[Перевод] Что такое большие данные, часть 1
Большие данные — это Большие Новости, Большая Важность и Большой Бизнес, но что это на самом деле? Что такое большие данные? Для тех, кто живёт ими, всё очевидно, а я просто тупица — задавать подобные вопросы. Но те, кто живёт ими, считают большинство людей глупыми, верно? Поэтому в начале я хочу поговорить с теми читателями, которые, как и я, не в теме. Что это вообще такое? На этой неделе я планирую хорошенько исследовать этот вопрос, и, скорее всего, опубликовать три длинных статьи (прим. переводчика: переводы следующих двух частей выйдут в ближайшие дни).
Моя передача на канале PBS «Триумф ботанов» («Triumph of the Nerds») — это история персонального компьютера и взлёта его популярности с 1975 по 1995. «Ботаны 2.01: Краткая история Интернета» («Nerds 2.01: A Brief History of the Internet») — это история взлёта его популярности с 1966 по 1998. Но каждый выпуск на самом деле был о влиянии закона Мура на технологии и общество. Персональные компьютеры стали возможными только когда стоимость микропроцессоров снизилась до доступной обычному человеку суммы. Это было невозможно до того переломного момента, когда рынок был готов к взрывному росту.
 Коммерческий интернет, в свою очередь, стал возможным только когда цена серверов упала еще на два порядка, к середине 1990-х годов, что сделало dial-up экономически целесообразным и привело к следующей критической точке. Если мыслить теми же понятиями, большие данные — это то, что произошло, когда стоимость вычислений упала еще на два порядка к 2005 году, подводя к самой последней критической точке. Мы притворяемся, что это произошло раньше, в 1998 году, но это не так (это часть истории). 2005 отмечен появлением мобильной и облачной компьютеризации, и началом эпохи больших данных. Точно так же, как показывалось в двух моих документальных фильмах, мы, люди, снова стоим на пороге новой эры в почти в полном непонимании: как мы сюда попали или что всё это значит.
Коммерческий интернет, в свою очередь, стал возможным только когда цена серверов упала еще на два порядка, к середине 1990-х годов, что сделало dial-up экономически целесообразным и привело к следующей критической точке. Если мыслить теми же понятиями, большие данные — это то, что произошло, когда стоимость вычислений упала еще на два порядка к 2005 году, подводя к самой последней критической точке. Мы притворяемся, что это произошло раньше, в 1998 году, но это не так (это часть истории). 2005 отмечен появлением мобильной и облачной компьютеризации, и началом эпохи больших данных. Точно так же, как показывалось в двух моих документальных фильмах, мы, люди, снова стоим на пороге новой эры в почти в полном непонимании: как мы сюда попали или что всё это значит.
Персональные компьютеры изменили Америку, интернет изменил мир, но Большие данные преобразуют мир. Они будут править развитием технологий следующие сто лет.
Где бы вы ни находились, компьютеры наблюдают за вами и регистрируют данные о вашей деятельности, отмечая, в первую очередь то, что вы смотрите, читаете, разглядываете или покупаете. Если выйти на улицу практически любого города, то к этому добавляется еще и видеонаблюдение: где вы, что делаете, кто или что находится рядом? Ваши сообщения частично прослушиваются, а иногда даже записываются. Все, что вы делаете в интернете — от комментариев к твитам до простого просмотра страниц — никогда не стирается из истории. Частично это связано с национальной безопасностью. Но основная цель этой технологии — просто заставить вас покупать больше вещей, сделать вас более эффективным потребителем. Технология, которая позволяет собирать и анализировать данные, изобретена по большей части в Кремниевой долине множеством технологических стартапов.
Почему мы оказались в таком положении, и что будет дальше? Технологии, конечно же, продолжат расширять горизонты, но на этот раз, вместо того, чтобы изобретать будущее и участвовать в прогрессе, гики будут плыть в одной лодке со всеми остальными: новые достижения вроде самоуправляемых автомобилей, универсальных переводчиков и даже компьютеров, разрабатывающих другие компьютеры, будут возникать не с помощью человеческого разума, а с помощью самих машин. И виной всему этому Большие данные.
Большие данные — это накопление и анализ информации для извлечения значения.
Данные — это сведения о состоянии чего-то: кто, что, почему, где и зачем играет в шпионские игры, как распространяется болезнь или как изменяется популярность попсовой группы. Данные могут быть собраны, сохранены и проанализированы для того, чтобы понять что происходит: действительно ли социальные медиа запустили Арабскую весну, может ли расшифровка ДНК предотвратить болезни или кто побеждает на выборах.
Хотя данные окружали нас и в прошлом, мы ими особенно не пользовались, в основном из-за высокой стоимости хранения и анализа. Будучи охотниками-собирателями первые 190 000 лет жизни человека разумного, мы вообще не собирали данные, так как не было способа хранения и даже способа записи. Письменность появилась около 8000 лет назад, в первую очередь как способ хранения данных в период формирования культуры, когда нам захотелось записывать свои истории, а позже появилась необходимость хранить списки о населении, налогах и смертности.
Списки, как правило, двоичные — вы или в нём, или вас нет, вы живой или мертвый, платите налоги или нет. Списки нужны для подсчёта, а не вычисления. Списки могут содержать смысловое значение, но не часто. Необходимость понять смысл более высоких сил и явлений привела нас от подсчетов к вычислениям.
 Тысячи лет назад стоимость записи и анализа данных для общественности была настолько высока, что только религия могла себе её позволить. В попытке объяснить мистический мир наши предки стали смотреть на небо, замечать движение звезд и планет и впервые стали записывать эту информацию.
Тысячи лет назад стоимость записи и анализа данных для общественности была настолько высока, что только религия могла себе её позволить. В попытке объяснить мистический мир наши предки стали смотреть на небо, замечать движение звезд и планет и впервые стали записывать эту информацию.
Религия, которая уже привела к письменности, затем привела к астрономии, а астрономия привела к математике — всё в поисках мистического смысла небесного движения. К примеру, календари не были выдуманы, они стали результатом обобщения данных.
На протяжении истории данными пользовались для учёта налогов и переписей населения, для общего бухгалтерского учета. Взять к примеру «Книгу Страшного суда» 1086 года — фактически, главную налоговую базу Британии. Везде сокрыт термин подсчет. Большая часть данных, собранных на протяжении истории, регистрировалась путём подсчета. Если нужно было рассмотреть много информации (больше нескольких наблюдений, необходимых для научного эксперимента), это почти всегда было связано с деньгами или другим выражением власти (сколько солдат, сколько налогоплательщиков, сколько младенцев мужского пола в возрасте до двух лет в Вифлееме?). Каждый раз при подсчёте результат — это число, а числа легко хранить, записывая их.
 Как только мы начали накапливать знания и записывать их, у нас появилась естественная потребность скрывать их от других. Это породило коды, шифры и статистические методы их взлома. Ученый IX века Абу Юсуф аль-Кинди написал «Манускрипт по расшифровке зашифрованных сообщений», положив начало статистике — поиску значения данных, криптоанализу и взлому кодов.
Как только мы начали накапливать знания и записывать их, у нас появилась естественная потребность скрывать их от других. Это породило коды, шифры и статистические методы их взлома. Ученый IX века Абу Юсуф аль-Кинди написал «Манускрипт по расшифровке зашифрованных сообщений», положив начало статистике — поиску значения данных, криптоанализу и взлому кодов.
В своей книге аль-Кинди продвигал метод, в настоящее время называемый частотным анализом, чтобы помочь взламывать коды с неизвестным ключом. Большинство кодов были подстановочными шифрами, где каждая буква заменялась на другую. Зная, какая буква соответствовала какой, сообщение можно легко расшифровать. Идея Аль-Кинди была в том, что если знать частоту использования букв при обычном общении, то эта частота перейдет без изменений в закодированное сообщение.
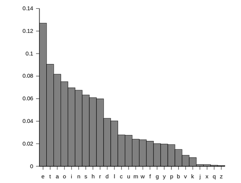 В английском наиболее частые буквы — это E, T, A и O (именно в таком порядке). Когда закодированное сообщение достаточно большое, самая часто встречающаяся буква должна быть буквой E, и так далее. Если вам попалась Q, после нее почти всегда будет U и т.д. Конечно, кроме тех случаев, когда целевой язык не английский.
В английском наиболее частые буквы — это E, T, A и O (именно в таком порядке). Когда закодированное сообщение достаточно большое, самая часто встречающаяся буква должна быть буквой E, и так далее. Если вам попалась Q, после нее почти всегда будет U и т.д. Конечно, кроме тех случаев, когда целевой язык не английский.
Главное в любой задаче частотной подстановки — это знание относительной частоты для любого языка, и это означает подсчет букв в тысячах обычных документов. Это сбор и анализ данных образца 900 г. н.э…
 Но только через 800 лет после аль-Кинди собранные данные стали доступны для широкого общественного пользования. В Лондоне еженедельно, начиная с 1603 года, публиковались списки смертности («Bills of mortality») чтобы вести учёт всех зарегистрированных случаев смерти в городе (Тащите ваших мертвецов!). Эти еженедельные отчеты позже публиковались в ежегодном выпуске, и тут начинается самое интересное. Хотя списки сделали просто для общественного знания, их ценность выявилась в процессе анализа этих страниц после чумы 1664–65 гг. Эксперты смогли построить график того, как болезнь распространилась из инфицированных областей по всему Лондону, совместив информацию с картой примитивной системы городского водоснабжения и канализации. Из этих данных стали понятны источники инфекции (комары и крысы) и то, как держаться от них подальше (быть богатым, а не бедным). Так начались исследования общественного здоровья.
Но только через 800 лет после аль-Кинди собранные данные стали доступны для широкого общественного пользования. В Лондоне еженедельно, начиная с 1603 года, публиковались списки смертности («Bills of mortality») чтобы вести учёт всех зарегистрированных случаев смерти в городе (Тащите ваших мертвецов!). Эти еженедельные отчеты позже публиковались в ежегодном выпуске, и тут начинается самое интересное. Хотя списки сделали просто для общественного знания, их ценность выявилась в процессе анализа этих страниц после чумы 1664–65 гг. Эксперты смогли построить график того, как болезнь распространилась из инфицированных областей по всему Лондону, совместив информацию с картой примитивной системы городского водоснабжения и канализации. Из этих данных стали понятны источники инфекции (комары и крысы) и то, как держаться от них подальше (быть богатым, а не бедным). Так начались исследования общественного здоровья.
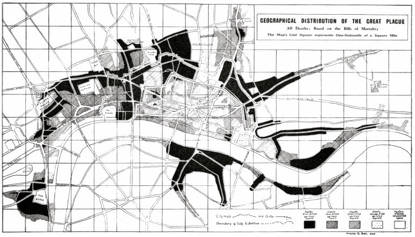
Главная польза списков смертности была не в информации об умерших (просто цифры), а в метаданных (данных о данных), которые показывали где жили жертвы, где умерли, их возраст и вид работы. Историю чумы 1664 можно проследить, отмечая метаданные на карте.
Несмотря на то, что списки смертности считались полноценными отчетами о чуме, сомневаюсь, что они были точными. Многие смерти, вероятно, не были зарегистрированы или указаны по неверным причинам. Но статистика привела к одному выводу: динамика четко прослеживается даже если данных недостаточно. Когда во Франции XVIII века статистика стала развиваться как самостоятельная дисциплина, стало ясно, что из случайной выборки данных можно извлечь столько же, сколько из всей информации. Мы видим это сегодня, когда политические социологи предсказывают результаты выборов, основываясь на небольших выборках случайных избирателей. В то же время, крупные ошибки, которые иногда случаются у исследователей, показывают, что метод с выборкой далек от совершенства.
Выборка и опрос дают результаты, в которые мы верим, но 100% выборка вроде переписи или выборов дают результаты, которые мы знаем.
Обработка данных. Хранение данных — это совсем не то, что их обработка. Библиотеки отлично хранят данные, но доступ к ним затруднен. Вам всё ещё нужно найти книгу, открыть ее, прочитать, но и после этого уровень детализации, которую мы можем достичь, ограничен нашей памятью.
Американский статистик Герман Холлерит в конце 19-го века задумал систему, которая будет автоматически собирать данные и записывать их с помощью отверстий на бумажных картах. Картах, которые могут быть механически отсортированы для получения значений из данных. Этот процесс Холлерит назвал табулированием («tabulating»). Холлерит получил патент на технологию, и его Tabulating Machine Company, расположенная в Вашингтоне, в итоге превратилась в современную International Business Machines (IBM).
 В течение десятилетий основной машинной функцией IBM была сортировка. Представьте, каждая карта была счётом клиента электрической компании. Машина облегчала работу по организации клиентской базы в алфавитном порядке, по фамилии, и сортировала их по дате выставления счетов, по сумме задолженности, по наличию или отсутствию долгов, и так далее. В то время под обработкой данных подразумевалась сортировка, и перфокарты отлично справлялись с этой задачей. Конечно, люди тоже способны на эту работу. Но машины экономят время, так что их использовали в первую очередь для того, чтобы все счета были отправлены до конца месяца.
В течение десятилетий основной машинной функцией IBM была сортировка. Представьте, каждая карта была счётом клиента электрической компании. Машина облегчала работу по организации клиентской базы в алфавитном порядке, по фамилии, и сортировала их по дате выставления счетов, по сумме задолженности, по наличию или отсутствию долгов, и так далее. В то время под обработкой данных подразумевалась сортировка, и перфокарты отлично справлялись с этой задачей. Конечно, люди тоже способны на эту работу. Но машины экономят время, так что их использовали в первую очередь для того, чтобы все счета были отправлены до конца месяца.
Первые базы данных были кучкой таких перфокарт. И электрической компании было легко решить, что должно быть на карте. Имя и адрес, потребление электроэнергии в текущем расчетном периоде, дата, когда счёт должен быть отправлен и текущий статус оплаты: оплачиваете ли вы свои счета?
Но что, если нужно было добавить новый продукт или услугу? Пришлось бы добавлять новое поле с данными на каждую карту, включая все существующие карты. Такие изменения делали механические сортировщики проклятьем. Ради большей гибкости в 1950-е годы возник новый вид баз данных, который изменил мир бизнеса и путешествий.
Обработка транзакций. Система бронирования SABRE компании American Airlines была первой в мире автоматизированной системой, работавшей в реальном времени. Это не только первая система бронирования, но первая в мире компьютерная система по взаимодействию с операторами в режиме реального времени, где все происходило полностью в компьютере. Прелюдия к Большим данным. Это всё работало уже тогда, когда мы еще вручную отслеживали русские бомбардировщики.
До SABRE обработка данных всегда происходила после событий. Системы учета заглядывали на квартал или месяц назад и выясняли, как представить то, что уже произошло. И этот процесс длился столько, сколько нужно. Но SABRE продавал билеты на будущее, на основе информации о местах, хранящейся исключительно в компьютере.
Представьте что SABRE — обувная коробка, которая содержит все билеты на все места на рейс AA 99. Продажа билетов из обувной коробки обезопасит от продажи одного места дважды, но как быть, если вам потребуется продавать места одновременно через агентов в разных офисах по всей стране? Для этого нужна компьютерная система и терминалы, чего в то время не существовало. Основателю American Airlines С.Р. Смиту потребовалось слетать в самолете рядом с Т. Уотсоном из IBM, чтобы запустить этот процесс.
 Ключевой момент истории SABRE: у IBM не было подходящего компьютера для запуска системы, настолько задача была требовательна к ресурсам. Так что American Airlines стал первым заказчиком самых крупных компьютеров, выпускаемых в те годы. Для задач авиакомпании не писали программ. Вместо этого компьютеры в первом корпоративном центре обработки данных в мире, в городе Талса, штат Оклахома (он все еще там), были ориентированы исключительно на продажу авиабилетов, и ничего другого делать не умели. Программы появились позже.
Ключевой момент истории SABRE: у IBM не было подходящего компьютера для запуска системы, настолько задача была требовательна к ресурсам. Так что American Airlines стал первым заказчиком самых крупных компьютеров, выпускаемых в те годы. Для задач авиакомпании не писали программ. Вместо этого компьютеры в первом корпоративном центре обработки данных в мире, в городе Талса, штат Оклахома (он все еще там), были ориентированы исключительно на продажу авиабилетов, и ничего другого делать не умели. Программы появились позже.
American Airlines и SABRE затянули IBM в бизнес мейнфреймов. А проектированием тех первых систем AA и IBM занимались совместно.
SABRE задала общее направление вычислительным приложениям, управляемым данными с 1950-ых до 1980-ых. У кассиров в банке, наконец, появились компьютерные терминалы, но так же, как при бронировании авиабилетов, их терминалы могли выполнять только одну задачу — банковское дело — и данные клиентов банка обычно хранились на перфокарте в 80 колонок.
Закон Мура. Когда компьютеры стали использовать для обработки данных, их скорость позволила углубиться в эти данные, раскрывая больше смысла. Высокая стоимость компьютеров ограничивала их применение такими прибыльными сферами, как продажа авиабилетов. Но появление компьютеров с твердотельной электроникой в 1960-х годах положило начало устойчивому увеличению мощности компьютеров и снижению их стоимости, что продолжается и сегодня. Это закон Мура. То, что обходилось American Airlines в $10 в 1955 году, к 1965 сократилось до десяти центов, к 1975 до одной десятой цента и до одной миллиардной цента сегодня.
Мощность всей вычислительной системы SABRE в 1955 году была меньше, чем мощность современного мобильного телефона.
 Влияние закона Мура и, самое главное, способность надежно предсказывать, на каком этапе стоимость компьютеров и их возможности будут через десять или более лет, позволяет применять вычислительные мощности ко всё более дешёвым сферам деятельности. Это то, что превратило обработку данных в Большие данные.
Влияние закона Мура и, самое главное, способность надежно предсказывать, на каком этапе стоимость компьютеров и их возможности будут через десять или более лет, позволяет применять вычислительные мощности ко всё более дешёвым сферам деятельности. Это то, что превратило обработку данных в Большие данные.
Но для того чтобы это произошло, мы должны были уйти от необходимости создавать новый компьютер каждый раз, когда нам требовалась новая база данных. Вместо железа на первый план должен был выйти софт. А программы, в свою очередь, должны были стать более открытым для модификации, поскольку нужды правительства и промышленности менялись. Решением стала реляционная система управления базами данных. Концепция была разработана в IBM, но миру ее представил стартап из Кремниевой долины — Oracle Systems под руководством Ларри Эллисона.
Эллисон запустил Oracle в 1977 году с бюджетом в $1200. Сейчас он (в зависимости от того, когда вы это читаете) третий самый богатый человек в мире и прототип главного героя фильма «Железный Человек».
До Oracle данные были таблицами — строками и столбцами. Они хранились в памяти компьютера, если в нём достаточно места, или записывались на магнитную ленту и считывались с неё, если памяти не хватало, что обычно случалось в 70-х. Такие плоские файловые базы данных были быстрыми, но часто не было возможности изменить логические связи между этими данными. Если появлялась необходимость удалить запись или менялась переменная, нужно было всё менять и конструировать совершенно новую базу данных, которая затем записывалась на ленту.
Для плоских файловых баз данных изменения и поиск смысла были сложными.
Тед Кодд из IBM, экспат из Англии, математик, работавший в Сан-Хосе, в Калифорнии, начал думать в 1970-х годах о чем-то более продвинутом, нежели плоская файловая база. В 1973 году он написал статью, в которой описывалась новая реляционная модель базы данных, где можно было добавлять и удалять данные, а важные связи в данных можно было переопределить на лету. Там, где до модели Кодда система начисления заработной платы была системой начисления заработной платы, а система инвентаризации — системой инвентаризации, реляционный подход отделил данные от приложения, которое обрабатывало их. Кодд представлял общую базу данных, которая одновременно имела атрибуты и платежной и инвентаризационной систем, и она могла изменяться по мере необходимости. И впервые присутствовал язык запросов — формальный способ запрашивать данные с гибкими способами управления этими данными.
Эта реляционная модель была огромным шагом вперед в разработке баз данных, но IBM зарабатывала много денег на своей старой технологии, так что они не сразу превратили новую идею в продукт, оставив эту возможность Эллисону и Oracle.
 Oracle реализовала почти все идеи Кодда, а затем шагнула дальше, дав возможность запускать программное обеспечение на разных типах компьютеров и операционных систем, повышая покупательную способность. Другие производители реляционных баз данных, включая IBM и Microsoft, последовали их примеру, но Oracle до сих пор остается крупнейшим игроком. Они не только обеспечили гибкость бизнес-приложениям, они открыли двери новым классам приложений: рекрутинг, CRM, и в особенности то, что называется бизнес-аналитикой. Бизнес-аналитика заглядывает в известную вам информацию, чтобы показать скрытую в ней пользу. Бизнес-аналитика — это одно из ключевых применений Больших Данных.
Oracle реализовала почти все идеи Кодда, а затем шагнула дальше, дав возможность запускать программное обеспечение на разных типах компьютеров и операционных систем, повышая покупательную способность. Другие производители реляционных баз данных, включая IBM и Microsoft, последовали их примеру, но Oracle до сих пор остается крупнейшим игроком. Они не только обеспечили гибкость бизнес-приложениям, они открыли двери новым классам приложений: рекрутинг, CRM, и в особенности то, что называется бизнес-аналитикой. Бизнес-аналитика заглядывает в известную вам информацию, чтобы показать скрытую в ней пользу. Бизнес-аналитика — это одно из ключевых применений Больших Данных.
Интернет и Всемирная паутина. Компьютеры, которые работали с реляционными базами данных вроде Oracle, были, к тому моменту, мейнфреймами и мини-ЭВМ, и назывались «большим железом». Они находились в корпоративных сетях, и потребители их никогда не касались. Это изменилось с появлением коммерческого интернета в 1987 году, а затем веба в 1991. Хотя типичной точкой доступа к Интернету в те ранние годы был персональный компьютер, он был по сути клиентом. Сервером, где физически находились данные Интернета, был, как правило, компьютер значительно крупнее, способный с лёгкостью справляться с Oracle или другой реляционной базой данных. Все они опирались на один язык структурированных запросов (Structured Query Language или SQL), чтобы запрашивать данные. Так что, практически с самого рождения веб-серверы опирались на базы данных.
Базы данных в основном не хранили состояния и данных о запросах. Иными совами, если сделать запрос в базу, то немного модифицированный запрос все равно будет совершенно новой задачей. Можно было, например, спросить «сколько аппаратов мы продали в прошлом месяце?» и получить ответ, но если дополнить вопрос «сколько из них синего цвета?», то компьютер должен представить это как совершенно новый запрос: «сколько синих аппаратов мы продали в прошлом месяце»?
Наверное, вы спросите, какое это всё имеет значение? Кого это волновало? Основателя amazon.com Джеффа Безоса. И его заинтересованность в вопросе навсегда изменила мир коммерции.
Amazon.com был построен на основе Всемирной паутины, создатель которой Тим Бернерс-Ли определил её как систему без состояния (stateless). Почему Тим это сделал? Потому что Ларри Теслер из Xerox PARC был против режимов. На автомобильном номере Ларри написано NO MODES (нет режимам). Это значит, что как специалист по интерфейсам, он был против существования режимов работы. Пример режима: если зажать клавишу Ctrl, то всё, что происходит дальше, обрабатывается компьютером иначе. Режимы порождают состояния, а состояния — это плохо, так что внутри компьютера Xerox Alto не было состояний. А так как Тим Бернерс-Ли был по большей части занят соединением в сеть компьютеров Alto в ЦЕРН, чтобы построить его величество World Wide Web, в вебе тоже не стало никаких режимов. Веб был «stateless».
Но веб без состояния порождал серьёзные проблемы для Amazon, а у Джеффа Безоса была мечта избавить мир от посредников в виде физических магазинов. Осуществить такое — сложная задача, если вам постоянно приходится всё начинать с нуля. Если вы пользовались услугами раннего Amazon, возможно, вы помните, что после выхода из системы все данные о вашем сеансе удалялись. В следующий раз при входе в систему (если она вас узнавала, чего обычно не происходило), скорее всего можно было увидеть свои предыдущие заказы, но не просмотренные товары.
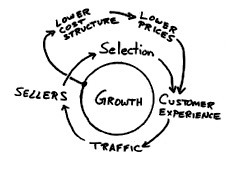 Одержимость Amazon качеством обслуживания клиентов, как показано на этом рисунке из первоначального бизнес-плана компании, была неотъемлемой частью его уникальной бизнес-модели.
Одержимость Amazon качеством обслуживания клиентов, как показано на этом рисунке из первоначального бизнес-плана компании, была неотъемлемой частью его уникальной бизнес-модели.
Безосу, бывшему айтишнику с Уолл Стрит, которому знакомы все инструменты бизнес-аналитики того времени, нужна была система, которая в следующий раз при входе на сервер спрашивала бы вас «Вы все еще ищете длинные подштанники?». Возможно, они всё ещё в вашей корзине, те подштанники, которые вы рассматривали в прошлый раз, но решили не покупать. Этот простой приём — сохранять историю недавних действий — был настоящим началом Больших данных.
Amazon построила свою систему электронной коммерции на Oracle и потратила $150 миллионов на развитие описанных здесь возможностей, таких, которые сейчас кажутся мелочью, но в прошлом были невозможны. Безос и Amazon начали с отслеживания купленных товаров, потом перешли к предполагаемым покупкам, потом к просмотренным товарам, потом к сохранению каждого клика и нажатия клавиши. Всё это они делают и сегодня на сайте, авторизованы вы или нет.
Нужно понимать, что мы говорим о 1996 годе, когда интернет-стартап стоил $3–5 миллионов венчурного капитала максимум, но Amazon потратила $150 миллионов на обслуживание клиентов с помощью больших данных, чего никто раньше никогда не делал. Насколько сильно это нарушает приемлемые для венчурных инвесторов отклонения от стандарта? Безос почти с самого возникновения компании поставил всё на Большие данные.
Этот риск окупился, и именно поэтому Amazon.com стоит сегодня $347 миллиардов, $59 миллиардов из которых принадлежит Джеффу Безосу.
То, что Джеффа Безоса подвигло создать такую функциональность, и то, что ему и его команде удалось сделать это на Oracle, системе управления реляционной БД с SQL, которая не была предназначена для таких задач — это первое чудо больших данных.
(Перевод Наталии Басс)
Комментарии (4)
 claygod
claygod
15 июля 2016 в 13:47
+1↑
↓
Спасибо за статью, жаль быстро закончилась)) Жду продолжение! freetonik
freetonik
15 июля 2016 в 13:52
0↑
↓
Уже готовится перевод второй части!
 minicon
minicon
15 июля 2016 в 14:17
+1↑
↓
Отличная, структурированная статья, много интересных примеров. Спасибо!15 июля 2016 в 15:01
+1↑
↓
Поддерживаю! Очень интересно. Спасибо!
