[Из песочницы] Большой туториал по обработке спортивных данных на python
Последние пару лет в свободное время занимаюсь триатлоном. Этот вид спорта очень популярен во многих странах мира, в особенности в США, Австралии и Европе. В настоящее время набирает стремительную популярность в России и странах СНГ. Речь идет о вовлечении любителей, не профессионалов. В отличие от просто плавания в бассейне, катания на велосипеде и пробежек по утрам, триатлон подразумевает участие в соревнованиях и системной подготовке к ним, даже не будучи профессионалом. Наверняка среди ваших знакомых уже есть по крайней мере один «железный человек» или тот, кто планирует им стать. Массовость, разнообразие дистанций и условий, три вида спорта в одном — все это располагает к образованию большого количества данных. Каждый год в мире проходит несколько сотен соревнований по триатлону, в которых участвует несколько сотен тысяч желающих. Соревнования проводятся силами нескольких организаторов. Каждый из них, естественно, публикует результаты у себя. Но для спортсменов из России и некоторых стран СНГ, команда tristats.ru собирает все результаты в одном месте — на своем одноименном сайте. Это делает очень удобным поиск результатов, как своих, так и своих друзей и соперников, или даже своих кумиров. Но для меня это дало еще и возможность сделать анализ большого количества результатов программно. Результаты опубликиваны на трилайфе: почитать.
Это был мой первый проект подобного рода, потому как лишь недавно я начал заниматься анализом данных в принципе, а также использовать python. Поэтому хочу рассказать вам о техническом исполнении этой работы, тем более что в процессе то и дело всплывали различные нюансы, требующие иногда особого подхода. Здесь будет про скраппинг, парсинг, приведение типов и форматов, восстановление неполных данных, формирование репрезентативной выборки, визуализацию, векторизацию и даже параллельные вычисления.
Объем получился большой, поэтому я разбил все на пять частей, чтобы можно было дозировать информацию и запомнить, откуда начать после перерыва.
Перед тем как двинуться дальше, лучше сначала прочитать мою статью с результатами исследования, потому как здесь по сути описана кухня по ее созданию. Это займет 10–15 минут.
Прочитали? Тогда поехали!
Часть 1. Скраппинг и парсинг
Дано: Сайт tristats.ru. На нем два вида таблиц, которые нас интересуют. Это собственно сводная таблица всех гонок и протокол результатов каждой из них.


Задачей номер один было получить эти данные программно и сохранить их для дальнейшей обработки. Так получилось, что я был на тот момент плохо знаком с веб технологиями и поэтому не знал сразу как это сделать. Начал соответственно с того, что знал — посмотреть код страницы. Это можно сделать использую правую кнопку мыши или клавишу F12.

Меню в Chrome содержит два пункта Просмотр кода страницы и Посмотреть код. Не самое очевидное разделение. Естественно, они дают разные результаты. Тот, что Посмотреть код, как раз и есть то же самое, что и F12 — непосредственно текстовое html-представление того, что отображено в браузере, поэлементно.
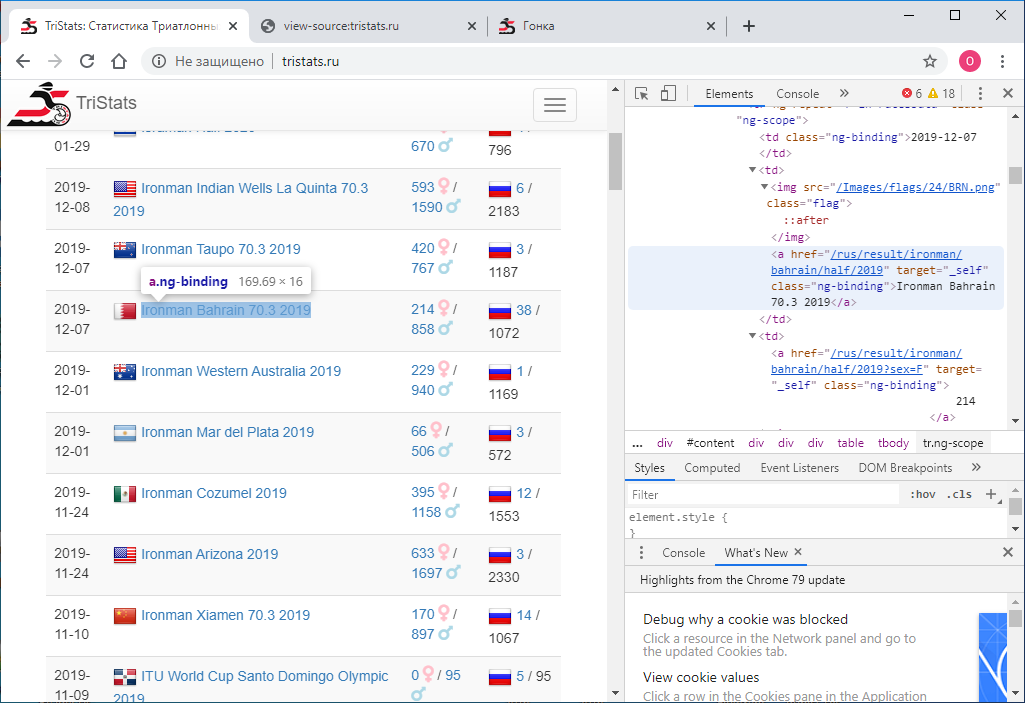
В свою очередь Просмотр кода страницы выдает исходный код страницы. Тоже html, но никаких данных там нет, только названия скриптов JS, которые их выгружают. Ну ладно.

Теперь надо понять, как с помощью python сохранить код каждой страницы в виде отдельного текстового файла. Пробую так:
import requests
r = requests.get(url='http://tristats.ru/')
print(r.content)
И получаю… исходный код. Но мне то нужен результат его исполнения. Поизучав, поискав и поспрашивав, я понял, что мне нужен инструмент для автоматизации действий браузера, например — selenium. Его я и поставил. А также ChromeDriver для работы с Google Chrome. Далее использовал его следующим образом:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
print(driver.page_source)
driver.quit()
Этот код запускает окно браузера и открывает в нем страницу по заданному url. В результате получаем html код уже с вожделенными данными. Но есть одна загвоздка. В полученном результате только 100 записей, а всего гонок почти 2000. Как же так? Дело в том, что изначально в браузере отображаются лишь первые 100 записей, и только если прокрутить до самого низа страницы, загружаются следующие 100, и так далее. Стало быть, надо реализовать прокрутку программно. Для этого воспользуемся командой:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
И при каждом прокручивании будем проверять, изменился ли код загруженной страницы или нет. Если он не изменился, для надежности проверим несколько раз, например 10, то значит страница загружена целиком и можно остановиться. Между прокрутками установим таймаут в одну секунду, чтобы страница успела загрузиться. (Даже если не успеет, у нас есть запас — еще девять секунд).
А полностью код будет выглядеть так:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
prev_html = ''
scroll_attempt = 0
while scroll_attempt < 10:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
if prev_html == driver.page_source:
scroll_attempt += 1
else:
prev_html = driver.page_source
scroll_attempt = 0
with open(r'D:\tri\summary.txt', 'w') as f:
f.write(prev_html)
driver.quit()
Итак, у нас есть html файл со сводной таблицей всех гонок. Нужно его распарсить. Для этого используем библиотеку lxml.
from lxml import html
Сначала находим все строки таблицы. Чтобы определить признак строки, просто смотрим html файл в текстовом редакторе.

Это может быть, например, «tr ng-repeat=«r in racesData» class=«ng-scope» или какой — то фрагмент, который больше не встречается ни в каких тегах.
with open(r'D:\tri\summary.txt', 'r') as f:
sum_html = f.read()
tree = html.fromstring(sum_html)
rows = tree.findall(".//*[@ng-repeat='r in racesData']")
затем заводим pandas dataframe и каждый элемент каждой строки таблица записываем в этот датафрейм.
import pandas as pd
rs = pd.DataFrame(columns=['date','name','link','males','females','rus','total'], index=range(len(rows))) #rs – races summary
Для того, чтобы разобраться, где спрятан каждый конкретный элемент, нужно просто посмотреть на html код одного из элементов наших rows в том же текстовом редакторе.
2015-04-26
 Ironman Texas 70.3 2015
Ironman Texas 70.3 2015
605
/
1539
 2
/ 2144
2
/ 2144
Здесь проще всего захардкодить навигацию по дочерним элементам, их не так много.
for i in range(len(rows)):
rs.loc[i,'date'] = rows[i].getchildren()[0].text.strip()
rs.loc[i,'name'] = rows[i].getchildren()[1].getchildren()[1].text.strip()
rs.loc[i,'link'] = rows[i].getchildren()[1].getchildren()[1].attrib['href'].strip()
rs.loc[i,'males'] = rows[i].getchildren()[2].getchildren()[2].text.strip()
rs.loc[i,'females'] = rows[i].getchildren()[2].getchildren()[0].text.strip()
rs.loc[i,'rus'] = rows[i].getchildren()[3].getchildren()[3].text.strip()
rs.loc[i,'total'] = rows[i].getchildren()[3].text_content().split('/')[1].strip()
Вот что получилось в итоге:
Сохраняем этот датафрейм в файл. Я использую pickle, но это может быть csv, или что-то еще.
import pickle as pkl
with open(r'D:\tri\summary.pkl', 'wb') as f:
pkl.dump(df,f)
На данном этапе все данные имеют строковый тип. Конвертировать будем позже. Самое главное, что нам сейчас нужно, это ссылки. Их будем использовать для скраппинга протоколов всех гонок. Делаем его по образу и подобию того, как это было сделано для сводной таблицы. В цикле по всем гонкам для каждой будем открывать страницу по ссылке, прокручивать и получать код страницы. В сводной таблице у нас есть информация по общему количеству участников в гонке — total, будем ее использовать для того, чтобы понять до какого момента нужно продолжать скроллить. Для этого будем прямо в процессе скраппинга каждой страницы определять количество записей в таблице и сравнивать его с ожидаемым значением total. Как только оно будет равно, значит мы доскроллили до конца и можно переходить к следующей гонке. Так же поставим таймаут — 60 сек. Ели за это время мы не добираемся до total, переходим к следующей гонке. Код страницы будем сохранять в файл. Будем сохранять файлы всех гонок в одной папке, а называть их по имени гонок, то есть по значению в колонке event в сводной таблице. Чтобы не было конфликта имен, нужно чтобы все гонки имели разные названия в сводной таблице. Проверим это:
df[df.duplicated(subset = 'event', keep=False)]
Что ж, в сводной таблице есть повторения, причем, даты, и количества участников (males, females, rus, total), и ссылки разные. Нужно проверить эти протоколы, здесь их немного, так что можно сделать это вручную.
Теперь все названия уникальны, запускаем большой майнинг-цикл:
service.start()
driver = webdriver.Remote(service.service_url)
timeout = 60
for index, row in df.iterrows():
try:
driver.get('http://www.tristats.ru' + row['link'])
start = time.time()
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
race_html = driver.page_source
tree = html.fromstring(race_html)
race_rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
if len(race_rows) == int(row['total']):
break
if time.time() - start > timeout:
print('timeout')
break
with open(os.path.join(r'D:\tri\races', row['event'] + '.txt'), 'w') as f:
f.write(race_html)
except:
traceback.print_exc()
time.sleep(1)
driver.quit()
Это долгий процесс. Но когда все настроено и этот тяжелый механизм начинает вращение, один за другим добавляя файлики с данными, наступает чувство приятного волнения. В минуту загружается всего примерно по три протокола, очень медленно. Оставил крутиться на ночь. На все понадобилось около 10 часов. К утру была закачана бoльшая часть протоколов. Как это обычно бывает при работе с сетью, на нескольких случился сбой. Быстро докачал их повторной попыткой.
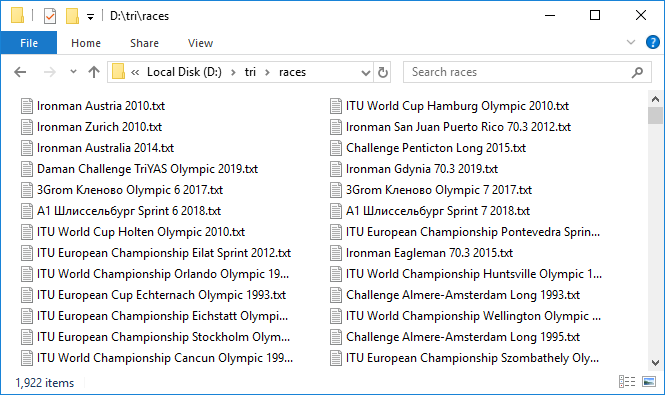
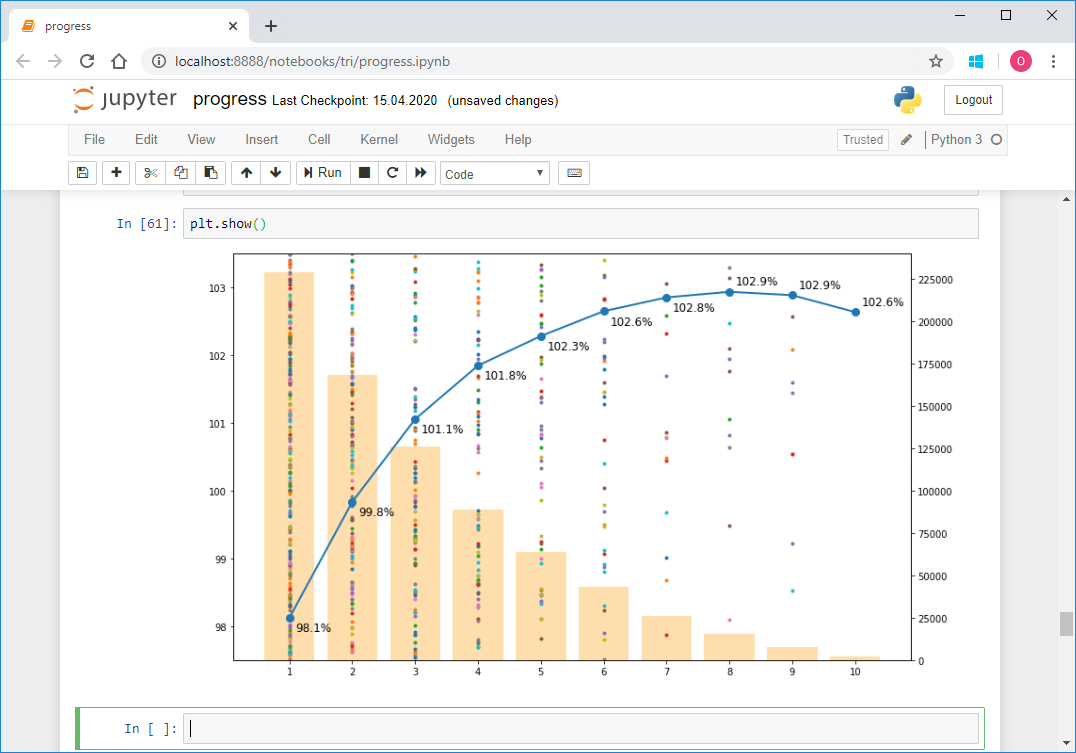
Итак, мы имеем 1 922 файла общим объемом почти 3 GB. Круто! Но обработка почти 300 гонок закончилась таймаутом. В чем же дело? Выборочно проверяем, оказывается, что действительно значение total из сводной таблицы и количество записей в протоколе гонки, которые мы проверяли, могут не совпадать. Это печально, потому что непонятно в чем причина такого расхождения. То ли это из-за того, что не все финишируют, то ли какой-то баг в базе. В общем первый сигнал о неидеальности данных. В любом случае, проверяем те, в которых количество записей равняется 100 или 0, это самые подозрительные кандидаты. Таких оказалось восемь. Закачиваем их заново под пристальным контролем. Кстати, в двух из них реально по 100 записей.
Ну что ж, все данные у нас. Переходим к парсингу. Опять же в цикле будем пробегать по каждой гонке, читать файл и сохранять содержимое в pandas DataFrame. Эти датафреймы объединим в dict, в котором ключами будут названия гонок — то есть значения event из сводной таблицы или названия файлов с html кодом страниц гонок, они совпадают.
rd = {} #rd – race details
for e in rs['event']:
place = []
... sex = [], name=..., country, group, place_in_group, swim, t1, bike, t2, run
result = []
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r')
race_html = f.read()
tree = html.fromstring(race_html)
rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
for j in range(len(rows)):
row = rows[j]
parts = row.text_content().split('\n')
parts = [r.strip() for r in parts if r.strip() != '']
place.append(parts[0])
if len([a for a in row.findall('.//i')]) > 0:
sex.append([a for a in row.findall('.//i')][0].attrib['ng-if'][10:-1])
else:
sex.append('')
name.append(parts[1])
if len(parts) > 10:
country.append(parts[2].strip())
k=0
else:
country.append('')
k=1
group.append(parts[3-k])
... place_in_group.append(...), swim.append ..., t1, bike, t2, run
result.append(parts[10-k])
race = pd.DataFrame()
race['place'] = place
... race['sex'] = sex, race['name'] = ..., 'country', 'group', 'place_in_group', 'swim', ' t1', 'bike', 't2', 'run'
race['result'] = result
rd[e] = race
with open(r'D:\tri\details.pkl', 'wb') as f:
pkl.dump(rd,f)
Помимо таблицы с результатами участников, html файл каждой гонки содержит еще и дату, название и место проведения соревнования. Дата и название уже есть в сводной таблице, а вот локации нет. Считаем эту информацию из html файлов и добавим в новую колонку в сводной таблице.
for index, row in rs.iterrows():
e = row['event']
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r') as f:
race_html = f.read()
tree = html.fromstring(race_html)
header_elem = [tb for tb in tree.findall('.//tbody') if tb.getchildren()[0].getchildren()[0].text == 'Дата'][0]
location = header_elem.getchildren()[1].getchildren()[1].text.strip()
rs.loc[index, 'loc'] = location
Сохраняем. В новый файл.
with open(r'D:\tri\summary1.pkl', 'wb') as f:
pkl.dump(df,f)
Часть 2. Приведение типов и форматирование
Итак, мы скачали все данные и поместили их в датафреймы. Однако все значения имеют тип str. Это относится и к дате, и к результатам, и к локации, и ко всем остальным параметрам. Необходимо привести все параметры к соответствующим типам.
Начнем со сводной таблицы.
Дата и время
event, loc и link оставим как есть. date конвертируем в pandas datetime следующим образом:
rs['date'] = pd.to_datetime(rs['date'])
Остальные приводим к целочисленному типу:
cols = ['males', 'females', 'rus', 'total']
rs[cols] = rs[cols].astype(int)
Все прошло гладко, никаких ошибок не возникло. Значит все OK — cохраняемся:
with open(r'D:\tri\summary2.pkl', 'wb') as f:
pkl.dump(rs, f)
Теперь датафреймы гонок. Поскольку все гонки удобнее и быстрее обрабатывать разом, а не по одной, соберем их в один большой датафрейм ar (сокращение от all records) с помощью метода concat.
ar = pd.concat(rd)
ar содержит 1 416 365 записей.
Теперь конвертируем place и place in group в целочисленное значение.
ar[['place', 'place in group']] = ar[['place', 'place in group']].astype(int))
Далее, обработаем колонки с временными значениями. Будем приводить их в типу Timedelta из pandas. Но чтобы конвертация прошла успешно, нужно правильно подготовить данные. Можно видеть, что некоторые значения, которые меньше часа идут без указания того самого часка.
Нужно его добавить.
for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
strlen = ar[col].str.len()
ar.loc[strlen==5, col] = '0:' + ar.loc[strlen==5, col]
ar.loc[strlen==4, col] = '0:0' + ar.loc[strlen==4, col]
Теперь времена, все еще оставаясь строками, выглядят так:
Конвертируем в Timedelta:
for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
ar[col] = pd.to_timedelta(ar[col])
Пол
Идем дальше. Проверим что в колонке sex есть только значения M и F:
ar['sex'].unique()
Out: ['M', 'F', '']
На самом деле там еще пустая строка, то есть пол не указан. Посмотрим сколько таких случаев:
len(ar[ar['sex'] == ''])
Out: 2538
Не так много — хорошо. В дальнейшем мы попытаемся еще уменьшить это значение. А пока оставим колонку sex как есть в виде строк. Сохраним результат, перед тем как перейти к более серьезным и рискованным преобразованиям. Для того, чтобы сохранять преемственность между файлами, преобразуем объединенный датафрейм ar обратно в словарь датафреймов rd:
for event in ar.index.get_level_values(0).unique():
rd[event] = ar.loc[event]
with open(r'D:\tri\details1.pkl', 'wb') as f:
pkl.dump(rd,f)
Кстати, за счет преобразования типов некоторых колонок размеры файлов уменьшились с 367 KB до 295 KB для сводной таблицы и с 251 MB до 168 MB для протоколов гонок.
Код страны
Теперь посмотрим страну.
ar['country'].unique()
Out: ['CRO', 'CZE', 'SLO', 'SRB', 'BUL', 'SVK', 'SWE', 'BIH', 'POL', 'MK', 'ROU', 'GRE', 'FRA', 'HUN', 'NOR', 'AUT', 'MNE', 'GBR', 'RUS', 'UAE', 'USA', 'GER', 'URU', 'CRC', 'ITA', 'DEN', 'TUR', 'SUI', 'MEX', 'BLR', 'EST', 'NED', 'AUS', 'BGI', 'BEL', 'ESP', 'POR', 'UKR', 'CAN', 'IRL', 'JPN', 'HKG', 'JEY', 'SGP', 'BRA', 'QAT', 'LUX', 'RSA', 'NZL', 'LAT', 'PHI', 'KSA', 'SEY', 'MAS', 'OMA', 'ARG', 'ECU', 'THA', 'JOR', 'BRN', 'CIV', 'FIN', 'IRN', 'BER', 'LBA', 'KUW', 'LTU', 'SRI', 'HON', 'INA', 'LBN', 'PAN', 'EGY', 'MLT', 'WAL', 'ISL', 'CYP', 'DOM', 'IND', 'VIE', 'MRI', 'AZE', 'MLD', 'LIE', 'VEN', 'ALG', 'SYR', 'MAR', 'KZK', 'PER', 'COL', 'IRQ', 'PAK', 'CZK', 'KAZ', 'CHN', 'NEP', 'ISR', 'MKD', 'FRO', 'BAN', 'ARU', 'CPV', 'ALB', 'BIZ', 'TPE', 'KGZ', 'BNN', 'CUB', 'SNG', 'VTN', 'THI', 'PRG', 'KOR', 'RE', 'TW', 'VN', 'MOL', 'FRE', 'AND', 'MDV', 'GUA', 'MON', 'ARM', 'F.I.TRI.', 'BAHREIN', 'SUECIA', 'REPUBLICA CHECA', 'BRASIL', 'CHI', 'MDA', 'TUN', 'NDL', 'Danish(Dane)', 'Welsh', 'Austrian', 'Unknown', 'AFG', 'Argentinean', 'Pitcairn', 'South African', 'Greenland', 'ESTADOS UNIDOS', 'LUXEMBURGO', 'SUDAFRICA', 'NUEVA ZELANDA', 'RUMANIA', 'PM', 'BAH', 'LTV', 'ESA', 'LAB', 'GIB', 'GUT', 'SAR', 'ita', 'aut', 'ger', 'esp', 'gbr', 'hun', 'den', 'usa', 'sui', 'slo', 'cze', 'svk', 'fra', 'fin', 'isr', 'irn', 'irl', 'bel', 'ned', 'sco', 'pol', 'SMR', 'mex', 'STEEL T BG', 'KINO MANA', 'IVB', 'TCH', 'SCO', 'KEN', 'BAS', 'ZIM', 'Joe', 'PUR', 'SWZ', 'Mark', 'WLS', 'MYA', 'BOT', 'REU', 'NAM', 'NCL', 'BOL', 'GGY', 'ISV', 'TWN', 'GUM', 'FIJ', 'COK', 'NGR', 'IRI', 'GAB', 'ANT', 'GEO', 'COG', 'sue', 'SUD', 'BAR', 'CAY', 'BO', 'VE', 'AX', 'MD', 'PAR', 'UM', 'SEN', 'NIG', 'RWA', 'YEM', 'PLE', 'GHA', 'ITU', 'UZB', 'MGL', 'MAC', 'DMA', 'TAH', 'TTO', 'AHO', 'JAM', 'SKN', 'GRN', 'PRK', 'NFK', 'SOL', 'Sandy', 'SAM', 'PNG', 'SGS', 'Suchy, Jorg', 'SOG', 'GEQ', 'BVT', 'DJI', 'CHA', 'ANG', 'YUG', 'IOT', 'HAI', 'SJM', 'CUW', 'BHU', 'ERI', 'FLK', 'HMD', 'GUF', 'ESH', 'sandy', 'UMI', 'selsmark, 'Alise', 'Eddie', '31/3, Colin', 'CC', 'Индия', 'Ирландия', 'Армения', 'Болгария', 'Сербия', 'Республика Беларусь', 'Великобритания', 'Франция', 'Гондурас', 'Коста-Рика', 'Азербайджан', 'GRL', 'UGA', 'VAT', 'ETH', 'ASA', 'PYF', 'ATA', 'ALA', 'MTQ', 'ZZ', 'CXR', 'AIA', 'TJK', 'GUY', 'KR', 'PF', 'BN', 'MO', 'LA', 'CAM', 'NCA', 'ZAM', 'MAD', 'TOG', 'VIR', 'ATF', 'VAN', 'SLE', 'GLP', 'SCG', 'LAO', 'IMN', 'BUR', 'IR', 'SY', 'CMR', 'GBS', 'SUR', 'MOZ', 'BLM', 'MSR', 'CAF', 'BEN', 'COD', 'CCK', 'TUV', 'TGA', 'GI', 'XKX', 'NRU', 'NC', 'LBR', 'TAN', 'VIN', 'SSD', 'GP', 'PS', 'IM', 'JE', '', 'MLI', 'FSM', 'LCA', 'GMB', 'MHL', 'NH', 'FL', 'CT', 'UT', 'AQ', 'Korea', 'Taiwan', 'NewCaledonia', 'Czech Republic', 'PLW', 'BRU', 'RUN', 'NIU', 'KIR', 'SOM', 'TKM', 'SPM', 'BDI', 'COM', 'TCA', 'SHN', 'DO2', 'DCF', 'PCN', 'MNP', 'MYT', 'SXM', 'MAF', 'GUI', 'AN', 'Slovak republic', 'Channel Islands', 'Reunion', 'Wales', 'Scotland', 'ica', 'WLF', 'D', 'F', 'I', 'B', 'L', 'E', 'A', 'S', 'N', 'H', 'R', 'NU', 'BES', 'Bavaria', 'TLS', 'J', 'TKL', 'Tirol"', 'P', '?????', 'EU', 'ES-IB', 'ES-CT', 'КГЫ', 'SOO', 'LZE', 'Могилёв', 'Гомель', 'Минск', 'Самара', 'Гродно', 'Москва']
412 уникальных значений.
В основном страна обозначается трехзначным буквенным кодом в верхнем регистре. Но как видно, далеко не всегда. На самом деле существует международный стандарт ISO 3166, в котором для всех стран, включая даже те, которых уже не существует, прописаны соответствующие трехзначные и двузначные коды. Для python одну из реализаций этого стандарта можно найти в пакете pycountry. Вот как он работает:
import pycountry as pyco
pyco.countries.get(alpha_3 = 'RUS')
Out: Country(alpha_2='RU', alpha_3='RUS', name='Russian Federation', numeric='643')
Таким образом проверим все трехзначные коды, приведя к верхнему регистру, которые дают отклик в countries.get (…) и historic_countries.get (…):
valid_a3 = [c for c in ar['country'].unique() if pyco.countries.get(alpha_3 = c.upper()) != None or pyco.historic_countries.get(alpha_3 = c.upper()) != None])
Таких оказалось 190 из 412. То есть меньше половины.
Для остальных 222 (их список обозначим tofix) сделаем словарь соответствия fix, в котором ключом будет оригинальное название, а значением трехзначный код по стандарту ISO.
tofix = list(set(ar['country'].unique()) - set(valid_a3))
В первую очередь проверим двузначные коды с помощью pycountry.countries.get (alpha_2 = …), приведя к верхнему регистру:
for icc in tofix: #icc -invalid country code
if pyco.countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.countries.get(alpha_2 = icc.upper()).alpha_3
else:
if pyco.historic_countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.historic_countries.get(alpha_2 = icc.upper()).alpha_3
Затем полные имена через pycountry.countries.get (name = …), pycountry.countries.get (common_name = …), приведя их к форме str.title ():
for icc in tofix:
if pyco.countries.get(common_name = icc.title()) != None:
fix[icc] = pyco.countries.get(common_name = icc.title()).alpha_3
else:
if pyco.countries.get(name = icc.title()) != None:
fix[icc] = pyco.countries.get(name = icc.title()).alpha_3
else:
if pyco.historic_countries.get(name = icc.title()) != None:
fix[icc] = pyco.historic_countries.get(name = icc.title()).alpha_3
Таким образом сокращаем число нераспознанных значений до 190. Все еще достаточно много: ['URU', '', 'PAR', 'SUECIA', 'KUW', 'South African', 'Гомель', 'Austrian', 'ISV', 'H', 'SCO', 'ES-CT', Гондурас', 'GUI', 'BOT', 'SEY', 'BIZ', 'LAB', 'PUR', 'Республика Беларусь', 'Scotland', 'Азербайджан', 'Минск', 'TCH', 'TGA', 'UT', 'BAH', 'GEQ', 'NEP', 'TAH', 'ica', 'FRE', 'E', 'TOG', 'MYA', 'Болгария', 'Danish (Dane)', 'SAM', 'TPE', 'MON', 'ger', 'Unknown', 'sui', 'R', 'SUI', 'A', 'GRN', 'KZK', 'Wales', 'Москва', 'GBS', 'ESA', 'Bavaria', 'Czech Republic', '31/3, Colin', 'SOL', 'SKN', 'Франция', 'MGL', 'XKX', 'WLS', 'MOL', 'FIJ', 'CAY', 'ES-IB', 'BER', 'PLE', 'MRI', 'B', 'KSA', 'Великобритания', 'Гродно', 'LAT', 'GRE', 'ARU', 'КГЫ', 'THI', 'NGR', 'MAD', 'SOG', 'MLD', '?????', 'AHO', 'sco', 'UAE', 'RUMANIA', 'CRO', 'RSA', 'NUEVA ZELANDA', 'KINO MANA', 'PHI', 'sue', 'Tirol"', 'IRI', 'POR', 'CZK', 'SAR', 'D', 'BRASIL', 'DCF', 'HAI', 'ned', 'N', 'BAHREIN', 'VTN', 'EU', 'CAM', 'Mark', 'BUL', 'Welsh', 'VIN', 'HON', 'ESTADOS UNIDOS', 'I', 'GUA', 'OMA', 'CRC', 'PRG', 'NIG', 'BHU', 'Joe', 'GER', 'RUN', 'ALG', 'Сербия', 'Channel Islands', 'Reunion', 'REPUBLICA CHECA', 'slo', 'ANG', 'NewCaledonia', 'GUT', 'VIE', 'ASA', 'BAR', 'SRI', 'L', 'Могилёв', 'J', 'BAS', 'LUXEMBURGO', 'S', 'CHI', 'SNG', 'BNN', 'den', 'F.I.TRI.', 'STEEL T BG', 'NCA', 'Slovak republic', 'MAS', 'LZE', 'Коста-Рика', 'F', 'BRU', 'Армения', 'LBA', 'NDL', 'DEN', 'IVB', 'BAN', 'Sandy', 'ZAM', 'sandy', 'Korea', 'SOO', 'BGI', 'Индия', 'LTV', 'selsmark, Alise', 'TAN', 'NED', 'Самара', 'Suchy, Jorg', 'SLO', 'SUDAFRICA', 'ZIM', 'Eddie', 'INA', 'Ирландия', 'SUD', 'VAN', 'FL', 'P', 'ITU', 'ZZ', 'Argentinean', 'CHA', 'DO2', 'WAL']
Можно заметить, что среди них все еще много трехзначных кодов, но это не ISO. Что же тогда? Оказывается, что существует еще один стандарт — олимпийский. К сожалению, его реализация не включена в pycountry и приходится искать что-то еще. Решение нашлось в виде csv файла на datahub.io. Поместим содержимое этого файла в pandas DataFrame под названием cdf.
ioc — Intenational Olympic Committee (IOC)
len(([x for x in tofix if x.upper() in list(cdf['ioc'])]))
Out: 82
Среди трехзначных кодов из tofix нашлось 82 соответствующих IOC. Добавим их в наш словарь соответствия.
for icc in tofix:
if icc.upper() in list(cdf['ioc']):
ind = cdf[cdf['ioc'] == icc.upper()].index[0]
fix[icc] = cdf.loc[ind, 'iso3']
Осталось 108 необработанных значений. Их добиваем вручную, иногда обращаясь за помощью в Google. {'BGI': 'BRB', 'WAL': 'GBR', 'MLD': 'MDA', 'KZK': 'KAZ', 'CZK': 'CZE', 'BNN': 'BEN', 'SNG': 'SGP', 'VTN': 'VNM', 'THI': 'THA', 'PRG': 'PRT', 'MOL': 'MDA', 'FRE': 'FRA', 'F.I.TRI.': 'ITA', 'BAHREIN': 'BHR', 'SUECIA': 'SWE', 'REPUBLICA CHECA': 'CZE', 'BRASIL': 'BRA', 'NDL': 'NLD', 'Danish (Dane)': 'DNK', 'Welsh': 'GBR', 'Austrian': 'AUT', 'Argentinean': 'ARG', 'South African': 'ZAF', 'ESTADOS UNIDOS': 'USA', 'LUXEMBURGO': 'LUX', 'SUDAFRICA': 'ZAF', 'NUEVA ZELANDA': 'NZL', 'RUMANIA': 'ROU', 'sco': 'GBR', 'SCO': 'GBR', 'WLS': 'GBR', 'Индия': 'IND', 'Ирландия': 'IRL', 'Армения': 'ARM', 'Болгария': 'BGR', 'Сербия': 'SRB', 'Республика Беларусь': 'BLR', 'Великобритания': 'GBR', 'Франция': 'FRA', 'Гондурас': 'HND', 'Коста-Рика': 'CRI', 'Азербайджан': 'AZE', 'Korea': 'KOR', 'NewCaledonia': 'FRA', 'Czech Republic': 'CZE', 'Slovak republic': 'SVK', 'Channel Islands': 'FRA', 'Reunion': 'FRA', 'Wales': 'GBR', 'Scotland': 'GBR', 'Bavaria': 'DEU', 'Tirol"': 'AUT', 'КГЫ': 'KGZ', 'Могилёв': 'BLR', 'Гомель': 'BLR', 'Минск': 'BLR', 'Самара': 'RUS', 'Гродно': 'BLR', 'Москва': 'RUS'}
Но даже ручное управление не решает проблему полностью. Остается 49 значений, которые уже невозможно интерпретировать. Вероятно, большая часть из этих значений — просто ошибки в данных.
unfixed = [x for x in tofix if x not in fix.keys()]
Out: ['', 'H', 'ES-CT', 'LAB', 'TCH', 'UT', 'TAH', 'ica', 'E', 'Unknown', 'R', 'A', '31/3, Colin', 'XKX', 'ES-IB','B','SOG','?????','KINO MANA','sue','SAR','D', 'DCF', 'N', 'EU', 'Mark', 'I', 'Joe', 'RUN', 'GUT', 'L', 'J', 'BAS', 'S', 'STEEL T BG', 'LZE', 'F', 'Sandy', 'DO2', 'sandy', 'SOO', 'LTV', 'selsmark, Alise', 'Suchy, Jorg' 'Eddie', 'FL', 'P', 'ITU', 'ZZ']
У этих ключей в словаре соответствия значением будет пустая строка.
for cc in unfixed:
fix[cc] = ''
Напоследок добавим в словарь соответствия коды, которые являются валидными, но записаны в нижнем регистре.
for cc in valid_a3:
if cc.upper() != cc:
fix[cc] = cc.upper()
Теперь пришло время применить найденные замены. Чтобы сохранить начальные данные для дальнейшего сравнения копируем колонку country в country raw. Затем используя созданный словарь соответствия исправляем в колонке country значения, которые не соответствуют ISO.
for cc in fix:
ind = ar[ar['country'] == cc].index
ar.loc[ind,'country'] = fix[cc]
Здесь, конечно, не обойтись без векторизации, в таблице почти полтора миллиона строк. Но по словарю делаем цикл, а как иначе? Проверяем, сколько записей изменено:
len(ar[ar['country'] != ar['country raw']])
Out: 315955
то есть более 20% от общего количества.
ar[ar['country'] != ar['country raw']].sample(10)
len(ar[ar['country'] == ''])
Out: 3221
Таково количество записей без страны или со страной неформата. Количество уникальных стран сократилось с 412 до 250. Вот они: ['', 'ABW', 'AFG', 'AGO', 'AIA', 'ALA', 'ALB', 'AND', 'ANT', 'ARE', 'ARG', 'ARM', 'ASM', 'ATA', 'ATF', 'AUS', 'AUT', 'AZE', 'BDI', 'BEL', 'BEN', 'BES', 'BGD', 'BGR', 'BHR', 'BHS', 'BIH', 'BLM', 'BLR', 'BLZ', 'BMU', 'BOL', 'BRA', 'BRB', 'BRN', 'BTN', 'BUR', 'BVT', 'BWA', 'CAF', 'CAN', 'CCK', 'CHE', 'CHL', 'CHN', 'CIV', 'CMR', 'COD', 'COG', 'COK', 'COL', 'COM', 'CPV', 'CRI', 'CTE', 'CUB', 'CUW', 'CXR', 'CYM', 'CYP', 'CZE', 'DEU', 'DJI', 'DMA', 'DNK', 'DOM', 'DZA', 'ECU', 'EGY', 'ERI', 'ESH', 'ESP', 'EST', 'ETH', 'FIN', 'FJI', 'FLK', 'FRA', 'FRO', 'FSM', 'GAB', 'GBR', 'GEO', 'GGY', 'GHA', 'GIB', 'GIN', 'GLP', 'GMB', 'GNB', 'GNQ', 'GRC', 'GRD', 'GRL', 'GTM', 'GUF', 'GUM', 'GUY', 'HKG', 'HMD', 'HND', 'HRV', 'HTI', 'HUN', 'IDN', 'IMN', 'IND', 'IOT', 'IRL', 'IRN', 'IRQ', 'ISL', 'ISR', 'ITA', 'JAM', 'JEY', 'JOR', 'JPN', 'KAZ', 'KEN', 'KGZ', 'KHM', 'KIR', 'KNA', 'KOR', 'KWT', 'LAO', 'LBN', 'LBR', 'LBY', 'LCA', 'LIE', 'LKA', 'LTU', 'LUX', 'LVA', 'MAC', 'MAF', 'MAR', 'MCO', 'MDA', 'MDG', 'MDV', 'MEX', 'MHL', 'MKD', 'MLI', 'MLT', 'MMR', 'MNE', 'MNG', 'MNP', 'MOZ', 'MSR', 'MTQ', 'MUS', 'MYS', 'MYT', 'NAM', 'NCL', 'NER', 'NFK', 'NGA', 'NHB', 'NIC', 'NIU', 'NLD', 'NOR', 'NPL', 'NRU', 'NZL', 'OMN', 'PAK', 'PAN', 'PCN', 'PER', 'PHL', 'PLW', 'PNG', 'POL', 'PRI', 'PRK', 'PRT', 'PRY', 'PSE', 'PYF', 'QAT', 'REU', 'ROU', 'RUS', 'RWA', 'SAU', 'SCG', 'SDN', 'SEN', 'SGP', 'SGS', 'SHN', 'SJM', 'SLB', 'SLE', 'SLV', 'SMR', 'SOM', 'SPM', 'SRB', 'SSD', 'SUR', 'SVK', 'SVN', 'SWE', 'SWZ', 'SXM', 'SYC', 'SYR', 'TCA', 'TCD', 'TGO', 'THA', 'TJK', 'TKL', 'TKM', 'TLS', 'TON', 'TTO', 'TUN', 'TUR', 'TUV', 'TWN', 'TZA', 'UGA', 'UKR', 'UMI', 'URY', 'USA', 'UZB', 'VAT', 'VCT', 'VEN', 'VGB', 'VIR', 'VNM', 'VUT', 'WLF', 'WSM', 'YEM', 'YUG', 'ZAF', 'ZMB', 'ZWE']
Теперь никаких отклонений. Сохраняем результат в новый файл details2.pkl, предварительно преобразовав объединенный датафрейм обратно в словарь датафреймов, как это было сделано ранее.
Локация
Теперь вспомним, что упоминание о странах также есть и в сводной таблице, в колонке loc.
Его тоже нужно привести к стандартному виду. Здесь немного другая история: не видно ни ISO, ни олимпийских кодов. Все описано в достаточно свободной форме. Через запятую перечислены город, страна и другие составляющие адреса, причем в произвольном порядке. Где-то страна на первом месте, где-то на последнем. pycountry тут уже не поможет. А записей много — на 1922 гонки 525 уникальных локаций (в исходном виде).
Но и тут нашелся подходящий инструмент. Это geopy, а именно geolocator Nominatim. Работает вот так:
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent='triathlon results researcher')
geolocator.geocode('Бирюзовая Катунь, Алтай, Россия', language='en')
Out: Location(Бирюзовая Катунь, Ая – Бирюзовая Катунь, Айский сельсовет, Altaysky District, Altai Krai, Siberian Federal District, Russia, (51.78897945, 85.73956296106752, 0.0))
По запросу в произвольной форме выдает структурированный ответ — адрес и координаты. Если задать язык, как здесь — английский, то что сможет — переведет. Нам в первую очередь нужно стандартное название страны для последующего перевода в код ISO. Оно как раз стоит на последнем месте в свойстве address. Поскольку geolocator каждый раз отправляет запрос на сервер, процесс этот не быстрый и для 500 записей занимает несколько минут. К тому же бывает, что ответ не приходит. В этом случае иногда помогает повторный запрос. В моем с первого раза ответ не пришел на 130 запросов. Большую часть из них удалось обработать двумя повторными попытками. Однако 34 названия обработать не так и не удалось даже несколькими дальнейшими повторными попытками. Вот они: ['Tongyeong, Korea, Korea, South', 'Constanta, Mamaia, Romania, Romania', 'Weihai, China, China', 'д. Толвинка, Брянская обл.', 'Odaiba Marin Park, Tokyo, Japan, Japan', 'Sweden, Smaland, Kalmar', 'Cholpon-Ata city, Resort Center "Kapriz", Kyrgyzstan', 'Luxembourg, Region Moselle, Moselle', 'Chita Peninsula, Japan', 'Kraichgau Region, Germany', 'Jintang, Chengdu, Sichuan Province, China, China', 'Madrid, Spain, Spain', 'North American Pro Championship, St. George, Utah, USA', 'Milan Idroscalo Linate, Italy', 'Dexing, Jiangxi Province, China, China', 'Mooloolaba, Australia, Australia', 'Nathan Benderson Park (NBP), 5851 Nathan Benderson Circle, Sarasota, FL 34235., United States', 'Strathclyde Country Park, North Lanarkshire, Glasgow, Great Britain', 'Quijing, China', 'United States of America , Hawaii, Kohala Coast', 'Buffalo City, East London, South Africa', 'Spain, Vall de Cardener', 'Россия, пос. Метлино Озерский городской округ', 'Asian TriClub Championship, Hefei, China', 'Taizhou, Jiangsu Province, China, China', 'Россия, Москва, СЦП «Крылатское»', 'Buffalo, Gallagher Beach, Furhmann Blvd, United States', 'North American Pro Championship | St. George, Utah, USA', 'Weihai, Shandong, China, China', 'Tarzo - Revine Lago, Italy', 'Lausanee, Switzerland', 'Queenstown, New Zealand, New Zealand', 'Makuhari, Japan, Japan', 'Szombathlely, Hungary']
Видно, что во многих присутствует двойное упоминание страны, и это на самом деле мешает. В общем пришлось вручную обработать эти оставшиеся названия и для всех были получены стандартные адреса. Далее из этих адресов я выделил страну и записал эту страну в новую колонку в сводной таблице. Поскольку, как я уже сказал работа с geopy не быстрая, я решил сразу сохранить координаты локации — широту и долготу. Они пригодятся позже для визуализации на карте.
После этого с помощью pyco.countries.get (name = »…»).alpha_3 искал страну по названию и выделял трехзначный код.
Дистанция
Еще одно важное действие, которое нужно сделать на сводной таблице — для каждой гонки определить дистанцию. Это пригодится нам для вычисления скоростей в дальнейшем. В триатлоне существует четыре основных дистанции — спринт, олимпийская, полужелезная и железная. Можно видеть, что в названиях гонок как правило есть указание на дистанцию — это Слова Sprint, Olympic, Half, Full. Помимо этого, у разных организаторов свои обозначения дистанций. Половинка у Ironman, например, обозначается как 70.3 — по количеству миль в дистанции, олимпийская — 5150 по числу километров (51.5), а железная может обозначаться как Full или, вообще, как отсутствие пояснений — например Ironman Arizona 2019. Ironman — он и есть железный! У Challenge железная дистанция обозначается как Long, а полужелезная — как Middle. Наш российский IronStar обозначает полную как 226, а половинку как 113 — по числу километров, но обычно слова Full и Half тоже присутствуют. Теперь применим все эти знания и пометим все гонки в соответствии с ключевыми словами, присутствующими в названиях.
sprints = rs.loc[[i for i in rs.index if 'sprint' in rs.loc[i, 'event'].lower()]]
olympics1 = rs.loc[[i for i in rs.index if 'olympic' in rs.loc[i, 'event'].lower()]]
olympics2 = rs.loc[[i for i in rs.index if '5150' in rs.loc[i, 'event'].lower()]]
olympics = pd.concat([olympics1, olympics2])
#… и так далее
rsd = pd.concat([sprints, olympics, halfs, fulls])
В rsd получилось 1 925 записей, то есть на три больше, чем общее число гонок, значит какие-то попали под два критерия. Посмотрим на них:
rsd[rsd.duplicated(keep=False)]['event'].sort_index()
Действительно, так и есть. В первой паре в названии Temiradam 113 Half 2019 есть упоминание и Half и 113. Но это не противоречие, они оба идентифицировались как половинки. Далее — Triway Olympic Sprint 2019. Здесь действительно можно запутаться — есть и Olympic и Sprint. Разобраться можно, посмотрев на протокол с результатами гонки.
Лучшее время — 1:09. Значит это спринт. Удалим эту запись из списка олимпийских.
olympics.drop(65)
Точно так же поступим с пересекающимися Ironman Dun Laoghaire Full Swim 70.3 2019
Здесь лучшее время 4:00. Это характерно для половинки. Удаляем запись с индексом 85 из fulls.
fulls.drop(85)
Теперь запишем информацию о дистанции в основной датафрейм и посмотрим, что получилось:
rs['dist'] = ''
rs.loc[sprints.index,'dist'] = 'sprint'
rs.loc[olympics.index,'dist'] = 'olympic'
rs.loc[halfs.index,'dist'] = 'half'
rs.loc[fulls.index,'dist'] = 'full'
rs.sample(10)
Проверим, что не осталось непокрытых записей:
len(rs[rs['dist'] == ''])
Out: 0
И проверим наши проблемные, двусмысленные:
rs.loc[[38,65,82],['event','dist']]
Все нормально. Сохраняем в новый файл:
pkl.dump(rs, open(r'D:\tri\summary5.pkl', 'wb'))
Возрастные группы
Теперь вернемся к протоколам гонок.
Мы уже проанализировали пол, страну и результаты участника, и привели их к стандартному виду. Но еще остались еще две графы — группа и, собственно, само имя. Начнем с групп. В триатлоне принято делить участников по возрастным группам. Также часто выделяется группа профессионалов. По сути, зачет идет в каждой такой группе отдельно — награждаются первые три места в каждой группе. По группам же идет квалификационный отбор на чемпионаты, например, на Кону.
Объединим все записи и посмотрим какие вообще группы существуют.
rd = pkl.load(open(r'D:\tri\details2.pkl', 'rb'))
ar = pd.concat(rd)
ar['group'].unique()
Оказалось, что групп огромное количество — 581. Сотня случайно выбранных выглядит так: ['MSenior', 'FAmat.', 'M20', 'M65-59', 'F25-29', 'F18-22', 'M75-59', 'MPro', 'F24', 'MCORP M', 'F21-30', 'MSenior 4', 'M40-50', 'FAWAD', 'M16-29', 'MK40-49', 'F65-70', 'F65-70', 'M12-15', 'MK18-29', 'MМ50up', 'FSEMIFINAL 2 PRO', 'F16', 'MWhite', 'MOpen 25-29', 'FПараатлет', 'MPT TRI-2', 'M16-24', 'FQUALIFIER 1 PRO', 'F15-17', 'FSEMIFINAL 2 JUNIOR', 'FOpen 60-64', 'M75-80', 'F60-69', 'FJUNIOR A', 'F17-18', 'FAWAD BLIND', 'M75-79', 'M18-29', 'MJUN19-23', 'M60-up', 'M70', 'MPTS5', 'F35-40', "M'S PT1", 'M50-54', 'F65-69', 'F17-20', 'MP4', 'M16-29', 'F18up', 'MJU', 'MPT4', 'MPT TRI-3', 'MU24-39', 'MK35-39', 'F18-20', "M'S", 'F50-55', 'M75-80', 'MXTRI', 'F40-45', 'MJUNIOR B', 'F15', 'F18-19', 'M20-29', 'MAWAD PC4', 'M30-37', 'F21-30', 'Mpro', 'MSEMIFINAL 1 JUNIOR', 'M25-34', 'MAmat.', 'FAWAD PC5', 'FA', 'F50-60', 'FSenior 1', 'M80-84', 'FK45-49', 'F75-79', 'M<23', 'MPTS3', 'M70-75', 'M50-60', 'FQUALIFIER 3 PRO', 'M9', 'F31-40', 'MJUN16-19', 'F18-19', 'M PARA', 'F35-44', 'MParaathlete', 'F18-34', 'FA', 'FAWAD PC2', 'FAll Ages', 'M PARA', 'F31-40', 'MM85', 'M25-39']
Посмотрим какие из них самые многочисленные:
ar['group'].value_counts()[:30]
Out:
M40-44 199157
M35-39 183738
M45-49 166796
M30-34 154732
M50-54 107307
M25-29 88980
M55-59 50659
F40-44 48036
F35-39 47414
F30-34 45838
F45-49 39618
MPRO 38445
F25-29 31718
F50-54 26253
M18-24 24534
FPRO 23810
M60-64 20773
M 12799
F55-59 12470
M65-69 8039
F18-24 7772
MJUNIOR 6605
F60-64 5067
M20-24 4580
FJUNIOR 4105
M30-39 3964
M40-49 3319
F 3306
M70-74 3072
F20-24 2522
Можно видеть, что это группы по пять лет, отдельно для мужчин и отдельно для женщин, а также профессиональные группы MPRO и FPRO.
Итак, нашим стандартом будет:
ag = ['MPRO', 'M18-24', 'M25-29', 'M30-34', 'M35-39', 'M40-44', 'M45-49', 'M50-54', 'M55-59', 'M60-64', 'M65-69', 'M70-74', 'M75-79', 'M80-84', 'M85-90', 'FPRO', 'F18-24', 'F25-29', 'F30-34', 'F35-39', 'F40-44', 'F45-49', 'F50-54', 'F55-59', 'F60-64', 'F65-69', 'F70-74', 'F75-79', 'F80-84', 'F85-90']
#ag – age group
Этим множеством покрывается почти 95% всех финишеров.
Разумеется, нам не удастся привести к этому стандарту вообще все группы. Но мы поищем те, что похожи на них и приведем хотя бы часть. Предварительно приведем к верхнему регистру и удалим пробелы. Вот что нашлось: ['F25-29F', 'F30-34F', 'F30-34-34', 'F35-39F', 'F40-44F', 'F45-49F', 'F50-54F', 'F55-59F', 'FAG:FPRO', 'FK30-34', 'FK35-39', 'FK40-44', 'FK45-49', 'FOPEN50-54', 'FOPEN60-64', 'MAG:MPRO', 'MK30-34', 'MK30-39', 'MK35-39', 'MK40-44', 'MK40-49', 'MK50-59', 'MМ40-44', 'MM85-89', 'MOPEN25-29', 'MOPEN30-34', 'MOPEN35-39', 'MOPEN40-44', 'MOPEN45-49', 'MOPEN50-54', 'MOPEN70-74', 'MPRO:', 'MPROM', 'M0-44"']
Преобразуем их к нашим стандартным.
fix = { 'F25-29F': 'F25-29', 'F30-34F' : 'F30-34', 'F30-34-34': 'F30-34', 'F35-39F': 'F35-39', 'F40-44F': 'F40-44', 'F45-49F': 'F45-49', 'F50-54F': 'F50-54', 'F55-59F': 'F55-59', 'FAG:FPRO': 'FPRO', 'FK30-34': 'F30-34', 'FK35-39': 'F35-39', 'FK40-44': 'F40-44', 'FK45-49': 'F45-49', 'FOPEN50-54': 'F50-54', 'FOPEN60-64': 'F60-64', 'MAG:MPRO': 'MPRO', 'MK30-34': 'M30-34', 'MK30-39': 'M30-39', 'MK35-39': 'M35-39', 'MK40-44': 'M40-44', 'MK40-49': 'M40-49', 'MK50-59': 'M50-59', 'MМ40-44': 'M40-44', 'MM85-89': 'M85-89', 'MOPEN25-29': 'M25-29', 'MOPEN30-34': 'M30-34', 'MOPEN35-39': 'M35-39', 'MOPEN40-44': 'M40-44', 'MOPEN45-49': 'M45-49', 'MOPEN50-54': 'M50-54', 'MOPEN70-74': 'M70- 74', 'MPRO:' :'MPRO', 'MPROM': 'MPRO', 'M0-44"' : 'M40-44'}
Применим теперь наше преобразование к основному датафрейму ar, но предварительно сохраним изначальные значения group в новою колонку group raw.
ar['group raw'] = ar['group']
В колонке group оставим только те значения, которые соответствуют нашему стандарту.
Теперь можно оценить наши старания:
len(ar[(ar['group'] != ar['group raw'])&(ar['group']!='')])
Out: 273
Совсем немного на уровне полутора миллионов. Но ведь не узнаешь, пока не попробуешь.
Выборочные 10 выглядят так:
Сохраняем новую версию датафрейма, предваритель
