[Перевод] Черновик книги Эндрю Ына «Жажда машинного обучения», главы 1-7

Представляю вниманию Хабра-сообщества перевод первых семи глав из доступных в настоящий момент четырнадцати. Замечу, что это не финальный вариант книги, а черновик. В нем есть ряд неточностей. Эндрю Ын предлагает писать свои комментарии и замечания сюда. Начинает автор с вещей, которые кажутся очевидными. Дальше ожидаются более сложные концепции.
1. Почему стратегии машинного обучения?
Машинное обучение (ML) является основой бесконечного количества важных продуктов и сервисов, включая поиск в интернет, анти-спам, распознование речи, рекомендательные системы и так далее. Я предполагаю, что вы и ваша команда работают над продуктами с алгоритмами машинного обучения, и вы хотите добиться быстрого прогресса в разработке. Эта книга поможет вам в этом.
Скажем, вы создаёте стартап, который будет обеспечивать непрерывный поток фотографий котиков для любителей кошек. Вы используете нейронную сеть для создания системы компьютерного зрения для обнаружения кошек на фото, снятых смартфонами.

Но, к сожалению, точность вашего алгоритма не достаточно высокая. Вы находитесь под колоссальным давлением, вы должны улучшить «детектор кошек». Что же делать?
У вашей команды есть масса идей, например:
• Собрать больше данных: взять больше изображений котиков.
• Собрать более разнообразную обучающую выборку: например, кошек в необычных позах, кошек редкого окраса, фотографии, полученные с разными настройками камеры, …
• Дольше обучать модель, использовать больше итераций градиентного спуска.
• Попробовать нейронную сеть большего размера: больше слоев/связей/параметров.
• Экспериментировать с сетью меньшего размера.
• Добавить регуляризацию, например, L2.
• Изменить архитектуру сети: функцию активации, число скрытых слоев и т.д.
• …
Если выбор среди возможных альтернатив будет удачным, то удастся создать лидирующую систему поиска фотографий кошек, и это приведет компанию к успеху. Если же выбор будет неудачным, то потеряете месяцы. Как же действовать в такой ситуации?
Эта книга расскажет вам как. Большинство задач машинного обучения оставляет ключевые подсказки, которые говорят, что полезно попробовать, а что нет. Умение видеть такие подсказки может сэкономить месяцы и годы времени на разработку.
После прочтения этой книги, вы будете знать, как задавать направления разработки в проекте с алгоритмами машинного обучения. Однако ваши коллеги могут не понимать, почему вы выбрали то или иное направление. Возможно, вы захотите, чтобы ваша команда определила метрику качества в виде одного числового параметра, но коллеги несогласны использовать только один показатель. Как убедить их? Вот почему я сделал главы в этой книге короткими: достаточно напечатать и дать коллегам прочитать 1–2 страницы ключевой информации, которую им полезно знать.
Незначительные изменения в приоритете задач могут дать огромный эффект для производительности команды. Я надеюсь, вы сможете стать супергероем, если поможете своей команде сделать подобные изменения.
3. Что вы должны знать?Если вы изучали курс «Машинное обучение» на Coursera или имеете опыт применения алгоритмов обучения с учителем (supervised learning), то этого достаточно чтобы понять текст книги. Я предполагаю, что вы знакомы с методами обучения с учителем: нахождения функции, которая по значениям х позволяет получить y для всех х, имея размеченную обучающую выборку для некоторых (x, y). К алгоритмам такого рода относятся, например, линейная регрессия, логистическая регрессия и нейронные сети. Существует множество областей машинного обучения, но большинство практических результатов достигнуты с помощью алгоритмов обучения с учителем.
Я буду часто говорить о нейронных сетях (NN) и глубинном обучении (deep learning). Вам потребуется только общее понимание их концепций. Если вы не знакомы с понятиями, упомянутыми выше, то сначала посмотрите видео лекций курса «Машинное обучение» на Coursera.
4. Какие масштабные изменения способствуют прогрессу в машинном обучении?Многие идеи глубинного обучения / нейронных сетей многие годы витали в воздухе. Почему именно сейчас мы начали применять их? Наибольший вклад в прогресс последних лет дали два фактора:
• Доступность данных: сейчас люди постоянно пользуются цифровыми устройствами (лаптопы, смартфоны и т.п.), их цифровая деятельность генерирует огромные объемы данных, которые мы можем «скормить» нашим алгоритмам.
• Вычислительные мощности: только несколько лет назад стало возможным массово обучать достаточно большие нейронные сети, чтобы почуствовать преимущества от огромных наборов данных, которые доступны сейчас.
Обычно, показатель качества «старых» алгоритмов, таких как логистическая регрессия, выходит на постоянный уровень, даже если вы накопили больше данных для обучения, т.е. с некоторого предела качество работы алгоритма перестает улучшаться при увеличении обучающей выборки. Если вы обучаете маленькую нейронную сеть на такой же задаче, то можете получить результат немного лучше. Здесь под «маленькой» нейронной сетью я имею ввиду сеть с малым количеством скрытых слоёв, связей и параметров. В конце концов, если вы обучаете всё бОльшую и бОльшую сеть, то вы сможете получить результаты еще лучше.
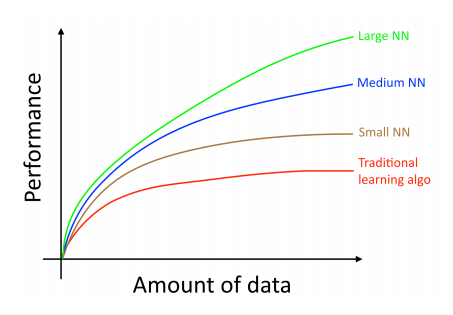
Примечание автора: Этот график показывает, что NN работает лучше традиционных алгоритмов ML в том числе и в случае малого количества данных для обучения. Это менее корректно, чем для огромного количества данных. Для малых выборок традиционные алгоритмы могут быть лучше или хуже в зависимости от признаков, сконструированных вручную. Например, если у вас есть только 20 образцов/прецедентов для обучения, то не имеет большого значения, используете ли вы логистическую регрессию или нейронную сеть, набор признаков даст значительно больший эффект по сравнению с выбором алгоритма. Но если у вас есть миллион образцов для обучения, то я предпочитаю использовать нейронную сеть.
Таким образом, наилучшие результаты достигаются:
1. когда обучается очень большая нейронная сеть (так чтобы быть на зеленой кривой на рисунке);
2. когда используется огромное количество данных для обучения.
Также важно и много других деталей, таких как архитектура сети, где постоянно появляется множество инноваций. Тем не менее, одним из наиболее надёжных способов улучшить качество работы алгоритма остается (1) обучить большую NN и (2) использовать больше данных для обучения. На практике следовать пунктам (1) и (2) необычайно сложно. Эта книга обсуждает детали данного процесса. Мы начнем с общих подходов, которые полезны как для традиционных алгоритмов ML так и для NN, затем отберём наиболее эффективные стратегии для построения систем глубинного обучения.
5. Какие должны быть выборки?Примечание переводчика: Эндрю Ын использует термин «development set» для обозначения выборки, на которой происходит настройка параметров модели. В настоящее время эту выборку чаще называют «validation set» — валидационная выборка. Действительно, термин «валидация» не соответствует тому многообразию задач, для которых применяется данная выборка, и название «development set» более соответствует status quo. Однако, мне не удалось найти хорошего перевода для «development set», поэтому я пишу «выборка для разработки» или «рабочая (development) выборка» .
Давайте вернемся к примеру с фотографиями котиков. Итак, вы разрабатываете мобильное приложение, пользователи загружают различные фотографии в ваше приложение, которое автоматически находит среди них фотографии кошек. Ваша команда создала большой набор данных путем загрузки с web-сайтов фотографий кошек (положительные образцы) и «не-кошек» (отрицательные образцы). Затем этот набор данных был разделен на обучающую (70%) и тестовую (30%) выборки. Используя данные выборки, был создан «детектор кошек», который хорошо работал для объектов из тестовой и обучающей выборок. Но когда данный классификатор был реализован в мобильном приложении, вы обнаружили, что качество его работы реально низкое! Что же случилось?
Вы выяснили, что фотографии, которые пользователи загружают в ваше приложение, выглядят иначе, чем изображения с web-сайтов, которые составляют обучающую выборку: пользователи загружают фото, снятые смартфонами, эти изображения имеют иное разрешение, менее чёткие, и сцена не идеально освещена. Поскольку обучающая и тестовая выборки были составлены из изображений с web-сайтов, то ваш алгоритм не обобщается на реальное распределение данных, для которых и разрабатывается алгоритм, т.е. не обобщается на фото со смартфонов.
До эры «больших данных» общим правилом в машинном обучении было случайным образом разбивать набор данных в отношении 70% / 30% на обучающую и тестовую выборки. Такой подход может сработать, но это плохая идея для всё бОльшего и бОльшего количества задач, где распределение данных в обучающей выборке отличается от распределения данных, для которых, в конечном счете, решается задача.
Обычно мы определяем три выборки:
• Обучающую, на которой запускается алгоритм обучения;
• Для разработки (development set), которая используется для настройки параметров, выбора признаков и принятия других решений относительно алгоритма обучения, иногда такую выборку называют удерживаемой для перёкрестной проверки (hold-out cross validation set);
• Тестовую, на которой оценивают качество работы алгоритма, но на её основе не принимают никаких решений о том, какой алгоритм обучения или параметры использовать.
Как только вы сделаете тестовую выборку и выборку для разработки, ваша команда начнёт пробовать множество идей, например различные параметры алгоритма обучения, чтобы увидеть что работает лучше. Эти выборки позволяют быстро оценить, на сколько хорошо работает модель. Другими словами, цель тестовой и рабочей (development) выборок направить вашу команду в сторону наиболее важных изменений на пути разработки системы машинного обучения. Таким образом, вы должны сделать следующее: создать рабочую и тестовую выборки так, чтобы они соответствовали данным, которые вы ожидаете получить в будущем, и на которых ваша система должна хорошо работать. Другими словами, ваша тестовая выборка должна не просто включать 30% доступных данных, особенно, если в будущем вы ожидаете данные (фотографий со смартфонов), которые отличаются от данных в обучающей выборке (изображения с web-сайтов).
Если вы еще не начали распространять ваше мобильное приложение, то пока у вас нет пользователей, и нет возможности собирать именно те данные, которые вы ожидаете в будущем. Но вы можете попробовать аппроксимировать их. Например, попросите ваших друзей и знакомых сделать фотографии мобильными телефонами и прислать их вам. Как только вы опубликуете мобильное приложение, вы сможете обновить рабочую (development) и тестовую выборки реальными данными пользователей.
Если же нет никакой возможности получения данных, которые аппроксимируют ожидаемые в будущем, то, пожалуй, вы можете начать работать с изображениями с web-сайтов. Но вы должны чётко понимать, что это риск создать систему, которая имеет низкую обобщающую способность для данной задачи.
Надо оценить, сколько сил и времени вы готовы инвестировать в создание двух мощных выборок: для разрабоки и тестовой. Не делайте слепых предположений о том, что распределение данных в обучающей выборке точно такое же как и в тестовой. Попробуйте подобрать тестовые примеры, которые отражают то, на чём в конечном итоге должно хорошо работать, а не любые данные, которые вам посчастливилось иметь для обучения.
6. Рабочая (development) и тестовая выборки должны быть получены из одного источника и иметь одинаковое распределениеФотографии «кошачьего» мобильного приложения сегментированы на четыре региона, которые соответствуют крупнейшим рынкам приложений: США, Китай, Индия и остальной мир. Вы можете создать рабочую выборку из данных двух случайно выбранных сегментов, а в тестовую выборку поместить данные двух оставшихся. Правильно? Нет, ошибка! Как только вы определите эти две выборки, команда будет сосредоточена на улучшении качества для рабочей выборки. Следовательно эта выборка должна отражать всю задачу, которую вы решаете, а не её часть: требуется хорошо работать на всех рынках, а не только на двух.
Существует ещё одна проблема в несоответствии распределений данных в рабочей и тестовой выборках: есть вероятность, что ваша команда создаст что-то хорошо работающее на выборке для разработки, а затем убедится, что это плохо работает на тестовой выборке. В результате будет много разочарований и напрасно потраченных усилий. Избегайте такого.
Положим, ваша команда разработала систему, которая хорошо работает на выборке для разработки, но не на тестовой. Если обе выборки получены из одного источника/распределения, то есть довольно чёткий диагноз того, что пошло не так: вы переобучились (overfit) на рабочей выборке. Очевидное лекарство: увеличьте объем данных в рабочей выборке. Но если эти две выборки не соответствуют друг другу, то есть много вещей, которые могли «пойти не так». Вообще, довольно сложно работать над приложениями с алгоритмами машинного обучения. Несоответствие между рабочей и тестовой выборками вносит дополнительную неопределенность в вопрос: приведет ли улучшение в работе на рабочей выборке к улучшениям на тестовой. Имея такое несоотвествие, сложно понять, что же не работает, трудно расставить приоритеты: что следовало бы попробовать в первую очередь.
Если же вы работаете над задачей, когда выборки вам предоставляет сторонняя компания/организация, то рабочая и тестовая выборки могут иметь разные распределения, и вы не можете повлиять на эту ситуацию. В этом случае, удача, а не мастерство, окажет большее влияние на качество работы модели. Обучение модели на данных, имеющих одно распределение, для обработки данных (ещё и с высокой обобщающей способностью), имеющих другое распределение, является важной исследовательской проблемой. Но если вашей целью является получение практического результата, а не исследования, то я рекоммендую использовать для рабочей и тестовой выборок данные из одного источника и одинаково распределённых.
7. Какого размера должны быть тестовая и рабочая (development) выборки?Рабочая выборка должна быть достаточно большой, чтобы обнаруживать разницу между алгоритмами, которые вы пробуете. Например, если классификатор A даёт точность 90.0%, а классификатор B точность 90.1%, то рабочая выборка из 100 образцов не даст увидеть изменение в 0.1%. В целом, рабочая выбока из 100 образцов слишком мала. Общей практикой являются выборки размером от 1000 до 10000 образцов. С 10000 образцов у вас есть шанс увидеть улучшение в 0.1%.
Примечание автора: теоретически можно проводить статистические тесты для того, чтобы определить привели ли изменения в алгоритме к значимым изменениям на рабочей выборке, но на практике большинство команд не заморачивается с этим (если только они не пишут научную статью), я также не нахожу такие тесты полезными для оценки промежуточного прогресса.
Для развитых и важных систем, таких как реклама, поиск, рекомендательные системы, я видел команды, которые стремились достичь улучшений даже в 0.01%, так как это непосредственно влияло на прибыль их компаний. В этом случае, рабочая выборка должна быть гораздо больше 10000, чтобы быть в состоянии определить малейшие изменения.
Что можно сказать о размере тестовой выборки? Она должна быть достаточно большой, чтобы оценить с высокой уверенностью качество работы системы. Одной популярной эвристикой было использовать 30% имеющихся данных для тестовой выборки. Это работает достаточно хорошо, когда вы имеете не очень большое количество данных, скажем, от 100 до 10000 образцов. Но в эпоху «больших данных», когда существуют задачи с более чем миллионом образцов для обучения, доля данных в рабочей и тестовой выборке сокращается, даже когда абсолютный размер этих выборок растет. Нет необходимости иметь рабочую и тестовые выборки гораздо больше того объема, который позволяет оценить качество работы ваших алгоритмов.
