[Перевод] Большие данные мертвы. Это нужно принять

Уже более десяти лет тот факт, что люди с трудом извлекают из своих данных полезную информацию, сбрасывают на чересчур большой размер этих данных. «Объем собираемой информации слишком велик для ваших хилых систем», — такой нам ставили диагноз. А лекарство, соответственно, заключалось в том, чтобы купить какую-нибудь новую причудливую технологию, которая сможет работать в больших масштабах. Конечно, после того, как целевая группа по Big Data покупала новые инструменты и мигрировала с устаревших систем, компании снова обнаруживали, что у них по-прежнему возникают проблемы с пониманием своих данных.
В результате постепенно некоторые начинали понимать, что размер данных вообще не был проблемой.
Мир в 2023 году выглядит иначе, чем когда зазвенели первые тревожные звоночки по поводу Big Data. Катаклизм обработки информации, который все предсказывали, не состоялся. Объемы данных, возможно, немного возросли, но возможности аппаратного обеспечения росли еще быстрее. Поставщики услуг все еще продвигают свои возможности масштабирования, но люди, которые сталкиваются с ними на практике, начинают задаваться вопросом, как они вообще связаны с их реальными проблемами.
А дальше будет и того интереснее.
Кто я такой и зачем меня слушать?
Больше 10 лет я был одним из тех, кто рассказывал всем о пользе Big Data. Я был инженером-основателем Google BigQuery. И как единственный инженер в команде, любящий публичные выступления, я ездил на конференции по всему миру, объясняя, как мы собираемся помочь людям устоять перед грядущим взрывом больших данных. Я переносил петабайт данных прямо стоя на сцене, показывая, что какими бы огромными и ужасными ни были ваши данные, вместе мы сможем справиться с ними!

На этом фото я выступаю на Big Data Spain в 2012 году, предупреждая об опасностях гигантских наборов данных и обещая спасение, если IT-компании переключатся на нашу технологию.
В течение следующих нескольких лет я потратил много времени на отладку проблем, с которыми сталкивались клиенты при работе с нашей BigQuery. Я написал две книги и действительно глубоко вникал в то, как использовался наш продукт. В 2018 году я переключился на управление: моя работа была разделена между общением с клиентами, многие из которых были крупнейшими компаниями в мире, и анализом показателей продукта.
Самое удивительное, что я узнал, это то, что большинство людей, использующих BigQuery, на самом деле не имеют больших данных. И даже те, кто имеет — обычно при работе используют лишь небольшую часть своих наборов информации. Когда появился BigQuery, для многих это казалось какой-то научной фантастикой — вы буквально могли обрабатывать данные со скоростью света, быстрее, чем когда-либо прежде. Но почти никому на самом деле такой инструмент был не нужен. Более того: то, что в 2012-м было научной фантастикой, теперь стало обычным явлением, и даже более традиционные способы обработки данных показывают невероятную скорость.
Об этом посте
В этом посте я хочу доказать, что эра больших данных закончилась. Всё, поигрались — и теперь можно перестать беспокоиться о размере своих данных и сосредоточиться на том, как мы собираемся использовать их для принятия наилучших решений. Я покажу ряд графиков, все они нарисованы мной вручную по памяти. Если бы у меня был доступ к точным цифрам, я бы всё равно не смог ими поделиться. Но важнее здесь форма, а не точные значения.
Данные, лежащие в основе моих графиков, получены из анализа журналов запросов, результатов сделок, результатов тестов (опубликованных и неопубликованных), запросов в службу поддержки, разговоров с клиентами, журналов обслуживания и опубликованных сообщений в блогах, а также моей личной интуиции.
Традиционный вступительный слайд
Все последние 10 лет каждая презентация любого продукта в сфере Big Data начинается со слайда, который выглядит примерно так:
 Количество генерируемых данных каждый год увеличивается! Вау!
Количество генерируемых данных каждый год увеличивается! Вау!
Мы использовали ту или иную версию этого слайда в течение многих лет в Google. Когда я перешел в SingleStore, то увидел, что они используют собственную версию с такой же диаграммой. Я видел несколько других поставщиков с чем-то подобным. Это очень «страшный» слайд. Большие данные наступают! Вы должны срочно купить то, что я продаю!
В общем, все говорили об одном: старые способы обработки данных скоро не будут работать. Ускорение генерации данных оставит системы прошлых лет в пыли и грязи. А любой, кто примет новые идеи, сможет понимать, что происходит, и обойти своих конкурентов.
Но, конечно, то, что количество генерируемых данных растет, ещё не означает, что это автоматически становится проблемой для всех. Данные распределяются неравномерно. Большинству приложений не нужно обрабатывать огромные объемы данных. Это привело к возрождению систем управления данными с традиционной архитектурой: SQLite, PostgreSQL и MySQL активно растут, в то время как системы «NoSQL» и даже «NewSQL» стагнируют.
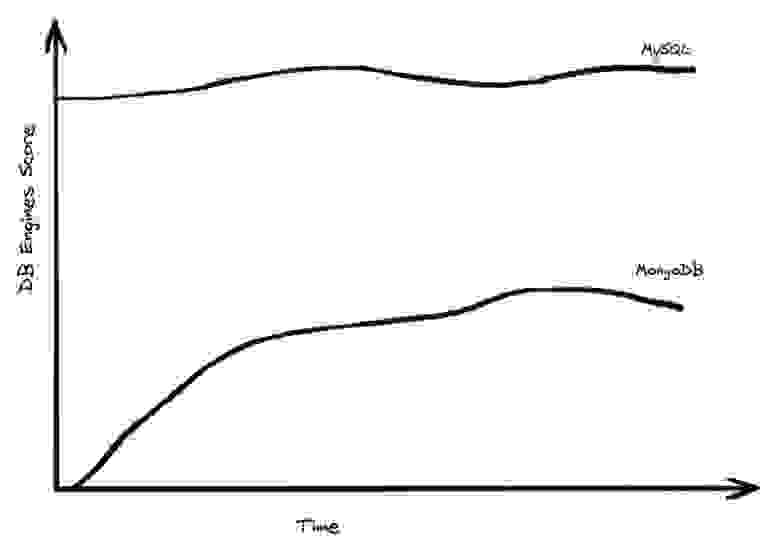 Оценка движков БД с течением времени: MongoDB по сравнению с MySQL
Оценка движков БД с течением времени: MongoDB по сравнению с MySQL
MongoDB — масштабируемая база данных с самым высоким рейтингом, и, хотя за годы «угрозы больших данных» она взяла хороший разгон, в последнее время она немного снизилась в популярности и на самом деле не добилась большого прогресса по сравнению с MySQL или Postgres, двумя очень монолитными БД. Если бы большие данные действительно начинали доминировать, мы могли бы ждать другой результат после всех этих лет.
Конечно, в аналитических системах картина может выглядеть иначе, но в OLAP мы видим массовый переход предприятий от локальных систем к облаку, и на самом деле у нас нет масштабируемых облачных аналитических систем, с которыми можно было бы сравнивать показатели.
У большинства людей нет так уж много данных
Предполагаемый вывод из знаменитой диаграммы «Большие данные приближаются!» заключался в том, что довольно скоро все будут завалены своими данными. А спастись будут способны лишь избранные. Десять лет спустя это будущее, мы видим, не наступило. Мы можем легко проверить это тремя способами: посмотреть на данные (количественно), спросить о впечатлениях людей (качественно) и обдумать информацию исходя из первых принципов (индуктивно).
Когда я работал в BigQuery, я тратил много времени на определение размеров компаний клиентов. Я не могу здесь поделиться цифрами напрямую, данные тут очень конфиденциальны. Но могу сказать, что у подавляющего большинства клиентов было менее терабайта данных в общем хранилище. Конечно, были и клиенты с огромными объемами данных, но чаще всего это было излишеством. В основном даже достаточно крупные предприятия имели очень умеренные объемы данных, которые полностью могли бы поместиться на один жесткий диск.
Размеры данных клиентов подчинялись степенному закону распределения. У крупнейшего клиента хранилище было вдвое больше, чем у следующего по величине клиента. У третьего по величине клиента хранилище было еще вдвое меньше и так далее. Таким образом, хотя у нас были клиенты и с сотнями петабайт данных, средние размеры уменьшались очень быстро. Было много тысяч клиентов, которые платили нам меньше 10 долларов в месяц за хранилище, то есть данных у них было полтерабайта. Средний размер хранилища среди активных корпоративных клиентов был намного меньше 100 ГБ. При этом, напоминаю, они использовали сервис для помощи в обработке больших данных. Видимо, искренне думая, что он им помогает.
 Размер данных клиента и количество таких клиентов
Размер данных клиента и количество таких клиентов
Это был секрет Полишинеля. Когда мы общались с крутыми отраслевыми аналитиками (Gartner, Forrester и т. д.), мы превозносили нашу способность обрабатывать массивные наборы данных, а они в ответ пожимали плечами. «Это хорошо, — говорили они, —, но у подавляющего большинства предприятий данных меньше терабайта». Общее мнение, которое мы получали от осведомленных представителей отрасли, состояло в том, что 100 ГБ — это правильный порядок величины для хранилища данных. Поэтому мы сместили фокус рекламы и впоследствии при разработке стали ориентироваться на эту цифру.
Один из наших инвесторов как-то решил выяснить, насколько велики на самом деле объемы аналитических данных. И провел опрос среди компаний в своем портфеле, большинство из которых были post-exit (они либо прошли IPO, либо были куплены более крупными организациями). Все они были IT-компаниями — вероятно, склонными к большим размерам данных. И вот он обнаружил, что у крупнейших B2B-компаний в его портфолио было около терабайт данных, а у крупнейших B2C-компаний — около 10 терабайт данных. У всех остальных данных было гораздо меньше, иногда гигабайты.
Чтобы понять, почему большие объемы данных встречаются так редко, можно подумать о том, откуда на самом деле берется информация. Представьте, скажем, что у вас средний бизнес с тысячей клиентов. Допустим, каждый из ваших клиентов размещает новый заказ каждый день. И в каждом заказе сотня разных позиций. Это нереально часто и очень много позиций, но даже в такой ситуации вы генерируете меньше мегабайта новых данных в день. Через три года у вас будет только гигабайт. А для создания терабайта потребуются тысячелетия.
Или, допустим, у вас есть миллион потенциальных клиентов в вашей маркетинговой базе данных. И вы проводите десятки рекламных кампаний, следя за каждым клиентом. Тогда ваша таблица лидов, вероятно, занимает меньше гигабайта, а отслеживание каждого клиента в каждой из кампаний — еще пару гигабайт. До терабайта тут никак не наскрести, даже если нанять сотню маркетологов. Нужно или допускать огромные ошибки в масштабировании, или признать, что большие данные вам не нужны. Как бы ни хотелось обратного.
Вот еще конкретный пример. Я работал над развитием реляционной СУБД SingleStore в 2020–2022 годах. Это была быстрорастущая компания Series E с существенным доходом и статусом единорога. Но если бы вы взяли размер нашего хранилища финансовых данных, добавили к нему нашу информацию о клиентах и маркетинговых кампаниях и добавили бы сюда все сервисные журналы, у вас бы в сумме набралось пять гигабайт. Даже при самом богатом воображении такое сложно назвать Big Data.
Разделение хранилища и вычислений
Все современные облачные платформы разделяют хранилища и вычислительные ресурсы. Это означает, что клиенты не привязаны к одному форм-фактору и могут выбирать, что им нужно. Вероятно, если не считать масштабирования, это самое важное изменение в архитектуре данных за последние 20 лет. Вместо архитектур «без общего доступа», которыми трудно управлять в реальных условиях, архитектуры с общими дисками позволяют наращивать хранилище и вычислительные ресурсы независимо друг от друга. Появление масштабируемых и достаточно быстрых объектных хранилищ, таких как S3 и GCS, означает, что у вас гораздо больше пространства для маневра в том, как вы создаете базу данных.
Но тут важно, что на практике размеры данных увеличиваются намного быстрее, чем размеры вычислений. И хотя рекламные описания преимуществ разделения хранения и вычислений создают впечатление, что вы можете масштабировать любой из этих аспектов в любое время, на самом деле эти два направления не эквивалентны. Неправильное понимание этого нюанса приводит к большому количеству неверных разговоров о Big Data, потому что методы работы с большими вычислительными требованиями отличаются от методов работы с большими данными. Это два разные направления, и их важно не смешивать. Сейчас я покажу, почему.
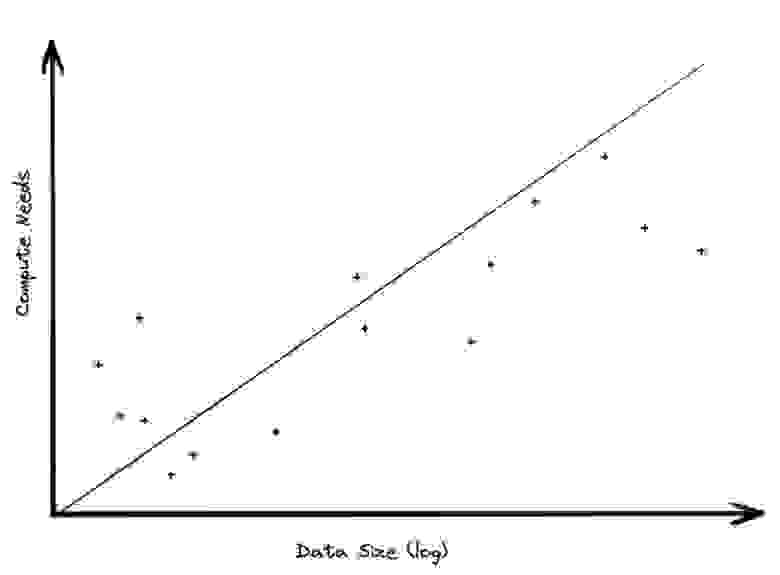 Объем собираемых данных в основном растет быстрее, чем вычислительная мощность, требуемая для их анализа
Объем собираемых данных в основном растет быстрее, чем вычислительная мощность, требуемая для их анализа
Все большие наборы данных генерируются постепенно, с течением времени. Каждый день приходят новые заказы. Новые поездки на такси. Новые записи в журнале. Выпускаются новые игры. Если бизнес статичен, не растет и не сокращается, объем данных будет увеличиваться линейно со временем.
Что это означает для аналитических мощностей? Очевидно, что потребности в хранении данных будут увеличиваться линейно, если только вы не решите резко сократить данные (подробнее об этом позже). Но потребности в вычислительных ресурсах, скорее всего, не сильно поменяются со временем. Большая часть анализа проводится по последним данным. Вам интересно, что происходит на рынке сейчас, а не три года назад. Сканирование старых данных довольно расточительно; они не меняются, так зачем вам тратить деньги на их анализ снова и снова? Но из хранения их выкидывать нельзя:, а вдруг вы захотите задать новый вопрос о данных, придумаете новую метрику, которую захочется просмотреть?
Вот и выходит, что объем данных растет быстрее, чем мощности, требуемые для их анализа.
Я заметил, когда клиент хранилища данных переходит из той среды, в которой у него не было разделения хранения и вычислений, в среду, где они есть, использование хранилища обычно значительно возрастает, но его потребности в вычислительных ресурсах, как правило, не меняются. В BigQuery у нас был клиент, который был одним из крупнейших ритейлеров в мире. У них было локальное хранилище данных объемом около 100 ТБ. Когда они перешли в наше облако, у них стало 30 ПБ данных — в 300 раз больше! Если бы их вычислительные потребности увеличились на аналогичную величину, они бы потратили миллиарды долларов только на аналитику. Вместо этого они потратили только маленькую долю этой суммы.
Это смещение в сторону размера хранилища, а не размера вычислений, оказывает реальное влияние на системную архитектуру. Это означает, что если вы используете масштабируемые хранилища объектов, вам нужно будет гораздо меньше вычислительных ресурсов, чем предполагалось. Возможно даже, что вам вообще не понадобится использовать распределенную обработку.
Объем рабочей нагрузки меньше, чем объем данных
Объем данных, обрабатываемых при аналитических нагрузках, почти наверняка меньше, чем вы думаете. Панели мониторинга, например, очень часто строятся на основе агрегированных данных. Люди смотрят на данные за последний час, или за последний день, или за последнюю неделю. Меньшие таблицы, как правило, запрашиваются чаще, гигантские таблицы — намного реже.
Пару лет назад я провел анализ запросов BigQuery, выбрав клиентов, которые тратят более 1000 долларов в год. И 90% их запросов обрабатывали менее 100 МБ данных. Я сделал ряд тестов, чтобы убедиться, что это не просто пара клиентов, которые выполнили тонну запросов, искажающих результаты. Но вывод был один: вы должны идти довольно высоко в диапазоне процентилей, пока не дойдете до обработки хотя бы гигабайт. И считанные единицы запросов выполнялись в терабайтном диапазоне.
У нас были клиенты с гигантскими объемами хранящихся данных. Но они почти никогда не запрашивали обработку больших объемов. Чаще всего такие запросы происходили, когда они создавали отчеты, и в таких случаях скорость выполнения запроса для них вообще не была приоритетом. На самом деле в итоге клиенты с умеренными объемами данных чаще выполняли большие по весу запросы (просто из-за количества таких клиентов).
Крупная компания, занимающаяся социальными сетями, обычно публикует отчеты в выходные, чтобы подготовить руководителей к утру в понедельник. Такие запросы у нас были довольно большими, но они составляли лишь крошечную долю из сотен тысяч запросов, которые компании выполняли во время рабочей недели.
 Подавляющее большинство рабочих нагрузок приходится на запросы меньше 10 ГБ
Подавляющее большинство рабочих нагрузок приходится на запросы меньше 10 ГБ
Даже при запросах к гигантским таблицам вам редко приходится обрабатывать очень много данных. Современные аналитические БД умеют выполнять проекцию столбцов для чтения только определенного подмножества полей и сокращать секции для чтения только узкого диапазона дат. Часто они идут еще дальше и устраняют сегменты, используя локальность данных с помощью кластеризации или автоматического микроразбиения. Есть и другие приемы, такие как вычисления со сжатыми данными, проецирование и проталкивание предикатов. Всё это позволяет сократить количество операций ввода-вывода во время проведения запроса. А меньшее количество операций ввода-вывода превращается в меньший объем необходимых вычислений, что приводит к снижению затрат и задержек. Современные БД успешно умеют бороться с огромными запросами, так что запредельные мощности даже здесь не нужны.
И это будет продолжаться. Обработка данных с каждым годом продолжает становиться эффективнее и затрачивает все меньше ресурсов. Всё потому, что существует острое экономическое давление, побуждающее людей искать способы сокращать объем обрабатываемых данных. Тот факт, что вы можете анализировать что-то очень быстро, не означает, что вы можете сделать это недорого. Запрос размером в петабайт, который я использовал на сцене, чтобы продемонстрировать возможности BigQuery, стоил 5000 долларов. Очень немногие люди могут позволить себе разбрасываться такими деньгами.
Поэтому финансовый стимул к обработке меньшего объема данных для компаний всегда будет в силе. Даже если появится облачный сервис, не использующий модель с оплатой за каждый байт, он никуда не уйдет. Скажем, вы сидите на платформе Snowflake. Если вы сможете уменьшить количество запросов, то перейдете на более скромный пакет и сможете платить меньше. Ваши запросы будут выполняться быстрее, вы сможете выполнять больше параллельных операций и, как правило, со временем станете платить меньше. Компании стремятся к этому, а разработчики БД и других систем — стараются удовлетворить это желание.
Большая часть данных редко запрашивается
Огромный процент обрабатываемых данных — не старше 24 часов. К тому времени, когда данным исполняется неделя, вероятность того, что они будут запрошены, уменьшается в 20 раз. Через месяц данные обычно просто лежат. Исторические данные, как правило, запрашиваются очень нечасто, возможно, когда кто-то решает сделать уникальный отчет.
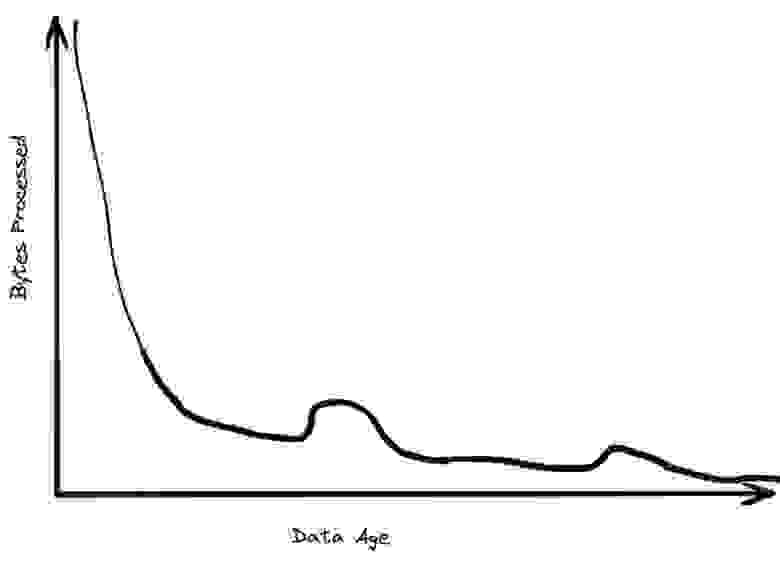 По мере старения данные обрабатываются всё реже и реже
По мере старения данные обрабатываются всё реже и реже
Со временем хранящиеся данные вызываются всё реже. Большинство из них просто добавляются в конец таблиц и хранятся где-то в уголках БД, в надежде, что их когда-нибудь снова вызовут. На последний год может приходиться около 30% всех данных, но 99% запросов к ним. В таблице с последним месяцем может храниться 5% всех данных, но на неё приходится 80% всех вызовов.
Такая ситуация означает, что размеры «рабочего» набора данных более скромны и более управляемы, чем вы ожидаете. Если у вас есть петабайтная таблица с данными за 10 лет, это не значит, что вам реально нужно обрабатывать этот петабайт. В большинстве случаев вы будете обращаться к данным не старше последней недели, которые могут быть сжаты до менее чем 50 ГБ.
Граница Big Data продолжает отдаляться
Одно из определений «больших данных» — это «все, что не помещается на одной машине». Если следовать этому определению, то количество больших данных на самом деле уменьшается с каждым годом.
В 2004 году, когда была написана статья о Google MapReduce, было обычным делом, чтобы рабочая нагрузка данных не умещалась на одной серийной машине. Масштабирование было очень дорогим. В 2006 году AWS запустила EC2, и единственным вариантом, который вы могли получить, было 1 ядро и 2 ГБ ОЗУ. Было много рабочих нагрузок, которые не помещались на этой машине.
Однако сегодня стандартный вариант на AWS использует физический сервер с 64 ядрами и 256 ГБ ОЗУ. Это на два порядка больше оперативной памяти, чем было пятнадцать лет назад. Если вы готовы потратить немного больше на инстанс, оптимизированный для памяти, то можете повысить свою ОЗУ еще на два порядка. Сколько есть рабочих нагрузок, для которых требуется более 24 ТБ ОЗУ и 445 ядер ЦП?
 Отдельные машины способны обрабатывать гораздо больший процент рабочих нагрузок с течением времени и с развитием технологий
Отдельные машины способны обрабатывать гораздо больший процент рабочих нагрузок с течением времени и с развитием технологий
Раньше большие машины стоили намного дороже, цены росли по гиперболе. Однако в облаке виртуальная машина, использующая весь сервер, стоит всего в 8 раз дороже, чем виртуальная машина, использующая 1/8 сервера. Стоимость увеличивается линейно с вычислительной мощностью, вплоть до очень больших размеров.
Когда-то мы считали, что «Big Data» наступит, когда на каждой машине будет храниться больше 10 ГБ информации. Потом — что больше 1 ТБ. Сейчас даже петабайты в облачных сервисах мало кого смущают. При этом люди продолжают считать, что Big Data — это что-то еще более масштабное, оно всё еще находится где-то там, за горизонтом, и готово свалиться всем нам на голову. Хотя никаких реальных признаков этому нет. На самом деле число рабочих нагрузок, которые можно было бы причислить к Big Data, ежегодно снижается. И это происходит уже много лет.
Данные — это обязательства
Альтернативное определение понятия «больших данных» — это:
Когда стоимость хранения данных меньше, чем стоимость выяснения того, что именно нужно выбросить.
Мне больше нравится это определение, потому что оно объясняет, почему люди в конечном итоге обращаются к Big Data. Не потому что им это очень нужно; они просто не хотят разбираться, что им удалять. Если подумать о многих озерах данных, которые собирают организации, то они полностью соответствуют этому требованию: гигантские грязные болота, где никто не знает, что именно они содержат и безопасно ли их очищать.
Стоимость хранения данных — намного выше, чем просто стоимость хранения физических байтов. Данные — это большая ответственность и большая опасность.
Например, в соответствии с правилами GDPR и CCPA, защищающими права потребителей, вы обязаны отслеживать все случаи использования определенных типов информации. Некоторые данные должны быть удалены через определенное время. Если у вас в файле записаны адреса и телефонные номера, которые годами хранятся где-то в вашем озере данных — возможно, вы нарушаете законодательство. А если эти данные вдруг утекут — это может поставить под угрозу существование всей вашей фирмы.
Данные, которые вы храните, могут быть использованы в судебных процессах против вас. Поэтому, например, многие организации ограничивают сроки хранения электронных писем — чтобы уменьшить свою потенциальную ответственность. Если у вас есть журналы пятилетней давности, которые показывают ошибку безопасности в вашем коде или пропущенный багрепорт, это может быть использовано как доказательство вашей преступной халатности. Я слышал историю о компании, которая вообще держит в секрете все свои возможности по анализу данных, чтобы в случае чего предотвратить их использование в возможном судебном расследовании.
Если софт или код не поддерживать, они часто страдают от того, что на жаргоне называют «битовой гнилью». Это не физическое явление, просто люди начинают забывать, как и что нужно использовать, а окружающая среда меняется, оставляя старое ПО бесполезным и загнивающим.
Так вот, данные могут страдать от того же типа проблем. Со временем люди забывают точное значение определенных полей. Или часть данных стирается из памяти из-за ошибки железа, делая остальную информацию нечитаемой или бесполезной. Например, может возникнуть ошибка, из-за которой каждый ID клиента станет нулем. Или у вас была крупная мошенническая транзакция (о которой вы потом забыли), из-за которой теперь кажется, что второй квартал 2017 года был для вас супер-прибыльным. Из-за чего все другие, даже современные данные, анализируются неверно.
Чем дольше вы храните данные, тем сложнее отслеживать эти особые случаи. Тем больше в компании людей, которые не знакомы с тем, как процесс шел до них. И чем больше у вас старых данных, тем больше в вашем хранилище «битовой гнили». За содержание которой вы еще и платите деньги.
Если вы храните старые данные, хорошо бы понять, зачем они вам. Вы проводите один и тот же тип анализа снова и снова? Тогда не будет ли намного дешевле просто хранить отчеты? Вы держите данные на черный день? Вы думаете, что найдутся новые вопросы, которые вы, возможно, захотите задать? Если да, то насколько это важно? Насколько велика вероятность того, что это что-то изменит? Или вы просто собираете данные, как человек с синдромом Плюшкина хранит в доме старые ненужные вещи?
Всё это важные вопросы, которые нужно задать, особенно когда вы пытаетесь выяснить настоящую стоимость хранения данных. Она может оказаться выше, чем вы думаете.
Вы относитесь к одному проценту, и у вас правда есть большие данные?
Большие данные существуют, но большинству компаний не стоит о них беспокоиться. Вот несколько вопросов, которые вы можете задать себе, чтобы выяснить, является ли ваша компания «однопроцентником» в сфере больших данных:
Вы действительно генерируете огромное количество данных — десятки гигабайтов в день?
Если да, то действительно ли вам нужно использовать огромное количество данных единовременно?
Если да, то действительно ли эти данные слишком велики, чтобы поместиться на одной машине?
Если да, то уверены ли вы, что не просто храните эти данные, а регулярно обращаетесь к ним?
Если да, то уверены ли вы, что это лучше составления простых отчетов, и приносит вам реальную пользу?
Если вы ответили «нет» на любой из этих вопросов, значит, Big Data вам не нужны. Вместо этого стоит посмотреть в сторону нового поколения инструментов анализа, которые помогут вам обрабатывать данные в том размере, который у вас есть на самом деле, а не том, которым вас пытаются запугать.
В итоге — больших данных (почти) нет. Они мертвы для всех, за исключением редких компаний уровня H&M, Google и Walmart. Для остальных — есть обычные данные. И нужно сосредоточиться не на их объеме, а на том, как выделять из них действительно полезную и важную информацию.
Промокод для читателей нашего блога!
— 15% на все тарифы VDS (кроме тарифа Прогрев) — по промокоду HabrFIRSTVDS.
50 тысяч активных серверов и 10 тысяч клиентов, которые с нами больше 5 лет.
