[Перевод] Дэвид О’Брайен (Xirus): Метрики! Метрики! Метрики! Часть 2
Недавно Дэвид О«Брайен открыл свою собственную компанию Xirus (https://xirus.com.au), сосредоточившись на облачных продуктах Microsoft Azure Stack. Они предназначены для согласованного создания и запуска гибридных приложений в центрах обработки данных, в пограничных расположениях, удаленных офисах и облаке.
Дэвид обучает отдельных лиц и компании всему, что связано с Microsoft Azure и Azure DevOps (бывшему VSTS) и до сих пор занимается практическим консультированием и инфракодированием. Он уже 5 лет является обладателем премии Microsoft MVP (Самый ценный профессионал Майкрософт), а недавно получил награду MVP Azure. Как соорганизатор Melbourne Microsoft Cloud и Datacentre Meetup, О«Брайен регулярно выступает на международных конференциях, сочетая свой интерес к путешествиям по миру со страстью делиться ИТ-историями с сообществом. Блог Дэвида находится по адресу david-obrien.net, он также публикует свои онлайн-тренинги по Pluralsight.
В выступлении рассказывается о важности метрик для понимания того, что происходит в вашей среде и того, как работает ваше приложение. Microsoft Azure имеет мощный и простой способ отображения метрик для всех видов рабочих нагрузок, и в лекции говорится, как можно все их использовать.
В 3 часа ночи, в воскресенье, во время сна вас внезапно будит сигнал текстового сообщения: «сверхкритическое приложение снова не отвечает». Что же происходит? Где и в чем причина «тормозов»? Из этого доклада вы узнаете про сервисы, которые Microsoft Azure предлагает клиентам для сбора логов и, в частности, метрик ваших облачных рабочих нагрузок. Дэвид расскажет, какие метрики должны вас интересовать при работе на облачной платформе и как до них добраться. Вы узнаете об инструментах с открытым исходным кодом и построении панелей мониторинга и в результате приобретете достаточно знаний для создания своих собственных панелей.
И если вас в 3 часа ночи снова разбудит сообщение о падении критического приложения, вы сможете быстро разобраться в его причине.
Дэвид О«Брайен (Xirus): Метрики! Метрики! Метрики! Часть 1
Поскольку слайды получились бы слишком громоздкими, я предпочел демо. Рассмотрим, как можно визуализировать мониторинг, и начнем с вкладки Monitor-Metrics. Как я упоминал, это достаточно легко. Все, что нужно сделать — это указать используемый ресурс в выпадающем меню Resource group и тип ресурса в меню Resource type. В нашем случае я выбираю все 72 типа метрик.

К счастью или к несчастью, большинство облачных сервисов запускаются на виртуальных машинах, и я поступаю так же. На данной виртуальной машине по умолчанию Microsoft показывает нам метрики хоста. В частности, мы можем увидеть количество трафика, проходящего через эту VM на протяжении последних 24 часов с интервалом измерений 15 мин. Вы видите, что у нас получилась прекрасная панель мониторинга данной метрики. Это не слишком продвинутая метрика, и мы ничего не можем с ней делать, кроме как просматривать объем исходящего трафика в мегабайтах. Из инструментов здесь присутствуют: возможность добавить новое правило относительно ограничений и возможность прикрепить эту метрику к панели мониторинга.
Те, кто пользуются виртуальной машиной, должны знать, что такое Telegraf, который указан в строке RESORCE. Это open source плагин TING, написанный на языке Go, который предназначается для сбора метрик или данных из системы, на которой он установлен. Telegraf передает собранные метрики в базу данных InfluxDB. Этот кроссплатформенный плагин работает на Windows и Linux.

Как я говорил, по умолчанию монитор Microsoft Azure использует гипервизор-метрики для виртуальной машины, это указано в строке METRIC NAMESPACE. Аналогично происходит в AWS. Не могу ничего сказать про облачную платформу GSP, поскольку никогда ей не пользовался. Итак, я выбираю в качестве ресурса Telegraf и поручаю ему передавать данную метрику в Sum монитор.

Я могу перейти в список METRIC и выбрать больше отображаемых метрик. Например, сейчас я выбираю метрику usage_steal (использование перехвата). Кто-нибудь знает, что это такое?
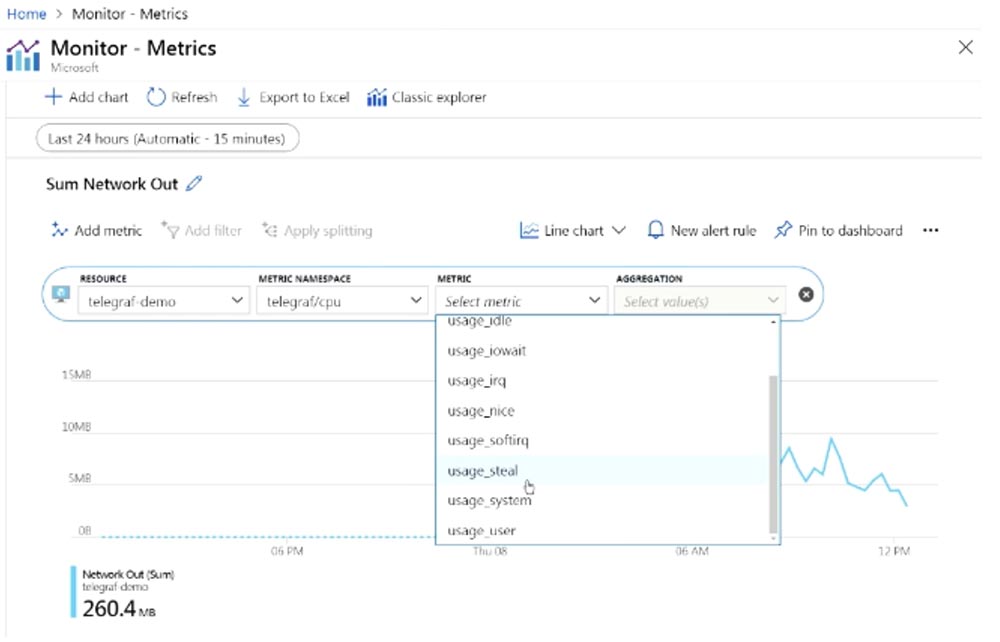
Кто из вас проживает в квартире с соседями, которые любят очень громко слушать музыку? Хорошо, так вот usage_steal это метрика, которая показывает, как соседи по облаку могут влиять на работу вашей операционной системы. Многие люди забывают о том, что запускают свои приложения в общедоступной облачной среде. И в GCP, и в AWS, и в Azure провайдеры помещают вас в общую инфраструктуру. Вы делите свою инфраструктуру — виртуальную машину, приложения, API — с остальными пользователями. Это не означает, что они имеют доступ к вашим данным, но они могут влиять на ваши приложения, и вы должны об этом знать. Если вы не будете знать о таком влиянии, то ваше приложение может испытывать определенные трудности в работе. Если вы не будете собирать метрики usage_steal, то не узнаете, что ваше приложение может пострадать от постороннего воздействия. Предположим, что вы запустили свою программу, все работает отлично, без ошибок, но вдруг что-то случается, и приложение дает сбой. Такое случается довольно часто и зависит от того, какой тип виртуальной машины вы используете, и сколько VM такого же типа ваш провайдер размещает на каждом хосте. Вполне вероятно, что ваши программы подвергнутся негативному влиянию этой инфраструктуры.
Единственный способ предотвратить подобное заключается в двух способах: первый — это подождать, пока все пройдет само собой, и второй — развернуть свою виртуальную машину на хосте другого гипервизора. Однако для принятия решения вы должны знать об этом, собирая соответствующие метрики. Как видите, при использовании метрики usage_steal монитор не показывает никакой активности, вероятно потому, что я не запустил большого количества приложений.
Итак, мы можем создать собственную панель мониторинга, разместив на ней мониторы выбранных метрик. Этой панелью можно делиться с другими пользователями, и я обычно советую своим клиентам создавать панели наподобие этой, размещая их на большом экране в офисе так, чтобы их было видно всем сотрудникам.

Каждое утро, приходя на работу, любой может глянуть на такой экран и узнать, что происходит с системой. Например, вы можете увидеть, что зафиксировано 500 ошибок HTTP-соединения и не дожидаться, пока вам сообщат об этом клиенты, а самим разобраться в причине их возникновения и исправить проблему с вашим сайтом.
Более продвинутым мониторингом является сбор перцентилей. Например, знания средних показателей работы вашего CPU может быть недостаточно, потому что разные приложения по-разному нагружают процессор.
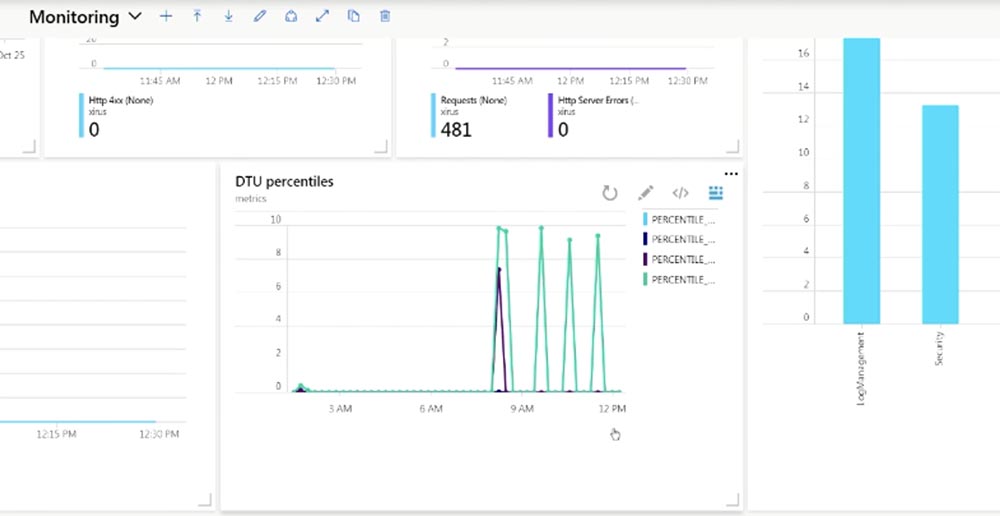
Перцентили дают вам понимание происходящего в глобальном масштабе. Предположим, что 99 перцентилей составляет 200 мс. Это означает, что 99% всех ваших запросов имеют время ответа до 200 мс, и это же означает, что 1% ваших клиентов получают ответ с задержкой, превышающей 200 мс.
В зависимости от содержания вашего SLA, вспомните, о чем мы говорили в начале, вы должны учесть это обстоятельство. В действительности чаще всего вы обращаете внимание на среднее значение, вместо того, чтобы учитывать перцентили. А среднее значение «прячет» в себе подобные отклонения.
Рассмотрим, каким путем мы получаем эти значения. Дело в том, что Azure Monitor ничего не вычисляет. Вы можете получить среднее значение, максимальное или минимальное, но если вам нужны более продвинутые показатели метрик, получаемые в результате вычислений, следует использовать анализ логов. Аналитика логов использует язык KQL, это очень полезная функция Azure «прямо из коробки».

Если посмотреть на эту метрику, можно увидеть, что провайдером ресурса служит Microsoft.SQL, сама она носит название «dtu_consumption_percent» и занимается созданием перцентилей. Это может быть не особо применимо к вашим рабочим процессам, но вам стоит знать, что модуль Log Analytics предоставляет такую возможность. Так что вы можете использовать аналитику, если нуждаетесь в более продвинутых вычислениях своих метрик. Правда, за это придется заплатить. По умолчанию данный инструмент позволяет бесплатно обрабатывать до 5 ГБ данных в месяц, однако я знаю клиентов, которые используют 5 ГБ в минуту. Так что 5 ГБ в месяц может и не хватить.
На экране вы видите метрику, показывающую, что в данный момент я использую 20 МБ. Поскольку это демонстрационная среда, объем полученных данных весьма незначителен. Как я сказал, «прямо из коробки» Logs Analytic позволяет бесплатно обработать до 5 ГБ данных в месяц, сохраняя их в течение 41 дня. За превышение этих объемом необходимо платить, однако по моему опыту, данный сервис все равно обходится дешевле, чем аналогичные продукты сторонних разработчиков, такие как Splunk или Sumo.
Перейдем к Grafana, которая имеет плагин для Azure Monitor. Он был выпущен несколько недель назад в версии 0.2. Благодаря этому плагину можно использовать Grafana для ваших метрик. Я предпочитаю разворачивать Grafana на App Services, поскольку здесь имеется возможность использовать контейнеры. Это позволяет мне запускать приложения на ноутбуке. Для этого я запускаю вот такую командную строку:

после чего быстро могу протестировать что-нибудь или показать что-то своим клиентам.
Развертывание Grafana в среде Azure также занимает одну строку, я просто разбил ее на 4, чтобы смогли увидеть это на одном экране.

В Azure присутствуют так называемые «контейнерные структуры», такие как AWS, эквивалент аналогичных структур Google. Это один контейнерный образ, который можно распространить на несколько контейнеров. Выделенная мною команда запускает Grafana одновременно с Azure Monitor. Развертывание Grafana в среде монитора занимает примерно 30 с.

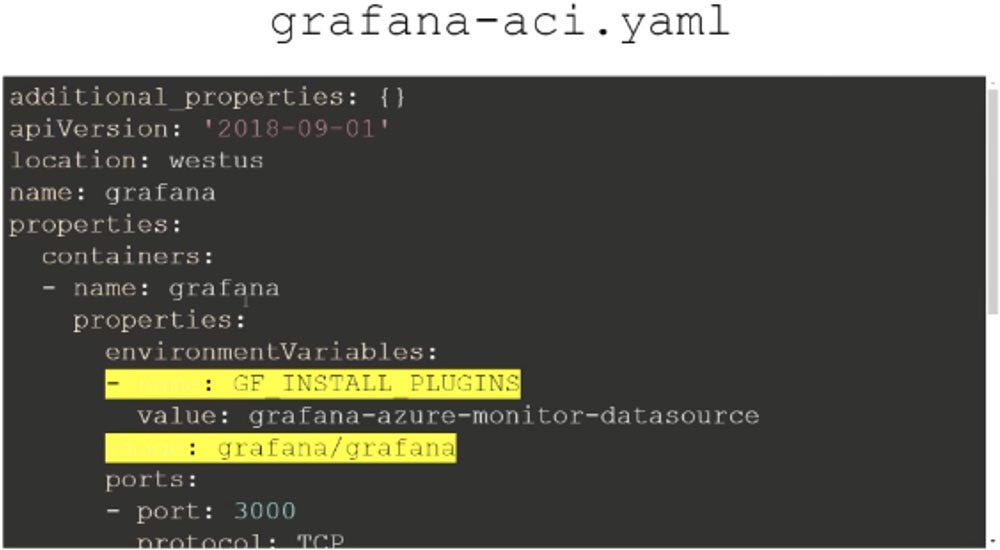
Я могу проделать тоже самое через инфраструктурный код:

Детали можно посмотреть в моем Twitter, позже я дам свои контакты. Файл с расширением .yaml указывает, каким образом использовать образ контейнера и что с ним нужно сделать. Здесь достаточно много строчек кода, и мне нужно прокрутить окно вниз, чтобы вы это увидели. Этот файл разворачивает Grafana на платформе Azure.

Итак, я захожу в Grafana на своем ноутбуке и показываю созданную мною панель мониторинга. Одну вещь, которую мне все еще не удается сделать — это передать в Grafana метрики Telegraf. К сожалению, эти полезные метрики, которые запускаются на виртуальной машине, пока что невозможно отобразить в Grafana. Microsoft занимается решением этой проблемы, и вероятно, мы увидим результат в новых версиях Telegraf и Grafana. Пока что мы можем использовать метрики гипервизора, которые Telegraf предлагает по умолчанию в выпадающем меню строки Metric. На виртуальной машине имеется возможность создавать различные пользовательские метрики, которых не хватает в Grafana, и затем вставлять их в это приложение. Это можно сделать, если пользовательскую метрику можно разместить в комплекте метрик Azure.

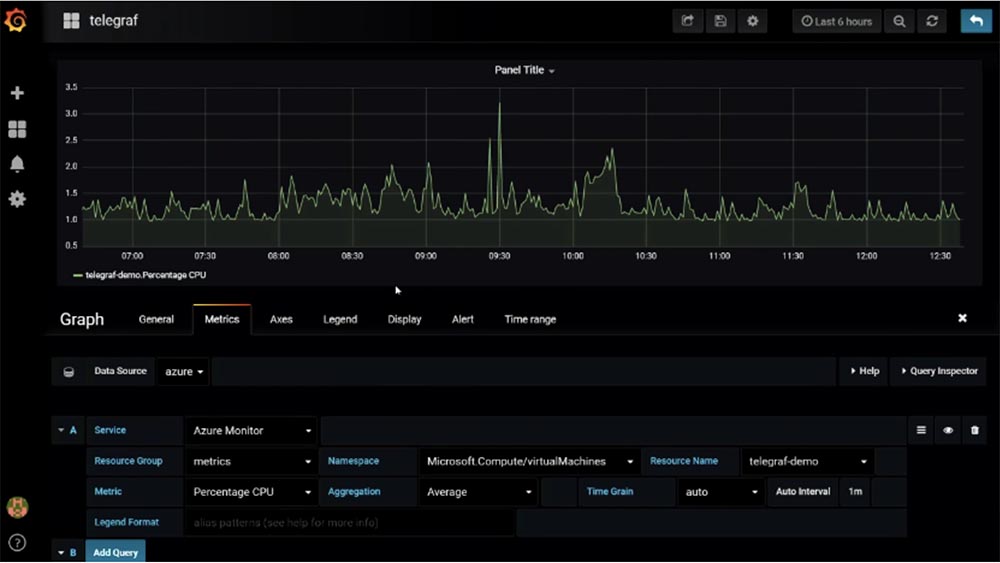
Клиенты часто спрашивают меня, что же им использовать? Grafana наглядно отображает метрики различных процессов, а Azure позволяет выполнять более сложные вычисления метрик. В последнем случае вы получаете большой набор метрик «прямо из коробки», но Azure отображает только метрики Azure. Таким образом, выбор зависит от выполняемых вами задач. Вы можете создать метрики для своего сайта, для баз данных, для развертываемых приложений, интегрировать их в Grafana и создать одну объемную информативную панель. К сожалению, вы не сможете проделать подобное с Azure, и я не думаю, что Microsoft намерен расширить функциональность Azure до такой степени.
Однако я рекомендую начинать создание своей панели мониторинга именно с Azure, потому что сегодня, работая с небольшим количеством приложений, вы уже можете работать с метриками Azure, а это лучше, чем вообще ничего не делать.
Итак, наше знакомство с метриками Azure Monitor приближается к концу, и я хочу рассказать о себе. Меня зовут Дэвид О«Брайен, и мой статус Microsoft MVP говорит о том, что я провожу много времени, рассказывая об Azure и обучая работе с этим сервисом.

У меня есть собственная компания, мы организуем учебные курсы по всему миру, рассказывая о различных продуктах Microsoft, включая облачные сервисы. Вы видите мои контакты в Twitter, где я проявляю суперактивность, ведя свой блог. Вам не нужно фотографировать этот слайд, достаточно просто запомнить адрес сайта компании Xirus. Можете задавать свои вопросы!
Вопрос: метрики очень важны, но что вы скажете по поводу менеджмента логов?
Ответ: в принципе, управление логами в Azure аналогично управлению метриками. Вы также можете разместить их в своем хранилище, затем отправить в Log Analytics и далее использовать это приложение для обработки логов аналогично метрикам. Вы можете собирать логи и хранить их вне машины, помещать в контейнеры и затем централизованно размещать в нужном месте.
Вопрос: это можно выполнять автоматически или программно?
Ответ: любым образом. Давайте вернемся к облачной оболочке Azure Cloud Shell — вы видите, что здесь в разделе метрик имеется сервис, который может представлять метрики как логи. Например, я могу создать шаблон ошибок и сказать этому сервису: «пожалуйста, разместите здесь эти логи». Во время этой демонстрации я показывал вам простые варианты работы с Azure, однако в реальных условиях работы, пожалуйста, используйте эти шаблоны. Вы можете пользоваться этим способом через интерфейс командной строки CLI или любым другим удобным способом. Если вы не хотите писать шаблоны и JSON, можете использовать открытый движок для написания шаблонов HTTL, Microsoft это позволяет.
Больше нет вопросов? Благодарю, что провели это время со мной!
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
