[Перевод] Анализ ключевых показателей производительности — часть 3, последняя, про системные и сервисные метрики
Мы заканчиваем публикацию перевода по тестированию и анализу производительности от команды Patterns&Practices о том, с чем нужно есть ключевые показатели производительности. За перевод спасибо Игорю Щегловитову из Лаборатории Касперского. Остальные наши статьи по теме тестирования можно найти по тегу mstesting
В первой статье цикла по анализу ключевых показателей производительности мы наладили контекст, теперь переходим к конкретным вещам. В второй посмотрели на анализ пользовательских, бизнесовых показателей/метрик и показателей, необходимых к анализу внутри приложения. В этой, заключительной — про системные и сервисные (в т.ч. зависимых сервисов) метрики.
Итак,
Системные метрики…
Системные метрики позволяют определять, какие системные ресурсы используются и где могут возникать конфликты ресурсов. Эти метрики направлена на отслеживание ресурсов уровня машины, таких как память, сеть, процессор и утилизация диска. Эти метрики могут дать представление о внутренних конфликтах лежащих в основе компьютера.
Вы также можете отслеживать данные метрики для определения аспектов производительности — нужно понимать, если ли зависимость между системными показателями и нагрузкой на приложение. Возможно, вам потребуются дополнительные апаратные ресурсы (виртуальные или реальные). Если при постоянной нагрузке происходит увеличение значений данных метрик, то это может быть обусловлено внешними факторами -фоновыми задачами, регулярно-выполняющимися заданиями, сетевой активностью или I/O устройства.
Как собирать
Вы можете использовать Azure Diagnostics для сбора данных диагностики для для отладки и устранения неполадок, измерения производительности, мониторинга использования ресурсов, анализа трафика, планирования необходимых ресурсов и аудита. После сбора диагностики ее можно перенести в Microsoft Azure Storage для дальнейшей обработки.
Другой способ для сбора и анализа диагностических данных — это использование PerfView. Этот инструмент позволяет исследовать следующие аспекты:
- CPU utilization. PerfView, используя технологию Sampling Tracing, периодически (милисекундными интервалами) запрашивает стек выполняющегося в текущий момент времени кода и возвращает полный стектрейс потока. Далее PerfView агрегирует собранные стектрейсы различных потоков вместе, и вы, используя утилиту stack viewer, можете посмотреть что ваш код делает (и за какое процессорное время), а также убрать или исправить код который выполняется неправильно.
- Managed memory. PerfView может делать снапшоты управляемой кучи (Managed Heap), которая контролируется сборщиком мусора .net. Эти снапшоты конвертируются в графы объектов, позволяя вам проводить анализ времени жизни объектов.
- Unmanaged memory. PerfView может фиксировать события, когда операционная система выделяет или освобождает блоки памяти. Вы можете использовать эту информацию для отслеживания того, как ваше приложение работает с неуправляемой памятью.
- Timing and blockages. PerfView может отслеживать и визуализировать информацию о том, когда потоки засыпают и просыпаются. Вы можете использовать эту информацию для поиска различных блокировок в вашем приложении. Данный анализ особенно полезен, когда при низкой загрузке процессора наблюдаются проблемы производительности.
Изначально PerfView был предназначен для локального запуска, но теперь он может быть использован для сбора данных из Web и Worker ролей облачных сервисов Azure. Вы можете использовать NuGet-пакет AzureRemotePerfView для установки и запуска PerfView удаленно на серверах ролей, после чего скачать и проанализировать полученные данные локально.
Windows Azure Diagnostics и PerfView полезны для анализа используемых ресурсов «постфактум». Однако, при применении таких практик как DevOps, необходимо мониторить «живые» данные производительности для обнаружения возможных проблем производительности еще до того, как они произойдут. APM-инструменты могут предоставлять такую информацию. Например, утилиты Troubleshooting tools для веб-приложений на портале Azure могут отображать различные графики, показывающие память, процессор и утилизацию сети.

На портале Azure есть «health dashboard», показывающий общие системные метрики.

Аналогичным образом, панель Diagnostic позволяет отслеживать заранее настроенный набор наиболее часто используемых счетчиков производительности. Здесь вы можете определить специальные правила, при выполнении которых оператор будет получать специальные нотификации, например, когда значение счетчика сильно превысит определенное значение.

Веб-портал Azure может отображать данные о производительности в течении 7 дней. Если вам нужен доступ данных за более длительный период, то данные о производительности нужно выгружать напрямую в Azure Storage.
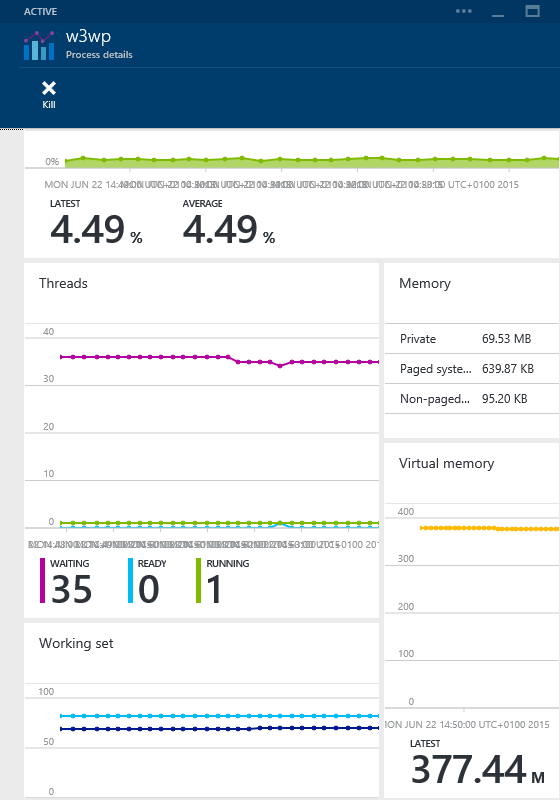
Websites Process Explorer позволяет вам просматривать детали отдельных процессов запущенных на веб-сайте, а также отслеживать корреляции между использованием различных системных ресурсов.
New Relic и многие другие APM имеют схожие функции. Ниже приведено несколько примеров.
Мониторинг системных ресурсов делится на категории, которые охватывают утилизацию памяти (физической и управляемой), пропускную способность сети, работу процессора и операции дискового ввода вывода (I/O). В следующих разделах описано, на что следует обратить внимание.
Использование физической памяти
Все процессы, запущенные в Windows, используют виртуальную память, которая операционной системой проецируется на физическую. Виртуальная память процесса делится на зарезервированную (reserved) и выделенную (commited):
- Зарезервированная память не связана с физической или страничной (paged) памятью, сохраненной в файле подкачки. Она просто описывает объем зарезервированной для процесса памяти, и записывается в дескрипторе виртуального адреса (VAD) для процесса. Эта память не связана с физическим хранилищем и во время мониторинга производительности может быть проигнорирована.
- Выделенная память связана с выделением физической памяти и/или страничной памяти файла подкачки. Использование выделенной памяти необходимо отслеживать.
Вы можете следить за утилизацией выделенной памяти для определения того, достаточно ли на хостинге ваших облачных сервисов или сайтов выделено памяти для поддержки требуемой бизнес-нагрузки и обработки резких всплесков пользовательской активности. Отслеживать необходимо следующие счетчики производительности:
- Memory\Commit Limit показывает максимальный объем памяти, который может быть выделен системой. Обычно это фиксированная величина, которая определяется операционной системой (подробнее How to determine the appropriate page file size for 64-bit versions of Windows) Например, на машине с 8Gb памяти эта цифра составит около 11Gb.
- Process\Private Bytes показывает объем выделенной памяти для процесса. Если сумма всех private bytes для всех процессов превысит предел памяти, описанный выше, это значит, что в системе образовалась нехватка памяти и приложения будут отказывать.
- Memory \% Committed Bytes in Use представляет собой соотношение величин Memory/Committed Bytes и Memory\Commit Limit. Высокое значение этого счетчика указывает, что в системе наблюдается большая нагрузка на память.
Примечание: В Windows есть счетчик Process\Virtual Bytes. Этот счетчик показывает общее количество виртуальной памяти, которое использует процесс, однако к нему нужно относиться очень аккуратно, т.к. на самом он показывает сумму зарезервированной и выделенной памяти процесса. Для примера, исследуя счетчики Process/Virtual Bytes и .NET CLR Memory\# total reserved bytes при старте процесса w3wp, данный счетчик может показывать 18 Гб, хотя его общий объем памяти составляет 185 Мб.
Зарезервированная память может расширяться за счет динамической ОЗУ и процессы могут преобразовывать эту память в физическую.
Существует две основные причины ошибки OutOfMemory — процесс превышает выделенное для него пространство виртуальной памяти либо операционная система оказывается неспособной выделить дополнительную физическую память для процесса. Второй случай является самым распространенным.
Вы можете использовать описанные ниже счетчики производительности для оценки нагрузки на память:
- Memory\Available Mbytes. В идеале значение данного счетчика должно превышать 10% от объема физической памяти, установленной на машине. Если объем доступной памяти слишком мал, то есть вероятность, что система начнет использовать для активных процессов файл подкачки. Если системе не хватает физической памяти, то результатом этого могут быть значительные задержки и/или полное зависание системы.
- Memory\% Committed Bytes In Use. Предел выделенной памяти будет расти, если общий объем выделенной памяти приблизится к 90% от предельного значения — если же значение достигнет 95%, то предел вероятно перестанет расти, и появится вероятность возникновения ошибки OutOfMemory. Как только объем выделенной памяти достигнет предела, то система больше не сможет выделять память для процессов. Большинство процессов не справится с данным поведением системы и прекратят свое выполнение. Поэтому очень важно следить за этим счетчиком.
- Memory\Pages/sec. Этот счетчик показыет, на сколько система использует файл подкачки. Вы можете определить, какое влияние оказывает подкачка на физическую память — для этого надо умножить значение данного счетчика на значение счетчика Physical Disk\Avg.Disk sec/Transfer. Результат данной операции окажется между 0 и 1, и будет характеризовать долю времени доступа к диску, которое затрачивается на чтение и запись виртуальных страниц в файл подкачки. Значение 0.1 означает, что система тратит больше 10% от всего времени доступа к диску на работу с файлом подкачки. Если это значение является постоянной величиной, то это может указывать на проблемы с физической памятью.
Также следует учитывать, что большие объемы памяти могут привести к фрагментации (когда свободной физической памяти в соседних блоках недостаточно), поэтому система, которая показывает, что имеет достаточно свободной памяти, может оказаться не в состоянии выделить эту память для конкретного процесса.
Многие APM-инструменты предоставляют сведения об использовании процессами системной памяти без необходимости глубокого понимания о принципах работы памяти. На графике ниже показана пропускная способность (левая ось) и время отклика (правая ось) для приложения, находящегося под постоянной нагрузкой. Примерно после 6 минут производительность внезапно падает, и время отклика начинает «прыгать», после прошествия нескольких минут происходит показателей.

Результаты нагрузочного тестирования приложения
Записанная с помощью New Relic телеметрия показывает избыточное выделение памяти, которое вызывает сбой операций с последующим восстановлением. Использованная память растет за счет файла подкачки. Такое поведение является классическим симптомом утечки памяти.

Телеметрия, показывающая избыточное выделение памяти
Примечание: В статье Investigating Memory Leaks in Azure Web Sites with Visual Studio 2013 содержится инструкция, показывающая как использовать Visual Studio и Azure Diagnostics для мониторинга использования памяти в веб-приложении в Azure.
Использование управляемой памяти
.NET приложения используют управляемую память, которая контролируется CLR (Common Language Runtime). Среда CLR проецирует управляемую память на физическую. Приложения запрашивают у CLR управляемую память, и CLR отвечает за выделение требуемой и освобождение неиспользуемой памяти. Перемещая структуры данных по блокам, CLR обеспечивает компоновку этого типа памяти, уменьшая тем самым фрагментацию.
Управляемые приложения имеют допоплнительный набор счетчиков производительности. В статье Investigating Memory Issues содержится детальное описание ключевых счетчиков. Ниже описаны наиболее важные счетчики производительности:
- .NET CLR Memory# Total Committed Bytes память процесса, которая опирается на физическую память и страничное место на диске. Данный счетчик отображает количество выделенной памяти процесса и должен быть очень похож на значение счетчика Process/Private Bytes.
- .NET CLR Memory# Total Reserved Bytes указывает на объем зарезервированной памяти для процесса. Он должен быть примерно равен значению счетчика Process\Virtual Bytes и быть меньше значения Process\Private Bytes.
- .NET CLR Memory\Allocated Bytes/sec, показывает на изменчивость управляемой кучи. Значение этого счетчика может быть положительным или отрицательным в зависимости от того, создает или уничтожает приложение объекты. Это счетчик обновляется после каждого цикла сборки мусора. Постоянно-положительное значение этого счетчика может указывать на утечку памяти.
- .NET CLR Memory# Bytes in all Heaps показывает на общий размер управляемой кучи для процесса.
- .NET CLR Memory\% Time in GC процент времени, который был затрачен на выполнение последнего цикла сборки мусора. Хорошим показателем этого счетчика является значение <10%.
Латентность сети на веб-сервере
Производительность сеть особенно важна для облачных приложений, т.к. это проводник, через который проходит вся информация. Сетевые проблемы могу привести к снижению производительности, которое вызовет неудовольствие пользователей, так как сетевые задержки приводят к увеличению длительности выполнения запросов. В настоящее время Windows не предоставляет счетчиков производительности для измерения латентности запросов отдельных приложений. Однако есть Resource Monitor, являющийся отличным инструментом для анализа сетевого трафика на локальной машине (вы можете настроить Remote Desktop во время деплоя ваших облачных сервисов и залогиниться на сервер ваших Web или Worker ролей). Resource Monitor предоставляет информацию о потерянных пакетах или информацию об общей задержке активных TCP/IP сессий. Потеря пакетов дает представление о качестве соединения. Задержка показываетвремя, требуемое для полного прохождения маршрута TCP/IP пакетом. На рисунке показана Network tab в Resource Monitor.
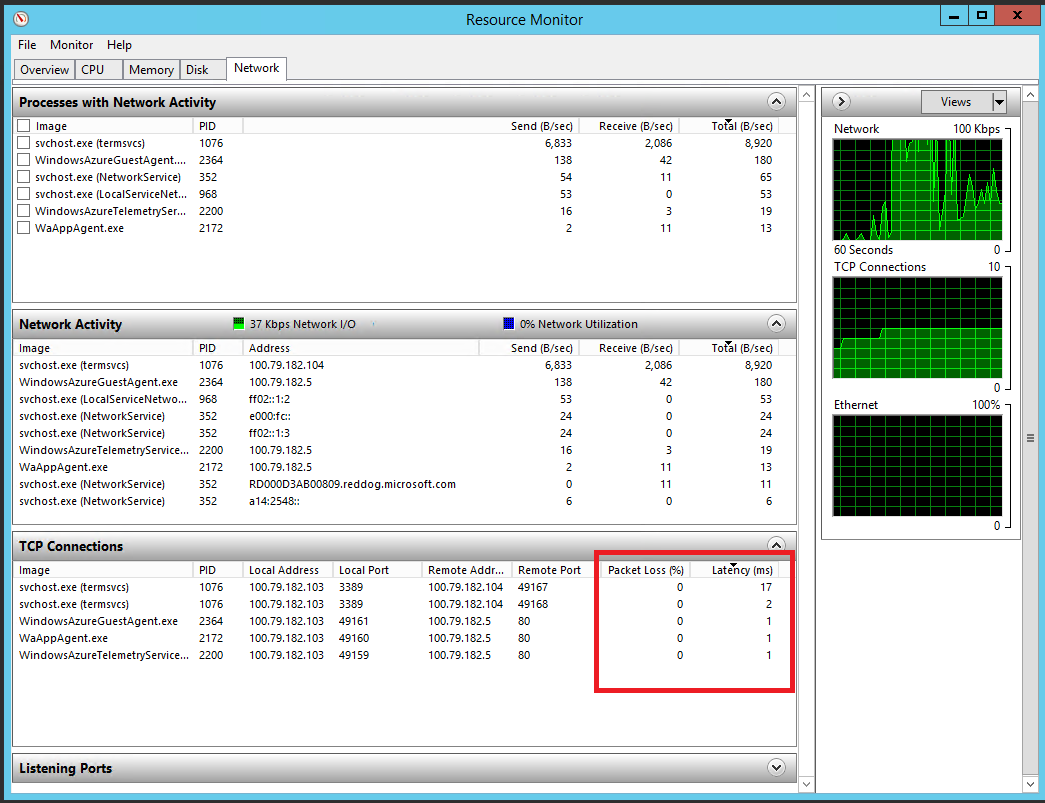
Resource Monitor, показывающий активность локальной сети
Использование сети на веб-сервере
Вы можете получить следующие счетчики производительности путем прямого подключения к веб-серверу из Perfomance Monitor (если вам требуетеся информация в режиме реального времени) либо настроить Azure Diagnostics для сохранения данных в Azure Storage.
- Network Adapter\Bytes Sent/sec и Network Adapter\Bytes Received/sec показывает скорость передачи и получения данных сетевым адаптером
- Network Adapter\Current Bandwidth используется для оценки допустимой полосы пропускания (в байтах в секунду) сетевого адаптера
- %Network utilization for Bytes Sent = ((Bytes Sent/sec * 8) / Current Bandwidth) * 100
- %Network utilization for Bytes Received = ((Bytes Received/sec * 8) / Current Bandwidth) * 100
Если эти значения окажутся около 100%, то это может свидетельствовать о перегрузке сети. В этом случаем может понадобиться распределить сетевой трафик на несколько экземпляров облачного приложения.
Портал Azure может показывать утилизацию сети всех экземплярами облачных сервиса, а также конкретного экземпляра роли. На портале доступны cчетчики Network In и Network Out, предоставляющие информацию по количеству полученных и отправленных байт в секунду.

Мониторинг использования сети на портале управления Azure
Если сетевые задержки очень высоки, но при этом утилизация низкая, то сеть вряд ли является узким местом. Высокая утилизация CPU экземпляров приложения может означать, что требуется больше мощностей, и нагрузку следует распараллелить между несколькими экземплярами. Если же утилизация CPU низкая, то это может быть связано с влиянием внешних сервисов. Например, сложные запросы, отправленные в БД Azure SQL, могут долго выполняться. В этой ситуации распределение сетевого трафика между экземплярами может усугубить проблемы производительности из-за перегрузки сервера БД, что в дальнейшем приведет к увеличению задержки. Вы должны быть готовы отслеживать использование внешних сервисов.
Примечание: Для получения подробной информации о сетевых задержках и ширине канала рекомендуем ознакомиться с инструментом PsPing от Windows Sysinternals.
Объемы сетевого трафика
Другой частой причиной задержек является большой объем сетевого трафика. Вы должны исследовать объемы трафика на внешние сервисы. Многие APM-инструменты позволяют отслеживать трафик, направленный в сторону облачных сервисов и веб-приложений. На рисунке показан пример, взятый из New Relic, на котором показан входящий и исходящий сетевой трафик службы Web API. Большой объем общего трафика (~200 Мб/cек) приводит к высокой латентности для клиентов.
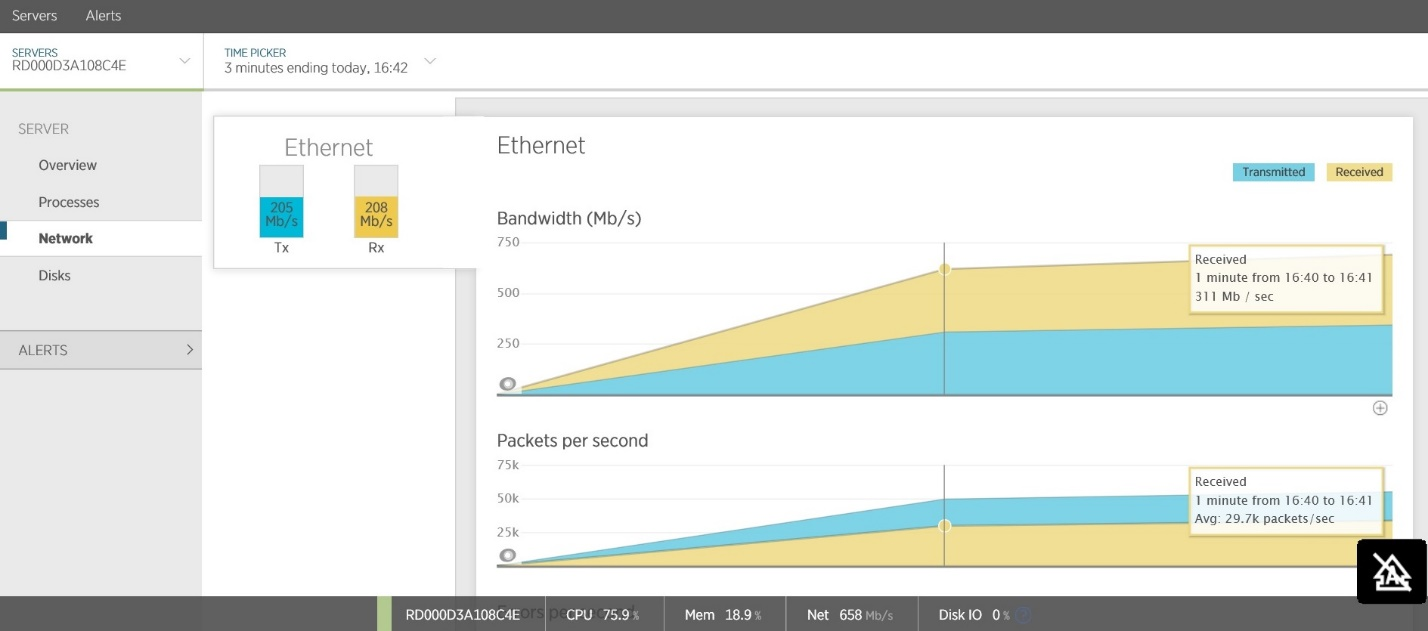
Портал управления Azure также содержит инструменты для просмотра утилизации внешних сервисов, таких как Azure SQL БД и Azure Storage.
Сетевые оверхеды и расположение клиентов
Высокие сетевые задержки могут быть связаны с такими накладными расходами, как взаимодействие протоколов, потери пакетов и эффекты маршрутизации. Латентность и пропускная способность может сильно зависить от расположения клиентов и сервисов, с которыми они работают. Если клиенты расположены в разных регионах, то следует расмотреть вопрос распределения экземпляров сервисов по регионам, убедившись что в каждом регионе будет достаточно мощностей для обработки требуемой нагрузки.
На графиках ниже показано, как географическая распределенность пользователей может повлиять на пропускную способность и латентность. Постоянный поток запросов в течении трех минут отправлялся на сервис. Данный сценарий использовался для двух тестов — в первом клиенты и сервер были расположены в одном регионе, а во втором — в разных. На обоих графиках левая ось показывает производительность в операциях в секунду, а правая — время отклика в секундах.
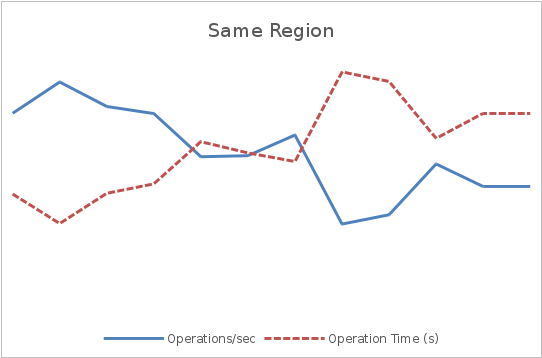
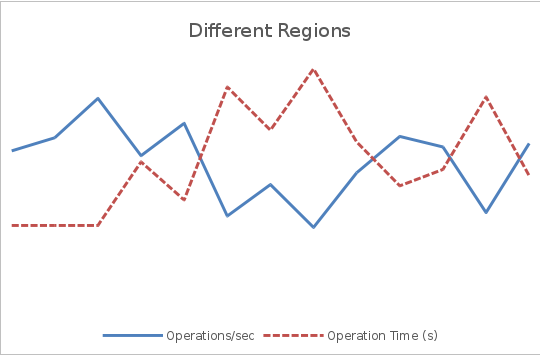
На первом графике средняя пропускная способность оказывается в несколько раз выше, чем во втором, а время отклика составляет примерно ¼ времени отклика второго графика.
Размер полезной нагрузки сообщения, проходящего по сети
Размер тела запросов и ответов может оказать существенное влияние на пропускную способность. XML-запросы могут быть существенно больше, чем их эквиваленты в формате JSON. Бинарно-сериализованные данные могут быть более компактными, но менее гибкими. Помимо потребления полосы пропускания, большие запросы приводят к дополнительной нагрузке на CPU, затрачиваемой на разбор или десериализацию данных.
Следующие графики иллюстрируют влияние различных размеров запросов на пропускную способность и время отклика. Как и прежде, на обоих графиках использовался один и тот же тестовый сервис. Клиенты и сервис расположены в одном регионе.


Здесь видно, что увеличение размера сообщения в 10 раз привело к снижению пропускной способности и увеличению времени отклика. Следует отметить, что это искусственный тест, ориентированный на демонстрацию сетевого трафик. Здесь не учитываются дополнительные процессы, необходимые для обработки запросов, а также отсутствует влияние стороннего сетевого трафика, генерируемого другими клиентами или сервисами.
«Болтливость» в сети
«Болтливость» (chattiness) является другой распространенной причиной сетевых задержек. Болтливостью называют частоту сетевых сессий, необходимых для выполнения бизнес-операции.
Для обнаружения «болтливости» все операции должны включать телеметрию, фиксирующую частоту вызова, а также кем и когда они были вызваны. Телеметрия должна включать размер сетевых запросов на входе и выходе операции. Большое число относительно мелких запросов в короткий промежуток времени, отправленных одним и тем же клиентом, может указывать на необходимость оптимизации системы путем объединения этих запросов в один или несколько. В качестве примера, на рисунке показана телеметрия тестового Web API сервиса. На каждый вызов API происходит один или более запросов в Azure SQL. Во время проведения мониторинга средняя пропускная способность составляла 13900 запросов в минуту. На рисунках также видна телеметрия БД, на которой видно, что за этот промежуток времени сервис сделал более 250000 запросов к БД. Эти цифры указывают на то, что при каждом вызове Web API в среднем происходит 18 вызовов к БД.


Вызовы к БД, происходящие при запросах к приложению
Использование CPU на уровне сервера и экземпляра
Загрузка (утилизация) CPU является мерой, измеряющей количество работы машины, а «доступность» CPU показывает количество запасных мощностей процессора, которые имеет машина для обработки дополнительной нагрузки. Используя APM, вы можете получать эту информацию для конкретного сервера, на котором запущен веб-сервис или облачное приложение. Рисунок показывает статистику New Relic.

Веб-портал Azure позволяет просматривать данные CPU для каждого экземпляра сервиса.

Использование CPU для экземпляров сервиса на портале Azure
Высокая утилизация CPU может быть следствием большого количества исключений, генерация которых перегружает процессор.
Вы можешь отслеживать частоту возниковения исключений, используя подходы, описанные ранее в соответствующих секциях. Чрезмерная утилизация процессора может быть обусловлена приложениями, в которых происходит частая сборка мусора больших объектов. Вы должны исследовать счетчики CLR Garbage Collections согласно описанию в разделе «Использование управляемой памяти», чтобы оценить влияние сборщика мусора (GC) на общую загрузку процессора. Вы также должны убедиться, что в вашей системе правильно настроена политика сборки мусора (подробнее см. Fundamentals of Garbage Collection).
Низкая утилизация CPU в совокупности с высокой латентностью может быть связана с различными блокировками, что может означать наличие проблем в коде, таких как неправильное использование блокировок или ожиданий выполнения синхронных I/O операций (подробнее см. антипаттерн Synchronous I/O).
Процессорное свойство affinity (привязка процесса к конкретному процессору) может привести к тому, что процессор или ядро процессора окажется узким местом. Такая ситуация может возникнуть в облачном приложении в Azure с Worker-ролью. Запросы от Web-роли могут всегда направляться на кокретную Worker-роль в обход балансировщика нагрузки.
Использование CPU на конкретном сервере
Процессор работает в двух режимах: пользовательском и привилегированном. В пользовательском режиме процессор выполняет инструкции, составляющие бизнес- логику приложения. В привилегированном режиме процессор выполняет операции уровня ядра операционной системы, такие как файловые операции, выделение памяти, подкачка, управление потоками, переключение контекста между процессами. Для отслеживания загрузки процессора следует наблюдать за следующими счетчиками производительности:
- Processor\%Privileged Time количество времени, которое тратит процессор на работу в привилегированном режиме. Постоянно-высокое значение этого счетчика показывает, что система тратит значительное время, выполняя функции операционной системы и может быть вызвано большими объемами операций I/O, постоянными блокировками процессов или потоков, чрезмерной подкачкой или накладными расходами при управлении памятью (например, при сборке мусора).
- Processor\%User Time, время, котрое тратит процессор на выполнение кода приложения, а не системных функций.
- Processor\%Processor Time общая загрузка процессора (в пользовательском и привилегированном режимах). Обычно загрузка процессора колеблется между высокими и низкими значениями, но постоянно высокий уровень (свыше 80%) означает, что процессор может являться узким местом. Например, антипаттерн Busy Front End показывает ситуацию, когда нагрузка изначально сосредоточена на одной Web-роли, а также рассказывает то, как улучшить время отклика при использовании очереди для переноса обработки данных на отдельные рабочие роли.
Процессы, активно потребляющие CPU
Вы можете исследовать возможные причины высокой загрузки процесса в тестовой среде во время нагрузочного тестирования. Такой подход должен помочь ликвидировать влияние внешних факторов. Многие APM-инструменты поддерживают профилировку потоков для анализа выполнения процессором стека операций. Рисунок показывает пример профилировки в New Relic.
Профилировка в New Relic
После проведения профилировки за определенный период времени, New Relic позволяет анализировать эту информацию и исследовать операции которые затрачивают наибольшее процессорное время. Полученная информация может стать сигналом к оптимизации кода.
Эта техника является очень мощным инструментом, но она может оказывать существенное влияние на производительность реальных пользователей. Таким образом, при проведении данного процесса на реальной среде, вы должны сразу выключать профилировщик после сбора данных.
Использование диска
Высокая частота операций ввода-вывода (I/O) обычно вызвана такими задачами, как бизнес-аналитика или обработка изображений. Кроме того, многие сервисы хранения данных (например, Azure SQL БД, Azure Storage и Azure DocumentDB) активно используют ресурсы диска. Если вы создаете виртуальные машины для запуска ваших сервисов, то вам может понадобиться мониторинг доступа к диску. Это нужно, чтобы убедиться, что вы выбрали правильную конфигурацию диска для обеспечения хорошей производительности.
Приложения с интенсивным использованием памяти также могут инициировать значительную дисковую активность. Перерасход памяти может привести к увеличению размеру и, как следствите, уменьшению производительности. В этом случае может потребоваться горизонтальное масштабирование роли, для перераспределения нагрузки по нескольким экземплярам, но перед этим следует проанализировать ваше приложение на предмет правильного использования памяти (причиной может быть банальная утечка).
В Azure виртуальные диски (которые используются в виртуальных машинах) создаются в Azure Storage. На сегодняшний день существует два типа Azure Storage: стандартный и Premium. Производительность вирутальных дисков измеряется в количестве операций ввода-вывода в секунду, а пропускная способность в МБ в секунду. IOPS (количество операций ввода/вывода — от англ. Input/Output Operations Per Second) — это стандартный показатель производительности различных видов хранилищ. Стандартное хранилище позволяет обрабатывать до 500 операций ввода-вывода в секунду при максимальной производительности 60 Мб/сек. Premium-хранилище основано на SSD-накопителях и может работать со скоростью до 5000 операций ввода-вывода и обеспечивать пропускную способность в 200 Мб/сек.
Использование RAID-дисков в конфигурациях виртальных машин может увеличить пропускную способность, но в этом случае контроль за выполнением I/O запросов будет осуществляться на уровне самой виртуальной машины. Подробнее см. Sizes for Virtual Machines.
Примечание: IOPS и пропускная способность измеряют разные аспекты производительности I/O-операций. Приложение, выполняющее большое число небольших дисковых операций, скорее всего, упрется в лимит по IOPS вне зависимости от пропускной способности. Приложение, выполняющее мало операций с большими данными, может достичь лимита пропускной способности прежде чем достигнет лимита по IOPS. Для максимальной производительности приложениям необходимо балансировать между частотой I/O операций и размерами данных.
Вы можете измерять производительность различных дисков (конфигураций) используя SQLIO Disk Subsystem Benchmark Tool. Для примера, если запустить данную утилиту на виртуальной машине на стандартных дисках, то вы получите следующий результат:

Производительность I/O одного стандартного диска на виртуальной машине
Видно, что диск, как и ожидалось, может обрабатывать порядка 500 операций ввода вывода. Этот же тест, но на RAID-массиве, состоящем из 4-х дисков (каждый из которых находится в стандартном Azure Storage) показывает следующие результаты.

Производительность I/O на striped-диске
В этом случае производительность достигает 1400 IOPS. Используя данную технологию с дисками Premium-хранилища, вы можете достичь производительности 80000 IOPS и низкой задержки операций чтения.
Обратите внимание, что за регулирование (ограничение) пропускной способности отвечает сама платформа Azure. Оно может возникать, если ваше приложение превысит IOPS или пропускную способность Premium-диска (5000 IOPS) или если суммарный трафик через все диски (в случае RAID) превысит дисковый предел виртуальной машины. Чтобы избежать этого, вы должны ограничить количество незавершенных (ожидающих) I/O запросов к диску максимальным значением IOPS используемого вида стораджа или же общей дисковой пропускной способности вашей виртуальной машины. Подробнее см. Premium Storage: High-Performance Storage for Azure Virtual Machine Workloads.
Портал Azure позволяет контролировать общую пропускную способность I/O операций виртуальной машины. Многие же APM-инструменты предоставляют информацию об активности отдельных дисков. На примере ниже показана производительность диска, полученная в New Relic. Собираемая статистика включает количество I/O-операций, позволяя вам увидеть, насколько вы близко к лимитам. Обратите внимание, что, когда утилизация диска составляет 100%, то показатель IOPS равен примерно 1500. Это соответствует максимальной пропускной способности для RAID`а из 4-х дисков (стандартное хранилище):
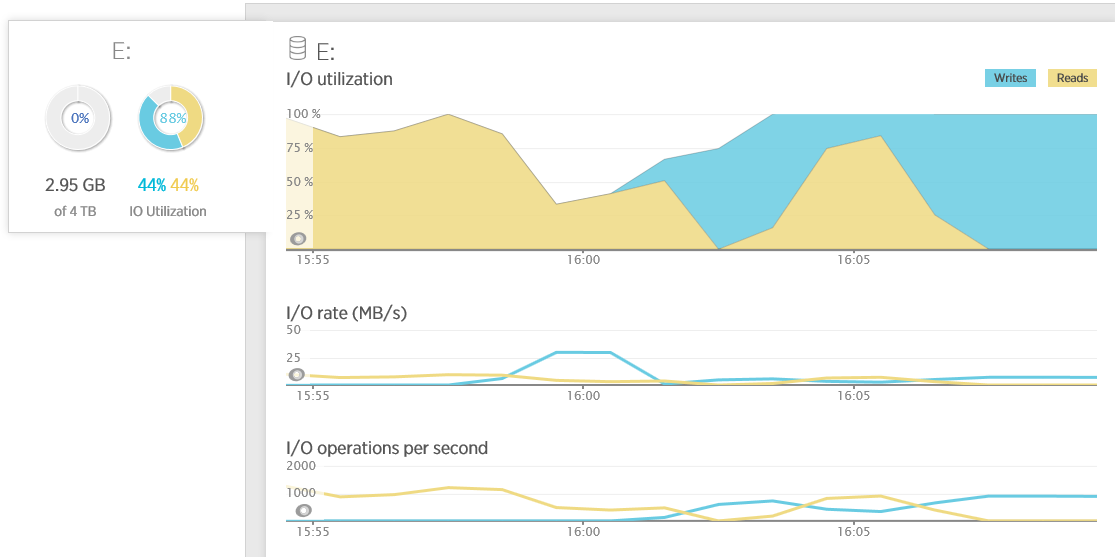
Вы также можете контролировать активность диска, используя следующие счетчики производительности (объекта Physical Disc):
- Avg. Disk sec/Read и Avg. Disk sec/Write. Это среднее время (в секундах) операций чтения и записи. Время ожидания диска сильно зависит от программного обеспечения и дискового кеша, но данные счетчики являются надежными показатели производительности диска. Для содержимого (payload) размером меньше 64 КБ пороговое значение этих счетчиков меньше 15 мс является очень хорошим значением. Однако из-за неустойчивой модели I/O операций в устройствах хранения данных, вполне нормально увидеть, что периодически это значение в пике может оказаться в несколько раз выше ожидаемого.
- Disk Transfers/sec. Это скорость выполнения диском операций чтения и записи. Следует отметить, что данная скорость для одного диска, в зависимости от размера данных, может оказаться выше его IOPS. Этот счетчик поможет определить суммарную пропускную способность I/O-операций на диске. Оборудование диска и производительность могут значительно отличаться, поэтому нет никакого универсального порогового значения для данного счетчика. С учетом выше сказанного попробуем установить уровень производительности для диска, а затем сравним его с базовым. Например, если вы знаете, что диск поддерживает 100 обращений в секунду при времени отклика 10 мс, то при тестировании вы можете найти время отклика в 50 мс и пропускную способность 20 обращений в секунду. Это указывает на существенное замедление оборудования диска (например, физический диск используют несколько серверов). В этом случае может потребоваться распределить нагрузку на несколько дисков или перейти на более мощные виртуальные машины.
- Disk Bytes/Sec, Disk Read Bytes/sec и Disk Writes Bytes/sec. Вы можете использовать данные счетчики для определения того, как размер запросов влияет на производительность. Запрос размером в 1 MB в 256 раз больше запроса размером в 4 КВ, поэтому для его обработки требуется больше времени. Если вы обнаружите, что среднее время выполнения запросов окажется больше 15 мс, то следует проверить средний размер I/O запросов, используя счетчики Avg. Disk Bytes/Read и Avg. Disk Bytes/Write
- Avg. Disk Queue Length, Avg. Disk Read Queue Length, and Avg. Disk Write Queue Length. Эти счетчики измеряют количество дисковых I/O операций, ожидающих обработки (в очереди). Эти счетчики вычисляются по формуле:
- Avg. Disk Queue Length = (Disk Transfers/sec) * (Disk sec/Transfer)
Эти счетчики очень важны для приложений с большой дисковой активностью, т.к. есть вероятность появления в таких приложениях длинных очередей доступа к диску. - % Idle Time. Этот счетчик показывает процент времени простаивания диска. Диск простаивает при отсутствии запросов. Этот счетчик не такой полезный, как кажется. Пока длина очереди диска 1 или более, то %idle time для этого диска 0. Используя данный счетчик, вы можете определить только промежутки времени, когда диск ничего не делал, а не общую занятость диска (для этой цели используйте счетчики длины очереди).
Сервисные метрики
Большинство облачных приложений и сервисов Azure зависят от одного или нескольких внешних сервисов, выполняющих функции хранения, кэширования и обмена сообщениями. Производительность этих сервисов может оказать значительное влияние на систему, поэтому очень важно отслежить их работу.
Общий вопрос, рассматриваемый в этом разделе, связан с внешним давлением (backend pressure). Это явление, которое происходит, когда приложение отправляет внешним сервисам объем работы, который они не могут выполнить. Это может привести к увеличению латентности и снижению пропускной способности приложения. Кроме того, временами подключения к внешим сервисам могут обрываться или же сервисы могут выбрасывать исключения.
Как собирать?
Порт
