[Перевод] C# является языком низкого уровня?
Я большой поклонник всего, что делает Фабьен Санглард, мне нравится его блог, и я прочитал обе его книги от корки до корки (о них рассказывали в недавнем подкасте Hansleminutes).
Недавно Фабьен написал отличный пост, где расшифровал крошечный рейтрейсер, деобфусцировав код и фантастически красиво объяснив математику. Я действительно рекомендую найти время, чтобы прочитать это!
Но это заставило меня задуматься, можно ли перенести этот код C++ на C#? Поскольку на основной работе мне в последнее время приходится довольно много писать на C++, я подумал, что могу попробовать.
Но что более важно, я хотел получить лучшее представление о том, является ли C# языком низкого уровня?
Немного другой, но связанный с этим вопрос: насколько C# подходит для «системного программирования»? На эту тему я действительно рекомендую отличный пост Джо Даффи от 2013 года.
Я начал с простого переноса деобфусцированного кода C++ строчка за строчкой на C#. Это было довольно просто: похоже, всё-таки правду говорят, что C# — это C++++!!!
В примере показана основная структура данных — 'vector', вот сравнение, C++ слева, C# справа:

Итак, есть несколько синтаксических различий, но поскольку .NET позволяет определять собственные типы значений, я смог получить ту же функциональность. Это важно, потому что обработка 'vector' как структуры означает, что мы можем получить лучшую «локальность данных», и не нужно вовлекать сборщик мусора .NET, поскольку данные будут поступать в стек (да, я знаю, что это деталь реализации).
Дополнительно о structs или «типах значений» в .NET см. здесь:
В частности, в последнем посте Эрика Липперта мы находим такую полезную цитату, которая даёт понять, что такое на самом деле «типы значений»:
Конечно, наиболее важным фактом о типах значений являются не детали реализации, как они выделяются, а скорее исконное семантическое значение «типа значения», а именно то, что он всегда копируется «по значению». Если бы важной была информация о выделении, мы бы назвали их «типами кучи» и «типами стека». Но в большинстве случаев это неважно. Большую часть времени актуальной является семантика копирования и идентификации.
Теперь посмотрим, как выглядят некоторые другие методы в сравнении (снова C++ слева, C# справа), сначала RayTracing(..):
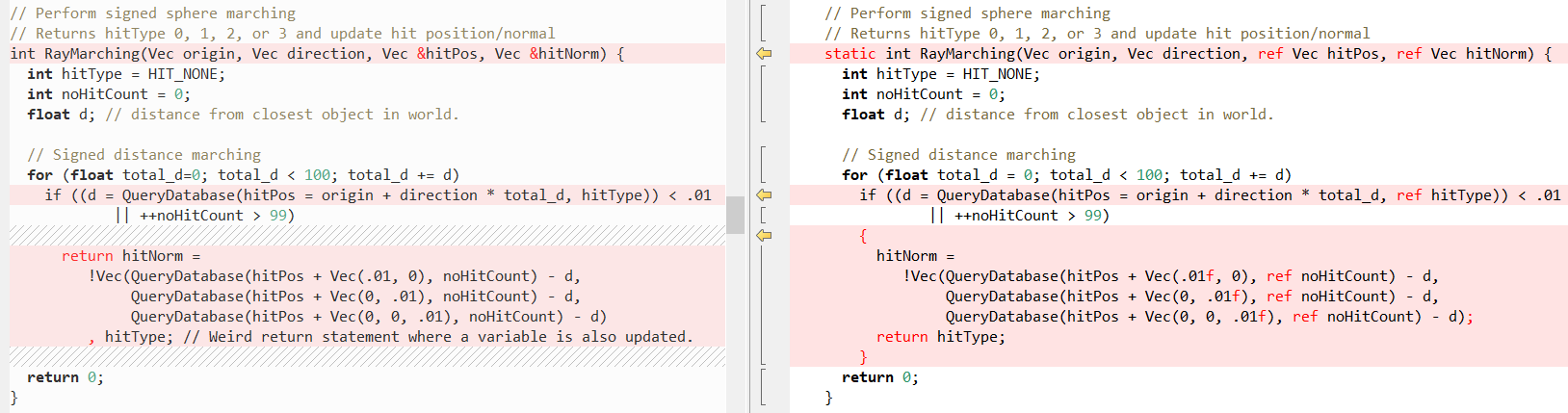
Затем QueryDatabase (..):
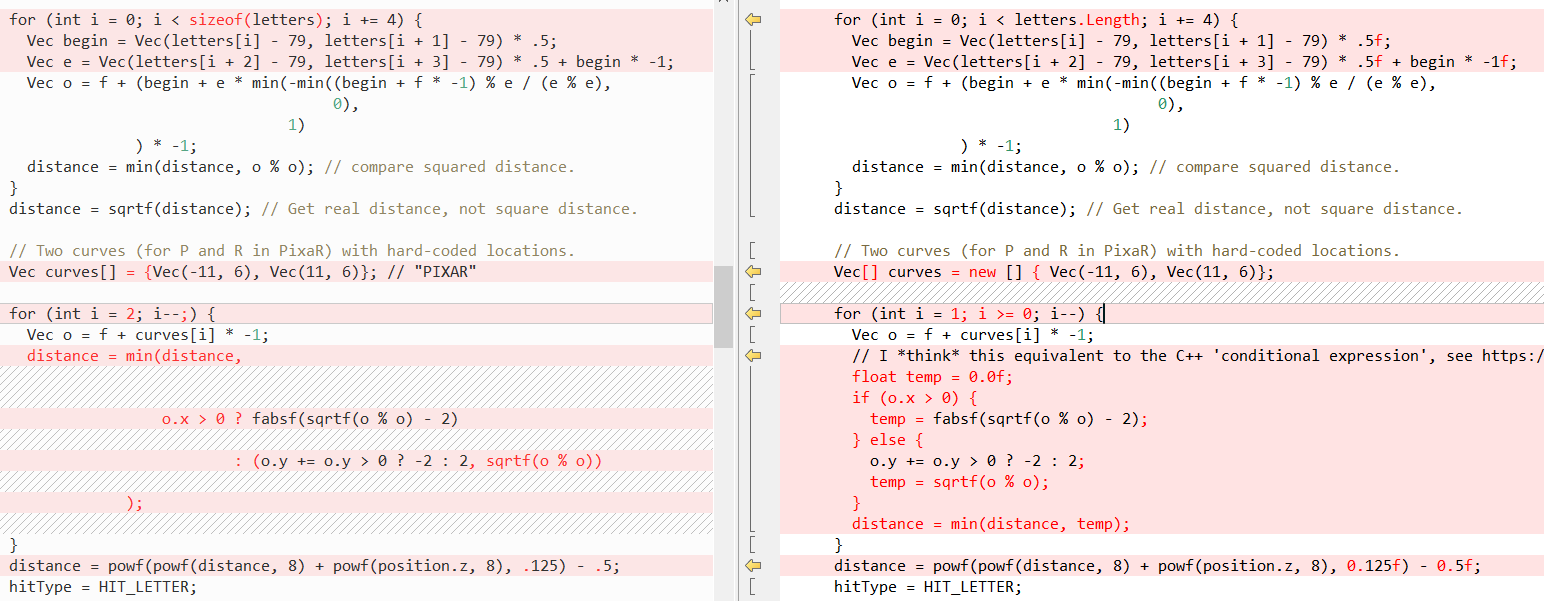
(см. пост Фабиана с объяснением, что делают эти две функции)
Но опять же дело в том, что C# позволяет очень легко писать код C++! В этом случае нам больше всего помогает ключевое слово ref, которое позволяет передавать значение по ссылке. Мы довольно давно использовали ref в вызовах методов, но в последнее время предпринимаются усилия, чтобы разрешить ref в других местах:
Теперь иногда использование ref повысит производительность, потому что тогда структуру не нужно копировать, см. бенчмарки в посте Адама Стиникса и «Ловушки производительности ref locals и ref returns в C#» для дополнительной информации.
Но самое важное то, что такой сценарий обеспечивает нашему порту C# то же поведение, что у исходного кода C++. Хотя хочу отметить, что так называемые «управляемые ссылки» не совсем такие же, как «указатели», в частности, вы не сможете на них выполнять арифметику, подробнее об этом см. здесь:
Производительность
Таким образом, код хорошо портировался, но производительность тоже имеет значение. Особенно в рейтрейсере, который может обсчитывать кадр несколько минут. Код C++ содержит переменную sampleCount, которая управляет конечным качеством изображения, при этом sampleCount = 2 выглядит следующим образом:

Явно не очень реалистично!
Но когда доберётесь до sampleCount = 2048, всё выглядит гораздо лучше:

Но запуск с sampleCount = 2048 отнимает очень много времени, поэтому все остальные прогоны выполняем со значением 2, чтобы уложиться хотя бы в минуту. Изменение sampleCount влияет только на количество итераций самого внешнего цикла кода, см. этот gist для объяснения.
Результаты после «наивного» построчного порта
Чтобы содержательно сравнить C++ и C#, я использовал инструмент time-windows, это порт юниксовой команды time. Первоначальные результаты выглядели так:
| C++ (VS 2017) | .NET Framework (4.7.2) | .NET Core (2.2) | |
|---|---|---|---|
| Время (сек) | 47,40 | 80,14 | 78,02 |
| В ядре (сек) | 0,14 (0,3%) | 0,72 (0,9%) | 0,63 (0,8%) |
| В user-space (сек) | 43,86 (92,5%) | 73,06 (91,2%) | 70,66 (90,6%) |
| Количество ошибок page fault | 1143 | 4818 | 5945 |
| Рабочий набор (КБ) | 4232 | 13 624 | 17 052 |
| Вытесняемая память (КБ) | 95 | 172 | 154 |
| Невытесняемая память | 7 | 14 | 16 |
| Файл подкачки (КБ) | 1460 | 10 936 | 11 024 |
Изначально мы видим, что код C# немного медленнее, чем версия C++, но он становится лучше (см. ниже).
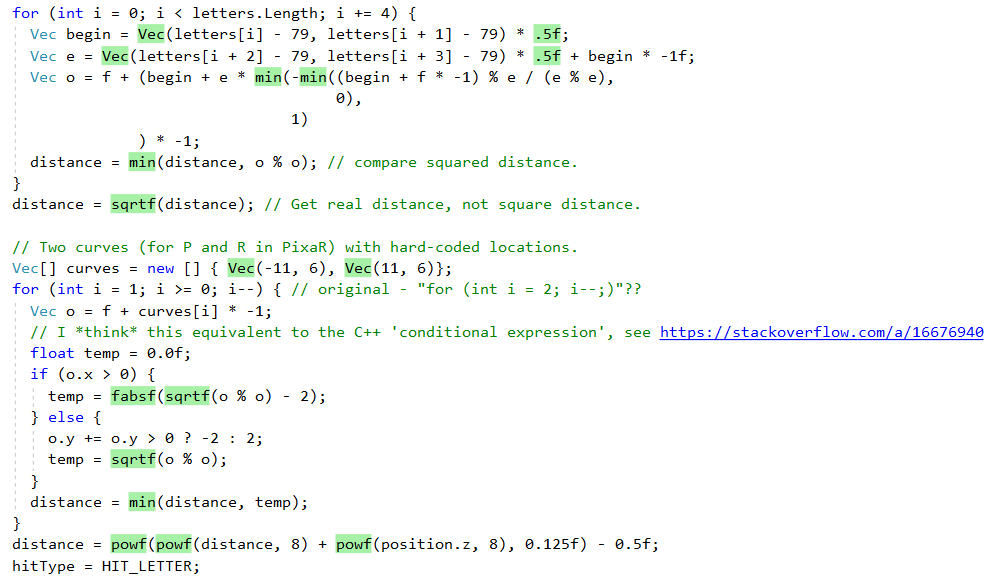
Но давайте сначала посмотрим, что нам делает .NET JIT даже с этим «наивным» построчным портом. Во-первых, он делает хорошую работу во встраивании меньших «хелпер-методов». Это видно на выдаче великолепного инструмента Inlining Analyzer (зелёный = встроенный):
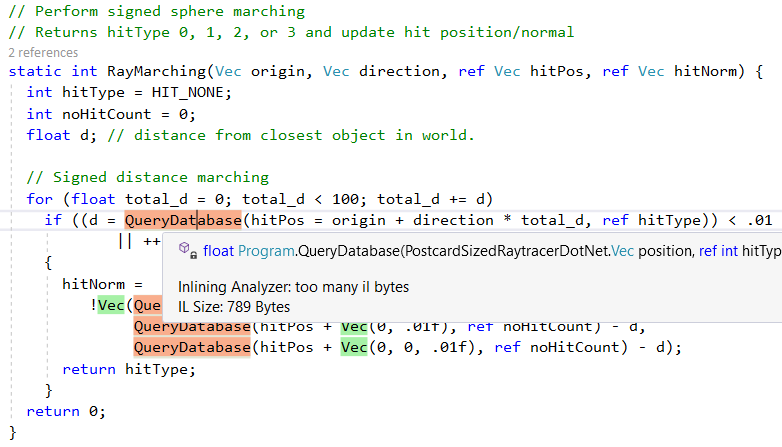
Однако он встраивает не все методы, например, из-за сложности пропускается QueryDatabase(..):
Другая функция компилятора .NET Just-In-Time (JIT) — преобразование определённых вызовов методов в соответствующие инструкции CPU. Мы можем видеть это в действии с функцией оболочки sqrt, вот исходный код C# (обратите внимание на вызов Math.Sqrt):
// intnv square root
public static Vec operator !(Vec q) {
return q * (1.0f / (float)Math.Sqrt(q % q));
}
И вот ассемблерный код, который генерирует .NET JIT: здесь нет вызова к Math.Sqrt и используется процессорная инструкция vsqrtsd:
; Assembly listing for method Program:sqrtf(float):float
; Emitting BLENDED_CODE for X64 CPU with AVX - Windows
; Tier-1 compilation
; optimized code
; rsp based frame
; partially interruptible
; Final local variable assignments
;
; V00 arg0 [V00,T00] ( 3, 3 ) float -> mm0
;# V01 OutArgs [V01 ] ( 1, 1 ) lclBlk ( 0) [rsp+0x00] "OutgoingArgSpace"
;
; Lcl frame size = 0
G_M8216_IG01:
vzeroupper
G_M8216_IG02:
vcvtss2sd xmm0, xmm0
vsqrtsd xmm0, xmm0
vcvtsd2ss xmm0, xmm0
G_M8216_IG03:
ret
; Total bytes of code 16, prolog size 3 for method Program:sqrtf(float):float
; ============================================================
(чтобы получить такую выдачу, следуйте этим инструкциям, используйте надстройку «Disasmo» VS2019 или посмотрите на SharpLab.io)
Эти замены тоже известны как «встроенные» (intrinsics), и в коде ниже мы можем видеть, как JIT генерирует их. Этот фрагмент показывает сопоставление только для AMD64, но JIT также нацелен на X86, ARM и ARM64, полный метод здесь.
bool Compiler::IsTargetIntrinsic(CorInfoIntrinsics intrinsicId)
{
#if defined(_TARGET_AMD64_) || (defined(_TARGET_X86_) && !defined(LEGACY_BACKEND))
switch (intrinsicId)
{
// AMD64/x86 has SSE2 instructions to directly compute sqrt/abs and SSE4.1
// instructions to directly compute round/ceiling/floor.
//
// TODO: Because the x86 backend only targets SSE for floating-point code,
// it does not treat Sine, Cosine, or Round as intrinsics (JIT32
// implemented those intrinsics as x87 instructions). If this poses
// a CQ problem, it may be necessary to change the implementation of
// the helper calls to decrease call overhead or switch back to the
// x87 instructions. This is tracked by #7097.
case CORINFO_INTRINSIC_Sqrt:
case CORINFO_INTRINSIC_Abs:
return true;
case CORINFO_INTRINSIC_Round:
case CORINFO_INTRINSIC_Ceiling:
case CORINFO_INTRINSIC_Floor:
return compSupports(InstructionSet_SSE41);
default:
return false;
}
...
}
Как видим, некоторые методы реализованы так, например, Sqrt и Abs, а для других используется функции среды выполнения C++, например, powf.
Весь этот процесс очень хорошо объясняется в статье «Как Math.Pow () реализован в .NET Framework?», его можно увидеть также в исходниках CoreCLR:
Результаты после простых улучшений производительности
Интересно, можно ли с ходу улучшить наивный построчный порт. После некоторого профилирования я сделал два основных изменения:
- Удаление инициализации встроенного массива
- Замена функций
Math.XXX(..)на аналогиMathF.ХХХ()
Более подробно эти изменения объясняются ниже.
Удаление инициализации встроенного массива
Для получения дополнительной информации о том, почему это необходимо, см. этот отличный ответ на Stack Overflow от Андрея Акиншина, вместе с бенчмарками и ассемблерным кодом. Он приходит к следующему выводу:
Вывод
- Кэширует ли .NET жёстко закодированные локальные массивы? Вроде тех, что помещает в метаданные компилятор Roslyn.
- В этом случае будут накладные расходы? К сожалению, да: для каждого вызова JIT будет копировать содержимое массива из метаданных, что занимает дополнительное время по сравнению со статическим массивом. Среда выполнения также выделяет объекты и создаёт трафик в памяти.
- Стоит ли об этом беспокоиться? Возможно. Если это горячий метод и вы хотите достичь хорошего уровня производительности, нужно использовать статический массив. Если это холодный метод, который не влияет на производительность приложения, вероятно, нужно написать «хороший» исходный код и поместить массив в область метода.
Внесённые изменения можете увидеть в этом diff.
Использование функций MathF вместо Math
Во-вторых, и это самое главное, я значительно улучшил производительность, сделав следующие изменения:
#if NETSTANDARD2_1 || NETCOREAPP2_0 || NETCOREAPP2_1 || NETCOREAPP2_2 || NETCOREAPP3_0
// intnv square root
public static Vec operator !(Vec q) {
return q * (1.0f / MathF.Sqrt(q % q));
}
#else
public static Vec operator !(Vec q) {
return q * (1.0f / (float)Math.Sqrt(q % q));
}
#endif
Начиная с .NET Standard 2.1 существуют конкретные реализации float общих математических функций. Они расположены в классе System.MathF. Дополнительно об этом API и его реализации см. здесь:
После этих изменений разница в производительности кода на C# и C++ сократилась примерно до 10%:
| C++ (VS C++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON | |
|---|---|---|---|---|
| Время (сек) | 41,38 | 58,89 | 46,04 | 44,33 |
| В ядре (сек) | 0,05 (0,1%) | 0,06 (0,1%) | 0,14 (0,3%) | 0,13 (0.3%) |
| В user-space (сек) | 41,19 (99,5%) | 58,34 (99,1%) | 44,72 (97,1%) | 44,03 (99,3%) |
| Количество ошибок page fault | 1119 | 4749 | 5776 | 5661 |
| Рабочий набор (КБ) | 4136 | 13 440 | 16 788 | 16 652 |
| Вытесняемая память (КБ) | 89 | 172 | 150 | 150 |
| Невытесняемая память | 7 | 13 | 16 | 16 |
| Файл подкачки (КБ) | 1428 | 10 904 | 10 960 | 11 044 |
TC — многоуровневая компиляция, Tiered Compilation (полагаю, её включат по умолчанию в .NET Core 3.0)
Для полноты, вот результаты нескольких прогонов:
| Прогон | C++ (VS C++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON |
|---|---|---|---|---|
| TestRun-01 | 41,38 | 58,89 | 46,04 | 44,33 |
| TestRun-02 | 41,19 | 57,65 | 46,23 | 45,96 |
| TestRun-03 | 42,17 | 62,64 | 46,22 | 48,73 |
Примечание: разница между .NET Core и .NET Framework обусловлена отсутствием MathF API в .NET Framework 4.7.2, дополнительные сведения см. в тикете о поддержке .Net Framework (4.8?) для netstandard 2.1.
Уверен, что код можно ещё улучшить!
Если вы заинтересованы в том, чтобы устранить разницу в производительности, вот код C#. Для сравнения можете смотреть ассемблерный код C++ от великолепного сервиса Compiler Explorer.
Наконец, если это поможет, вот выдача профилировщика Visual Studio с отображением «горячего пути» (после улучшений производительности, описанных выше):
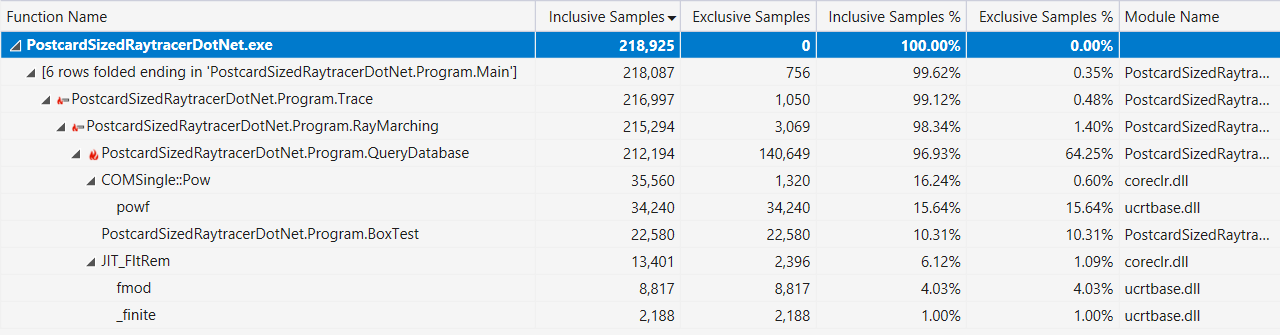
Или более конкретно:
Какие языковые особенности C#/F#/VB.NET или функциональность BCL/Runtime означают «низкоуровневое»* программирование?
* да, я понимаю, что «низкий уровень» — это субъективный термин.
Примечание: у каждого разработчика C# своё представление о том, что такое «низкий уровень», эти функции будут приняты как должное программистами C++ или Rust.
Вот список, который я составил:
- ref returns и ref locals
- «Передача и возвращение по ссылке, чтобы избежать копирования больших структур. Безопасные типы и память могут быть даже быстрее, чем небезопасные!»
- Небезопасный код в .NET
- «Основной язык C#, как он определён в предыдущих главах, сильно отличается от C и C++ тем, что в нём отсутствуют указатели как тип данных. Вместо этого C# предоставляет ссылки и возможность создавать объекты, регулируемые сборщиком мусора. Этот дизайн в сочетании с другими функциями делает C# гораздо более безопасным языком, чем C или C++».
- Управляемые указатели в .NET
- «Существует другой тип указателя в CLR — управляемый указатель. Его можно определить как более общий тип ссылки, который может указывать на другие местоположения, а не только на начало объекта».
- Серия C# 7, часть 10: Span
и управление универсальной памятью - «System.Span
— это только тип стека ( ref struct), который обёртывает все шаблоны доступа к памяти, это тип для универсального непрерывного доступа к памяти. Можно представить реализацию Span с фиктивной ссылкой и длиной, которая принимает все три типа доступа к памяти».
- «System.Span
- Совместимость («Руководство по программированию на C#»)
- «Платформа .NET Framework обеспечивает взаимодействие с неуправляемым кодом через службы вызова платформы, пространства имён
System.Runtime.InteropServices, совместимость C++ и совместимость COM (COM-взаимодействие)».
- «Платформа .NET Framework обеспечивает взаимодействие с неуправляемым кодом через службы вызова платформы, пространства имён
Я также кинул клич в твиттере и получил гораздо больше вариантов для включения в список:
- Бен Адамс: «Встроенные средства для платформ (инструкции CPU)»
- Марк Грэвелл: «SIMD через Vector (что хорошо сочетается со Span) это *довольно* низкий уровень; .NET Core должен (скоро?) предложить прямые встроенные средства CPU для более явного использования конкретных инструкций CPU»
- Марк Грэвелл: «Мощный JIT: вещи вроде пропуска диапазона (range elision) на массивах/интервалах, а также использование правил per-struct-T для удаления больших кусков кода, которые JIT точно знает, что они недоступны для этого T или на вашем конкретном CPU (BitConverter.IsLittleEndian, Vector.IsHardwareAccelerated и т. д.)»
- Кевин Джонс: «Я бы особенно упомянул классы
MemoryMarshalиUnsafe, и может несколько других вещей в пространствах имёнSystem.Runtime.CompilerServices» - Теодорос Чацигианнакис: «Также можно включить
__makerefи остальное» - damageboy: «Способность динамически генерировать код, который точно соответствует ожидаемому входу, учитывая, что последний будет известен только во время выполнения и может периодически меняться?»
- Роберт Хэкен: «Динамическая эмиссия IL»
- Виктор Байбеков: «Stackalloc не упоминался. Также возможность писать чистый IL (не динамический, поэтому сохраняется на вызове функции), например, использовать кэшированные
ldftnи вызывать их черезcalli. В VS2017 есть шаблон proj, который делает это тривиальным с помощью перезаписи методов extern + MethodImplOptions.ForwardRef + ilasm.ехе» - Виктор Байбеков: «MethodImplOptions.AggressiveInlining тоже «активирует низкоуровневое программирование» в том смысле, что позволяет писать высокоуровневый код со многими небольшими методами и по-прежнему контролировать поведение JIT для получения оптимизированного результата. В противном случае копипаст сотен LOC-методов…»
- Бен Адамс: «Использование тех же соглашений о вызовах (ABI), что и в базовой платформе, и p/invokes для взаимодействия?»
- Виктор Байбеков: «Ещё, поскольку вы упомянули #fsharp — у него есть ключевое слово
inline, которое выполняет работу на уровне IL до JIT, поэтому оно считалось важным на уровне языка. C# этого не хватает (до сих пор) для лямбд, которые всегда являются виртуальными вызовами, а обходные пути часто странные (ограниченные дженерики)» - Александре Мютель: «Новые встроенные SIMD, постпобработка Unsafe Utility класса/IL (например, custom, Fody и др.). Для C#8.0 предстоящие указатели функций…»
- Александре Мютель: «В отношении IL, F# напрямую поддерживает IL в языке, например»
- OmariO: «BinaryPrimitives. Низкоуровнево, но безопасно»
- Кодзи (Kozy) Мацуи: «Как насчёт собственного встроенного ассемблера? Это сложно и для инструментария, и для среды выполнения, но он может заменить текущее решение p/invoke и реализовать встроенный код, если такой имеется»
- Фрэнк A. Крюгер: «Ldobj, stobj, initobj, initblk, cpyblk»
- Конрад Кокоса: «Может быть, потоковое локальное хранилище? Буферы фиксированного размера? Вероятно, следует упомянуть неуправляемые ограничения и типы blittable:)»
- Себастьяно Мандала: «Всего лишь маленькое дополнение ко всему сказанному: как насчёт чего-то простого, такого как компоновка структур и как заполнение и выравнивание памяти и порядок полей могут повлиять на производительность кэша? Это то, что я и сам должен исследовать»
- Нино Флорис: «Константы, встраиваемые через readonlyspan, stackalloc, финализаторы, WeakReference, открытые делегаты, MethodImplOptions, MemoryBarriers, TypedReference, varargs, SIMD, Unsafe.AsRef, могут устанавливать типы структур в точном соответствии макету (используется для TaskAwaiter и его версии)»
Так что в итоге я бы сказал, что C#, безусловно, позволяет писать код, который выглядит как C++, и в сочетании с библиотеками времени выполнения и базового класса предоставляет много низкоуровневых функций.
Компилятор Unity Burst:
