[Перевод] Deepfakes и deep media: Новое поле битвы за безопасность

Эта статья является частью специального выпуска VB. Читайте полную серию здесь: AI and Security.
Количество дипфейков — медиа, которые берут существующее фото, аудио или видео и заменяют личность человека на нем на чужую с помощью ИИ — очень быстро растет. Это вызывает беспокойство не только потому, что такие подделки могут быть использованы, чтобы влиять на мнения людей во время выборов или впутывать кого-то в преступления, но и потому, что ими уже злоупотребляли для создания фейкового порно и обмана директора британской энергетической компании.
Предвосхищая такого рода новую реальность, объединение академических учреждений, технологических фирм и некоммерческих организаций разрабатывает способы выявления вводящих в заблуждение медиа, генерируемых ИИ. Их работа показывает, что инструменты обнаружения являются лишь краткосрочным жизнеспособным решением, в то время как дипфейковая гонка вооружений только начинается.
Дипфейковый текст
Раньше лучшая проза, созданная ИИ, была скорее близка к текстам из игры Mad Libs, чем к роману «Гроздья гнева», но современные языковые модели теперь могут писать тексты, близкие по подаче и убедительности к написанным человеком. Например, модель GPT-2, выпущенная исследовательской фирмой OpenAI из Сан-Франциско, за считанные секунды создает отрывки в стиле статей New Yorker«a или сценариев для игры «Мозговой штурм». Исследователи Центра по терроризму, экстремизму и борьбе с терроризмом Института международных исследований г. Миддлбери предположили, что GPT-2 и другие подобные ей модели могут быть настроены на пропаганду превосходства белой расы, джихадистского исламизма и других угрожающих идеологий — и это вызывает еще больше опасений.
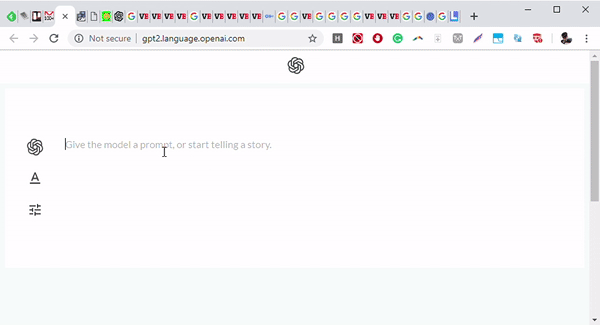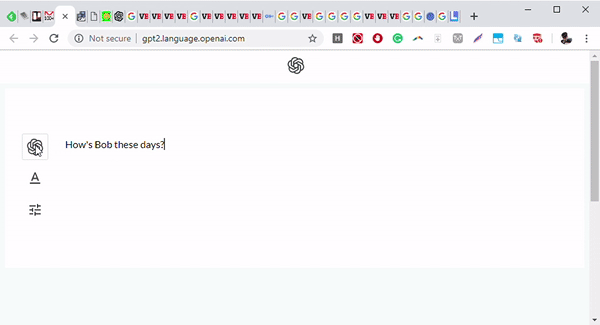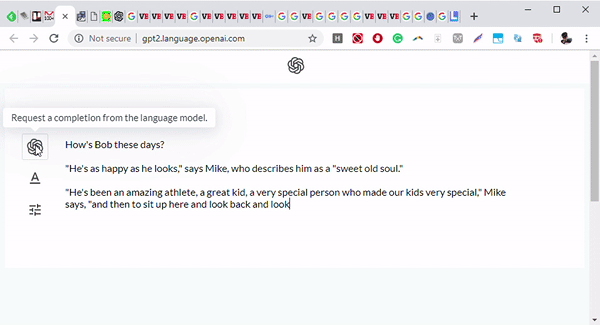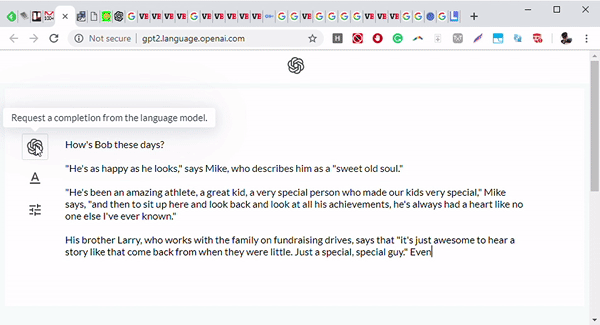
Выше: Фронтенд GPT-2, обученной языковой модели исследовательской фирмы OpenAI.
Изображение предоставлено: OpenAI
В поисках системы, способной обнаруживать синтетическое содержимое, исследователи Школы компьютерных наук и инженерии имени Пола Г. Аллена Университета Вашингтона и Института искусственного интеллекта имени Аллена разработали Grover — алгоритм, который, как они утверждают, смог отобрать 92% дипфейков в тестовом наборе, составленном из открытых данных Common Crawl Corpus. Команда объясняет свой успех копирайтинговым подходом Гровера, который, по их словам, помог разобраться с особенностями языка, созданного ИИ.
Команда ученых из Гарварда и MIT-IBM Watson AI Lab отдельно выпустила The Giant Language Model Test Room, веб-среду, которая пытается определить, был ли текст написан с помощью модели ИИ. Учитывая семантический контекст, она предсказывает, какие слова наиболее вероятно появятся в предложении, по сути, написав свой собственный текст. Если слова в проверяемом образце соответствуют 10, 100 или 1000 наиболее вероятных слов, индикатор становится зеленым, желтым или красным соответственно. Фактически она использует свой собственный прогнозируемый текст в качестве ориентира для выявления искусственно сгенерированного контента.
Дипфейковые видео
Современный ИИ, генерирующий видео, так же опасен и обладает такими же, если не большими, возможностями, как и его естественный аналог. В академической статье, опубликованной гонконгским стартапом SenseTime, Технологическим университетом Наньянга и Институтом автоматизации Китайской академии наук, подробно описывается фреймворк, который редактирует отснятый материал с использованием аудио для синтеза реалистичных видео. А исследователи из Hyperconnect в Сеуле недавно разработали инструмент MarioNETte, который может управлять чертами лица исторического деятеля, политика или генерального директора, синтезируя воссозданное лицо, оживленное движениями другого человека.
Однако даже самые реалистичные дипфейки содержат артефакты, которые их и выдают. «Дипфейки, созданные генеративными системами, изучают набор реальных изображений в видео, к которым вы добавляете новые изображения, а затем генерируют новое видео с новыми изображениями», — говорит Ишай Розенберг, руководитель группы глубокого обучения в компании по кибербезопасности Deep Instinct. «Полученное видео в результате немного отличается, поскольку происходят изменения в распределении искусственно генерируемых данных и в распределении данных в исходном видео. Эти так называемые «проблески в матрице», — то, что способны различать дипфейковые детекторы».

Выше: два фальшивых видео, созданных с использованием самых современных методов.
Изображение предоставлено: SenseTime
Прошлым летом команда из Калифорнийского университета в Беркли и Университета Южной Калифорнии подготовила модель для поиска точных «единиц действия лица» — данных о движениях лиц людей, тиках и выражениях, в том числе при поднятии верхней губы и вращении головы, когда люди хмурятся, — чтобы определить фальшивые видео с точностью более 90%. Аналогичным образом, в августе 2018 года участники программы «Медиа-криминалистика» Агентства перспективных исследований в области обороны США (DARPA) протестировали системы, способные обнаруживать видео, сгенерированное ИИ, по таким признакам, как неестественное мигание, странные движения головой, необычный цвет глаз и многое другое.
В настоящее время несколько стартапов находятся в процессе коммерциализации похожих инструментов для обнаружения поддельных видеоизображений. Амстердамская лаборатория Deeptrace Labs предлагает набор средств для мониторинга, целью которых является классификация дипфейков, загружаемых в социальные сети, платформы видеохостинга и дезинформационные сети. Dessa предложила методы улучшения детекторов подделок, обученных работе с наборами данных фальшивых видео. А в июле 2018 года компания Truepic привлекла 8 млн. долл. США для финансирования своего сервиса по глубокому обнаружению подделок на видео и фото. В декабре 2018 года компания приобрела стартап Fourandsix, чей детектор поддельных изображений получил лицензию DARPA.

Выше: Дипфейковые изображения, отредактированные ИИ.
Помимо разработки полностью обученных систем, ряд компаний опубликовал корпусы текстов в надежде на то, что исследовательское сообщество разработает новые методы обнаружения подделок. Чтобы ускорить этот процесс, Facebook наряду с Amazon Web Services (AWS), объединением Partnership on AI и учеными из ряда университетов возглавил программу Deepfake Detection Challenge. Программа включает в себя набор данных по образцам видеоматериалов с метками, указывающими на то, что на них воздействовали с помощью искусственного интеллекта. В сентябре 2019 года компания Google выпустила коллекцию визуальных подделок в рамках теста FaceForensics, который был создан Техническим университетом Мюнхена и Неаполитанским университетом Федерико II. А совсем недавно исследователи из SenseTime совместно с Технологическим университетом Наньяна в Сингапуре разработали DeeperForensics-1.0, набор данных для обнаружения подделок лица, который, как они утверждают, является самым большим в своем роде.
Дипфейковые аудио
ИИ и машинное обучение подходят не только для синтеза видео и текста, они также могут копировать голоса. Бесчисленныеисследования показали, что небольшой набор данных — это все, что требуется для воссоздания речи человека. Коммерческим системам, таким как Resemble и Lyrebird, для этого требуется несколько минут аудиозаписей, в то время как сложные модели, такие как новейшая реализация Baidu Deep Voice, могут скопировать голос всего лишь с 3,7-секундного образца.
Инструментов для обнаружения аудиодипфейков пока не так много, но решения начинают появляться.
Несколько месяцев назад команда Resemble выпустила инструмент с открытым исходным кодом под названием Resemblyzer, который использует ИИ и машинное обучение для обнаружения дипфейков путем получения голосовых образцов высокого уровня и прогнозирования того, являются ли они реальными или смоделированными. Получив аудиофайл с речью, он создает математическое представление, суммирующее характеристики записанного голоса. Это позволяет разработчикам сравнить схожесть двух голосов или выяснить, кто говорит в данный момент.
В январе 2019 года в рамках Google News Initiative компания Google выпустила корпус речи, содержащий «тысячи» фраз, произнесенных с помощью моделей text-to-speech. Образцы были взяты из английских статей, прочитанных 68-ю различными синтетическими голосами с разными диалектами. Корпус доступен для всех участников ASVspoof 2019, конкурса, целью которого является содействие контрмерам против поддельной речи.
Многое можно потерять
Ни один детектор не достиг идеальной точности, и исследователи еще не выяснили, как определить фальшивое авторство. Розенберг из Deep Instinct ожидает, что это воодушевит плохих актеров на распространение подделок. «Даже если дипфейк, созданный злоумышленником, обнаружат, только сам дипфейк рискует быть раскрытым», — сказал он. «Для актера риск быть пойманным минимален. Поскольку риск низок, существует мало сдерживающих факторов против создания подделок.»
Теория Розенберга подтверждается отчетом Deeptrace, который нашел 14 698 фальшивых видео онлайн во время своего последнего подсчета в июне и июле 2019 года. За семимесячный период их количество увеличилось на 84%. Подавляющее большинство из них (96%) — видео порнографического содержания с участием женщин.
Учитывая эти цифры, Розенберг утверждает, что компании, которые «многое могут потерять» из-за дипфейков, должны разработать и внедрить в свои продукты технологию глубокого обнаружения, близкую, по его мнению, к антивирусным программам. И в этой области появились подвижки; в начале января Facebook объявил, что будет использовать комбинацию автоматизированных и ручных систем для обнаружения поддельного контента, а Twitter недавно предложил отмечать дипфейки и удалять те, которые могут причинить вред.
Конечно, технологии, лежащие в основе генерации дипфейков, являются всего лишь инструментами, и у них огромный потенциал для добрых дел. Майкл Клозер, глава отдела Data & Trust в консалтинговой компании Access Partnership, отмечает, что технология уже используется для улучшения медицинской диагностики и выявления рака, устранения пробелов в картировании вселенной и улучшения обучения беспилотных автомобилей. Поэтому он предостерегает от применения общих кампаний по блокировке генеративного ИИ.
«Так как лидеры начали применять существующие правовые нормы в делах о дипфейках, сейчас очень важно не избавиться от ценных технологий, избавляясь от подделок», — сообщил Клозер. «В конечном счете, прецедентное право и социальные нормы в отношении использования этой новой технологии не созрели достаточно, чтобы создать ярко-красные линии, разграничивающие добросовестное использование и злоупотребление».
