[Перевод] [В закладки] Как работает браузер

К старту курса по Fullstack-разработке на Python делимся лонгридом от ведущего программиста компании THG. Специалистам материал будет полезен в подготовке к собеседованиям, а новичкам поможет получить целостное представление о том, что происходит у браузера под капотом.
Расскажем, что происходит на отрезке «пользователь ввёл веб-адрес в браузере — веб-страница отобразилась на экране».
Введение
В момент, когда пользователь запрашивает веб-страницу, и до того, как она отобразится в браузере, происходит множество процессов. Для большей наглядности все эти процессы поделены на следующие разделы:
Навигация по сети
преобразование веб-адреса (DNS-поиск);
установка соединения с сервером (тройное TCP-рукопожатие);
установка протокола безопасности (согласование TLS).
Получение страницы
HTTP-запрос;
HTTP-ответ.
Разбор
построение DOM-дерева;
построение CSSOM-дерева;
объединение деревьев в дерево рендеринга;
сканер предварительной загрузки;
компиляция JavaScript;
создание дерева доступности.
Отображение
Завершение
Для перехода к интересующему вас этапу нажмите на название главы. Если вы не знакомы с какими-то концепциями, то я рекомендую читать статью по порядку. Начнём знакомство с ряда фоновых процессов!
Фоновые процессы
В данной главе приводится краткий и общий обзор основных фоновых процессов, необходимых нам для понимания дальнейшего материала.
Сетевые модели
Модели объясняют, как данные передаются по сети. Одна из таких сетевых моделей знакома даже тем, кто далёк от хакерства! Мы называем её моделью взаимодействия открытых систем, или моделью OSI.

Модель OSI
Модель взаимодействия открытых систем описывает 7 уровней, или слоёв, которыми компьютерные системы пользуются для обмена данными по сети. Каждый последующий слой на уровень абстракции выше предыдущего. Так продолжается вплоть до прикладного (браузерного) уровня, о котором мы и будем говорить.
Важно понять, что модель OSI — это «концептуальная модель» того, как именно приложения взаимодействуют внутри сети. Это не протокол. Не путайте два этих понятия. Протоколами называются строгие наборы правил, которые могут находиться внутри данных уровней.
Более старой и очень похожей моделью — возможно, даже лучше подходящей к тематике статьи — является модель TCP/IP. Эта сетевая модель моделирует текущую архитектуру интернета и предоставляет набор правил (конкретных протоколов), которым следуют все виды передачи данных по сети.

OSI или TCP/IP
Я буду ссылаться на модель TCP/IP и связанные с ней протоколы.
Любые данные, отправляемые из одного приложения в другое, проходят вверх и вниз по уровням модели. Этот процесс повторяется многократно (в зависимости от количества посредников). Конечно же, в наши дни всё выполняется предельно быстро, но, раз такие процессы в принципе существуют, значит, каждый разработчик должен о них знать. Ниже показано сетевое взаимодействие между сервером и клиентским приложением:
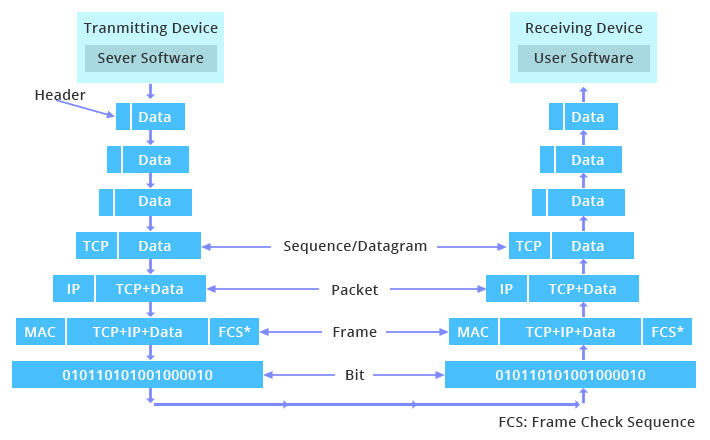
Передача данных между приложениями в модели TCP/IP
Рассмотрим пример. Пользователь запрашивает открытие страницы в браузере:
Сначала запрос отправляется на прикладной уровень и обрабатывается поэтапно на каждом уровне модели.
Затем данные передаются через физический уровень сети до тех пор, пока не дойдут до нужного сервера или другого устройства.
Данные вновь проходят по уровням модели. Каждый уровень выполняет свои функции до тех пор, пока данные не заберёт серверное приложение.
Процесс повторяется для получения ответа от сервера.
Это схематическое представление взаимодействия машин внутри сети.
Абстракция высокого уровня в браузере
В следующих главах рассказывается о том, как обычный браузер отображает содержимое страницы. Я буду ссылаться на следующие компоненты браузера:
Пользовательский интерфейс. Адресная строка, кнопки вперёд/назад, меню «Закладки» и т. д. Отображаются все части браузера, кроме окна, в котором вы видите запрошенную страницу.
Движок браузера. Распределяет действия между пользовательским интерфейсом и механизмом визуализации.
Механизм визуализации. Отвечает за отображение запрошенного содержимого. Например, если запрошенное содержимое — это HTML, то механизм визуализации разбирает HTML и CSS и отображает проанализированные данные на экране.
Сеть. Для сетевых вызовов (например, HTTP-запросов), которые используют различные реализации всевозможных платформ в платформо-независимом интерфейсе.
Серверная часть интерфейса. Используется для отрисовки основных графических элементов (комбинированных списков и окон). Эта серверная часть представлена в общем и платформо-независимом интерфейсах.
Интерпретатор JavaScript. Используется для разбора и выполнения кода JavaScript.
Хранилище данных. Это уровень хранения данных. Бывает, что браузеру нужно сохранить какие-то данные локально (например, файлы cookies). Кроме того, браузеры поддерживают такие механизмы хранения, как localStorage, IndexedDB, WebSQL и FileSystem.

Компоненты браузера
Важно отметить, что в Chrome и схожих браузерах используется многозадачный подход к производительности и безопасности. Это означает, что для каждой вкладки (каждая вкладка = отдельный процесс) браузер запускает экземпляры каких-то компонентов (например, механизма визуализации). Вы можете сами в этом убедиться, если просмотрите процессы Chrome в диспетчере задач.

Скриншот диспетчера задач Chrome
Как вы уже заметили, у каждой вкладки есть свой приоритет процесса и статистические данные по использованию ЦП/памяти/сети. Всё это указывает на то, что они работают как обычные процессы. Так и есть! Если открыть процессы операционной системы, вы увидите их в общем списке.
В заключение вводной главы стоит отметить, что все написанное —обобщённые, абстрактные сведения о принципах работы сетей и браузеров. Не все сети строго придерживаются моделей OSI/TCP IP. Все современные браузеры в чём-то различаются, но основаны на общих принципах.
Например, все браузеры в той или иной степени придерживаются спецификаций от организации W3C — Консорциума Всемирной паутины, который считается законодателем веб-стандартов. Но механизмы визуализации в браузерах различаются: Internet Explorer пользуется Trident, Firefox — Gecko, Safari — WebKit, а Chrome, Edge и Opera используют Blink — ответвление WebKit.
Путешествие страницы
Вы открываете браузер и печатаете www.google.com. Затем происходит следующее:
Навигация
Первый шаг — попасть в нужное место. Перейти на веб-страницу означает найти, где находятся файлы этой страницы. Для нас веб-страницы сводятся к доменным именам, а компьютеры распознают их по IP-адресам.

IP
При открытии www.google.com все ресурсы этой страницы будут размещаться на сервере со всевозможными разновидностями IP-адреса 93.184.216.34. Если вы посещаете данный сайт впервые, то обязательно выполняется поиск по системе доменных имён — DNS.
Время приёма-передачи
Время приёма-передачи (RTT) — это отрезок времени, за который браузер отправляет запрос и получает ответ от сервера. Время приёма-передачи измеряется в миллисекундах. Это основной показатель производительности веб-приложений и один из главных факторов при измерении времени загрузки страницы и загрузки сети; к таким факторам также относится время до первого бита, или TTFB.
Рядом с каждым сетевым процессом я буду добавлять его RTT.
Преобразование веб-адреса — DNS-процесс (O RTT)
Говоря коротко, DNS-процесс для www.google.com сводится к следующему:
Проверить кеш браузера и операционной системы; вернуть IP-адрес, если он найден.
Браузер отправляет запрос DNS-преобразователю.
DNS-преобразователь проверяет свой кеш и возвращает IP, если он найден.
DNS-преобразователь отправляет запрос корневому DNS-серверу.
Корневой DNS-сервер отправляет ответ DNS-преобразователю с IP-адресом TLD-сервера (домена верхнего уровня; в данном случае это TLD для расширений .com).
DNS-преобразователь отправляет ещё один запрос, теперь уже запрос IP к TLD-серверу.
TLD-сервер отвечает DNS-преобразователю IP-адресом полномочного DNS-сервера.
DNS-преобразователь отправляет конечный запрос полномочному DNS-серверу, запрашивая IP.
Полномочный DNS-сервер сканирует файлы зон для поиска совпадения доменного имени и IP-адреса, а затем возвращает ответ DNS-преобразователю с информацией о том, существует ли такое совпадение.
И, наконец, DNS-преобразователь отвечает браузеру IP-адресом сервера, с которым пытается связаться браузер.

Визуализация процесса DNS
Стоит отметить, что, как правило, этот процесс происходит молниеносно и редко проходит от начала до конца. Это возможно благодаря уровню кеширования. Так и было задумано.
Установка соединения с сервером —TCP-рукопожатие (1 RTT)
Выяснив IP-адрес, браузер настраивает соединение с сервером через тройное TCP-рукопожатие.
Для установки надёжного соединения TCP использует тройное рукопожатие. Это дуплексное соединение: обе стороны синхронизируют (SYN) и подтверждают (ACK) друг друга. Обмен четырьмя флагами выполняется в три этапа: SYN, SYN-ACK и ACK (см. ниже).

Тройное рукопожатие TCP
Клиент выбирает начальный номер последовательности, указанный в первом SYN-пакете.
Сервер выбирает свой начальный номер последовательности.
Каждая сторона подтверждает номер последовательности друг друга, увеличивая его; это номер подтверждения.
Как только соединение установлено, для каждого сегмента выполняется ACK. В дальнейшем соединение разрывается с помощью RST — сброса или разрыва соединения, или FIN — корректного завершения соединения.
Данный механизм разработан так, чтобы два объекта (в этом случае — браузер и веб-сервер) могли согласовать параметры сетевого подключения TCP-сокета до передачи данных. В нашем случае это HTTPS — защищённая версия HTTP.
HTTPS — это HTTP с шифрованием. Единственное различие между двумя протоколами заключается в том, что для шифрования обычных HTTP-запросов и ответов HTTPS использует TLS (SSL). HTTPS надстраивает прочный слой безопасности поверх HTTP. URL сайта, использующего HTTP, начинается с HTTP://, а для HTTPS адрес меняется на HTTPS://.
Установка протокола безопасности — согласование TLS (~2 RTT)
Для безопасных соединений через HTTPS необходимо ещё одно «рукопожатие». В этом рукопожатии, или, скорее, согласовании TLS, определяется, какой шифр используется для шифрования связи, верифицируется сервер и до передачи данных проверяется наличие безопасного соединения.

Современная установка соединения TLS
Создание безопасного соединения увеличивает время загрузки страницы, но это оправданная жертва, поскольку данные, передаваемые между браузером и веб-сервером, не смогут расшифровать со стороны. TLS долго развивался, а в версии 1.3 и выше сократилось время приёма-передачи с 4 до 2 (или даже 1), в зависимости от ситуации.
Предположим, что DNS сработал мгновенно и добавил в HTTP RTT. Тогда до перехода браузера к отображению страницы пройдёт 4 приёма-передачи. Если открывать сайт, который вы недавно посещали, то за счёт возобновления TLS-сеанса стадия с TLS-рукопожатием может сократиться с 2 приёмов-передач до 1.
Получение
Теперь, когда вы настроили TCP-соединение и произошёл обмен TLS, браузер получает доступ к ресурсам страницы. Процесс начинается с доступа к разметке страницы по протоколу HTTP. HTTP-запросы отправляются через TCP/IP. В нашем случае Google использует HTTPS, поэтому то запросы зашифровываются с помощью протокола защиты транспортного уровня — TLS.
HTTP-запрос
Для получения веб-страницы делается идемпотентный, то есть не изменяющий состояние сервера запрос. Отправим HTTP-запрос GET.
Существует множество других HTTP-методов:
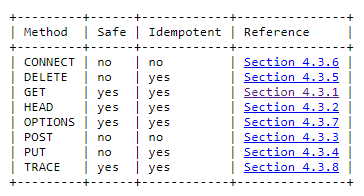
HTTP-методы по спецификации
Чтобы получить страницу, нужен только GET.
GET / HTTP/2
Host: www.google.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-GB,en;q=0.5
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
TE: TrailersHTTP-ответ
После получения запроса веб-сервер начинает его синтаксический разбор (парсинг) и пытается выполнить его. Предположим, запрос оказался правильным, а файлы — доступными. Сервер отправит HTTP-ответ, добавив в тело (body) ответа подходящие заголовки и содержимое запрошенного HTML-документа.
HTTP/2 200 OK
date: Sun, 18 Jul 2021 00:26:11 GMT
expires: -1
cache-control: private, max-age=0
content-type: text/html; charset=UTF-8
strict-transport-security: max-age=31536000
content-encoding: br
server: gws
content-length: 37418
x-xss-protection: 0
x-frame-options: SAMEORIGIN
domain=www.google.com
priority=high
X-Firefox-Spdy: h2Исходный код HTML-документа размещается в body ответа.
Разбор/парсинг
Получив ответ, браузер переходит к синтаксическому разбору полученной информации. На этапе разбора браузер преобразует данные, полученные по сети, в DOM или CSSOM — они используются визуализатором для отрисовки страницы на экране.
Объектная модель документа (DOM) — это внутреннее представление объектов, которое включает в себя структуру и содержимое разметки полученного браузером документа, в данном случае — HTML. DOM переводит страницу в схему, чтобы программы могли изменять структуру документа, стили и содержимое.
Документ в DOM представляется в виде узлов и объектов, благодаря чему к странице могут подключаться языки программирования. Интерфейс узла (Node) в DOM выглядит так:
Это все возможные узлы в документе. Такое представление позволяет подключать к странице языки программирования и изменять её.
В завершение разговора о парсинге стоит упомянуть CSSOM.
Объектная модель таблицы стилей (CSSOM) — это набор API, позволяющий работать с CSS из JavaScript. Данная модель очень похожа на DOM, но придумана для CSS, а не HTML. Она помогает пользователям динамически читать и изменять CSS-стили. Её представление во многом схоже с DOM (древовидное), да и сама модель может использоваться с DOM при создании дерева рендеринга, которое необходимо браузеру для запуска отрисовки. Давайте узнаем, как это происходит.
Создание DOM-дерева
Первый шаг — обработка HTML-разметки и создание DOM-дерева. Разбор HTML включает в себя токенизацию и построение дерева.
Должно быть, в мире парсинга HTML стал настоящим сюрпризом: его нельзя разобрать стандартными средствами, поскольку он не определяется контекстно свободной грамматикой. Зато есть официальный формат для определения HTML — определение типа документа (DTD). Не буду вдаваться в детали того, как это делается, но вот основные пункты:
неприхотливость языка;
у браузеров есть общепринятая отказоустойчивость для поддержки распространённых вариантов некорректного HTML;
разбор может повторяться. При парсинге для других языков исходник не меняется, но динамический код HTML (элементы скриптов с вызовами document.write ()) может добавлять дополнительные токены. Фактически такой разбор изменяет значения на входе.
Поскольку нельзя использовать типовые методы разбора, для HTML браузеры создают специализированные парсеры.
Алгоритм парсинга подробно описан в спецификации HTML5. Это
Токенизация. Это лексический анализ, который разбирает входные значения на токены. Токенами HTML считаются открывающие и закрывающие теги, а также названия и значения атрибутов.
Построение дерева. По сути, это создание дерева из проанализированных токенов. Мы будем разбирать DOM-дерево.
DOM-дерево описывает содержимое документа. Первый тег и корневой узел в древовидной схеме представления документа — это элемент . Само дерево показывает взаимосвязи и иерархии различных тегов. Теги, вложенные в другие теги, называются дочерними узлами. Чем больше в DOM узлов, тем дольше строится DOM-дерево. Ниже показано визуальное представление DOM-дерева — результат синтаксического разбора:

Часть DOM-дерева
Если парсер находит неблокируемые ресурсы (например, изображение), то браузер запрашивает их и продолжает разбор. При обнаружении файла CSS процесс парсинга продолжается, но теги

В приведённом выше примере сканер предварительной загрузки ищет скрипты и изображения и пытается их скачать. Взаимодействовать со сканером предварительной загрузки можно через HTML с помощью атрибутов async и defer.
async, если он есть, указывает, что скрипт выполняется асинхронно, как только станет доступным.
Атрибут defer указывает на выполнение после завершения разбора страницы.
Ожидание получения CSS не блокирует разбор или скачивание HTML, но блокирует JavaScript: последний часто используется для запроса влияния свойств CSS на элементы.
Компиляция JavaScript
Параллельно с разбором CSS и созданием CSSOM сканер скачивает другие ресурсы, включая файлы JavaScript. JavaScript интерпретируется, компилируется, разбирается и выполняется.

Обзор компиляции JS
Скрипты разбираются в AST — абстрактные синтаксические деревья. Некоторые движки браузера (см. диаграмму выше из блога о движке V8) берут абстрактное синтаксическое дерево и передают его преобразователю, выводя байт-код, который выполняется на основном потоке. Этот процесс называется компиляцией JavaScript.
Построение дерева доступности
Помимо прочего, браузер создаёт дерево доступности содержимого. Это дерево для разбора и интерпретации содержимого используют вспомогательные средства [например, скрин-ридеры для незрячих людей — прим. ред.]. Объектная модель доступности (AOM) похожа на семантическую версию DOM. При обновлении DOM браузер обновляет и дерево доступности. Вспомогательные технологии сами по себе не могут изменять дерево доступности.
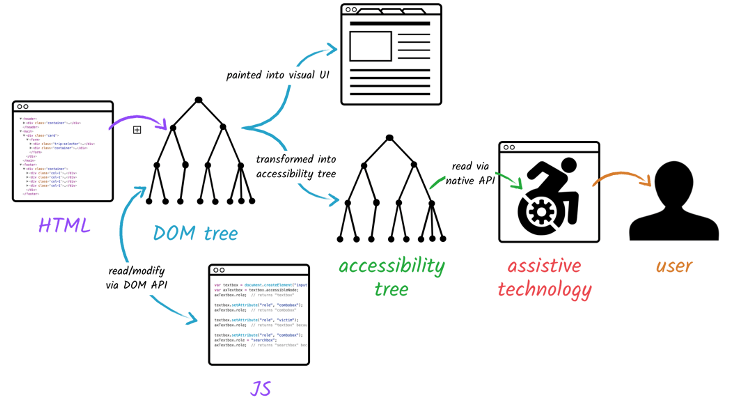
Создание и использование процесса AOM
До создания AOM содержимое недоступно скрин-ридерам.
Отображение
После разбора информации браузер может приступить к её отображению. Для этих целей используется дерево рендеринга. Отображение складывается из компоновки, отрисовки и, в некоторых случаях, наложения.
Критический путь рендеринга
А сейчас самое время поговорить о критическом пути рендеринга:

Критический путь рендеринга
Оптимизация критического пути рендеринга сокращает время до первой отрисовки. Важно проследить, чтобы перерасчёт положения и перерисовка могли выполняться со скоростью 60 кадров в секунду.
Мы не будем вдаваться в детали оптимизации критического пути рендеринга. Суть в том, чтобы ускорить загрузку страницы: настроить приоритеты загрузки ресурсов, следить за очерёдностью их загрузки и уменьшить размер самих файлов.
Компоновка
Компоновка — первый этап отображения: после построения дерева рендеринга определяются геометрия и положение узлов в дереве рендеринга.
Это рекурсивный процесс. Он начинается с корневого модуля визуализации: в HTML-документе ему соответствует элемент . Компоновка рекурсивно проходит по определённым или всем элементам иерархии фреймов, вычисляя геометрическую информацию каждого модуля визуализации.

Этапы компоновки
После компоновки создаётся дерево, похожее на те, о которых говорилось ранее. Но в качестве узлов в них используются так называемые блоки/поля, которые содержат геометрические параметры объектов и узлов DOM.
Система «грязный бит»
Чтобы не приходилось заново компоновать весь макет при любых незначительных изменениях, браузеры используют систему «грязного бита». Изменённый или добавленный модуль визуализации отмечает себя и своих потомков «грязными», то есть требующими перекомпоновки элементами.
Доступно 2 «грязных» флага:
dirty: узлу требуется компоновка;
children are dirty: в узле есть как минимум один дочерний элемент, которому требуется компоновка.
Алгоритм компоновки
Система «грязный бит» помогает браузерам при создании макета следовать определённому алгоритму. Вот этот алгоритм на высоком уровне абстракции:
Родительский узел определяет свою ширину.
Родительский узел проверяет дочерние элементы и:
а) вычисляет размер [для] отображения потомка;
б) вызывает компоновку дочернего элемента, если у него есть «грязный» потомок.
Родитель использует совокупную высоту дочерних узлов, а также высоту полей и отступов для настройки своей высоты, которая будет использоваться предком родительского модуля визуализации.
Устанавливает свой «грязный бит» в значение 0.
Ещё одно важное понятие — перерасчёт. Как уже отмечалось, определение первоначального размера и положения узлов называется компоновкой. Дальнейшее вычисление размера узлов и их положений называется перерасчётом. Представим, что первоначальная компоновка выполняется до того, как вернулось изображение. Мы не задавали размер изображения, поэтому, как только узнаем его, нужно будет пересчитать его размер!
Отрисовка
Это третий и последний этап рендеринга. На стадии отрисовки браузер преобразует каждое вычисленное на этапе компоновки поле в пиксели на экране. Отрисовка включает в себя прорисовку всех визуальных частей элемента, включая текст, цвета, границы, тени и заменённые элементы — кнопки и изображения. Причём браузер должен делать это очень быстро.
Порядок отрисовки
CSS2 определяет порядок отрисовки — очерёдность добавления элементов в контексты наложения. Этот порядок влияет на отрисовку потому, что блоки отрисовываются от фоновых элементов к лицевым:
Цвет фона.
Изображение фона.
Граница.
Дочерний элемент.
Контур.
Слои отрисовки
Отрисовка может разбивать элементы из дерева макета на слои. Распределение содержимого на слои в графическом процессоре (а не в основном потоке на ЦП) повышает производительность отрисовки и перерисовки. Отдельные элементы и свойства создают экземпляры слоя, включая
Слои улучшают производительность, но потребляют много памяти, поэтому не стоит злоупотреблять ими в стратегиях оптимизации веб-производительности.
Наложение
Если части документа отрисованы на разных слоях и перекрывают друг друга, то им требуется наложение. Наложение используется для правильного размещения слоёв на экране и корректного отображения содержимого.
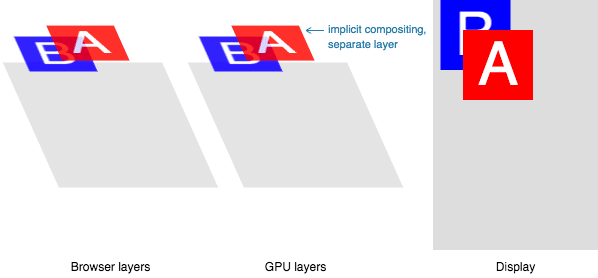
Стадии наложения
Пока страница загружает ресурсы, её размер может перерасчитываться: вспомните пример с изображением, которое подгрузилось позже. Перерасчёт вызывает повторную отрисовку и наложение. Задай мы точный размер изображения — и не пришлось бы выполнять перерасчёт. Повторная перерисовка и наложение выполняются только для затронутого слоя. Но мы не прописали размер изображения! После его загрузки с сервера процесс отображения откатывается на этап отрисовки и повторяется.
Завершение
Когда основной поток завершил отрисовку страницы, вы, должно быть, подумали, что теперь уже всё. Но так бывает не всегда. Если загрузка содержит JavaScript (отложенный и выполняемый только после срабатывания события onload), то основной поток может оказаться заполненным и недоступным для прокрутки, касания и прочих взаимодействий.
Заполнение JavaScript
Время загрузки до взаимодействия (TTI) — это временной интервал от первого запроса, за которым последовали DNS-поиск и установка SSL-соединения, до момента, когда страница стала интерактивной. Интерактивной она считается после первого отображения содержимого, когда страница реагирует на взаимодействие пользователя в рамках 50 мс. Если основной поток занят разбором, компиляцией или выполнением JavaScript, а потому недоступен, он не сможет реагировать на взаимодействия пользователя меньше чем за 50 мс.
В нашем примере изображение загрузилось быстро, но файл скрипта JS весил 2 МВ, а скорость сетевого подключения у пользователя оказалась неважной. Поэтому пользователь быстро увидел страницу, но не смог прокручивать её, пока не скачаются, разберутся и выполнятся скрипты страницы. У пользователя остались не лучшие впечатления. Ситуаций заполнения основного потока (как это видно в примере с WebPageTest) следует избегать:

Пример: JavaScript перегружает основной поток
Здесь загрузка содержимого DOM занимает 1,5 с. Всё это время основной поток полностью занят и не реагирует на события кликов или касания экрана.
Теперь пользователь может посетить страницу!
Да, теперь, после всего перечисленного пользователь может не только открывать страницу, но и взаимодействовать с ней!
Итоги
Чтобы простая страница отобразилась в окне нашего браузера, она проходит непростой путь:
DNS-поиск — поиск IP веб-адреса.
TCP-рукопожатие — настройка TCP/IP взаимодействия между клиентом и сервером для дальнейших этапов.
TLS-рукопожатие — защита информации шифрованием.
HTTP-коммуникация — определение понятного браузеру метода коммуникации.
Синтаксический разбор в браузере — разбор ответа HTTP, то есть документа отображаемой страницы.
Отображение в браузере — отрисовка документа в окне браузера.
Заполнение Javascript — ожидание компиляции и выполнения JS, чтобы он не тормозил основной поток.
Просто удивительно, сколько всего происходит при выполнении такой, казалось бы, простой задачи. Приключение небольшой страницы впечатляют!
Это ещё не всё…
На самом деле прежде чем наша небольшая страничка достигнет своего пункта назначения, ей придётся преодолеть ещё больше трудностей, а именно балансировщики нагрузок, прокси, многоуровневые брандмауэры и т. д.
Эти темы сами по себе многогранны, так что, если вам интересно, как всё работает, я рекомендую почитать про них самостоятельно! Возможно, напишу о них позже.
А мы поможем вам прокачать ваши навыки или с самого начала освоить профессию, актуальную в любое время:
Выбрать другую востребованную профессию.

