[Перевод] Анатомия программы в памяти
Управление памятью — одна из главных задач ОС. Она критична как для программирования, так и для системного администрирования. Я постараюсь объяснить, как ОС работает с памятью. Концепции будут общего характера, а примеры я возьму из Linux и Windows на 32-bit x86. Сначала я опишу, как программы располагаются в памяти.
Каждый процесс в многозадачной ОС работает в своей «песочнице» в памяти. Это виртуальное адресное пространство, которое в 32-битном режиме представляет собою 4Гб блок адресов. Эти виртуальные адреса ставятся в соответствие (mapping) физической памяти таблицами страниц, которые поддерживает ядро ОС. У каждого процесса есть свой набор таблиц. Но если мы начинаем использовать виртуальную адресацию, приходится использовать её для всех программ, работающих на компьютере — включая и само ядро. Поэтому часть пространства виртуальных адресов необходимо резервировать под ядро.

Это не значит, что ядро использует так много физической памяти — просто у него в распоряжении находится часть адресного пространства, которое можно поставить в соответствие необходимому количеству физической памяти. Пространство памяти для ядра отмечено в таблицах страниц как эксклюзивно используемое привилегированным кодом, поэтому если какая-то программа пытается получить в него доступ, случается page fault. В Linux пространство памяти для ядра присутствует постоянно, и ставит в соответствие одну и ту же часть физической памяти у всех процессов. Код ядра и данные всегда имеют адреса, и готовы обрабатывать прерывания и системные вызовы в любой момент. Для пользовательских программ, напротив, соответствие виртуальных адресов реальной памяти меняется, когда происходит переключение процессов: 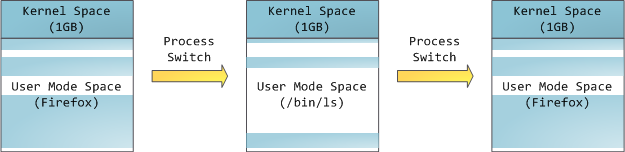
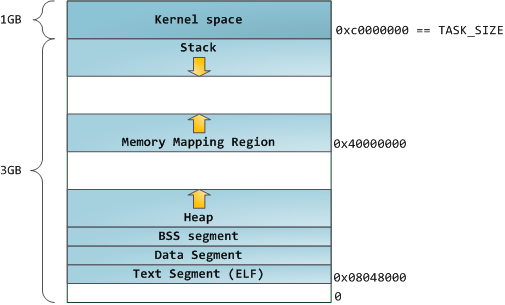
Голубым отмечены виртуальные адреса, соответствующие физической памяти. Белым — пространство, которому не назначены адреса. В нашем примере Firefox использует гораздо больше места в виртуальной памяти из-за своей легендарной прожорливости. Полоски в адресном пространстве соответствуют сегментам памяти таким, как куча, стек и проч. Эти сегменты — всего лишь интервалы адресов памяти, и не имеют ничего общего с сегментами от Intel. Вот стандартная схема сегментов у процесса под Linux:
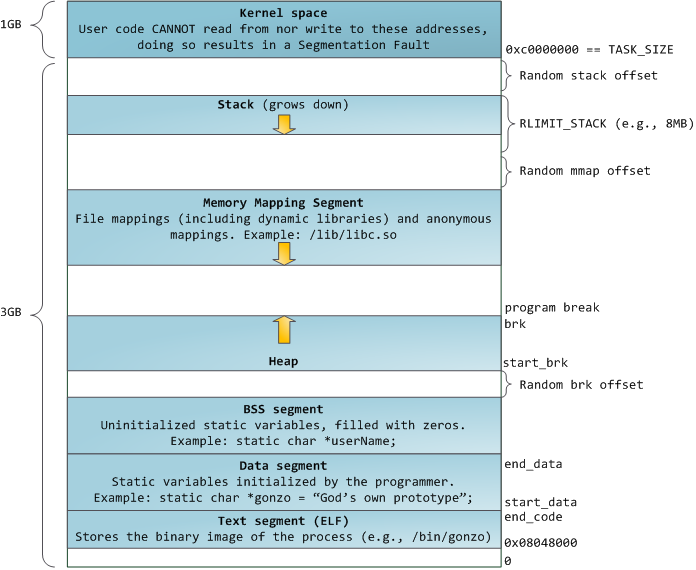
Когда программирование было белым и пушистым, начальные виртуальные адреса сегментов были одинаковыми для всех процессов. Это позволяло легко удалённо эксплуатировать уязвимости в безопасности. Зловредной программе часто необходимо обращаться к памяти по абсолютным адресам — адресу стека, адресу библиотечной функции, и т.п. Удаленные атаки приходилось делать вслепую, рассчитывая на то, что все адресные пространства остаются на постоянных адресах. В связи с этим получила популярность система выбора случайных адресов. Linux делает случайными стек, сегмент разметки памяти и кучу, добавляя смещения к их начальным адресам. К сожалению, в 32-битном адресном пространстве особо не развернёшься, и для назначения случайных адресов остаётся мало место, что делает эту систему не слишком эффективной.
Самый верхний сегмент в адресном пространстве процесса — это стек, в большинстве языков хранящий локальные переменные и аргументы функций. Вызов метода или функции добавляет новый кадр стека (stack frame) к существующему стеку. После возврата из функции кадр уничтожается. Эта простая схема приводит к тому, что для отслеживания содержимого стека не требуется никакой сложной структуры — достаточно всего лишь указателя на начало стека. Добавление и удаление данных становится простым и однозначным процессом. Постоянное повторное использование районов памяти для стека приводит к кэшированию этих частей в CPU, что добавляет скорости. Каждый поток выполнения (thread) в процессе получает свой собственный стек.
Можно прийти к такой ситуации, в которой память, отведённая под стек, заканчивается. Это приводит к ошибке page fault, которая в Linux обрабатывается функцией expand_stack (), которая, в свою очередь, вызывает acct_stack_growth (), чтобы проверить, можно ли ещё нарастить стек. Если его размер не превышает RLIMIT_STACK (обычно это 8 Мб), то стек увеличивается и программа продолжает исполнение, как ни в чём не бывало. Но если максимальный размер стека достигнут, мы получаем переполнение стека (stack overflow) и программе приходит ошибка Segmentation Fault (ошибка сегментации). При этом стек умеет только увеличиваться — подобно государственному бюджету, он не уменьшается обратно.
Динамический рост стека — единственная ситуация, в которой может осуществляться доступ к свободной памяти, которая показана белым на схеме. Все другие попытки доступа к этой памяти вызывают ошибку page fault, приводящую к Segmentation Fault. А некоторые занятые области памяти служат только для чтения, поэтому попытки записи в эти области также приводят к Segmentation Fault.
После стека идёт сегмент разметки памяти. Тут ядро размещает содержимое файлов напрямую в памяти. Любое приложение может запросить сделать это через системный вызов mmap () в Linux или CreateFileMapping () / MapViewOfFile () в Windows. Это удобный и быстрый способ организации операций ввода и вывода в файлы, поэтому он используется для подгрузки динамических библиотек. Также возможно создать анонимное место в памяти, не связанное с файлами, которое будет использоваться для данных программы. Если вы сделаете в Linux запрос на большой объём памяти через malloc (), библиотека C создаст такую анонимную разметку вместо использования памяти из кучи. Под «большим» подразумевается объём больший, чем MMAP_THRESHOLD (128 kB по умолчанию, он настраивается через mallopt ().)
Сама куча расположена на следующих позициях в памяти. Она обеспечивает выделение памяти во время выполнения программы, как и стек — но, в отличие от него, хранит те данные, которые должны пережить функцию, размещающую их. В большинстве языков есть инструменты для управления кучей. В этом случае удовлетворение запроса на размещение памяти выполняется совместно программой и ядром. В С интерфейсом для работы с кучей служит malloc () с друзьями, а в языке, имеющем автоматическую сборку мусора, типа С#, интерфейсом служит ключевое слово new.
Если в куче оказывается недостаточно места для выполнения запроса, эту проблему может обработать сама программа без вмешательства ядра. В ином случае куча увеличивается системным вызовом brk (). Управление кучей — дело сложное, оно требует хитроумных алгоритмов, которые стремятся работать быстро и эффективно, чтобы угодить хаотичному методу размещению данных, которым пользуется программа. Время на обработку запроса к куче может варьироваться в широких пределах. В системах реального времени есть специальные инструменты для работы с ней. Кучи тоже бывают фрагментированными:

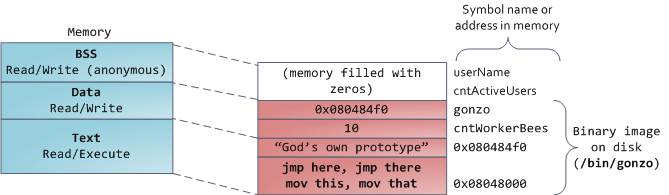
И вот мы добрались до самой нижней части схемы — BSS, данные и текст программы. BSS и данные хранят статичные (глобальные) переменные в С. Разница в том, что BSS хранит содержимое непроинициализированных статичных переменных, чьи значения не были заданы программистом. Кроме этого, область BSS анонимна, она не соответствует никакому файлу. Если вы пишете static int cntActiveUsers, то содержимое cntActiveUsers живёт в BSS.
Сегмент данных, наоборот, содержит те переменные, которые были проинициализированы в коде. Эта часть памяти соответствует бинарному образу программы, содержащему начальные статические значения, заданные в коде. Если вы пишете static int cntWorkerBees = 10, то содержимое cntWorkerBees живёт в сегменте данных, и начинает свою жизнь как 10. Но, хотя сегмент данных соответствует файлу программы, это приватная разметка памяти (private memory mapping) –, а это значит, что обновления памяти не отражаются в соответствующем файле. Иначе изменения значения переменных отражались бы в файле, хранящемся на диске.
Пример данных на диаграмме будет немного сложнее, поскольку он использует указатель. В этом случае содержимое указателя, 4-байтный адрес памяти, живёт в сегменте данных. А строка, на которую он показывает, живёт в сегменте текста, который предназначен только для чтения. Там хранится весь код и разные другие детали, включая строковые литералы. Также он хранит ваш бинарник в памяти. Попытки записи в этот сегмент оканчиваются ошибкой Segmentation Fault. Это предотвращает ошибки, связанные с указателями (хотя не так эффективно, как если бы вы вообще не использовали язык С). На диаграмме показаны эти сегменты и примеры переменных:
Изучить области памяти Linux-процесса можно, прочитав файл /proc/pid_of_process/maps. Учтите, что один сегмент может содержать много областей. К примеру, у каждого файла, сдублированный в память, есть своя область в сегменте mmap, а у динамических библиотек — дополнительные области, напоминающие BSS и данные. Кстати, иногда, когда люди говорят «сегмент данных», они имеют в виду данные + bss + кучу.
Бинарные образы можно изучать при помощи команд nm и objdump — вы увидите символы, их адреса, сегменты, и т.п. Схема виртуальных адресов, описанная в этой статье — это т.н. «гибкая» схема, которая по умолчанию используется уже несколько лет. Она подразумевает, что переменной RLIMIT_STACK присвоено какое-то значение. В противном случае Linux использует «классическую» схему: