависимым размером В то время векторные типы фиксированного размера удобно использовать, их максимальная степень параллелизации ограничена количеством компонентов. Например, приложение, которое использует Vector2f получит ускорение, самое большее, в два раза, даже если CPU будет способен выполнять операции над восемью элементами одновременно.
Для того, чтобы приложение масштабировалось с аппаратными возможностями, разработчик должен векторизовать алгоритм. Векторизация алгоритма означает то, что разработчик должен разбить входные параметры на множество векторов, размер которых зависит от оборудования. На машине с SSE2, это означает, что приложение может работать над векторами из четырех 32-битных чисел с плавающей запятой. На машине с AVX, то же приложение может работать над векторами из восьми таких чисел.
Чтобы понять для разницу, ниже представлена упрощенная версия Vector
public struct Vector
Он обобщенный. Для повышения гибкости и во избежание комбинаторного взрыва типов, мы определили аппаратно-зависимый вектор как обобщенный тип, Vector
При наивном использовании SIMD, можно было бы векторизовать алгоритм, представляя комплексные числа как Vector2f. Более сложный алгоритм будет векторизовать точки для визуализации (число которых является неограниченным) вместо размера (который фиксирован). Один из способов сделать это заключается в представлении действительной и мнимой компонент, как векторов. Другими словами, можно было бы векторизовать один и тот же компонент над несколькими точками.
Для получения более подробной информации, посмотрите на наш пример. В частности, сравните скалярную и векторизованную версии.
Использование превью-версии SIMD В предпросмотре мы предоставляем следующие две части:
Новый релиз RyuJIT, который обеспечивает поддержку SIMD Новая библиотека NuGet, который предоставляет поддержку SIMD Библиотека NuGet была специально предназначена для работы без поддержки SIMD со стороны аппаратных средств / JIT. В этом случае все методы и операции реализованы в виде чистого IL. Тем не менее, очевидно, что вы можете получить максимальную производительность только при использовании этой библиотеки в сочетании с новой версией RyuJIT.
Для того чтобы использовать SIMD, вам необходимо выполнить следующие шаги:
Скачать и установить последнюю превью RyuJIT с aka.ms/RyuJIT Установить некоторые переменные окружения для активизации новой JIT и SIMD для вашего процесса. Самый простой способ сделать это путем создания пакетного файла, который запускает ваше приложение: @echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe Добавьте ссылку на NuGet-пакет Microsoft.Bcl.Simd. Вы можете сделать это, щелкнув правой кнопкой мыши на проекте и выбрав Manage NuGet References. В следующем диалоговом окне выберите вкладку под названием Online. Кроме того, необходимо выбрать Include Prelease в выпадающем списке на самом верху. Затем введите в текстовое поле в верхнем правом углу слово Microsoft.Bcl.Simd. Нажмите кнопку Install. В данном превью существуют определенные ограничения, о которых, возможно, вам стоит знать:
SIMD доступна только для 64-битных процессов. Поэтому убедитесь, что ваше приложение либо ориентировано именно на x64, либо скомпилировано как Any CPU, а не отмечено как 32-битное
Тип Vector поддерживает только int, long, float и double. Создание экземпляров Vector
Мы хотели бы получить ваши отзывы об обоих проектах. Нравится ли вам такая модель программирования? Чего не хватает? Какие улучшения производительности нужны для вашего приложения? Пожалуйста, используйте комментарии для обеспечения обратной связи или отправьте нам письмо по адресу ryujit (at)microsoft.com.
