[Из песочницы] Визуализация статистики производительности оборудования с R – Shiny
«Безграмотными в 21 веке будут не те, кто не умеет читать и писать, а те, кто не умеет учиться, разучиваться и переучиваться«Элвин ТоффлерУ ИТ-специалистов могут возникать задачи, связанные с анализом производительности оборудования или анализом результатов различных генераторов нагрузки (ioMeter, Vdbench и прочее). В большинстве случаев для этих целей используется Excel с построением временных рядов, с нахождением основных описательных статистик и попытками это все как-то проанализировать. Существует альтернативное средство более быстрого и удобного анализа описательных статистик с разнообразными диаграммами и возможностью создания web-приложения для общего доступа. Касаться настоящей статистики с различными методами анализа данных не буду, только базовая описательная статистика (без проверки тестов и даже p-значения не будет) и разные диаграммы.
В этой статье я опишу один из вариантов того, как можно проанализировать такую информацию, представлять её в виде диаграмм (трафик!), и все это в виде web-приложения. Как следует из названия статьи — реализовано это на R, с пакетом (фреймворком) для web-приложений к R — Shiny.
Ограничения ExcelВ случае, когда номинальных переменных (LUN, RAID группы, профили нагрузки и пр.) немного — единицы, то использование Excel еще не представляет сложности. Но когда их количество увеличивается и необходимо сравнивать разные количественные характеристики в пределах одной переменной или, особенно, между разными переменными, то использование Excel и, тем более, только временных рядов, является нерациональным — вероятность сделать ложные предпосылки, найти то, чего нет или проглядеть очевидное — велика. Не говоря уже про затраченное время, усилия, обилие листов, десятки — сотни графиков на этих листах, об источниках данных, которые забываешь на следующий день. Многие (весьма показательные) типы диаграмм в Excel построить вообще невозможно, другие требуют использования надстроек или же написание объемного кода на VBA, или с десяток ручных действий по настройке диаграмм. Но даже в простом случае, анализ, выявление зависимости по классическим временным рядам — не очень хорошая идея, так как в первую очередь они служат для других целей — оценки развития изменения переменной во времени, декомпозиции временного ряда на составляющие, и прогнозирование данных рядов. А вовсе не для того, чтобы разместить несколько графиков на одной диаграмме, да еще с двумя разными осями и пытаться найти зависимости между переменными. В частности, создатель пакета ggplot2 Hadley Wickham (специалист по статистике) написал в 2008 году по этому поводу следующее: «I’m against this technique because I believe it leads to serious visual distortions and meaningless graphics».Преимущества R Ранее анализ данных (для личных проектов) я осуществлял с помощью Excel (в т.ч. с написанием VBA кода), и время от времени слышал о R, но относился скептически, думая, что и Excel мне вполне достаточно. Когда же интерес превысил скепсис, я был приятно удивлен, насколько быстро и просто можно производить манипуляции с данными, оценивать различные модели и строить разнообразные диаграммы со многими независимыми переменными, буквально в несколько команд. Большинство операций векторизовано, поэтому операции выполняются оперативно и необходимость в циклах в большинстве случаев отсутствует. Также стоит отметить широкое мировое сообщество по R, открывающее большие возможности по разрешению каких-то вопросов.Последовательность выполнения анализа данных производительности: I. Загрузка данных Загрузка информации осуществляется базовой функцией read.table () с необходимыми параметрами (разделитель столбцов, разделитель дробной части, строка заголовок).II. Упорядочение данных Иногда необходимо упорядочивать данные, и в зависимости от поставленных целей, разный тип представления данных (узкий — переменные одной размерности указаны в одном столбце, но с номинальными параметрами в других столбцах, или широкий — каждая переменная в разных столбцах) может быть удобнее другого. Например, для построения диаграмм пакета ggplot2 удобнее узкий формат, но и с широким форматом никаких сложностей. Удобными средствами конвертирования таблиц в разные форматы и манипуляций с данными располагают пакеты tidyr и dplyr.III. Основные параметры описательной статистики Основными параметрами являются минимальное (Min) и максимальное (Max) значение переменной, ее медианы (Median), ее арифметического среднего (Mean), первый (1st Qu.) и третий (3rd Qu.) квартиль. Все эти параметры могут быть посчитаны функцией summary (), а используя ее совместно с функцией tapply (), возможно получить результаты отдельно по любой наблюдаемой переменной с определенными условиями, или же для большей гибкости можно использовать функцию describe () (describeBy ()) которая выводит большую статистическую информацию, но позволяет удобно группировать исходные данные.IV. Диаграммы »… нет статистического метода более мощного, чем хорошо подобранный график«Дж. ЧемберсОдним из основных достоинств R является разнообразие типов диаграмм, которые он может построить. Диаграммы являются неотъемлемой частью разведочного анализа данных, позволяют выявлять закономерности и тренды в сложных наборах данных. В данном разделе я приведу девять основных концептуально различных диаграмм, краткое описание и пример их использования. Разумеется, при каждом исследовании выдвигается свое предположение о переменных, при котором использование конкретных диаграмм более показательно, и не всегда необходимо использовать их все, но в каких-то случаях и этого набора будет недостаточно (вообще в R более 1 000 диаграмм в разных пакетах). Многие диаграммы имеют весьма гибкие параметры, позволяющие настраивать результат диаграммы в требуемом виде, так и в оформлении (оси, подписи осей, название, цвета).
1. Временной ряд
Всем привычный временной ряд, представляет собой ряд данных, в котором измерения показателей повторяются через некоторые интервалы времени. Как уже было сказано выше, данные графики хороши для визуальной оценки одной из исследуемых переменных и ее развития во времени. Но в общем случае, помимо визуального анализа, такие диаграммы предназначены для декомпозиции ряда на компоненты, и возможное дальнейшее прогнозирование развития тенденции. В случае отсутствия привязки ко времени, при сравнении разных переменных целесообразнее использовать диаграммы приведенные ниже, тем самым элиминировав одну из размерностей — время (в случае же необходимости использования времени, использовать время как номинальную переменную — раскрасив ее цветом или использовать панельные диаграммы).
2. Точечные диаграммы (диаграммы рассеяния)
Данные диаграммы представляют собой графики, на которых точки используются для отображения значений некоторых количественных переменных, которые дополнительно могут быть разбиты на группы в соответствии с уровнями некоторых номинальных (или количественных) переменных (данные группы определяются цветом и/или размером). В данном примере изображаются зависимость значений задержек (мс) и производительности (IOps) по всем измерениям разных профилей, разбитые на группы (размера кэша — зашифрован в размере точки, и тип RAID группы — зашифрован цветов). Таким образом, на данной диаграмме отображаются сразу 4 разных переменных: 
3. Панельные (категоризованные) графики
Анализируемые данные разбиваются на отдельные категории и для каждой из них строится своя диаграмма (панель) определенного типа. Все эти диаграммы затем объединяются на одном рисунке (вертикально, горизонтально, сеткой), что существенно облегчает выявление статистических закономерностей и структур в данных. В данной диаграмме используется пример №2, видно, что слой данных по RAID группам был перенесен на две отдельные панели (слева и справа), но теперь размер кэша используется как параметр группирования (он покрашен цветом). И теперь дополнительно появляется возможность добавить одну группу (доп. переменную) — размер точки, тем самым увеличить количество независимых переменных до пяти, на единой диаграмме, не потеряв при этом наглядности.
4. Гистограмма (плотность) распределения
Гистограмма (плотность — кривая сглаживающая гистограмму (линии столбиков)) позволяет наглядно представить распределение значений анализируемой переменной, также совмещение на одной диаграмме переменных, которые дополнительно могут быть разбиты на группы в соответствии с уровнями некоторых номинальных (или количественных) переменных, позволит сравнить частоту встречаемости. В данном примере, например, изображена плотность распределения производительности (IOps) одной переменной в зависимости от созданного типа RAID.
5. Диаграммы размахов (боксплот, «ящик с усами»)
Данная диаграмма подходит для отражения основных робастных (устойчивых) характеристик выборки, эта функция также позволяет отображать несколько боксплотов одновременно, что позволяет быстро и эффективно оценить описательную статистику по разным факторным переменным. В данном примере, например, показано статистика распределения производительности (МБ/c) на разные профили нагрузки (фактически это аналог выводы функции summary (), но в графическом виде, и с добавлением выбросов, что более показательно): 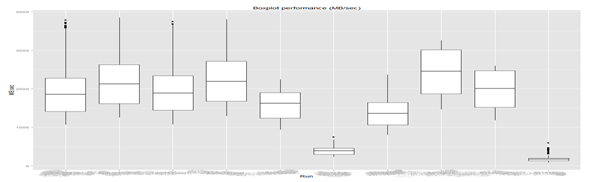
6. Матричный график (парные диаграммы рассеяния)
Данный график представляет собой семейство точечных диаграмм (п.2), отражающих попарно зависимость значений каждой переменной от каждой прочей переменной. В данном примере показаны попарные зависимости всех 5 переменных, также возможно добавить еще 6 переменную, раскрасив один из факторов цветом.
7. График параллельных координат
Данный график позволяет сравнивать значительное количество независимых переменных для каждого номинального значения, и показать попарную связь между ними, а цветом раскрасить одну из номинальных переменных. Несмотря на необычный вид, во многих случаях данные диаграммы могут помочь быстро классифицировать набор многомерных данных. Так, в данном примере, из диаграммы видно, что один профиль нагрузки (оранжевый) с высокими операциями ввода вывода, не влечет за собой увеличение нагрузки, а некоторые (синий) наоборот; часть профилей (зеленые) стабильно показывают высокую задержку, также видно, что некоторые профили попадают в одно и тоже место на каждом признаке, видно куда (малые или большие значения) смещены многие признаков и т.д.
8. Тепловая карта
Данная диаграмма отображает значение определенной переменной своим цветом, данная диаграмма будет полезна для отображения каких-либо характеристик в привязке к реальному физическому размещению компонентов оборудования. Например, отображать более «горячие» (по производительности, по времени, по частоте обращения и т.д.) диски в полках (как в данном примере: по горизонтали — номера слотов, по вертикали — номера полок), или отображать более горячие RAID группы или пулы в привязке к их физическим дискам в массиве.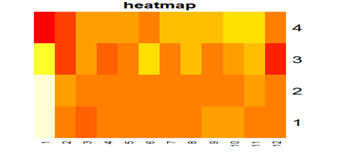
9. Пиктограммы (звезды, лица Чернова) Также для анализа агрегированных многомерных данных могут использоваться разные пиктограммы (звезды, лица Чернова).Идея таких диаграмм состоит в том, что люди хорошо различают объекты, в данном случае лица (а не набор десятков значений из 10–20 цифр). В приведенном примере каждое лицо соответствует одному профилю нагрузки, который в агрегированном (медианном) виде отражает характеристики значений признаков (производительность (двух типов), задержки (трех типов)). Беглый взгляд на данную диаграмму позволит быстро определить, значимо ли отличаются (совпадают) характеристики профилей, при детальном обзоре (черт лиц) будет понятно, в каких признаках (каждое черта лица — отдельный признак исходного набора данных) сходство, а в чем различие.

V. Динамичное управление (Shiny) Весь код по загрузке данных, преобразованию данных и изображению диаграмм, пишется в R-Studio, удобной графической оболочке к R, этого вполне достаточно для получения быстрых результатов и написания отчетов. Но может возникнуть ситуация в гибком, динамическом средстве настройки результатов (выбор осей, диаграмм, масштабирование, сохранение результатов в графические файлы и многое другое), и/или в случае демонстрации результатов широкому кругу — коллег, заказчику, партнерам. В таком случае достаточно удобно привязать существующий код (или сразу писать новый) к элементам ввода-вывода web-приложения с использованием пакета Shiny. Shiny — это пакет (фреймворк) для быстрой разработки веб-приложений. Наткнулся я на него совершенно случайно, и мое удивление от использования R — перенеслось также и на него: несколько типов основных элементов ввода-вывода, удобная привязка кода вычислений к элементам ввода-вывода, динамическое изменение элементов ввода, реактивные переменные и функции — все оказалось намного проще, чем я думал. Отличное решение для скрытия кода и демонстрации только «крутилок-вертелок» и картинок.VI. Распространение результатов Как в случае использования Shiny, так и без него, весь код R — находится в текстовых файлах с расширением R. Единственное отличие в случае Shiny — таких файлов два — ui.R (описание элементов ввода-вывода) и server.R (все вычисления) (хотя можно делать Shiny приложения и в одном файле, но по мне удобнее оставлять два). Следовательно, распространение результатов следующее: Для пользователей R:1. Непосредственное распространение файлов R (отдельно или в архиве)2. Размещение файлов R, используя Github. Для получения файлов, в R достаточно выполнить одну команду и файлы будут загружены локально, и появляется возможность их запустить.
Для всех (в этих случаях необходимость иметь установленный R отсутствует, запуск Shiny — приложения осуществляется из браузера):1) размещение Shiny приложения на своем локальном Shiny сервере (имеется два варианта — бесплатный и платный (с аутентификацией и SSL));2) размещение Shiny приложения в облачном хостинге (на серверах R-Studio), на данный момент имеется четыре тарифных плана: от бесплатного (с ограничениями по кол-ву приложений и времени работающего приложения в месяц) до платных (со снятыми ограничениями, возможностями аутентификации (SSL)).
Вкратце о реализации и результаты 1. Вначале открывается выбранный пользователем файл;2. На основе существующих профилей нагрузок, формируются уникальные значения, обновляется выпадающий список;3. При выборе профиля из выпадающего списка, создается новый набор и на основании него изменяются диаграммы, описательная статистика и исходные данные (для сравнения);4. Разумеется, можно сделать и выбор нескольких профилей (элементы управления это позволяют), анализ их на разных диаграммах, раскраска цветами номинальных параметров, сохранение диаграмм в различных форматах (векторных и растровых).Ниже приведены некоторые скриншоты моего Shiny приложения для анализа производительности выгрузки Vdbench, с индивидуальным выбором профиля, динамической настройкой диапазонов осей, отображением некоторых типов диаграмм (перестраиваются менее чем за секунду). Это все реализовано исключительно на базовых элементах Shiny, хотя есть возможности настройки, стилизации приложения используя непосредственно как HTML, CSS, так и JavaScript и jQuery.
 1 панель
1 панель
 2 панель
2 панель
 3 панель
3 панель
 4 панель
4 панель
Заключение В итоге можно сказать, что я разобрался с основными графическими возможностями ggplot2 и оформлением диаграмм (ранее в основном мне было достаточно построение самих диаграмм, без особого оформления) — действительно удобным средством для построения разных диаграмм, ну и конечно изучил Shiny. Для начального разведочного анализа данных производительности ресурсов — R весьма подходящий инструмент, по крайней мере, по удобству использования, скорости получения результатов, и самих графических результатов. Дополнительное использование Shiny (как своего сервера или облачного сервера) позволит продемонстрировать результаты анализа в более удобной форме, как внутренним сотрудникам, так и Заказчикам.
