[Перевод] 5 современных альтернатив старым инструментам командной строки Linux
Используя более современные альтернативы наряду со старыми инструментами командной строки, можно получить больше удовольствия и даже повысить производительность труда.

В повседневной работе в Linux / Unix мы используем множество инструментов командной строки — например, du для мониторинга использования диска и системных ресурсов. Некоторые из этих инструментов существуют уже давно. Например, top появился в 1984 году, а первый релиз du датируется 1971 годом.
За прошедшие годы эти инструменты были модернизированы и портированы на разные системы, но в целом далеко не ушли от своих первых версий, их внешний вид и usability также сильно не изменились.
Это отличные инструменты, которые необходимы многим системным администраторам. Однако сообщество разработало альтернативные инструменты, которые предлагают дополнительные преимущества. Некоторые из них просто имеют современный красивый интерфейс, а другие значительно улучшают удобство использования. В этом переводе расскажем о пяти альтернативах стандартным инструментам командной строки Linux.
1. ncdu vs du
NCurses Disk Usage (ncdu) похож на du, но с интерактивным интерфейсом на основе библиотеки curses. ncdu отображает структуру каталогов, которые занимают большую часть вашего дискового пространства.
ncdu анализирует диск, а затем отображает результаты, отсортированные по наиболее часто используемым каталогам или файлам, например:
ncdu 1.14.2 ~ Use the arrow keys to navigate, press ? for help
--- /home/rgerardi ------------------------------------------------------------
96.7 GiB [##########] /libvirt
33.9 GiB [### ] /.crc
7.0 GiB [ ] /Projects
. 4.7 GiB [ ] /Downloads
. 3.9 GiB [ ] /.local
2.5 GiB [ ] /.minishift
2.4 GiB [ ] /.vagrant.d
. 1.9 GiB [ ] /.config
. 1.8 GiB [ ] /.cache
1.7 GiB [ ] /Videos
1.1 GiB [ ] /go
692.6 MiB [ ] /Documents
. 591.5 MiB [ ] /tmp
139.2 MiB [ ] /.var
104.4 MiB [ ] /.oh-my-zsh
82.0 MiB [ ] /scripts
55.8 MiB [ ] /.mozilla
54.6 MiB [ ] /.kube
41.8 MiB [ ] /.vim
31.5 MiB [ ] /.ansible
31.3 MiB [ ] /.gem
26.5 MiB [ ] /.VIM_UNDO_FILES
15.3 MiB [ ] /Personal
2.6 MiB [ ] .ansible_module_generated
1.4 MiB [ ] /backgrounds
944.0 KiB [ ] /Pictures
644.0 KiB [ ] .zsh_history
536.0 KiB [ ] /.ansible_async
Total disk usage: 159.4 GiB Apparent size: 280.8 GiB Items: 561540
По записям можно перемещаться с помощью клавиш со стрелками. Если вы нажмёте Enter, ncdu отобразит содержимое выбранного каталога:
--- /home/rgerardi/libvirt ----------------------------------------------------
/..
91.3 GiB [##########] /images
5.3 GiB [ ] /media
Вы можете использовать этот инструмент, чтобы, например, определить, какие файлы занимают больше всего дискового пространства. В предыдущий каталог можно перейти, нажав клавишу со стрелкой влево. С помощью ncdu вы можете удалить файлы, нажав клавишу d. Перед удалением он запрашивает подтверждение. Если вы хотите отключить функцию удаления, чтобы предотвратить случайную потерю ценных файлов, используйте опцию -r для включения режима доступа только для чтения: ncdu -r.
ncdu доступен для многих платформ и дистрибутивов Linux. Например, вы можете использовать dnf для его установки на Fedora непосредственно из официальных репозиториев:
$ sudo dnf install ncdu2. htop vs top
Htop — это интерактивная утилита для просмотра процессов, похожая на top, но из коробки обеспечивающая приятное взаимодействие с пользователем. По умолчанию htop отображает ту же информацию, что и top, но в более наглядном и красочном виде.
По умолчанию htop выглядит так:
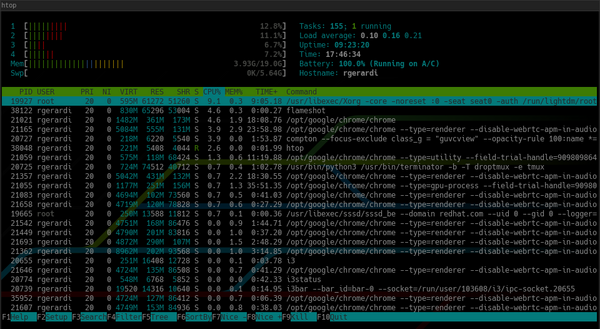
В отличие от top:
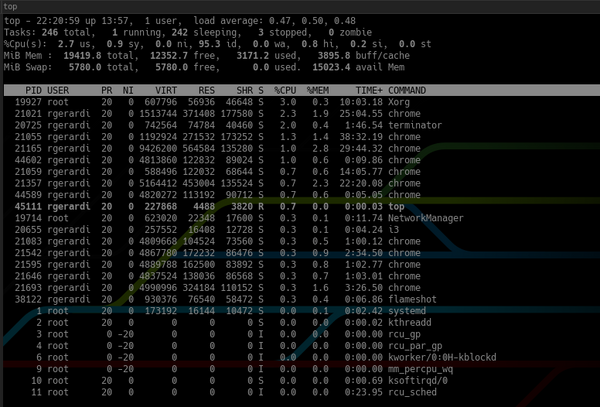
Кроме того, в верхней части htop отображает обзорную информацию о системе, а нижней части — панель для запуска команд с помощью функциональных клавиш. Вы можете настроить её, нажав F2, чтобы открыть экран настройки. В настройках можно изменить цвета, добавить или удалить метрики или изменить параметры отображения панели обзора.
Хотя, покрутив настройки последних версий top, тоже можно добиться похожего usability, htop предоставляет удобные конфигурации по умолчанию, что делает его более практичным и простым в использовании.
3. tldr vs man
Инструмент командной строки tldr отображает упрощённую справочную информацию о командах, в основном примеры. Его разработало сообщество tldr pages project.
Стоит отметить, что tldr — это не замена man. Он по-прежнему является каноническим и наиболее полным инструментом вывода справочных страниц. Однако в некоторых случаях man является избыточным. Когда вам не нужна исчерпывающая информация о какой-либо команде, вы просто пытаетесь запомнить основные варианты её использования. Например, страница man для команды curl содержит почти 3000 строк. Страница tldr для curl имеет длину 40 строк. Её фрагмент выглядит так:
$ tldr curl
# curl
Transfers data from or to a server.
Supports most protocols, including HTTP, FTP, and POP3.
More information: .
- Download the contents of an URL to a file:
curl http://example.com -o filename
- Download a file, saving the output under the filename indicated by the URL:
curl -O http://example.com/filename
- Download a file, following [L]ocation redirects, and automatically [C]ontinuing (resuming) a previous file transfer:
curl -O -L -C - http://example.com/filename
- Send form-encoded data (POST request of type `application/x-www-form-urlencoded`):
curl -d 'name=bob' http://example.com/form
- Send a request with an extra header, using a custom HTTP method:
curl -H 'X-My-Header: 123' -X PUT http://example.com
- Send data in JSON format, specifying the appropriate content-type header:
curl -d '{"name":"bob"}' -H 'Content-Type: application/json' http://example.com/users/1234
... TRUNCATED OUTPUT
TLDR означает «слишком длинно; не читал»: то есть, некоторый текст был проигнорирован из-за его чрезмерной многословности. Название подходит для этого инструмента, потому что man-страницы, хотя и полезны, но иногда бывают слишком длинными.
Для Fedora tldr был написан на Python. Вы можете установить его с помощью менеджера dnf. Обычно для работы инструмента необходим доступ к интернету. Но клиент Python в Fedora позволяет загружать и кэшировать эти страницы для автономного доступа.
4. jq vs sed/grep
jq — это JSON-процессор для командной строки. Он похож на sed или grep, но специально разработан для работы с данными в формате JSON. Если вы разработчик или системный администратор, который использует JSON в повседневных задачах, этот инструмент для вас.
Основное преимущество jq перед стандартными инструментами обработки текста, такими как grep и sed, заключается в том, что он понимает структуру данных JSON, позволяя создавать сложные запросы в одном выражении.
Например, вы пытаетесь найти названия контейнеров в этом файле JSON:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"labels": {
"app": "myapp"
},
"name": "myapp",
"namespace": "project1"
},
"spec": {
"containers": [
{
"command": [
"sleep",
"3000"
],
"image": "busybox",
"imagePullPolicy": "IfNotPresent",
"name": "busybox"
},
{
"name": "nginx",
"image": "nginx",
"resources": {},
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "Never"
}
}
Запустите grep для поиска строки name:
$ grep name k8s-pod.json
"name": "myapp",
"namespace": "project1"
"name": "busybox"
"name": "nginx",
grep вернул все строки, содержащие слово name. Вы можете добавить ещё несколько параметров в grep, чтобы ограничить его, и с помощью некоторых манипуляций с регулярными выражениями найти имена контейнеров.
Чтобы получить этот же результат с помощью jq, достаточно написать:
$ jq '.spec.containers[].name' k8s-pod.json
"busybox"
"nginx"
Эта команда выдаст вам имена обоих контейнеров. Если вы ищете только имя второго контейнера, добавьте индекс элемента массива в выражение:
$ jq '.spec.containers[1].name' k8s-pod.json
"nginx"
Поскольку jq знает о структуре данных, он даёт те же результаты, даже если формат файла незначительно изменится. grep и sed в этом случае могут работать некорректно.
У jq много функций, но для их описания нужна ещё одна статья. Для получения дополнительной информации обратитесь к странице проекта jq или к tldr.
5. fd vs find
fd — это упрощённая альтернатива утилите find. Fd не призван заменить её полностью: в нём по умолчанию установлены наиболее распространённые настройки, определяющие общий подход к работе с файлами.
Например, при поиске файлов в каталоге репозитория Git, fd автоматически исключает скрытые файлы и подкаталоги, включая каталог .git, а также игнорирует шаблоны из файла .gitignore. В целом, он ускоряет поиск, выдавая более релевантные результаты с первой попытки.
По умолчанию fd выполняет поиск без учёта регистра в текущем каталоге с цветным выводом. Тот же поиск с использованием команды find требует ввода дополнительных параметров в командной строке. Например, чтобы найти все файлы .md (или .MD) в текущем каталоге, нужно написать такую команду find:
$ find . -iname "*.md"
Для fd она выглядит так:
$ fd .md
Но в некоторых случаях и для fd требуются дополнительные параметры: например, если вы хотите включить скрытые файлы и каталоги, вы должны использовать опцию -H, хотя обычно при поиске это не требуется.
fd доступен для многих дистрибутивов Linux. В Fedora его можно установить так:
$ sudo dnf install fd-findНеобязательно от чего-то отказываться
Используете ли вы новые инструменты командной строки Linux? Или сидите исключительно на старых? Но скорее всего, у вас комбо, да? Пожалуйста, поделитесь вашим опытом в комментариях.
На правах рекламы
Многие наши клиенты уже оценили преимущества эпичных серверов!
Это виртуальные серверы с процессорами AMD EPYC, частота ядра CPU до 3.4 GHz. Максимальная конфигурация позволит оторваться на полную — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe. Спешите заказать!

