[Перевод] 6 уроков, извлечённых из поиска решения масштабной проблемы на gitlab.com. Часть 1
Материал, первую часть перевода которого мы публикуем сегодня, посвящён масштабной проблеме, которая возникла в gitlab.com. Здесь пойдёт речь о том, как её обнаружили, как с ней боролись, и как, наконец, её решили. Кроме того, столкнувшись с этой проблемой, команда gitlab.com узнала о том, что такое тирания часов.

Проблема
Мы начали получать от клиентов сообщения о том, что они, работая с gitlab.com, периодически сталкиваются с ошибками при выполнении pull-запросов. Ошибки обычно происходили при выполнении CI-задач или в ходе работы других похожих автоматизированных систем. Сообщения об ошибках выглядели примерно так:
ssh_exchange_identification: connection closed by remote host
fatal: Could not read from remote repository
Ситуацию ещё более усложняло то, что сообщения об ошибках появлялись нерегулярно и, как казалось, непредсказуемо. Мы не могли их воспроизвести по своему желанию, не могли выявить какой-то явный признак происходящего на графиках или в логах. Сами сообщения об ошибках тоже особой пользы не приносили. SSH-клиенту сообщалось о том, что соединение прервано, но причиной этого могло быть всё что угодно: сбойный клиент или неустойчиво работающая виртуальная машина, файрвол, который мы не контролируем, странные действия провайдера или проблема нашего приложения.
Мы, работая по схеме GIT-over-SSH, имеем дело с очень большим количеством подключений — порядка 26 миллионов в сутки. Это, в среднем, 300 соединений в секунду. Поэтому попытка отбора небольшого числа сбойных подключений из имеющегося потока данных обещала стать непростым делом. Хорошо в этой ситуации было лишь то, что нам нравится решать сложные задачи.
Первая подсказка
Мы связались с одним из наших клиентов (спасибо Хьюберту Хольцу из компании Atalanda), который сталкивался с проблемой по несколько раз в день. Это дало нам точку опоры. Хьюберт смог предоставить нам подходящий публичный IP-адрес. Это означало, что мы могли бы выполнить захват пакетов на наших фронтенд-узлах HAProxy для того, чтобы попытаться изолировать проблему, опираясь на набор данных, который меньше, чем нечто, что можно назвать «всем SSH-трафиком». Ещё лучше было, что компания использовала alternate-ssh-порт. Это означало, что нам нужно было проанализировать состояние дел лишь на двух HAProxy-серверах, а не на шестнадцати.
Анализ пакетов, правда, не оказался особенно увлекательным занятием. Несмотря на ограничения примерно за 6.5 часов было собрано около 500 Мб пакетов. Мы обнаружили короткоживущие соединения. TCP-соединение устанавливалось, клиент отправлял идентификатор, после чего наш HAProxy-сервер немедленно разрывал соединение с использованием правильной последовательности TCP FIN. В результате в нашем распоряжении оказалась первая отличная подсказка. Она позволила нам сделать вывод о том, что соединение, определённо, закрывалось по инициативе gitlab.com, а не из-за чего-то, находящегося между нами и клиентом. Это значило, что перед нами стояла проблема, которую мы можем исследовать и исправить.
Урок №1. В меню Statistics инструмента Wireshark есть масса полезных инструментов, на которые я, до этого случая, не обращал особого внимания.
В частности, речь идёт о пункте меню Conversations, который может продемонстрировать базовые сведения по захваченным данным о TCP-соединениях. Здесь есть сведения о времени, пакетах, байтах. Данные, выводимые в соответствующем окне, можно сортировать. Мне следовало бы использовать этот инструмент с самого начала вместо того, чтобы вручную возиться с захваченными данными. Тогда я понял, что мне надо было искать соединения с маленьким количеством пакетов. Окно Conversations позволило сразу же обратить на них внимание. После этого я смог найти и другие подобные соединения и убедиться в том, что первое такое соединение не представляло собой некое аномальное явление.
Погружение в логи
Что заставляло HAProxy разрывать соединение с клиентом? Сервер, определённо, делал это не произвольным образом, у происходящего должна была быть какая-то более глубокая причина; если угодно — «ещё один уровень черепах». Возникло такое ощущение, что следующим объектом исследования должны стать логи HAProxy. Наши логи хранились в GCP BigQuery. Это удобно, так как логов у нас много, и нам нужно было всесторонне их проанализировать. Но для начала нам удалось идентифицировать запись лога для одного из инцидентов, который нашёлся в захваченных пакетах. Мы опирались на время и на TCP-порт, это было крупным достижением в нашем исследовании. Самой интересной деталью в найденной записи оказался атрибут t_state (Termination State, состояние завершения), который имел значение SD. Вот извлечение из документации HAProxy:
S: отменено сервером, или сервер явно его отклонил.
D: сессия была в фазе DATA.
Смысл значения D объясняется очень просто. TCP соединение было правильно установлено, данные были отправлены. Это совпадало со свидетельствами, полученными из захваченных пакетов. Значение S означало, что HAProxy получил от бэкенда RST, или ICMP-сообщение об отказе. Но мы не могли сразу найти подсказку относительно того, почему это происходило. Причиной подобного могло быть всё что угодно — от нестабильной работы сети (например — сбой или перегрузка) до проблемы уровня приложения. Использовав BigQuery для агрегации данных по Git-бэкендам, мы выяснили, что проблема не привязана к какой-то конкретной виртуальной машине. Нам нужно было больше информации.
Хочу отметить, что записи логов со значением SD не были чем-то особенным, характерным лишь для нашей проблемы. На порт alternate-ssh мы получали множество запросов, касающихся сканирования на предмет HTTPS. Это вело к тому, что значение SD попадало в логи тогда, когда SSH-сервер видел сообщение TLS ClientHello в то время как он ожидал получить SSH-приветствие. Это ненадолго повело наше расследование кружным путём.
Захватив некоторый объём трафика между HAProxy и Git-сервером и снова воспользовавшись инструментами Wireshark, мы быстро выяснили то, что SSHD на Git-сервере разрывает соединение с TCP FIN-ACK сразу же после трёхстороннего рукопожатия TCP. HAProxy при этом всё ещё не отправлял первый пакет с данными, но собирался это сделать. Когда же он отправлял пакет, Git-сервер отвечал ему с TCP RST. В результате — теперь мы обнаружили причину того, почему HAProxy писал в логи сведения о сбое соединения со значением SD. SSH закрывал соединение, делая это намеренно и правильно, а RST было лишь артефактом того, что SSH-сервер получал пакет после FIN-ACK. Это не значило больше ничего.
Красноречивый график
Разглядывая и анализируя логи со значениями SD в BigQuery, мы поняли что ошибки имеют ярко выраженную привязку ко времени. А именно, мы обнаружили пики количества сбойных соединений, находящиеся в пределах первых 10 секунд каждой минуты. Они наблюдались в течение 5–6 секунд.
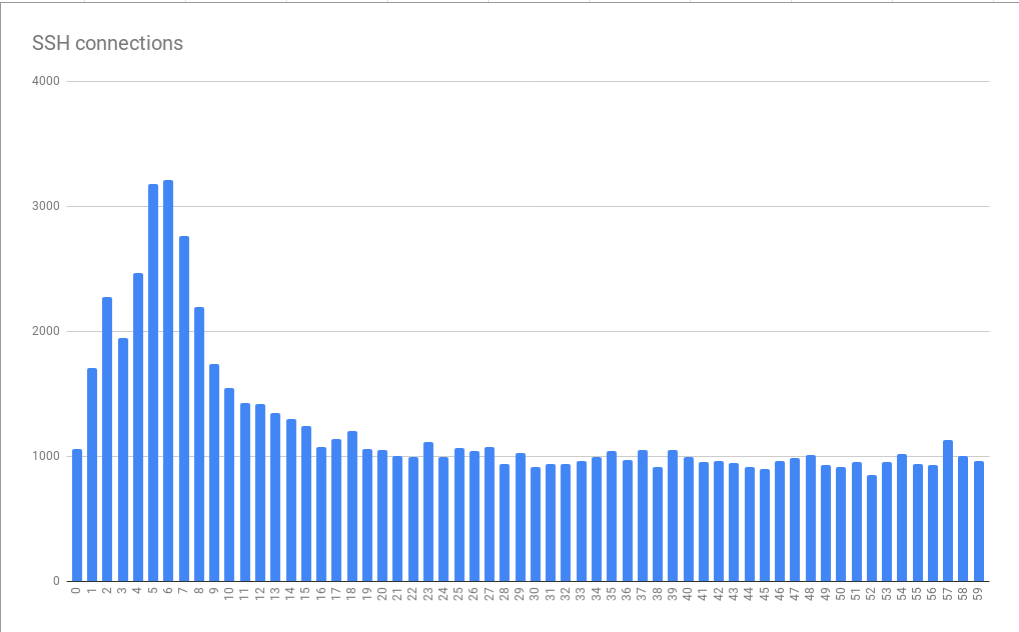
Ошибки соединений, сгруппированные в пределах минут по секундам
Этот график создан на основе данных, собранных за множество часов. То, что обнаруженный шаблон распределения ошибок оказался устойчивым, указывает на то, что причина ошибок стабильно проявляется в пределах отдельно взятых минут и часов, и, что, возможно, ещё хуже, она устойчиво проявляется в разное время дня. Весьма интересно и то, что средний размер пика оказывается примерно в 3 раза больше базовой нагрузки. Это означало, что перед нами стоит нетривиальная проблема масштабирования. В результате простое подключение «большего количества ресурсов» в виде дополнительных виртуальных машин, призванное помочь нам справиться с пиковыми нагрузками, теоретически могло оказаться неприемлемо дорогим. Это указывало ещё и на то, что мы достигаем некоего жёсткого ограничения. В результате мы получили первую подсказку о той фундаментальной системной проблеме, которая и вызывает ошибки. Я назвал это «тиранией часов».
Cron или похожие системы планирования часто не отличаются возможностями по настройке выполнения заданий с точностью до секунды. Если же подобные системы и обладают такими возможностями, они используются не особенно часто из-за того, что люди предпочитают рассматривать время, разбитое на промежутки, выраженные красивыми круглыми числами. В результате задания запускаются в начале минуты или часа, или в другие подобные моменты. Если заданиям нужна пара секунд на подготовку выполнения команды git fetch для загрузки материалов с gitlab.com, это могло бы объяснить найденный нами шаблон, когда нагрузка на систему резко возрастает в течение нескольких секунд каждой минуты. В такие моменты возрастает и количество ошибок.
Урок №2. У множества людей, по-видимому, используется правильно настроенная синхронизация времени (через NTP или с использованием других механизмов).
Если никто не синхронизировал бы время, то наша проблема не проявилась бы так чётко. Браво тебе, NTP!
Но что же приводит к тому, что SSH разрывает соединение?
Приближение к сути проблемы
Изучая документацию по SSHD, мы обнаружили параметр MaxStartups. Он контролирует максимальное количество неаутентифицированных подключений. Правдоподобным выглядит то, что лимит подключений оказывается исчерпанным тогда, когда в начале минуты система подвергается нагрузке, создаваемой шквалом вызовов запланированных заданий со всего интернета. Параметр MaxStartups состоит из трёх чисел. Первое — это нижняя граница (число соединений, при достижении которого начинаются разрывы соединений). Второе — это процентное значение соединений, превышающих нижнюю границу соединений, которые надо, в случайном порядке, разорвать. Третье значение — это абсолютный максимум количества соединений, после достижения которого отклоняются все новые соединения. Значение MaxStartups по умолчанию выглядит как 10:30:100, наши настройки тогда выглядели как 100:30:200. Это указывало на то, что в прошлом мы увеличили стандартные лимиты подключений. Возможно — пришло время снова их увеличить.
Немного неприятным оказалось то, что, так как на наших серверах был установлен пакет OpenSSH 7.2, единственным способом увидеть достижение лимитов, заданных в MaxStartups, было переключение на уровень отладки Debug. При таком подходе в логи попадает целая лавина данных. Поэтому мы ненадолго включили этот режим на одном из серверов. К нашему счастью уже через пару минут стало ясно, что количество соединений превысило пределы, заданные в MaxStartups, в результате чего и происходил ранний разрыв соединений.
Оказалось, что в OpenSSH 7.6 (эта версия поставляется с Ubuntu 18.04) организован более удобный подход к логированию того, что имеет отношение к MaxStartups. Здесь для этого нужно лишь переключиться в режим логирования Verbose. Хотя это и не идеально, но это всё же лучше, чем переход на уровень Debub.
Урок №3. Считается хорошим тоном писать в журналы интересную информацию на стандартных уровнях логирования, а сведения о намеренном разрыве соединения по любой причине, определённо, интересны системным администраторам.
Теперь, когда мы выяснили причину проблемы, перед нами встал вопрос о том, как её решить. Мы могли бы увеличить значения в параметре MaxStartups, но чего бы это нам стоило? Определённо, это потребовало бы немного дополнительной памяти, но приведёт ли это к каким-нибудь неблагоприятным последствиям в тех частях системы, где ведётся обработка запросов? Мы могли об этом только размышлять, поэтому мы решили взять и просто попробовать новые настройки MaxStartups. А именно мы поменяли их на такие: 150:30:300. Раньше они выглядели как 100:30:200, то есть — мы увеличили число соединений на 50%. Это оказало сильное положительное воздействие на систему. При этом неких негативных эффектов, вроде повышения нагрузки на процессоры, не наблюдалось.
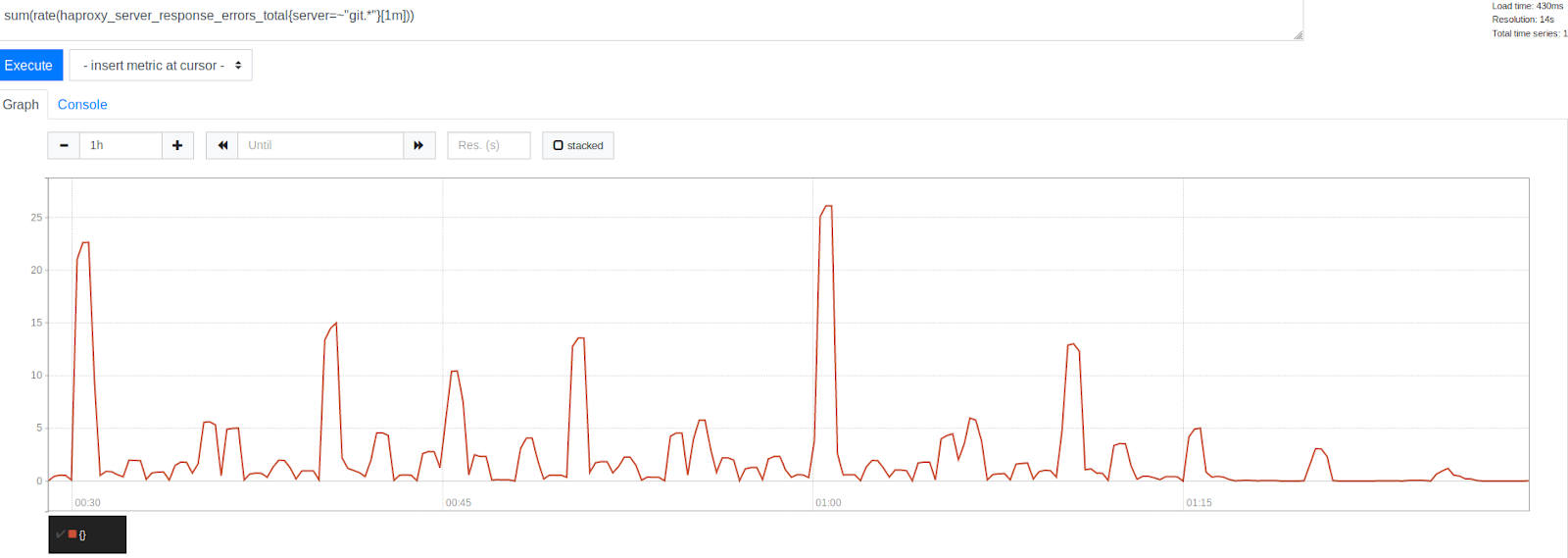
Количество ошибок до и после увеличения MaxStartups на 50%
Обратите внимание на значительное снижение количества ошибок после отметки времени 1:15. Это ясно указывает на то, что нам удалось избавиться от значительной части ошибок, хотя некоторое их количество всё ещё присутствовало. Интересно отметить то, что ошибки сгруппированы вокруг временных отметок, представленных красивыми круглыми числами. Это — начало часа, каждые 30, 15 и 10 минут. Несомненно то, что тирания часов продолжалась. В начале каждого часа наблюдается самый высокий пик ошибок. Это, учитывая то, что мы уже выяснили, выглядит вполне понятным. Многие люди просто планируют ежечасный запуск заданий, выполняющийся через 0 минут после начала часа. Этот факт подтвердил нашу теорию, касающуюся того, что пики ошибок вызывает запуск запланированных заданий. Это указывало на то, что мы находимся на правильном пути в деле решения проблемы путём настройки ограничений систем.
К нашему удовольствию, изменение лимита MaxStartups не привело к появлению заметных негативных эффектов. Использование процессора на SSH-серверах оставалось примерно на том же уровне, что и раньше, нагрузка на наши системы тоже не возросла. Это было очень приятно, учитывая то, что мы принимали теперь больше соединений, из тех, что раньше были бы просто разорваны. Кроме того, ситуацию не ухудшило и то, что мы делали это в моменты, когда наши системы были очень сильно нагружены. Всё это выглядело многообещающе.
Продолжение следует…
Уважаемые читатели! Какими инструментами вы пользуетесь для анализа трафика и логов?

