[Перевод] Больше разработчиков должны знать это о базах данных
Прим. перев.: Jaana Dogan — опытный инженер из Google, которая в данный момент занимается вопросами наблюдаемости production-сервисов компании, написанных на Go. В этой статье, снискавшей большую популярность у англоязычной аудитории, она в 17 пунктах собрала важные технические детали, касающиеся СУБД (а иногда — распределённых систем в целом), которые полезно учитывать разработчикам крупных/требовательных приложений.

Подавляющее большинство компьютерных систем отслеживают свое состояние и, соответственно, нуждаются в некой системе хранения данных. Я накапливала знания о базах данных в течение длительного времени, попутно совершая ошибки при проектировании, приводившие к потере данных и перебоям в работе. В системах, обрабатывающих большие объемы информации, базы данных лежат в сердце системной архитектуры и выступают ключевым элементом при выборе оптимального решения. Несмотря на то, что работе БД уделяется пристальное внимание, проблемы, которые пытаются предусмотреть разработчики приложений, часто оказываются лишь верхушкой айсберга. В этой серии статей я делюсь некоторыми идеями, которые будут полезны для разработчиков, не специализирующихся в этой области.
- Вам повезло, если 99,999% времени сеть не является источником проблем.
- ACID подразумевает множество разных вещей.
- У каждой базы свои механизмы обеспечения согласованности и изоляции.
- Оптимистическая блокировка приходит на выручку, когда сложно удерживать обычную.
- Существуют и другие аномалии кроме «грязных» чтений и потери данных.
- База данных и пользователь не всегда приходят к единому мнению по поводу порядка действий.
- Шардинг на уровне приложения можно вынести за пределы приложения.
- Автоинкрементирование может быть опасным.
- Устаревшие (stale) данные могут быть полезны и не нуждаться в блокировке.
- Искажения типичны для любых источников времени.
- У задержки множество значений.
- Требования к производительности следует оценивать для конкретной транзакции.
- Вложенные транзакции могут быть опасны.
- Транзакции не должны быть привязаны к состоянию приложения.
- Планировщики запросов могут многое рассказать о базах данных.
- Онлайн-миграция сложна, но возможна.
- Значительное увеличение базы данных влечет за собой рост непредсказуемости.
Хочу выразить признательность Emmanuel Odeke, Rein Henrichs и другим за их обратную связь по ранней версии этой статьи.
Вам повезло, если 99,999% времени сеть не является источником проблем
Остается открытым вопрос о том, насколько надежны современные сетевые технологии и как часто системы простаивают из-за сбоев в работе сети. Информации по этому вопросу недостаточно, и часто в исследованиях преобладают крупные организации со специализированными сетями, оборудованием и персоналом.
Имея показатель доступности в 99,999% для Spanner (глобально распределенной базы данных Google), Google утверждает, что только 7,6% проблем связаны с сетью. При этом компания называет свою специализированную сеть «главной опорой» высокой доступности. Исследование Bailis и Kingsbury, проведенное в 2014 году, бросает вызов одному из «заблуждений о распределенных вычислениях», которые Peter Deutsch сформулировал в 1994 году. Действительно ли сеть надежна?
Полноценных исследований за пределами компаний-гигантов, проведенных для широкого интернета, просто не существует. Также недостаточно данных от основных игроков о том, какой процент проблем их клиентов связан с сетью. Мы хорошо осведомлены о перебоях в сетевом стеке крупных облачных провайдеров, способных вывести из строя целый кусок Интернета на несколько часов просто потому, что это самые резонансные события, затрагивающие большое число людей и компаний. Перебои в работе сети могут служить источником проблем в гораздо большем числе случаев, даже если не все эти случаи попадают в центр всеобщего внимания. Клиенты облачных сервисов также ничего не знают о причинах проблем. В случае сбоя практически невозможно связать его с сетевой ошибкой на стороне поставщика услуг. Для них сторонние сервисы — это черные ящики. Невозможно оценить воздействие, не будучи крупным поставщиком услуг.
Учитывая то, что крупные игроки сообщают о своих системах, можно с уверенностью сказать, что вам повезло, если сложности с сетью отвечают лишь за небольшой процент потенциальных проблем, приводящих к простоям. Сетевые коммуникации все еще страдают от таких заурядных вещей, как отказы оборудования, смена топологии, изменения административной конфигурации и отключения питания. Недавно я с удивлением узнала, что к перечню возможных проблем добавились укусы акул (да, вы не ослышались).
ACID подразумевает множество разных вещей
Акроним ACID означает атомарность, консистентность, изолированность, надежность. Эти свойства транзакций призваны гарантировать их действительность на случай сбоев, ошибок, отказов оборудования и т.п. Без ACID или похожих схем разработчикам приложений было бы сложно провести границу между зоной своей ответственности и тем, за что отвечает база данных. Большинство реляционных транзакционных баз данных пытаются быть совместимыми с ACID, однако новые подходы вроде NoSQL породили множество баз данных без ACID-транзакций, поскольку их реализация обходится дорого.
Когда я только пришла в отрасль, наш техлид рассуждал о том, насколько актуальна концепция ACID. Справедливости ради следует отметить, что ACID считается примерным описанием, а не строгим стандартом реализации. Сегодня я нахожу его преимущественно полезным, поскольку он поднимает определенную категорию вопросов (и предлагает спектр возможных решений).
Не всякая СУБД соответствует требованиям ACID; при этом поддерживающие ACID реализации баз по-разному понимают набор требований. Одна из причин разнородной реализации ACID связана с обилием компромиссов, на которые приходится идти ради внедрения требований ACID. Создатели могут представлять свои базы данных как ACID-совместимые, при этом интерпретация пограничных случаев может кардинально различаться, как и механизм обработки «маловероятных» событий. По крайней мере, разработчики могут на высоком уровне разобраться в тонкостях реализации баз, чтобы получить правильное представление об их особых режимах и компромиссах при проектировании.
Дебаты о том, насколько MongoDB соответствует требованиям ACID, не прекращаются даже после выхода 4-ой версии. MongoDB долгое время не поддерживала журналирование, хотя по умолчанию фиксация данных на диск осуществлялась не чаще, чем раз в 60 секунд. Представьте следующий сценарий: приложение проводит две записи (w1 и w2). MongoDB успешно сохраняет w1, но w2 теряется из-за аппаратного сбоя.
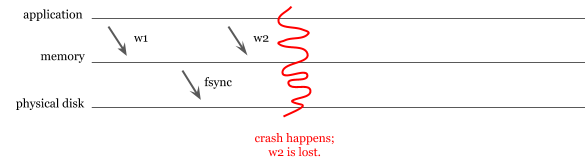
Схема, иллюстрирующая сценарий. MongoDB падает до того, как успевает записать данные на диск
Фиксация на диск — дорогостоящий процесс. Избегая частых фиксаций, разработчики улучшают показатели записи, жертвуя надежностью. На сегодняшний день MongoDB поддерживает журналирование, однако «грязные» записи все еще могут сказаться на целостности данных, поскольку по умолчанию журналы фиксируются каждые 100 мс. То есть похожий сценарий все еще возможен для журналов и изменений, представленных в них, хотя риск гораздо ниже.
У каждой базы свои механизмы обеспечения согласованности и изоляции
Из числа требований ACID согласованность и изоляция могут похвастаться самым большим количеством различных реализаций, поскольку спектр компромиссов шире. Надо сказать, что согласованность и изоляция — довольно затратные функции. Они требуют координации и усиливают конкуренцию ради согласованности данных. Сложность проблемы значительно возрастает при необходимости горизонтально масштабировать базу по нескольким ЦОД (особенно если они находятся в разных географических регионах). Добиться высокого уровня согласованности очень сложно, поскольку попутно снижается доступность и увеличивается сегментация сети. Для более общего объяснения этого феномена советую обратиться к теореме САР. Стоит также отметить, что приложения способны справляться с небольшой несогласованностью, а программисты могут достаточно хорошо представлять нюансы проблемы, чтобы реализовать дополнительную логику в приложении, позволяющую справляться с несогласованностью, не сильно полагаясь на БД в этом вопросе.
СУБД часто предоставляют различные уровни изоляции. Разработчики приложений могут выбрать наиболее эффективный из них, основываясь на своих предпочтениях. Низкая изоляция позволяет увеличить скорость, попутно повышая риск возникновения гонки данных (data race). Высокая изоляция снижает эту вероятность, но замедляет работу и может привести к конкуренции, которая приведет к таким тормозам в базе, что начнутся сбои.
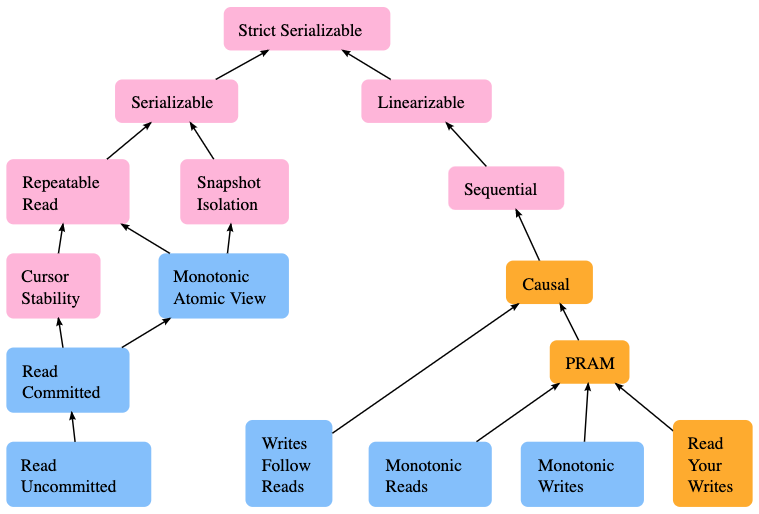
Обзор существующих моделей параллелизма и взаимосвязей между ними
Стандарт SQL определяет только четыре уровня изоляции, хотя в теории и на практике их число значительно больше. Jepson.io предлагает отличный обзор существующих моделей параллелизма. Например, Google Spanner гарантирует внешнюю сериализуемость с синхронизацией часов, и хотя это более строгий слой изоляции, он не определен в стандартных слоях изоляции.
В стандарте SQL упоминаются следующие уровни изоляции:
- Serializable (самый жесткий и затратный): сериализуемое исполнение имеет эффект, аналогичный некоторому последовательному выполнению транзакций. Последовательное выполнение означает, что каждая последующая транзакция начинается только после полного завершения предыдущей. Следует отметить, что уровень Serializable часто реализуется в виде так называемой snapshot-изоляции (например, в Oracle) из-за различий в интерпретации, хотя сама snapshot-изоляция не представлена в стандарте SQL.
- Repeatable reads: незафиксированные записи в текущей транзакции доступны для текущей транзакции, но изменения, сделанные другими транзакциями (например, новые строки), не видны.
- Read committed: незафиксированные данные недоступны для транзакций. В этом случае транзакции могут видеть только зафиксированные данные, при этом могут происходить фантомные чтения. Если некая транзакция вставит и зафиксирует новые строки, текущая транзакция сможет увидеть их при запросе.
- Read uncommitted (наименее строгий и затратный уровень): «грязное» чтение допустимо, транзакции могут видеть незафиксированные изменения, внесенные другими транзакциями. На практике этот уровень может пригодиться для приблизительных оценок, например, для запросов
COUNT(*)на таблице.
Уровень Serializable минимизирует риск возникновения гонок данных, при этом наиболее затратен в реализации и приводит к самой высокой конкурентной нагрузке на систему. Другие уровни изоляции реализовать легче, однако возрастает вероятность гонок данных. Некоторые СУБД позволяют задать пользовательский уровень изолированности, в других имеются выраженные предпочтения и поддерживаются не все уровни.
Поддержка уровней изолированности часто рекламируется в той или иной СУБД, однако только тщательное изучение ее поведения позволяет прояснить, что на самом деле происходит.
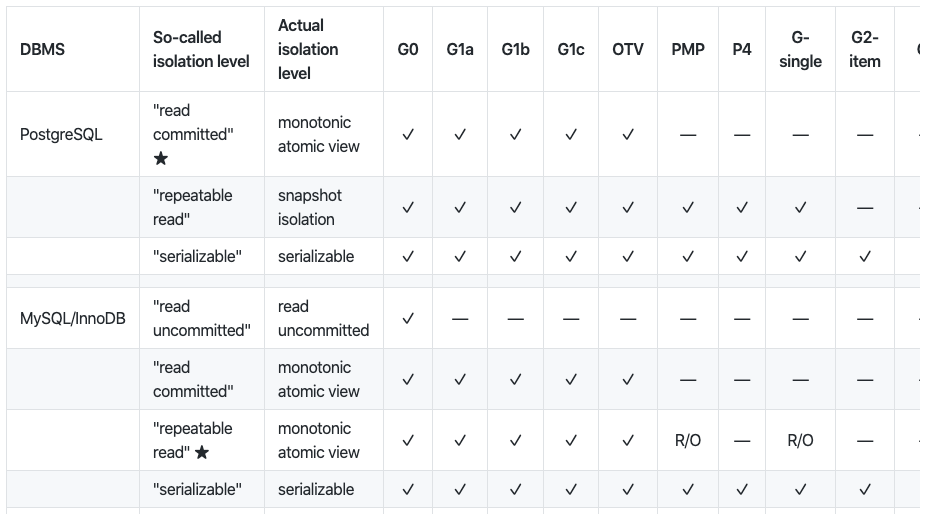
Обзор аномалий параллелизма на разных уровнях изоляции для разных СУБД
Martin Kleppmann в своем проекте hermitage проводит сравнение различных уровней изоляции, рассказывает об аномалиях параллелизма и о том, способна ли база данных придерживаться определенного уровня изоляции. Исследования Kleppmann’а показывают, насколько по-разному разработчики баз данных представляют себе уровни изоляции.
Оптимистическая блокировка приходит на выручку, когда сложно удерживать обычную
Блокировка может быть очень накладной не только потому, что ужесточает конкуренцию в базе, но и потому, что требует постоянного подключения от серверов приложения к базе данных. Сегментация сети способна усугубить ситуацию с монопольными блокировками и привести к возникновению тупиковых блокировок, которые трудно идентифицировать и устранять. В случаях, когда монопольная блокировка не подходит, помогает оптимистическая.
Оптимистическая блокировка — это метод, при котором при считывании строки учитывается ее версия, контрольная сумма или время последнего изменения. Благодаря этому перед тем, как изменять запись, можно убедиться в отсутствии атомарного изменения версии:
UPDATE products
SET name = 'Telegraph receiver', version = 2
WHERE id = 1 AND version = 1
В данном случае обновление таблицы products не будет проведено, если ранее другая операция внесла изменения в эту строку. Если же других операций с данной строкой не проводилось, изменение для одной строки произойдет и мы сможем сказать, что обновление было успешным.
Существуют и другие аномалии кроме «грязных» чтений и потери данных
Когда речь заходит о согласованности данных, основное внимание уделяется возможному возникновению условий гонки, которые могут привести к «грязным» чтениям и потере данных. Однако аномалии с данными этим не ограничиваются.
Одним из примеров таких аномалий являются искажения записи (write skews). Искажения сложно обнаружить, поскольку обычно их активно не ищут. Они связаны не с «грязными» чтениями или потерей данных, а с нарушениями логических ограничений, налагаемых на данные.
Например, давайте рассмотрим приложения для мониторинга, которое требует, чтобы один оператор постоянно был on-call:
BEGIN tx1; BEGIN tx2;
SELECT COUNT(*)
FROM operators
WHERE oncall = true;
0 SELECT COUNT(*)
FROM operators
WHERE oncall = TRUE;
0
UPDATE operators UPDATE operators
SET oncall = TRUE SET oncall = TRUE
WHERE userId = 4; WHERE userId = 2;
COMMIT tx1; COMMIT tx2;
В ситуации выше возникнет искажение записи, если обе транзакции будут успешно зафиксированы. Хотя «грязных» чтений или потери данных не произошло, целостность данных оказалась нарушена: теперь два человека одновременно считаются on-call.
Сериализуемая изоляция, строение схемы или ограничения БД могут способствовать в устранении искажений записи. Разработчики должны уметь выявлять такие аномалии во время разработки, чтобы избежать их в production. При этом искажения записи крайне тяжело искать в кодовой базе. Особенно в крупных системах, когда разные команды разработчиков отвечают за реализацию функций на основе одних и тех же таблиц и не согласовывают между собой особенности доступа к данным.
База данных и пользователь не всегда приходят к единому мнению по поводу порядка действий
Одна из ключевых особенностей баз данных — это гарантирование порядка выполнения, однако сам этот порядок может быть непрозрачен для разработчика ПО. Базы данных выполняют транзакции в порядке получения, а не в том порядке, который подразумевают программисты. Порядок выполнения транзакций сложно предсказать, особенно в высоконагруженных параллельных системах.
Во время разработки, особенно при работе с неблокирующими библиотеками, плохой стиль и низкая читаемость могут привести к тому, что пользователи будут уверены, что транзакции выполняются последовательно, хотя на самом деле они могут поступать в базу в любом порядке.
На первый взгляд, в приведенной ниже программе Т1 и Т2 вызываются последовательно, но если эти функции неблокирующие и сразу возвращают результат в виде promise, то порядок вызова будет определяться моментами, когда они поступили в базу данных:
result1 = T1() // реальные результаты — это promises
result2 = T2()
Если необходима атомарность (то есть либо все операции должны быть выполнены, либо прерваны) и последовательность имеет значение, то операции Т1 и Т2 должны выполняться в рамках единой транзакции.
Шардинг на уровне приложения можно вынести за пределы приложения
Шардинг — это способ горизонтального разделения базы данных. Некоторые базы умеют автоматически разбивать данные горизонтально, в то время как другие этого не умеют, или им это удается не слишком хорошо. Когда архитекторы данных/разработчики имеют возможность спрогнозировать, как именно будет осуществляться доступ к данным, они могут создать горизонтальные партиции в пользовательском пространстве вместо того, чтобы делегировать эту работу БД. Этот процесс называется «шардинг на уровне приложения» (application-level sharding).
Увы, такое название часто создает неверное представление, что шардинг обитает в сервисах приложения. На самом деле его можно реализовать в виде отдельного слоя перед базой данных. В зависимости от роста данных и итераций схемы, требования к шардингу могут становиться весьма сложными. При некоторых стратегиях может пригодиться возможность проводить итерации без необходимости повторно развертывать серверы приложения.
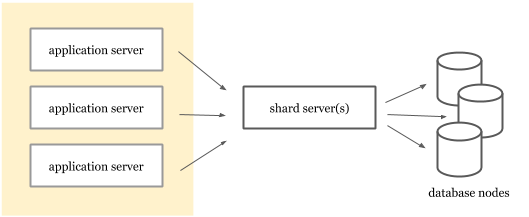
Пример архитектуры, в которой серверы приложения отделены от сервиса шардинга
Вынос шардинга в отдельный сервис расширяет возможности по использованию различных стратегий шардинга без необходимости заново деплоить приложения. Vitess — пример такой системы шардинга на уровне приложения. Vitess обеспечивает горизонтальный шардинг для MySQL и позволяет клиентам подключаться в нему через протокол MySQL. Система сегментирует данные по разным узлам MySQL, ничего не знающим друг о друге.
Автоинкрементирование может быть опасным
AUTOINCREMENT — распространенный способ генерации первичных ключей. Нередко встречаются случаи, когда БД используются в качестве генераторов ID, а в базе имеются таблицы, предназначенные для генерации идентификаторов. Существует несколько причин, по которым генерация первичных ключей с помощью auto-incrementing'а далека от идеала:
- В распределенной базе данных auto-incrementing представляет собой серьезную проблему. Для генерации ID необходима глобальная блокировка. Вместо этого можно сгенерировать UUID: для этого не потребуется взаимодействие разных узлов базы. Auto-incrementing с блокировками может привести к конкуренции и значительно снизить производительность при вставках в распределенных ситуациях. Некоторым СУБД (например, MySQL) может потребоваться особая настройка и более пристальное внимание, чтобы правильным образом организовать репликацию мастер-мастер. А при конфигурировании легко ошибиться, что приведет к сбоям записи.
- У некоторых баз алгоритмы партицирования основаны на первичных ключах. Последовательные ID могут привести к непредсказуемому возникновению «горячих точек» и повышенной нагрузки на некоторые партиции, в то время как другие будут простаивать.
- Первичный ключ — это самый быстрый способ доступа к строке в базе данных. При наличии лучших способов идентификации записей, последовательные ID могут превратить самый важный столбец в таблицах в бесполезный, наполненный бессмысленными значениями. Поэтому при возможности, пожалуйста, выбирайте глобально уникальный и естественный первичный ключ (например, имя пользователя).
Прежде чем определиться с подходом, рассмотрите влияние auto-increment'ированных ID и UUID на индексирование, партицирование и шардинг.
Устаревшие (stale) данные могут быть полезны и не требовать блокировки
Управление параллельным доступом с помощью многоверсионности (MVCC) реализует многие требования к согласованности, которые кратко обсуждались выше. Некоторые базы данных (например, Postgres, Spanner) с помощью MVCC «скармливают» транзакциям снимки (snapshot'ы) — более старые версии базы данных. Транзакции со snapshot'ами также можно сериализовать для обеспечения согласованности. При чтении из старого snapshot'a считываются устаревшие данные.
Чтение слегка устаревших данных может пригодиться, например, при генерировании аналитики на основе данных или вычислении примерных агрегированных значений.
Первое преимущество работы с устаревшими данными — низкая задержка (особенно если база данных распределена по разным географическим регионам). Второе — в том, что транзакции «только для чтения» свободны от блокировки. Это существенное преимущество для приложений, которые много читают, если, конечно, допустима работа с устаревшими данными.
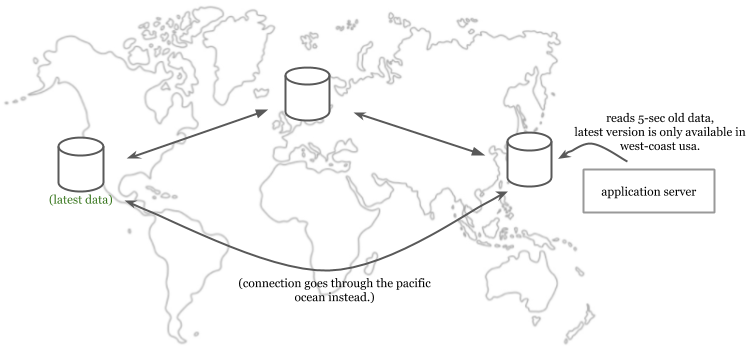
Сервер приложения считывает с локальной реплики данные, устаревшие на 5 секунд, даже если их свежайшая версия доступна по другую сторону Тихого океана
СУБД автоматически зачищают старые версии и в некоторых случаях позволяют делать это по запросу. Например, Postgres позволяет пользователям делать VACUUM по запросу, а также периодически проводит эту операцию в автоматическом режиме. Spanner запускает сборщик мусора, чтобы избавиться от снимков старше одного часа.
Искажению подвержены любые источники времени
Самый тщательно охраняемый секрет в информатике состоит в том, что все временны́е API лгут. На самом деле наши машины не знают точное текущее время. Компьютеры содержат кварцевые кристаллы, генерирующие колебания, которые используются для отсчета времени. Однако они недостаточно точны и могут опережать/отставать от точного времени. Сдвиг может достигать 20 секунд в сутки. Поэтому время на наших компьютерах необходимо периодически синхронизировать с сетевым.
Для синхронизации используются серверы NTP, однако сам процесс синхронизации подвержен задержкам из-за сети. Даже синхронизация с NTP-сервером в том же дата-центре занимает некоторое время. Понятно, что работа с публичным NTP-сервером может привести к еще большему искажению.
Атомные часы и их GPS-аналоги лучше подходят для определения текущего времени, однако они дороги и требуют сложной настройки, поэтому не могут быть установлены на каждой машине. Из-за этого в центрах обработки данных используется многоуровневый подход. Атомные и/или GPS-часы показывают точное время, после чего оно транслируется остальным машинам через вторичные серверы. Это означает, что на каждой машине будет наблюдаться определенный сдвиг от точного времени.
Ситуация усугубляется тем, что приложения и БД часто находятся на разных машинах (если не в разных ЦОД). Таким образом, время будет отличаться не только на узлах ДБ, распределенных по разным машинам. Оно также будет другим и на сервере приложения.
В Google TrueTime реализован совсем иной подход. Большинство людей считают, что прогресс Google в этом направлении объясняется банальным переходом на атомные и GPS-часы, но это лишь часть общей картины. Вот как устроен TrueTime:
- TrueTime использует два разных источника: GPS и атомные часы. У этих часов некоррелирующие точки отказа (failure modes) [подробности см. на 5 странице здесь — прим. перев.), поэтому их совместное использование повышает надежность.
- У TrueTime необычный API. Он возвращает время в виде интервала с заложенной погрешностью измерения и неопределенностью. Реальный момент времени находится где-то между верхней и нижней границами интервала. Spanner, распределенная база данных от Google, просто дожидается момента, когда можно с уверенностью сказать, что текущее время вышло за пределы интервала. Этот метод привносит определенную задержку в систему, особенно если неопределенность на мастерах высока, но обеспечивает корректность даже в глобально распределенной ситуации.

Компоненты Spanner используют TrueTime, где TT.now() возвращает интервал, так что Spanner просто спит до момента, когда можно наверняка сказать, что текущее время перевалило через определенную отметку
Снижение точности определения текущего времени означает рост длительности операций Spanner и снижение производительности. Вот почему важно поддерживать максимально высокую точность даже несмотря на то, что невозможно получить абсолютно точные часы.
У задержки множество значений
Спросив десяток специалистов о том, что такое задержка, вы наверняка получите разные ответы. В СУБД latency часто называется «задержкой базы данных», и она отличается о той, которую воспринимает клиент. Дело в том, что клиент наблюдает сумму сетевой задержки и задержки БД. Способность выделять тип задержки критически важна при отладке нарастающих проблем. При сборе и отображении метрик всегда старайтесь следить за обоими типами.
Требования к производительности следует оценивать для конкретной транзакции
Иногда характеристики производительности СУБД и ее ограничения указываются в виде пропускной способности write/read и задержки. Это позволяет получить общее представление о ключевых параметрах системы, однако при оценке производительности новой СУБД гораздо более всеобъемлющий подход заключается в раздельной оценке критических операций (для каждого запроса и/или транзакции). Примеры:
- Пропускная способность записи и задержка при вставке новой строки в таблицу Х (с 50 млн. строк) с заданными ограничениями и заполнением строк в связанных таблицах.
- Задержка при выводе друзей друзей некоего пользователя, когда среднее число друзей равно 500.
- Задержка при извлечении топ-100 записей из истории пользователя, когда он подписан на 500 других пользователей с Х записей в час.
Оценка и экспериментирование могут включать подобные критические случаи до тех пор, пока вы не будете уверены, что БД удовлетворяет требованиям к производительности. Аналогичное эмпирическое правило также учитывает эту разбивку при сборе latency-метрик и определении SLO.
Помните о высокой мощности (cardinality) при сборе метрик для каждой операции. Используйте логи, сбор событий или распределенную трассировку для получения отладочных данных с высокой мощностью. В статье «Want to Debug Latency?» вы можете ознакомиться с методологиями отладки задержек.
Вложенные транзакции могут быть опасны
Не каждая СУБД поддерживает вложенные транзакции, но когда это происходит, такие транзакции могут приводить к неожиданным ошибкам, которые не всегда легко выявить (то есть должно стать очевидно, что имеется какая-то аномалия).
Избежать использования вложенных транзакций можно с помощью клиентских библиотек, которые умеют их обнаруживать и обходить. Если от вложенных транзакций не получается отказаться, отнеситесь к их реализации с особым вниманием, чтобы избежать неожиданных ситуаций, когда совершённые транзакции случайно прерываются из-за вложенных.
Инкапсуляция транзакций в разные слои может приводить к неожиданному возникновению вложенных транзакций, а с точки зрения читаемости кода способна осложнить понимание намерений автора. Взгляните на следующую программу:
with newTransaction():
Accounts.create("609-543-222")
with newTransaction():
Accounts.create("775-988-322")
throw Rollback();
Каков будет результат приведенного выше кода? Откатит ли он обе транзакции, или только внутреннюю? Что произойдет, если мы будем полагаться на несколько уровней библиотек, которые инкапсулируют создание транзакций от нас? Сможем ли мы выявлять и улучшать такие случаи?
Представьте, что слой данных с несколькими операциями (например, newAccount) уже реализован в собственных транзакциях. Что произойдет, если запустить их в рамках бизнес-логики более высокого уровня, которая работает в рамках собственной транзакции? Какими в этом случае будут изоляция и согласованность?
function newAccount(id string) {
with newTransaction():
Accounts.create(id)
}
Вместо того, чтобы искать ответы на подобные бесконечные вопросы, лучше избегайте вложенных транзакций. Ведь ваш слой данных вполне может проводить операции высокого уровня без создания собственных транзакций. Кроме того, бизнес-логика сама способна инициировать транзакцию, выполнять операции над нею, фиксировать или прерывать транзакцию.
function newAccount(id string) {
Accounts.create(id)
}
// In main application:
with newTransaction():
// Read some data from database for configuration.
// Generate an ID from the ID service.
Accounts.create(id)
Uploads.create(id) // create upload queue for the user.Транзакции не должны быть привязаны к состоянию приложения
Иногда возникает соблазн использовать состояние приложения в транзакциях, чтобы изменить определенные значения или подправить параметры запроса. Критический нюанс, который нужно учитывать, — это правильная область применения. Клиенты часто перезапускают транзакции при проблемах в сети. Если при этом транзакция зависит от состояния, которое меняется каким-либо другим процессом, то она может выбрать неправильное значение в зависимости от возможности возникновения гонки данных. Транзакции должны учитывать риск возникновения условий гонки данных в приложении.
var seq int64
with newTransaction():
newSeq := atomic.Increment(&seq)
Entries.query(newSeq)
// Other operations...
Приведенная выше транзакция будет увеличивать номер последовательности при каждом выполнении независимо от конечного результата. Если коммит не удастся из-за проблем с сетью, при повторной попытке запрос будет выполняться с другим номером последовательности.
Планировщики запросов могут многое рассказать о БД
Планировщики запросов определяют, как запрос будет выполняться в базе данных. Они также анализируют запросы и оптимизируют их перед отправкой. Планировщики могут предоставить только некоторые возможные оценки, основанные на сигналах в их распоряжении. Например, какой способ поиска для следующего запроса самый оптимальный?
SELECT * FROM articles where author = "rakyll" order by title;
Результаты можно извлечь двумя способами:
- Полное сканирование таблицы: можно смотреть на каждую запись в таблице и возвращать статьи с совпадающим именем автора, а затем упорядочить их.
- Индексное сканирование: можно использовать индекс, чтобы найти соответствующие идентификаторы, получить эти строки, а затем упорядочить их.
Задача планировщика запросов состоит в том, чтобы определить, какая стратегия является наилучшей. Стоит учесть, что у планировщиков запросов лишь ограниченные возможности прогнозирования. Это может приводить к неудачным решениям. Администраторы БД или разработчики могут использовать их для диагностики и тонкой настройки неэффективных запросов. Новые версии СУБД умеют настраивать планировщиков запросов, а самодиагностика способна помочь при обновлении БД, если новая версия приводит к проблемам с производительностью. Логи медленных запросов, сообщения о проблемах с задержкой или статистика времени выполнения способны помочь с выявлением запросов, требующих оптимизации.
Некоторые метрики, представляемые планировщиком запросов, могут быть подвержены шуму (особенно при оценке задержки или процессорного времени). Хорошим дополнением к планировщикам являются инструменты для трассировки и отслеживания пути выполнения. Они позволяют диагностировать подобные проблемы (увы, не все СУБД предоставляют такие инструменты).
Онлайн-миграция сложна, но возможна
Онлайн-миграция, «живая» миграция или миграция в реальном времени означают переход от одной базы данных к другой без простоев и нарушений корректности данных. Живую миграцию легче провести, если переход происходит в рамках одной и той же СУБД/движка. Ситуация осложняется, когда необходим переезд на новую СУБД с иной производительностью и требованиями к схеме.
Существуют различные модели онлайн-миграции. Вот одна из них:
- Включите двойную запись в обе базы. Новая база на этом этапе не имеет всех данных, а только принимает свежие данные. Убедившись в этом, можно переходить к следующему шагу.
- Включите чтение с обеих БД.
- Настройте систему так, чтобы чтение и запись в первую очередь проводились с новой базой.
- Остановите запись в старую базу, при этом продолжая считывать из нее данные. На этом этапе новая БД по-прежнему лишена части данных. Их следует скопировать из старой базы.
- Старая база доступна только для чтения. Скопируйте недостающие данные из старой БД в новую. После завершения миграции переключите пути на новую базу, а старую остановите и удалите из системы.
За дополнительной информацией рекомендую обратиться к статье, подробно описывающей стратегию миграции Stripe на основе этой модели.
Значительное увеличение базы данных влечет за собой рост непредсказуемости
Рост БД приводит к непредсказуемым проблемам, связанным с ее масштабом. Чем больше мы знаем о внутреннем устройстве БД, тем лучше можем спрогнозировать, как она будет масштабироваться. При этом некоторые моменты все же невозможно предвидеть.
С ростом базы прежние предположения и ожидания относительно объема данных и требований к пропускной способности сети могут устареть. Именно тогда встает вопрос о серьезном пересмотре схемы, широкомасштабных улучшениях в эксплуатации, переосмыслении развертываний или миграции на другие СУБД, чтобы избежать потенциальных проблем.
Но не думайте, что отличное знание внутреннего устройства имеющейся БД — это единственное, что необходимо. Новые масштабы принесут с собой новые неизвестные. Непредсказуемые проблемные точки, неравномерное распределение данных, неожиданные проблемы с пропускной способностью и оборудованием, постоянно растущий трафик и новые сегменты в сети заставят вас переосмыслить подход к БД, модель данных, модель развертывания, а также его размер.
...
На момент, когда я только задумалась о публикации этой статьи, в моем первоначальном списке уже было на пять пунктов больше. Затем пришло огромное количество новых идей о том, что еще можно охватить. Поэтому в статье затронуты наименее очевидные проблемы, требующие максимального внимания. Впрочем, это не означает, что тема исчерпана и я больше не вернусь к ней в своих будущих материалах и не буду вносить изменения в нынешнюю.
P.S.
Читайте также в нашем блоге:
