[Перевод] Четыре проекта с веб-скрейпингом, которые позволят упростить себе жизнь

Подумайте обо всех тех вещах, которые вы делаете в течение дня. Возможно, вы читаете новости, отправляете электронные письма, находите самые выгодные цены на товары или ищете работу онлайн. Большинство этих задач можно автоматизировать при помощи веб-скрейпинга, поэтому вместо того, чтобы вы тратили часы на изучение веб-сайтов, компьютер может сделать это за вас в течение пары минут.
Веб-скрейпинг — это процесс извлечения данных с веб-сайта. Для изучения веб-скрейпинга достаточно пройти туториал о принципах работы таких библиотек Python, как Beautiful Soup, Selenium или Scrapy; однако если вы не будете применять на практике все изученные концепции, то время окажется потраченным впустую.
Именно поэтому стоит попробовать создавать проекты с веб-скрейпингом, которые не только помогут вам освоить теорию веб-скрейпинга, но и позволять разработать ботов. автоматизирующих повседневные задачи.
В этой статье я перечислю проекты, которые автоматизируют четыре задачи, ежедневно выполняемые многими людьми. Проекты изложены по возрастанию сложности, от начальных до продвинутых.
Чтобы первый проект был простым для новичков, мы используем Beautiful Soup, потому что это самая лёгкая библиотека Python для веб-скрейпинга.
Задача проекта будет заключаться в получении title и параграфа body из статьи на любом веб-сайте (например, из новости, поста и т.д.). После этого мы экспортируем весь контент в файл .txt, имя которого будет совпадать с заголовком статьи. Демо проекта представлено в показанном ниже gif. В данном случае вместо скрейпинга новостной статьи я скачал транскрипцию фильма «Титаник».

Код для реализации первого проекта представлен по ссылке ниже. Этот проект для начинающих позволит вам познакомиться с базовыми концепциями веб-скрейпинга на Python, например, как получить HTML с веб-сайта, находить элементы на веб-сайте и экспортировать данные в файл .txt.
Как легко скрейпить множество страниц веб-сайта с помощью Python [en].
Разумеется, можно было просто скопипастить данные вручную, а затем создать файл .txt, и это заняло бы меньше минуты; однако представьте, что это нужно сделать для десяти или более статей! Выполнение этой задачи вручную заняло бы много времени, но благодаря Python и Beautiful Soup мы за несколько минут можем создать скрипт, извлекающий эти данные, а затем добавить цикл for для скрейпинга множества страниц.
Ниже перечислены некоторые другие повторяющиеся задачи, которые можно автоматизировать при помощи веб-скрейпинга. Помните, что для их автоматизации требуются начальные знания Selenium (для изучения Selenium с нуля прочитайте это руководство [en]).
- Отправка электронных писем
- Публикации в социальных сетях
- Заказ еды
Если вам нравится спорт, то после каждого матча вы, вероятно, заходите на веб-сайты со свободно доступной статистикой, например, со счётом игры и показателями игроков. Разве не здорово было бы получать эти данные после каждого нового матча? Или даже лучше — представьте, что вы сможете использовать эти данные для создания отчёта, чтобы сделать интересные открытия о своей любимой команде или лиге.
И это задача второго проекта — выполнить скрейпинг веб-сайта, содержащего статистику вашего любимого вида спорта. Чаще всего подобные данные находятся внутри таблицы, поэтому экспортируйте эти данные в формат CSV, чтобы потом считать их при помощи библиотеки Pandas. Чтобы представить, как выглядит проект, посмотрите gif. В этом демо я извлекаю результаты матчей в нескольких футбольных лигах за последние три года.
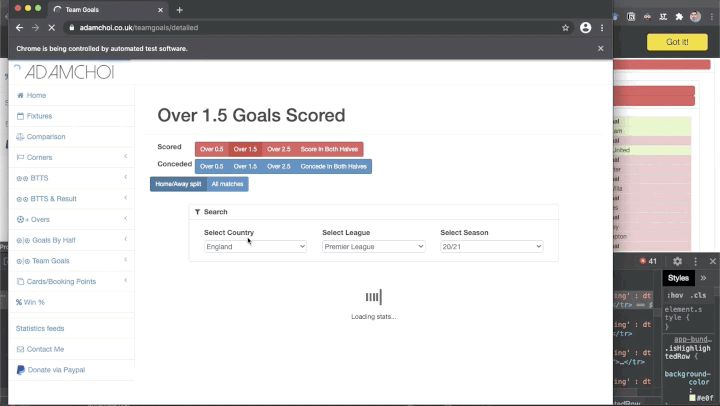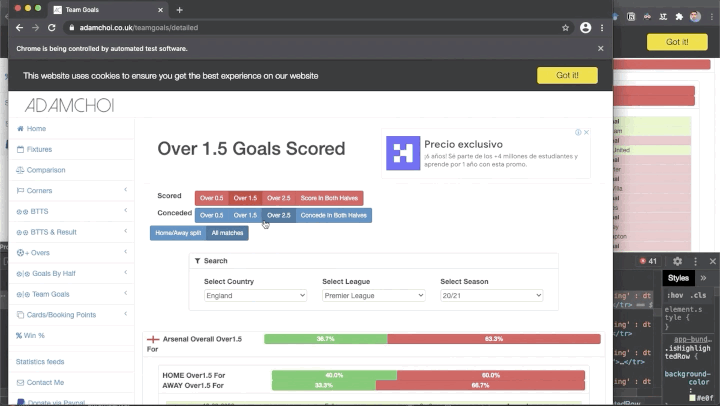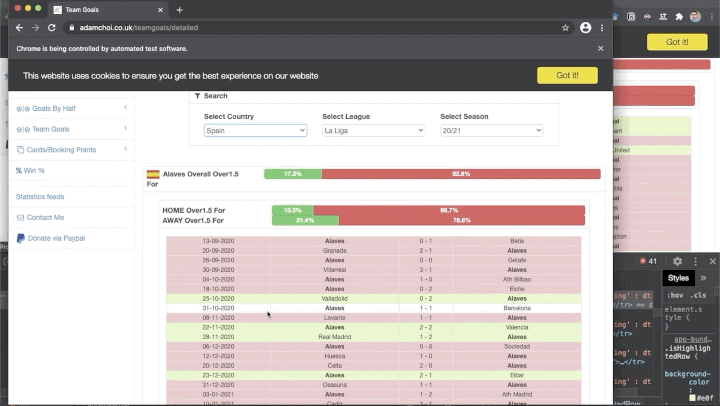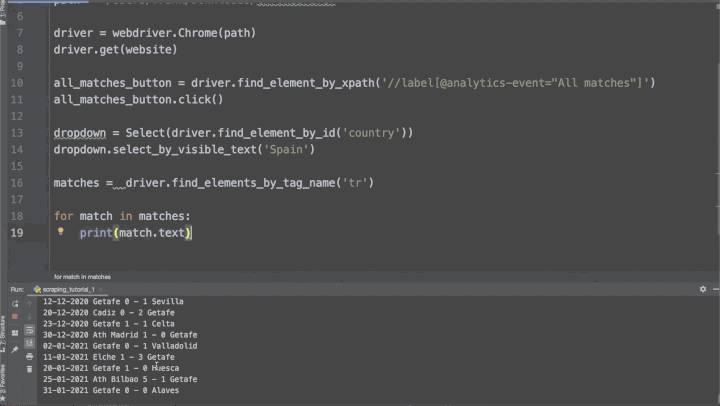
Большинство сайтов со спортивными данными использует JavaScript для динамического обновления этих данных. Это значит, что мы не сможем использовать для этого проекта библиотеку Beautiful Soup. Вместо этого мы используем Selenium для нажатия на кнопки, выбора элементов раскрывающихся меню и извлечения нужных нам данных.
Код для реализации этого проекта выложен на моём Github. Можно усложнить этот проект, находя команды, которые обычно забивают больше голов в матче. После этого можно будет создать отчёт, из которого можно понять, в каких матчах есть тенденция к большему количеству голов. Это поможет вам принимать более правильные решения при анализе футбольного матча. По ссылке ниже можно найти руководство по созданию этой последней части проекта.
Раньше я платил по 180 долларов в год за инструмент, позволяющий делать прибыльные ставки. В этом году я написал свой на Python. [en]
Поиск работы благодаря веб-скрейпингу становится проще. Такие задачи, как просмотр нескольких страниц в поисках новых вакансий, проверка требований к кандидату и диапазона зарплат может ежедневно занимать примерно по двадцать минут, если делать это вручную. К счастью, всё это можно автоматизировать при помощи кода.
В этом проекте мы создаём бота, занимающегося скрейпингом портала вакансий для получения требований к кандидату по конкретной работе и предлагаемой зарплате. Для этого проекта можно использовать Beautiful Soup или Selenium, но решения при этом будут различаться.
Если вы пользуетесь Beautiful Soup, то учитывайте только те страницы, на которых есть те данные, которые нужно скрейпить. Чтобы освоиться с проектом, можно посмотреть этот видео-туториал.
Несмотря на это, я бы рекомендовал использовать Selenium, так как он позволяет производить больше действий на веб-сайте. Лучше всего то, что можно запускать код после каждого действия и наблюдать в браузере за шагами, которые выполняет бот. Чтобы решить эту задачу в Selenium, задумайтесь о всех шагах, которые вы обычно выполняете, чтобы получить данные с портала вакансий. Например, вы заходите на веб-сайт, вводите название должности, нажимаете на кнопку поиска и просматриваете каждую вакансию, чтобы извлечь всю важную информацию. После этого воспроизведите эти шаги на Python с помощью библиотеки Selenium.
Если вы стараетесь найти лучшую цену на конкретный товар, шоппинг может занимать очень много времени. Поиск лучшей цены машины, телевизора или одежды на нескольких сайтах может занимать многие часы; к счастью, благодаря нашему новому проекту веб-скрейпинга на это будет тратиться пара минут.
Это самый сложный проект в этой статье и он разделён на две части. Во-первых, зайдите в любимый онлайн-магазин и соберите данные о продуктах, например, название, цену, скидку и ссылки на них, чтобы можно было отслеживать их в дальнейшем. Если вы планируете скрейпить множество страниц, то рекомендую использовать для этого проекта библиотеку Scrapy, потому что это самая быстрая библиотека для веб-скрейпинга на Python. Чтобы начать работу над проектом, можно изучить этот туториал.
Во второй части проекта нам нужно отслеживать извлечённые цены, чтобы когда цена на конкретный продукт значительно снижалась, мы получали бы уведомление.
Помните, что последний проект можно адаптировать и под другие интересующие вас области. Например:
- Скрейпинг курсов акций
- Скрейпинг коэффициентов букмекеров
- Скрейпинг цен криптовалют
Например, вместо скрейпинга цен на товары я скрейпил коэффициенты ставок на спорт. Принцип тот же — находишь лучшие коэффициенты среди нескольких букмекеров, а затем получаешь уведомление, когда коэффициент увеличивается. Если вы хотите реализовать этот проект, то прочитайте моё руководство.
Скрейпим сайт букмекера за десять минут. [en]
На правах рекламы
Устанавливайте любые операционные системы и выполняйте разнообразные задачи на наших облачных серверах с процессорами Intel Xeon Gold. Сервер готов к работе через минуту после оплаты!
Подписывайтесь на наш чат в Telegram.

