[Перевод] 6 уроков, извлечённых из поиска решения масштабной проблемы на gitlab.com. Часть 2
Представляем вашему вниманию вторую часть перевода материала о борьбе команды gitlab.com с тиранией времени.

→ Вот, кстати, первая часть.
Ограничение скорости обработки запросов
В этот момент мы не были заинтересованы в простом повышении значений параметра MaxStartups. Хотя 50% увеличение этого параметра и показывало себя хорошо, дальнейшее его повышение без достаточных на то оснований выглядело как довольно-таки грубое решение проблемы. Наверняка было ещё что-то, что мы могли сделать.
Поиски привели меня на уровень HAProxy, который был расположен перед SSH-серверами. У HAProxy есть приятная опция rate-limit sessions, влияющая на ту часть системы, которая принимает входящие запросы. Если эта опция настроена — она используется для ограничения количества новых TCP-запросов в секунду, которые фронтенд передаёт бэкендам, оставляя при этом дополнительные входящие соединения в TCP-сокете. Если скорость поступления входящих запросов превышает лимит (изменяемый каждую миллисекунду), то новые соединения просто откладываются. TCP-клиент (в данном случае — SSH) просто видит задержку перед установкой TCP-соединения. Это, на мой взгляд, очень красивый ход. До тех пор, пока скорость поступления запросов не будет, на слишком больших отрезках времени, слишком сильно превышать лимит, система будет работать хорошо.
Следующим вопросом стал подбор значения опции rate-limit sessions, которое нам следовало бы использовать. Поиск ответа на этот вопрос усложнял тот факт, что у нас имеется 27 SSH-бэкендов и 18 HAProxy-фронтендов (16 главных и 2 alt-ssh), а также то, что фронтенды не координируют между собой то, что относится к скорости обработки запросов. Кроме того, нам нужно было принимать во внимание то, сколько времени занимает этап аутентификации новой SSH-сессии. Предположим, что первое значение MaxStartups равно 150. Это значит, что если фаза аутентификации занимает две секунды, то мы можем передавать каждому из бэкендов только 75 новых сессий в секунду. Здесь можно найти подробности о расчёте значения rate-limit sessions, я не буду тут вдаваться в подробности. Отмечу лишь то, что для вычисления этого значения нужно учесть четыре параметра. Первый и второй — это количество серверов обоих типов. Третий — значение MaxStartups. Четвёртый — это T — то, сколько времени занимает аутентификация SSH-сессии. Значение T чрезвычайно важно, но его можно вывести лишь приблизительно. Мы так и поступили, выйдя в итоге на значение в 2 секунды. В результате у нас получилось значение rate-limit для фронтендов, которое составило 112.5. Мы округлили его до 110.
И вот, новые настройки вступили в силу. Наверное, вы думаете, что после этого всё благополучно кончилось? Должно быть, число ошибок устремилось к нулю и все вокруг были оказались безмерно счастливы? Ну, на самом деле всё было далеко не так хорошо. Это изменение не привело к каким-либо видимым изменениям уровня ошибок. Откровенно говоря, я был изрядно расстроен. Мы упустили что-то важное или неправильно поняли суть проблемы.
В результате мы вернулись обратно к логам (и, в конце концов, к сведениям о HAProxy) и смогли убедиться в том, что ограничение скорости обработки запросов, по крайней мере, работает, воздействуя на запросы так, как мы ожидали. Раньше соответствующие показатели были выше, это позволяло сделать вывод о том, что мы успешно ограничили скорость, с которой поступающие запросы направляются на обработку. Но совершенно очевидно было то, что скорость поступления запросов всё ещё была слишком высокой. Хотя было понятно и то, что она даже и близко не подходит к тем уровням, когда она могла бы оказать заметное влияние на систему. Когда мы проанализировали процесс выбора бэкендов (по логам HAProxy), мы заметили там одну странность. В начале часа бэкенд-соединения были распределены по SSH-серверам неравномерно. В выбранном для анализа промежутке времени число соединений в секунду на разных серверах варьировалось от 30 до 121. А это означало, что наша балансировка нагрузки справляется со своей задачей не так уж и хорошо. Анализ конфигурации показал, что мы использовали опцию balance source, благодаря чему клиент с определённым IP-адресом всегда подключался к одному и тому же бэкенду. Это можно рассматривать как положительное явление в тех случаях, когда нужна привязка сессий. Но мы имеем дело с SSH, поэтому нам это не нужно. Эта опция была когда-то нами настроена, но мы не обнаружили никаких намёков на то, почему это было сделано. Мы не могли найти достойной причины для того, чтобы продолжать её использовать. В результате мы решили перейти на leastconn. Благодаря этой опции новые входящие соединения отдают бэкенду с минимальным числом текущих соединений. Это повлияло на использование ресурсов процессора нашими SSH (Git) серверами. Вот соответствующий график.
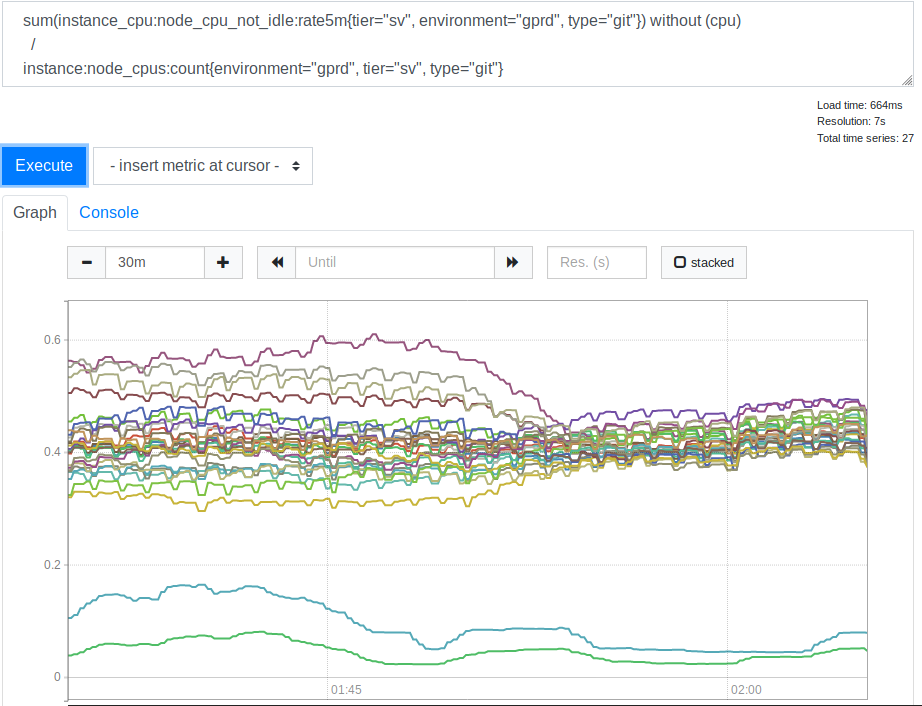
Потребление ресурсов процессора серверами до и после применения опции leastconn
После того, как мы это увидели, мы поняли, что использование leastconn — это удачная идея. Две линии, которые находятся в нижней части графика — это наши Canary-серверы, на них можно не обращать внимания. Но раньше разброс значений нагрузки на CPU у разных серверов соотносился как 2:1 (от 30% до 60%). Это явно указывало на то, что раньше некоторые из наших бэкендов были нагружены сильнее других за счёт привязки к ним клиентов. Для меня это стало неожиданностью. Казалось, разумно ожидать того, что широкий диапазон IP-адресов клиентов достаточен для того, чтобы нагружать наши серверы гораздо равномернее. Но, по видимому, для того, чтобы исказить показатели нагрузки серверов, достаточно было нескольких крупных клиентов, поведение которых отличается от некоего усреднённого варианта.
Урок №4. Когда вы выбираете специфические настройки, отличающиеся от настроек по умолчанию, комментируйте их или оставляйте ссылку на материалы, объясняющие изменения. Тот, кому в будущем придётся заниматься этими настройками, будет вам за это благодарен.
Эта прозрачность является одной из ключевых ценностей GitLab.
Включение опции leastconn, кроме того, помогло снизить уровни ошибок. А это было именно то, к чему мы и стремились. Поэтому данную опцию мы решили оставить. Но, продолжая экспериментировать, понизили уровень ограничения скорости обработки запросов до 100, что помогло ещё сильнее снизить уровень ошибок. Это указывало на то, что изначальный подбор значения T, вероятно, был выполнен неправильно. Но если так, то этот показатель был слишком мал, что вело к слишком сильному ограничению скорости, и даже 100 запросов в секунду воспринималось как очень низкое значение, и мы не были готовы дальше его снижать. К несчастью, по некоторым внутренним причинам, эти два изменения были лишь экспериментом. Нам пришлось вернуться к использованию опции balance source и к ограничению скорости обработки запросов в 100 запросов в секунду.
Учитывая то, что скорость обработки запросов была настроена на устраивающий нас низкий уровень, и то, что мы не могли пользоваться leastconn, мы попытались увеличить параметр MaxStartups. Сначала мы увеличили его до 200, это дало некоторый эффект. Потом — до 250. Ошибки почти полностью исчезли и ничего плохого не произошло.
Урок №5. Хотя высокие значения MaxStartups и могут выглядеть пугающими, они оказывают очень небольшое воздействие на производительность даже тогда, когда оказываются гораздо выше, чем значения, устанавливаемые по умолчанию.
Возможно, это — нечто вроде большого и мощного рычага, которым мы можем, при необходимости, воспользоваться в будущем. Возможно, мы столкнёмся с проблемами, если речь пойдёт о цифрах в районе нескольких тысяч или нескольких десятков тысяч, но нам ещё до этого далеко.
Что это говорит о моих оценках параметра T, времени, необходимого для установки и аутентификации SSH-сессии? Если поработать с формулой расчёта показателя ограничения скорости обработки подключений, зная о том, что 200 — не вполне достаточно для показателя MaxStartups, а 250 — достаточно, можно выяснить, что T, вероятно, имеет значение от 2.7 до 3.4 секунд. В результате оценочное значение в 2 секунды было недалеко от истины, но реальное значение, определённо, оказалось выше ожидаемого. Мы вернёмся к этому немного позже.
Заключительные шаги
Мы снова просмотрели логи, учитывая то, что уже знали, и, после некоторых размышлений, выяснили, что проблему, с которой всё это началось, можно выявить по следующим признакам. Во-первых, это значение t_state, равное SD. Во-вторых — это значение b_read (байты, прочитанные клиентом), равное 0. Как уже было сказано, мы обрабатываем примерно 26–28 миллионов SSH-подключений в день. Неприятно было узнать о том, что, в разгар бедствия, примерно 1.5% этих подключений оказывались грубо разорванными. Очевидно то, что масштабы проблемы были куда больше, чем мы думали в самом начале. При этом тут не было ничего такого, что мы не могли бы обнаружить раньше (ещё тогда, когда поняли, что на проблему указывало появление в логах t_state="SD"), но мы и не думали о том, чтобы это сделать, хотя нам и следовало бы об этом подумать. Вероятно, из-за этого мы потратили на решение проблемы значительно больше времени и сил, чем могли бы потратить.
Урок №6. Измеряйте реальные уровни ошибок как можно раньше.
Если бы мы изначально догадывались о масштабах проблемы, то могли бы уделить ей больше внимания. Хотя, то, как это воспринимать, всё ещё зависит от знания характеристик, которые позволяют описать неполадки.
Если говорить о плюсах, проявившихся после того, как мы увеличили значения MaxStartups и настроили скорость обработки запросов, то можно сказать, что уровень ошибок снизился до 0.001%. То есть — до нескольких тысяч в день. Такая ситуация выглядела гораздо лучше, но подобный уровень ошибок был всё ещё выше того, на который нам хотелось бы выйти. После того, как мы разобрались с некоторыми делами, мы снова смогли воспользоваться опцией leastconn и ошибки полностью исчезли. После этого мы смогли вздохнуть с облегчением.
Будущая работа
Очевидно то, что фаза SSH-аутентификации всё ещё занимает немало времени. Возможно — до 3.4 секунд. GitLab может использовать AuthorizedKeysCommand для прямого поиска SSH-ключа в базе данных. Это очень важно для быстрого выполнения операций, когда имеется большое число пользователей. В противном случае SSHD необходимо последовательно считывать очень большой файл authorized_keys для поиска публичного ключа пользователя. Эта задача хорошо не масштабируется. Мы реализовали поиск с использованием некоторого объёма кода на Ruby, который выполняет обращения к внешнему HTTP-API. Стэн Хью, руководитель нашей инженерно-технической службы и неиссякаемый источник знаний по GitLab, выяснил, что Unicorn-экземпляры Git/SSH-серверов находятся под постоянной нагрузкой от выполняемых к ним запросов. Это могло вносить значительный вклад в те три секунды, которые требовались на аутентификацию запросов. В результате мы поняли, что в будущем нам стоит исследовать этот вопрос. Возможно, мы увеличим число экземпляров Unicorn (или Puma) на этих узлах, сделав так, чтобы SSH-серверам не приходилось бы ждать, обращаясь к ним. Однако тут имеется определённый риск, поэтому нам нужно проявлять осторожность и внимательно относиться к сбору и анализу показателей системы. Работа над производительностью продолжается, но сейчас, после того, как основная проблема решена, дело идёт медленнее. Мы, возможно, сможем уменьшить значение MaxStartups, но так как его высокий уровень не создаёт того негативного влияния на систему, который он, как кажется, может создавать, в этом нет особой необходимости. Всем будет гораздо легче жить в том случае, если OpenSSH сможет в любое время сообщать нам о том, насколько близко мы подошли к лимитам MaxStartups. Лучше будет, если мы сможем всегда быть в курсе происходящего. Это куда приятнее, чем узнавать о том, что лимиты превышены, сталкиваясь с разорванными подключениями.
Кроме того, нам нужна некая система оповещения при появлении записей логов HAProxy, указывающих на возникновение проблемы разорванных соединений. Дело в том, что это, на практике, вообще не должно происходить. Если же это снова случится — нам понадобится и дальше увеличивать значения MaxStartups, или, если мы столкнёмся с нехваткой ресурсов, понадобится добавить в систему больше Git/SSH-узлов.
Итоги
Части сложных систем взаимодействуют по сложным схемам. И в них, для решения различных проблем, часто можно обнаружить далеко не один «рычаг». Имея дело с подобными системами, полезно знать о присутствующих в них инструментах. Дело в том, что все они имеют свои плюсы и минусы. Кроме того, надо отметить, что рискованным делом может быть выполнение неких настроек на основе предположений и оценочных значений. Сейчас, глядя на пройденный нами путь, я попытался бы как можно точнее измерить время, необходимое на выполнение аутентификации запроса, что привело бы к тому, что приблизительное значение T, которое я вывел, было бы ближе к истине.
Но главный урок, который мы извлекли из всего этого, заключается в том, что когда множество людей планируют задания, опираясь на некие красивые показатели времени, это, у централизованных провайдеров услуг наподобие GitLab, ведёт к появлению по-настоящему необычных проблем с масштабированием.
Если вы — один из тех, кто пользуется средствами запуска задач по расписанию, то вам, возможно, стоит подумать о том, чтобы настраивать время запуска ваших заданий по-новому. Например, можно сделать так, чтобы задания «засыпали» бы на некоторое время, начиная реально работать лишь через 30 секунд после запуска. Можно, например, указывать в расписании запуска задач случайные моменты времени в пределах часа (сюда можно добавить и случайное время ожидания перед реальным выполнением задачи). Это поможет нам всем в деле борьбы с тиранией часов.
Уважаемые читатели! Сталкивались ли вы с проблемами, похожими на ту, рассказу о решении которой посвящён этот материал?

