[Из песочницы] Зачем нужен алгоритм Хо-Кашьяпа?
Несмотря на бум нейросетей в машинном обучении, алгоритмы линейной классификации остаются гораздо более простыми в использовании и интерпретации. Но при этом иногда вовсе не хочется пользоваться сколько-нибудь продвинутыми методами, вроде метода опорных векторов или логистической регрессии и возникает искушение загнать все данные в одну большую линейную МНК-регрессию, тем более её прекрасно умеет строить даже MS Excel.
Проблема такого подхода в том, что даже если входные данные линейно разделимы, то получившийся классификатор может их не разделять. Например, для набора точек ,
получим разделяющую прямую
(пример позаимствован из (1)):
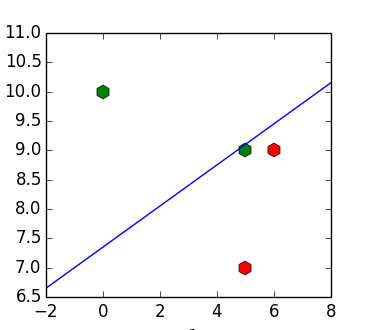
Встаёт вопрос — можно ли как-то избавиться от этой особенности поведения?
Задача линейной классификации
Для начала формализуем предмет статьи.
Дана матрица , каждая строчка
которой соответствует признаковому описанию объекта
(включая константу
) и вектора меток классов
, где
— метка объекта
. Мы хотим построить линейный классификатор вида
.
>>> import numpy as np
>>> X = np.array([[6, 9, 1], [5, 7, 1], [5, 9, 1], [0, 10, 1]])
>>> y = np.array([[1], [1], [-1], [-1]])
Самый простой способ это сделать — построить МНК-регрессию для
>>> w = np.dot(np.linalg.pinv(X), y)
>>> w
array([[ 0.15328467],
[-0.4379562 ],
[ 3.2189781 ]])
>>> np.dot(X, w)
array([[ 0.19708029],
[ 0.91970803],
[ 0.04379562],
[-1.16058394]])
Линейная разделимость
Для удобства записи мы поэлементно домножим каждую строчку неравенства
>>> Y = y * X
>>> Y
array([[ 6, 9, 1],
[ 5, 7, 1],
[ -5, -9, -1],
[ 0, -10, -1]])
На этом месте можно вспомнить, что условие разделения классов это
Введём вектор , в котором
отвечает за расстояние от элемента
до разделяющей прямой (
). Поскольку мы хотим, чтобы все элементы были классифицированы правильно, мы вводим условие
. Тогда задача сведётся к
и будет решаться как
. Можно вручную подобрать такие значения
, что получившаяся плоскость будет разделять нашу выборку:
>>> b = np.ones([4, 1])
>>> b[3] = 10
>>> w = np.dot(np.linalg.pinv(Y), b)
>>> np.dot(Y, w)
array([[ 0.8540146 ],
[ 0.98540146],
[ 0.81021898],
[ 10.02919708]])
Алгоритм Хо-Кашьяпа
Алгоритм Хо-Кашьяпа предназначен для того, чтобы подобрать
- Вычислить коэффициенты МНК-регрессии (
).
- Вычислить вектор отступов
.
- Если решение не сошлось (
), то повторить шаг 1.
Вектор отступов хочется вычислить каким-нибудь путём вроде
>>> e = -np.inf * np.ones([4, 1])
>>> b = np.ones([4, 1])
>>> while np.any(e < 0):
... w = np.dot(np.linalg.pinv(Y), b)
... e = b - np.dot(Y, w)
... b = b - e * (e < 0)
...
>>> b
array([[ 1.],
[ 1.],
[ 1.],
[ 12.]])
>>> w
array([[ 2.],
[-1.],
[-2.]])
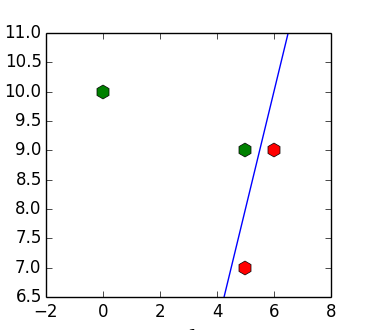
В случае линейно-разделимой выборки алгоритм всегда сходится и сходится к разделяющей плоскости (если все элементы градиента по неотрицательны, то они все нулевые).
В случае линейно-неразделимой выборки, функция потерь может быть сколь угодно малой, поскольку достаточно домножить и
на константу для изменения её значения и в принципе алгоритм может и не сойтись. Поиск не даёт никаких конкретных рекомендаций на эту тему.
Связь алгоритма Хо-Кашьяпа и линейного SVM
Можно заметить, что если объект классифицирован правильно, то ошибка в поставленной оптимизационной задаче (
В свою очередь, функция потерь линейного SVM имеет вид:
Таким образом, задача, решаемая алгоритмом Хо-Кашьяпа, представляет собой некоторый аналог SVM с квадратичной функцией потерь (она сильнее штрафует за выбросы далеко от разделяющей плоскости).
Многомерный случай
Можно вспомнить, что МНК-регрессия является аналогом двухклассового линейного дискриминанта Фишера (их решения совпадают с точностью до константы). Алгоритм Хо-Кашьпяпа можно применить и для случая
Благодарности
parpalak за удобный редактор.
rocket3 за оригинальную статью.
Ссылки
(1) http://www.csd.uwo.ca/~olga/Courses/CS434a_541a/Lecture10.pdf
(2) http://research.cs.tamu.edu/prism/lectures/pr/pr_l17.pdf
(3) http://web.khu.ac.kr/~tskim/PatternClass Lec Note 07–1.pdf
(4) А.Е. Лепский, А.Г. Броневич Математические методы распознавания образов. Курс лекций
(5) Ту Дж., Гонсалес Р. Принципы распознавания образов
(6) Р.Дуда, П.Харт Распознавание образов и анализ сцен
