[Перевод] Дата снаружи, дата внутри, дата танцуй, дата умри

В статье «Данные снаружи и данные внутри» 2005 года Пэт Хелланд размышляет о данных в сервис-ориентированных архитектурах. В настоящее время СОА принято считать «микросервисной архитектурой», состоящей из «микросервисов». Хелланд показывает, что для инкапсулированных данных и данных, которыми обмениваются сервисы, требуются совершенно разные подходы. Переход от монолитной структуры к микросервисам более глубокий, чем просто рефакторинг кода в удобные, независимо развёртываемые модули:
Переход к микросервисам — это как переход от ньютоновской физики к физике Эйнштейна. Во времена Ньютона теория несколько расходилась с практикой, что устраивало далеко не всех. До появления микросервисов многие системы для распределённых вычислений выглядели похоже: с RPC, 2PC и так далее. Во вселенной Эйнштейна всё относительно и зависит от конкретной точки зрения. У микросервисов «настоящее» находится внутри (сервиса), а «прошлое» приходит в сообщениях.
Похоже, нам следует переименовать рефакторинг «извлечение микросервиса» (extract microservice) в «изменение модели пространства-времени» :).
Недавно микросервисы привлекли много внимания. Это системы, состоящие из многочисленных сервисов, каждый со своим кодом и данными, способных оперировать независимо друг от друга… В этой работе отражён ряд основополагающих различий между данными внутри сервиса и данными, отправленными во внешнее пространство, за пределы сервиса.
Давайте разберёмся.
Сервисы инкапсулируют данные, которыми они владеют. Любые изменения, а также операции чтения этих данных осуществляются через строго определённый интерфейс. Изменения может вносить только доверенная логика приложения в рамках сервиса. Снаружи сервиса нет никаких ACID-транзакций:
Участие в ACID-транзакции подразумевает готовность удерживать блокировки базы данных до тех пор, пока координатор транзакции не решит закоммитить или отменить транзакцию. Для некоординатора это серьёзное ущемление его независимости…
«Данные внутри» — это инкапсулированные частные данные, содержащиеся в рамках сервиса. «Данные снаружи» — это информация, передаваемая между независимыми сервисами.
Прошлое, настоящее, будущее и «потом»Внутри сервиса мы можем использовать транзакционный доступ к данным, с транзакционной изоляцией, создающей иллюзию того, что каждая транзакция выполняется в строго определённый момент времени…
ACID-транзакции существуют в «настоящем». По мере течения времени и выполнения коммитов транзакций каждая новая транзакция получает входные данные транзакций-предшественниц. Логика исполнения сервисов существует с чётким и ясным ощущением «настоящего».
Отправляемые сервисом сообщения часто могут содержать данные сервиса. Отправитель не будет применять блокировки к данным после отправки сообщения. Следовательно, к тому времени, как получатель обработает сообщение, исходные данные внутри отправителя могут измениться.
Содержимое сообщения всегда приходит из прошлого! Оно никогда не бывает в состоянии «настоящего».
У каждого сервиса — своё собственное восприятие внутренних данных, формирующее представление о текущем моменте. А внешние данные формируют представление о прошлом. Командные сообщения, дающие задания сервисам, это «надежды на будущее».
Получается гремучая смесь прошлого, настоящего и будущего:
Операнды могут существовать либо в прошлом, либо в будущем (в зависимости от шаблона их использования). В прошлом они живут тогда, когда имеют копии незаблокированной информации удалённого сервиса. А в будущем они живут тогда, когда содержат предполагаемые значения, которые могут быть использованы при успешном завершении оператора. Между сервисами всё находится в состоянии «потом»… Как следствие, данные снаружи живут в мире «потом». Это либо прошлое, либо будущее, но не настоящее.
Поскольку каждый сервис живёт в собственном настоящем, то синхронизация этого настоящего с входящим и исходящим «потом» зависит от логики сервиса.
Воздействия внешних данныхДанные снаружи должны быть неизменяемыми и идентифицируемыми, чтобы они оставались прежними вне зависимости от того, когда и где на них ссылаются. В рамках сервиса вы можете ссылаться на The New York Times, и всегда будет иметься в виду текущая версия. В данном случае The New York Times — объект, не зависящий от версии идентификатора. Но когда данные покидают сервис, то уже недостаточно сказать «The New York Times»; не зависящий от версии идентификатор должен стать зависящим от версии идентификатором. Например, «The New York Times, 4 января 2005 года, Калифорнийское издание».
Неизменяемость — недостаточное условие для избежания путаницы. Должна существовать недвусмысленная интерпретация контекста данных. Стабильные данные имеют недвусмысленную и неизменяемую интерпретацию на протяжении «пространства и времени»… Есть несколько способов создания стабильных данных — использование временных меток и/или версионности либо использование уникальных важных идентификаторов.
Сообщения должны быть неизменяемыми (например, их содержимое не должно меняться в случае повторения запросов) вместе с их схемой.
Именно поэтому рекомендуется версионировать схемы сообщений, и каждое сообщение должно использовать зависящий от версии идентификатор точного определения формата сообщения.
(Дальше в своей статье Хелланд обсуждает схему, обеспечивающую расширяемость.)
При ссылке на другие данные необходимо, чтобы идентификатор, используемый для ссылки, также был неизменяемым.
Внутренние данныеВнутренние данные — это царство SQL и DDL SQL. SQL и DDL живут в «настоящем»…
Как и другие операции в SQL, обновления схемы через DDL выполняются под защитой транзакции и применяются атомарно. Изменения схемы могут вносить существенные различия в способы интерпретирования данных, хранящихся в базе. Ключевое качество DDL заключается в том, что транзакции, предшествующие операции DDL, основаны на схеме, существовавшей ранее, а транзакции, следующие за операцией DDL, основаны на новой схеме. Иными словами, изменения в схеме участвуют в механизмах сериализации баз данных.
Полученные извне данные могут быть преобразованы в удобную для использования сервисом форму. Допустим, можно хранить внешние данные в «документе» (в качестве примера в статье приведён XML, самый популярный в 2005 году язык). С помощью этого можно добиться расширяемости и благодаря ней добавить информацию, не объявленную в исходной схеме сообщения.
Расширяемость во многом напоминает заметки на полях. Она часто даёт желаемый результат, но безо всяких гарантий.
Второй вариант — «измельчение» данных: преобразование в реляционное представление.
Интересный момент — расширяемость конфликтует с «измельчением». В запланированных таблицах нужно отобразить незапланированные расширения.
Выбор подходящего представления данныхСтатья завершается рассмотрением трёх разных представлений данных — XML, SQL и инкапсуляции объекта. (Сейчас мы можем добавить JSON или заменить им XML.) SQL и XML/JSON, по сути, это антиинкапсуляция: они делают данные абсолютно доступными. Компоненты и объекты, напротив, усиливают инкапсуляцию.
Учитывая всё вышесказанное, Хелланд предлагает таблицу требований к внутренним и внешним данным:
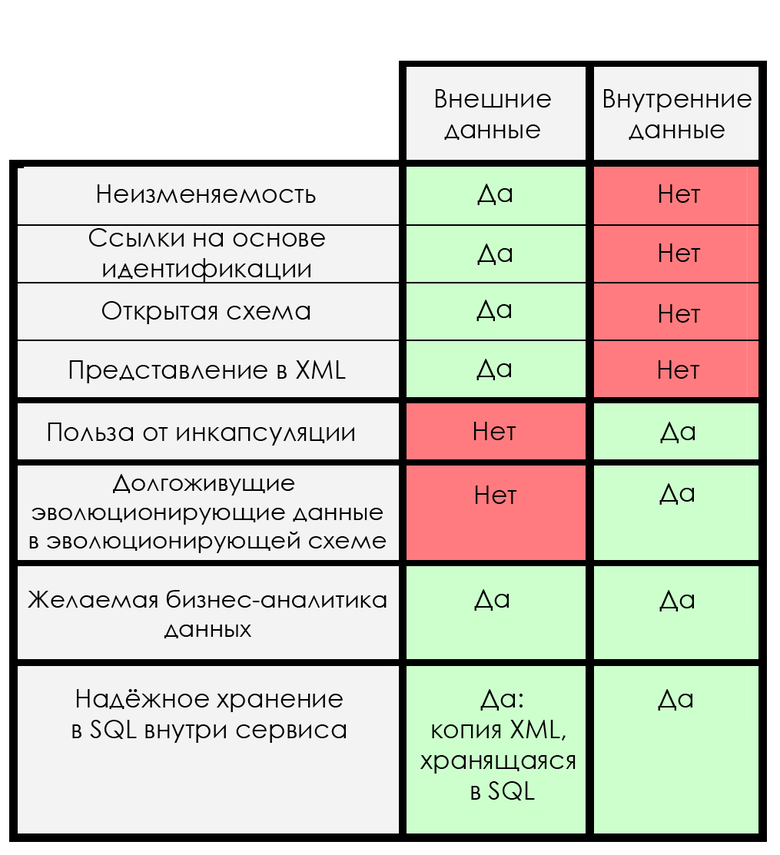
…Мы рассматриваем инкапсуляцию и понимаем, что внешние данные не защищены кодом. Не существует общепринятого способа убедиться, что тело кода является посредником при доступе к данным. Более того, в силу текущей архитектуры, вы должны понимать внутреннюю структуру сообщения, если у вас есть к ней доступ. Внутренние данные всегда являются частью сервиса и логики приложения.
У каждого из трёх представлений свои преимущества и недостатки, так что они по-разному годятся для внутренних и внешних ролей:
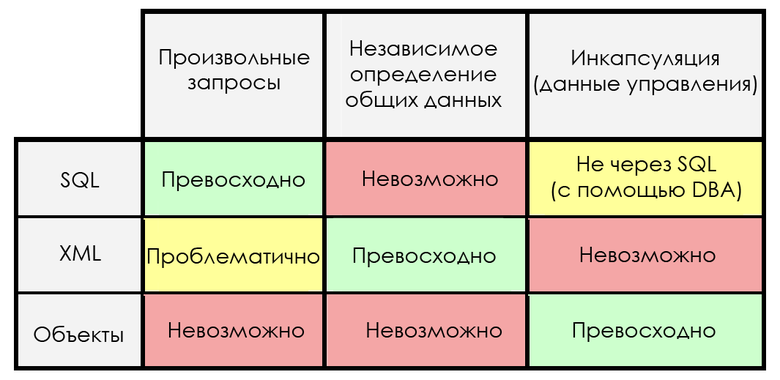
Преимущество каждой модели одновременно является её слабостью! То, благодаря чему SQL прекрасно подходит для создания запросов, делает его ужасным решением для независимого определения общих данных. XML замечательно подходит для независимого определения и создания данных, но не годится для инкапсуляции. Инкапсуляция — ключевое преимущество объектных систем, но при этом несовместима с запросами. Ни в одну из этих моделей нельзя добавить возможности, компенсирующие их слабости, без потери преимуществ!
Так что можно заключить, что у каждой из моделей есть своя роль, необходимы все три:
Если осознать, что большинство разработчиков ПО весьма умны, то это заключение не должно вас удивлять. Сегодня является нормальной практикой использование XML для представления внешних данных, объектов — для реализации бизнес-логики сервисов, SQL — для хранения данных внутри. Нам нужны все три представления, и мы должны выгодно использовать их сильные стороны!
