[Из песочницы] Тестировщик ПО. Минимальный пакет знаний для трудоустройства
 Всем привет. Что нужно знать для того, чтобы устроиться на работу тестировщиком?
Всем привет. Что нужно знать для того, чтобы устроиться на работу тестировщиком?
I) Прочитать и понять эту книгу Роман Савин. Тестирование Дот Ком; II) Разобраться с SQL — запросами; III) Разослать резюме; IV) Показать свои знания и адекватность на собеседовании.
Теперь подробнее.
I) Прочитать и понять книгуВ книге около 300 страниц. За 1–2 дня прочитать несложно. Для тех, у кого нет времени на чтение, попробую изложить коротко основные моменты. Но рекомендую прочитать её полностью.Участники разработки ПО:1. Менеджер проекта — специалист, занимающийся вопросами поиска заказчиков проектов и исполнителей2. QA-инженер — специалист, задача которого организовать процесс разработки таким образом, чтобы работа была выполнена в срок и на надлежащем уровне качества.3. Продюсер — специалист, задача которого составить спецификацию (spec)4. Программист — специалист, занимающийся написанием или корректировкой кода программы5. Тестировщик — специалист, занимающийся поиском багов
Цикл разработки ПО состоит из:1. Идея.2. Разработка дизайна продукта и создание документации.3. Кодирование или создание кода.4. Исполнение тестирования и ремонт багов. 5. Релиз.
Цикл тестирования ПО состоит из трех этапов:1. Изучение и анализ предмета тестирования.2. Планирование тестирования.3. Исполнение тестирования.
Основные понятия:
1. Тестирование — это сравнение фактического результата с ожидаемым.2. Цели тестирования — нахождение багов до того, как их найдут пользователи.3. Баг (bug) — это отклонение фактического результата от ожидаемого.4. Спецификация (spec) — это детальное описание того, как должно работать ПО. Так же, это детальное описание ожидаемого результата. (В спецификации тоже могут быть баги, например, двусмысленные предложения).5. Тест-кейс — это инструмент тестировщика, предназначенный для документирования и проверки одного или более ожидаемых результатов. 6. Тест-комплект — совокупность тест-кейсов находящихся, как правило, в одном документе, которые проверяют какую-то определенную часть нашего проекта.7. Шаги тест-кейса (procedure) — это часть тест-кейса, ведущая исполнителя тест-кейса к фактическому результату. (Излишняя детализация может осложнить поддержку, а излишнее абстрагирование привести к непониманию того, как исполнить тест-кейс).8. Front end — это непосредственный интерфейс пользователя (текст, картинки, кнопки, линки и прочие вещи, которые видно в окне приложения)9. Back end — это то что на заднем фоне приложения (веб-сервер, код приложения, база данных и т.д.).10. New feature testing — тестирование новых компонентов. 11. Regression testing — исполнение старых тест-кейсов для проверки того, что старые компоненты ПО еще работают.12. СТБ (Bug Tracking System) — Система в которую заносятся баги.13. Git — распределённая система управления версиями файлов (для управления коллекцией исправлений, патчей).
Виды тестирования:
1. По знанию внутренностей системы: • черный ящик (black box testing) — тестирование программы без доступа к коду; • белый ящик (white box testing) — тестирование программы только по коду; • серый ящик (grey box testing) — тестирование без кода+тестирование по коду.
2. По объекту тестирования: • функциональное тестирование (functional testing) — например, проверка выводимого результата; • тестирование интерфейса пользователя (UI testing) — из названия понятно; • тестирование локализации (localization testing) — например, проверка шрифтов и другая адаптация приложения для пользователей; • тестирование скорости и надежности (load/stress/performance testing) — например, проверка скорости загрузки сайта при определенном количестве пользователей; • тестирование безопасности (security testing) — суть в том, чтобы усложнить условия для кражи данных (например телефонов и др. личной информации); • тестирование опыта пользователя (usability testing) — суть в том, чтобы интерфейс был интуитивно понятен даже непродвинутым пользователям; • тестирование совместимости (compatibility testing) — запуск на разных операционках и браузерах.
3. По субъекту тестирования: • альфа-тестировщик (alpha tester) — тестирование сотрудниками фирмы; • бета-тестировщик (beta tester) — тестирование пользователями.
4. По важности тестирования: • сначала тестирование новых функциональностей (new feature testing) — тестирование новых функциональностей; • потом регрессивное тестирование (regression testing) — повторное тестирование старых функций.
5. По критерию «позитивности«сценариев: • позитивное тестирование (positive testing) — тестируем ожидаемыми методами; • негативное тестирование (negative testing) — тестируем нестандартными методами (например вводим вместо 9 цифр — 11 букв).
6. По степени изолированности тестируемых компонентов: • компонентное тестирование (component testing) — это тестирование одного логического компонента; • интеграционное тестирование (integration testing) — это тестирование на уровне двух или больше логических компонентов; • системное тестирование (system or end- to-end testing) — это проверка всей системы от начала до конца.
7. По степени автоматизированности тестирования: • ручное тестирование (manual testing) — это исполнение тест-кейсов без помощи каких-либо программ, автоматизирующих вашу работу (например, создаем аккаунт вручную); • автоматизированное тестирование (automated testing)- акаунт создается программой автоматически; • смешанное/полуавтоматизированное тестирование (semi automated testing) — создаем акаунт вручную, но закупки сделаются автоматически.
8. По степени подготовки к тестированию: • тестирование по документации (formal/documented testing) — тестирование по тест-кейсам; • эд хок-тестирование (ad hoc testing) — интуитивное тестирование без документации (например, когда что-то нужно быстро проверить).
Пример тест-кейса:
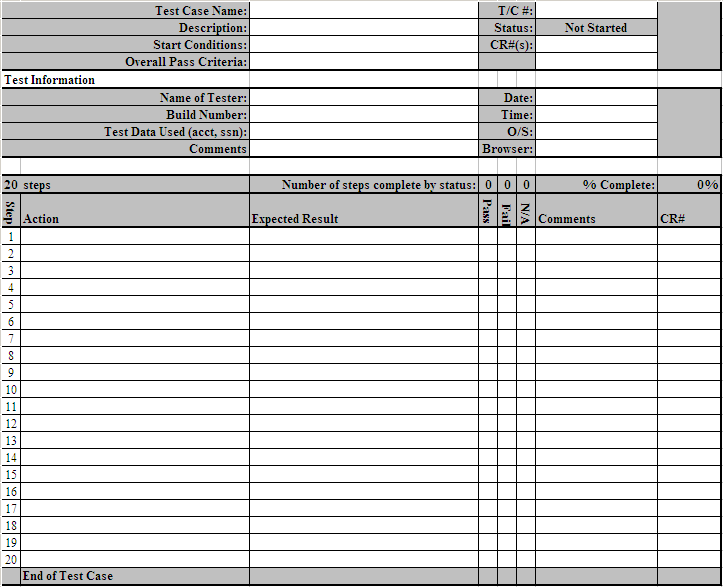
Также по документам существует: • Тест-смета (Test Estimation) — документ, включающий в себя предварительную оценку времени, необходимого на подготовку к тестированию и на тестирование новых фича (new feature testing); • Тест-план (test-plan) — документ, обобщающий и координирующий тестирование (подробнее об этом документе можно узнать в книге Савина).
II) Разобраться с SQL запросами SQL (structured query language) — структурированный язык запросов.С помощью SQL- запросов можно создавать и работать с реляционными базами данных.Реляционная база данных — это таблица, в которой в качестве столбцов выступают поля данных, а каждая строка хранит данные.SQL определяется Американским Национальным Институтом Стандартов и Международной Организацией по стандартизации (ISO)Несмотря на это, некоторые производители баз данных вносят изменения и дополнения в этот язык. Эти изменения незначительны и основа остаётся совместимой со стандартом. (например ms sql, my sql, postgreSQL).
В каждой таблице должно быть одно уникальное поле, которое однозначно будет идентифицировать строку. Это поле назовем ключевым (Key1, Key2…).В качестве ключа обычно используют численный тип и если позволяет база данных, то он будет типа «autoincrement» (автоматически увеличивающееся).
Столбцы в базе данных, также должны быть уникальными, но в этом случае не обязательно числовыми. Их можно называть как угодно, лишь бы было уникально и понятно.
SQL может быть двух типов: интерактивный и вложенный. Интерактивный — это отдельный язык, он сам выполняет запросы и сразу показывает результат работы. Второй — это когда SQL язык вложен в другой, например в С++ или Delphi.
Так как мы формируем минимальный список знаний трудоустройства, мы рассмотрим интерактивный SQL.
Представим, что у нас есть две таблицы:
Prog.dbKey1 / ProgName / Cost1 / Windows 95 / 1002 / Windows 98 / 120
и
User.dbKey1 / Key2 / LastName1 / 1 / Иванов2 / 1 / Петров3 / 2 / Сидоров
Рассмотрим первый запрос:
SELECT *FROM Prog, UserWHERE Prog.Key1= Key2AND ProgName LIKE 'Windows 95'
Выбрать (SELECT) все поля (*) из (FROM) баз данных Prog и User, где (WHERE) есть связь (Prog.Key1 и Key2) Prog.Key1= Key2 и ProgName LIKE 'Windows 95'.LIKE это тоже самое что равно (=) только для строк
Результатом этого запроса будет:
Prog.db User.dbKey1 / ProgName / Cost / Key1 / Key2 / LastName1 / Windows 95 / 100 / 1 / 1 / Иванов1 / Windows 95 / 100 / 2 / 1 / Петров
Отредактируем немного запрос: SELECT Prog.Key1, Prog.ProgName, Prog.Cost*2 'руб', Cost.Key1, Cost.Key2, Cost.LastNameFROM Prog, UserWHERE Prog.Key1= Key2
Prog.Cost*2 'руб' — эта запись говорит, что к каждое значение надо умножить на 2 и прибавить строку 'руб'.
Результат: Prog.db User.dbKey1 / ProgName / Cost / Key1 / Key2 / LastName1 / Windows 95 / 200 руб / 1 / 1 / Иванов1 / Windows 95 / 200 руб / 2 / 1 / Петров
Для сортировки используется команда ORDER BY. После этого пишутся поля, по которым надо отсортировать. В самом конце нужно поставить АSC (сортировать в порядке возрастания) или DESC (в порядке убывания). Если ты не ставишь АSC или DESC, то таблица сортируется по возрастанию и подразумевается параметр АSC.
Например: SELECT *FROM ProgORDER BY ProgName DESC
Результатом будет таблица Prog, отсортированная по полю ProgNamе в порядке убывания.
SQL калькулятор: Вот несколько функций: • COUNT — подсчёт количества строк; • SUM — подсчёт суммы; • AVG — подсчёт среднего значения; • MAX — поиск максимального значения; • MIN — поиск минимального значения.
Этот запрос просто подсчитывает количество строк в базе: SELECT COUNT (LecNumber)FROM User
Этот запрос опять подсчитывает количество строк, но теперь результатом будет количество народу, у которых поле LecNumber = 1: SELECT COUNT (LecNumber)FROM UserWHERE LecNumber=1
Этот запрос выводит количество лицензий и единицу измерения в одном столбце. Здесь к числу прибавляется текст: SELECT LecNumber+'шт.'FROM User
Объединения: Представим, что у нас есть две таблицы User1 и User2: User1.dbKey1/OC/ LastName1 / Win/ Иванов2 /Unix/ Петров3 /Win/ Яковлев4 /Win/ Сидоров5 /Win/ Ковалёв6 /Unix/ Амаров
User2.dbKey1/OC/ LastName2 /Unix/ Богров3 /Win/ Сидоров4 /OS2/ Ковалёв
Мы хотим получить список всех пользователей Unix из двух таблиц сразу. Для этого нужно выполнить запрос выбора к первой таблице, а потом ко второй. Результатом будет две выходные таблицы. А если мы хотим получить одну? Для этого можно воспользоваться объединением — оператор UNION. Вот как это будет выглядеть:
SELECT *FROM User1.dbWHERE OC LIKE 'Unix’UNIONSELECT *FROM User2.dbWHERE OC LIKE 'Unix';
Результатом будет таблица:
User1.dbKey1 / OC / LastName2 /Unix/ Петров6 /Unix/ Амаров2 /Unix/ Богров
Чтобы запрос не завершился ошибкой, он должен удовлетворять следующим условиям: • Количество и типы полей должны быть одинаковыми; • Символьные поля должны иметь одинаковое число символов.
Если одного поля в одном из запросов нет, то его можно заменить. Например:
SELECT Key1, OC, LastNameFROM User1.dbWHERE OC LIKE 'Unix’UNIONSELECT Key1, OC, 'NO FOUND’FROM User2.dbWHERE OC LIKE 'Unix';
Результат:
User1.dbKey1 / OC / LastName2 /Unix/ Петров6 /Unix/ Амаров2 /Unix/ NO NAME
Здесь мы вместо поля LastName подсовываем текст 'NO FOUND', чтобы количество и тип полей совпадали.
Упорядочим наш вывод:
SELECT Key1, OC, LastName, 'Table 1'FROM User1.dbWHERE OC LIKE 'Unix’UNIONSELECT Key1, OC, 'NO FOUND', 'Table 2'13FROM User2.dbWHERE OC LIKE 'Unix'; ORDER BY 3
Результат:
User1.dbKey1/ OC / LastName2 /Unix /NO NAME Table 26 /Unix /Амаров Table 12 /Unix /Петров Table 1
Запросы с подзапросами: SQL позволяет вставлять одни запросы внутрь других.
SELECT *FROM User1.dbWHERE Key2 =(SELECT Key1 FROM ProgWHERE ProgName LIKE 'MyProg.exe');
Сначала SQL выполнит внутренний запрос, который расположен в скобках и результат подставит во внешний запрос.Тут должно выполнятся два условия: у внутреннего запроса, в качестве результата должен быть только один столбец. Это значит, что мы не можем написать во внутреннем запросе SELECT *, а можно только SELECT ИмяОдногоПоля. Помним, что имя должно быть только одно и тип его должен совпадать с типом сравниваемого значения.
Для большей надёжности можно использовать с подзапросом оператор DISTINCT. Единственный случай, когда подзапрос может выдавать в результате несколько строк, это когда в основном запросе используется оператор IN:
SELECT *FROM User1.dbWHERE Key2 IN (SELECT Key1 FROM ProgWHERE ProgName LIKE 'MyProg.exe');
Здесь, вместо знака равно мы использовали оператор IN (key2 IN (подзапрос)). Так что для надёжности запроса можно использовать не только DISTINCT, но и оператор IN. Это желательно делать даже в тех случаях, когда мы уверены, что результатом будет только одна строка.
Мы можем обращаться из внутреннего запроса к внешнему. Как это делать?
SELECT *FROM User1.db outerWHERE Key2 =(SELECT Key1FROM Prog innerWHERE key1 = outer.Key2);
Слова outer и inner — псевдонимы, которые назначаются таблицам user1 и prog соответственно. Это значит, что когда мы пишем outer, это то же самое, что и написать User1. Такой запрос будет выполнятся по следующему алгоритму:
• Выбрать строку из таблицы User1.db в внешнем запросе. Это будет текущая строка- кандидат.
• Сохранить значения из этой строки-кандидата в псевдониме с именем outer.
• Выполнить подзапрос. Везде, где псевдоним данный для внешнего запроса найден (в этом случае «outer»), использовать значение для текущей строки-кандидата. key1 = outer.Key2. Использование значения из строки — кандидата внешнего запроса в подзапросе называется — внешней ссылкой.
• Оценить предикат внешнего запроса на основе результатов подзапроса выполняемого в предыдущем шаге. Он определяет — выбирается ли строка-кандидат для вывода.
Попробуй остановится на секунду и подумать над предложенным запросом.
Ещё несколько операторов:1) Оператор EXISTS. Это простая проверка на существование. Этот оператор относится к выражениям Булиан.
разу рассмотрим пример:
SELECT cnum, cname, cityFROM User1WHERE EXISTS (SELECT *FROM User2WHERE OC = «Unix»);
Это не подзапрос, потому что он выполняется только один раз. Внутренний запрос выбирает все записи, где ОС равна «Unix». Оператор EXISTS проверяет, если был какой-то результат, то генерирует True, а значит выполниться условие EXISTS. После этого выполнится внешний запрос:
SELECT cnum, cname, cityFROM User1
Так как EXISTS Булиан оператор, его можно использовать с другими Булианами. Вот тебе пример с NOT: SELECT cnum, cname, cityFROM User1WHERE EXISTS (SELECT *FROM User2WHERE OC = «Unix»); В этом случае внешний запрос выполнится только если внутренний не выведет ни одной строки.
Теперь рассмотрим операторы ANY, SOME, и ALL. Первые два оператора абсолютно одинаковы.
SELECT cnum, cname, cityFROM User116WHERE ОC=ANY (SELECT OCFROM User2);
Здесь сначала выполняется внутренний запрос, выбирая все OC из базы User2. Затем выполняется внешний запрос, который выберет все строки, где встретилась любая (ANY) из ОС внутреннего запроса. То есть, результатом будут все строки из User1, в которых встречаются ОС такие же как и в User2.
Теперь познакомится с ALL:
SELECT cnum, cname, cityFROM User1WHERE NumberLesens>ALL (SELECT NumberLesensFROM User2);
Результатом этого запроса будут все строки, в которых количество лицензий (NumberLesens) больше, чем у всех из таблицы User2.
Работа с полями: NSERT (вставить), UPDATE (модифицировать), DELETE (удалить).После оператора VALUES идёт перечисление всех полей строки. Теперь рассмотрим пример: INSERT INTO User1VALUES ('Иванов', 'Сергей', 34);
Этой командой мы вставили строку и присвоили значения полям. В таблице три поля: первые два поля строковые (Фамилия и Имя), последнее поле — целое число (возраст). Типы данных обязаны совпадать с теми, что установлены в таблице.
Если не надо задавать все поля, тогда можно оставить их пустыми с помощью NULL: INSERT INTO User1VALUES ('Иванов', NULL, 34);
Если таблица с большим количеством полей и нужно заполнить только два из них? Решение:
INSERT INTO User1 (Family, Age)VALUES ('Иванов', 35);
После конструкции INSERT INTO и имени базы стоят скобки, где перечислены поля, которые необходимо заполнить (Фамилия и Возраст). В скобках после слова VALUES перечисляем эти поля в той же последовательности, в которой перечислил перед этим (сначала фамилия, а потом возраст).
Теперь представь, что мы хотим сохранить результат запроса SELECT в отдельной таблице. Для этого в SQL всё уже предусмотрено. Нужно только написать:
INSERT INTO User1SELECT *FROM User2WHERE Age=10
В этом примере сначала выполнится запрос SELECT:
SELECT *FROM User2WHERE Age=10
После его выполнения результат будет занесён в таблицу User1. Важно, что количество столбцов в запросе и результирующей таблицы должно быть одинаково. А самое главное — это чтобы тип данных совпадал
Теперь рассмотрим такой запрос:
INSERT INTO User1(Name, Age)SELECT Name, AgeFROM User2WHERE Age=10
Теперь в таблицу User1 будут перенесены только два столбца (имя и возраст). Поля должны быть перечислены в таком порядке, чтобы типы и длина полей совпадали.
Мы смогли добавить строки, но надо и научиться изменять данные. Для этого нам доступна команда UPDATE. Сразу же попробуем взглянуть на пример:
UPDATE User1SET age=65
Первая строка говорит о том, что нам надо обновить базу User1. Вторая строка начинается с оператора SET (установить). После этого мы пишем поле, которое хотим обновить, и присваиваем ему значение.
Если нужно обновить только определённые строки, то ты должен написать так: UPDATE User1SET age=65WHERE Name LIKE 'Вася'
или
UPDATE User1SET age=age+1
или
UPDATE User1SET age=age+1, Name='Иван'WHERE Family LIKE 'Сидоров'
Этот запрос увеличит поле Age на единицу и установит поле Name в «Иван» во всех строках, где поле Family равно «Сидоров».
Теперь команда DELETE:
DELETE FROM User1
Эта конструкция удаляет абсолютно все строки из таблицы User1. Можно сказать, что этим мы очищаем таблицу.
Теперь рассмотрим другой пример:
DELETE FROM User1WHERE Age=10
Этот пример удаляет только те строки, в которых поле Age равно 10.
Создание, изменение и удаление таблиц:
Для создания таблицы используется команда CREATE TABLE, которая создаёт пустую таблицу. После этой команды нужно определить столбцы, их типы и размер.
CREATE TABLE (<Имя столбца > <Тип> [(<Размер>)], <Имя столбца > <Тип> [(<Размер>)]…);
Обрати внимание, что <Размер> показан в квадратных скобках, потому что не все типы данных требуют указания размера поля.
Виды типов данных:
• CHAR или CHARACTER — строковое поле. В качестве размера используется длина строки.
• DEC или DECIMAL — Десятичное число, т.е. число с дробной частью. Размер состоит из двух частей — точность и масштаб. Эти параметры нужно указывать через запятую. Точность показывает сколько значащих цифр имеет число. Масштаб показывает количество знаков после запятой. Если масштаб равен нулю, то число становится эквивалентом целого.
• NUMERIC — Такое же как DECIMAL. Разница только в том, что максимальное десятичное не может превышать аргумента точности.
• FLOAT — Опять число с плавающей точной, только в этом случае размер указывается одним числом, которое указывает на минимальную точность.
• REAL — то же, что и FLOAT, только размер не указывается, а берётся из системы по умолчанию.
• DOUBLE — то же, что и REAL, только размер побольше (чаще всего в два раза).
• INT или INTEGER — целое число. Размер указывать не надо, он подставляетсяавтоматически.
• SMALLINT — то же, что и INTEGER, только его размер меньше. В большинствеслучаев, если точность INTEGER равна 2 байтам, то точность SMALLINT равна 1 байту.
CREATE TABLE NovayaTablica (id integer, name char (10), city char (10), Metr declmal); Этот запрос создаёт таблицу с именем NovayaTablica и четырьмя полями.
Все названия, включающие в себя пробелы, должны заключаться в квадратные скобки.
CREATE TABLE [Новая таблица](Идентификатор integer, Имя char (10),[Место расположения] char (10), Метраж declmal);
Обрати внимание, что все составные имена заключены в квадратные скобки. При работе с запросом, ты так же должен использовать такие скобки:
Select *From [Новая таблица]WHEREИдентификатор=10 and[Место расположения] LIKE 'Москва';
Важно: не все базы данных позволяют использовать русские и составные имена.
Теперь поговорим о создании индексов. В общем виде это выглядит так:
CREATE INDEX <Имя индекса> ON <Имя таблицы>(<Имя поля> [, <Имя поля>]…);
Реальный пример:
CREATE INDEX NewIndex ON NewTable (name);
Здесь создаётся новый индекс с именем NewIndex в таблице NewTable для name. Если нужно создать уникальный индекс, то можно написать так: CREATE UNIQUE INDEX NewIndex ON NewTable (name);
При создании простых индексов можно указать в скобках несколько полей, например: CREATE INDEX NewIndex ON NewTable (name, city); Это создаст составной индекс и проиндексирует таблицу сразу по двум полям name и city. Важно: при создании уникальных индексов такого делать нельзя. Поле должно быть одно.
Теперь поговорим о добавлении новых столбцов. Для этого существует команда ALTER TABLE. Вот так она выглядит в общем виде: ALTER TABLE <Имя таблицы> ADD <Имя поля> <Тип> <Размер>; Например: ALTER TABLE Справочник ADD [Новое поле] INTEGER
Для удаления полей используем:
ALTER TABLE [Имя таблицы] DROP [Имя поля]
А для удаления таблиц используется команда DROP TABLE: DROP TABLE < Имя таблицы >;
Настройка таблиц:
Рассмотрим общий случай:
CREATE TABLE Имя_Таблицы (Имя_Поля_1 Тип Ограничения, Имя_Поля_2 Тип Ограничения,);
Создадим таблицу с двумя полями. Первое должно быть уникальным, а второе не должно содержать нулей:
CREATE TABLE NewTable (Name char (10) UNIQUE, email char (10) NOT NULL);
Это позволяет нам использовать это поле в качестве уникального ключа, и за уникальностью будет следить сама база данных.
Для первичных ключей не нужно указывать уникальность, они уникальны от природы:
CREATE TABLE NewTable (Name char (10) NOT NULL PRIMARY KEY, email char (10) NOT NULL UNIQUE);
Единственное ограничение, которое мы оставляем — это NOT NULL. Его желательно оставить, потому что первичные ключи не могут быть пустыми.
А если нам нужно создать таблицу, где комбинация из двух полей должна давать уникальность? Это значит, что в двух строках не может быть одинаковых значений двух определённых полей, например:
П1/П23 /34 /25 /34 /2
Если мы поставим уникальность по обоим полям, то во второй и четвёртой строке будет ошибка, оба поля имею одно и то же значение.
Так как же задать ограничение сразу по двум столбцам?
CREATE TABLE NewTable (Name char (10) NOT NULL, email char (10) NOT NULL, Phone char (10), UNIQUE (Name, email)); В этом примере мы создали таблицу с тремя полями и первые два из них являются уникальными. Точно так же можно создать таблицу с первичным ключом из двух первых столбцов:
CREATE TABLE NewTable (Name char (10) NOT NULL, email char (10) NOT NULL, Phone char (10), PRIMARY KEY (Name, email));
Помни, что большинство баз данных накладывает ограничение на первичный ключ — только первые и подряд идущие поля могут входить в первичный ключ.
Есть ещё одно интересное ключевое слово — CHECK, которое позволяет задать диапазон допустимых значений в поле, например:
CREATE TABLE NewTable (Name char (10) NOT NULL PRIMARY KEY, email char (10) NOT NULL UNIQUE, Age decimal CHECK (Age<110));
В этом примере мы добавили поле Age (Возраст) типа decimal. После этого поставили ключевое слово CHECK, которое задаёт ограничение. После этого в скобках указываем это ограничение, что поле Age должно быть меньше 110 (Вряд ли, что кто-то проживёт больше 110 лет). Теперь усложним пример, сделав двойную проверку:
CREATE TABLE NewTable (Name char (10) NOT NULL PRIMARY KEY, email char (10) NOT NULL UNIQUE, Age decimal CHECK (Age<110 and Age>0));
В этом примере мы сделали дополнительное ограничение. Теперь значение в поле Age должно быть больше 0 и меньше 100.
Есть ещё один тип ограничений — типа SQL оператора IN (который мы рассматривали чуть выше):
CREATE TABLE NewTable (Name char (10) NOT NULL PRIMARY KEY, email char (10) NOT NULL UNIQUE, Age decimal CHECK (Age<110),Town char(15) CHECK (Town in ('Moscow', 'Piter', 'Brest')));
Здесь мы используем знакомый оператор IN, который перечисляет допустимые значения для поля Town. Так можно использовать любые допустимые операторы сравнения SQL. Например, можно использовать знаки множественного выбора (маски) такие как _ (подчёркивание — заменяет одну любую букву) и % (процент — заменяет множество букв). Эти маски мы уже изучали, так что давайте посмотрим пример:
CREATE TABLE NewTable (Name char (10) NOT NULL PRIMARY KEY, email char (10) NOT NULL UNIQUE, Age decimal CHECK (Age<110),Town char(15) CHECK (Town in ('Moscow', 'Piter', 'Brest')),DateB char(10) CHECK (DateB LIKE '__/__/____'),Password char(10) CHECK (DateB LIKE 'RTY%'));
Здесь добавляем два поля:
• DateB (Дата рождения) — любое значение этого поля должно удовлетворять маске__/__/____• Password (Пароль) — пароль — слово, которое должно начинаться с трёх букв 'RTY'
Помимо ограничений, нам доступны для настройки и значения по умолчанию, за этоотвечает слово DEFAULT:
CREATE TABLE NewTable (Name char (10) NOT NULL PRIMARY KEY, email char (10) DEFAULT='mail.ru', Age decimal CHECK (Age<110),Town char (15) DEFAULT='Moscow');
В этом примере мы сразу двум полям задали значения по умолчанию.
III) Разослать резюме
Самая короткая глава, это все умеют, hh.ru вам в помощь. Там же можно составить резюме. Перед составлением не забывайте смотреть резюме своих конкурентов.
IV) Показать свои знания и адекватность на собеседовании Обычно собеседование делятся на 3 этапа:1) Встреча с девушкой из отдела кадров. На этом этапе будет несколько вопросов по вашим знаниям, чтобы было понятно, что вы в «теме» и много общих вопросов, чтобы определить вашу адекватность.2) Тестовое задание — обычно дается на дом3) Встреча с руководителем где будут вопросы, касающиеся ваших навыков тестирования.Тестовое задание и встреча с руководителем вряд ли уйдет за рамки того, что мы написали выше. Рассмотрим первую ситуацию, где нам будут задавать вопросы на нашу адекватность.
Предположим, что у нас нет никакого официального опыта работы тестировщиком, в нашей голове только теория, хобби- программирование на самом начальном этапе, а в трудовой запись «менеджер по продажам».
Рассмотрим основные вопросы и и примеры самых обычных ответов на них:
1) Почему вы решили стать тестировщиком? Меня всегда тянуло в IT сферу, эта профессия больше всего подходит моему характеру и моим интересам.
2) Что больше всего вам нравится в тестировании? Я обожаю анализировать и изучать программы, например на прошлом месте работы мне больше всего нравилось работать с 1с, я даже смог поставить одну из версий себе на домашний компьютер, для более детального изучения программы, без всяких ограничений.
3) Какими достоинствами должен обладать эффективный тестировщик? Честность, внимательность (для поиска багов), общительность (так как нужно будет много общаться с персоналом), обучаемость (без этого никуда), умение работать с большим объемом информации и умение расставлять приоритеты, и, конечно, стрессоустойчивость.
4) Ваше самое большое профессиональное достижение (не обязательно в области тестирования).Создание и поддержание базы для логистики и закупа, которой пользовались все менеджеры компании. По этой базе, я мог закупить все, что мне нужно максимально дешево, и с любой точки России доставить товар с отличным соотношением цены, качества и риска.
5) Почему вы ушли (уходите) из своей предыдущей компании? Мне нравилось работать в прошлой компании, но я хочу опробовать себя как тестировщик ПО. Так как данная сфера ближе к моим интересам, характеру и увлечениям. На этой должности я буду получать гораздо большое удовольствия от работы.
6) Приведите пример сложной ситуации, с которой вы столкнулись в своей карьере, и какой выход из нее вы нашли? Из-за текучки кадров, мне часто приходилось брать обязанности других на себя, например доставка или закупки. И чтобы свести всю свою деятельность в единую систему, в свободное от работы время я создал базу (excel), которая собрала в кучу всю мою старую и новую деятельность. Эта база не дала мне запутаться в огромном количестве работы. Так же она помогла избавиться от блокнотов и стикеров, а это значит, что покупатели всегда видели порядок за моим рабочим столом.
7) Что бы вы пожелали усовершенствовать в себе? Что вы для этого делаете? У меня есть хобби — программирование. Хочу совершенствовать свои навыки в этой области, они же в дальнейшем помогут улучшить мои навыки тестировщика.
8) Что вы ждете от нашей компании? Хороший коллектив, и профессиональное развитие
9) Какой минимальный доход вас устроит? Можно посмотреть средний доход по региону на эту вакансию и назвать его. Но, если вы проходите собеседование в 2 гис, то говорите что готовы работать бесплатно 24/7/365, как рекомендует Савин. Так как эта книга эталон для их отдела кадров и им будет приятно знать что вы ее уже прочитали.
10) Какими источниками вы пользуетесь для развития в этой областиМожно посмотреть в конец статьи и назвать все, что будет в списке «Источники, которые были использованы для написания статьи:»
11) Кем вы видите себя через 5 лет? Тут на ваш вкус.
В принципе все. У вас все получится. Главное:

Источники, которые были использованы для написания статьи: Роман Савин. Тестирование Дот Ком; — Wiki Тестирование программного обеспечения; — Флёнов Михаил. Язык запросов SQL; — Wiki sql; — Форум тестировщиков; — habrahabr.ru; — Книги для молодых тестировщиков.
