[Из песочницы] Data Mining. Оптимизация заказов товаров в аптеке (аптечном пункте)
В небольшом аптечном пункте существует потребность гибкой системы заказов лекарственных средств и пара-фармацевтических товаров чувствительной к постоянным колебаниям рынка. В рамках современной действительности одиночные аптечные пункты не обладают достаточными складскими помещениями (материальными комнатами), что накладывает свой отпечаток и заставляет человека, ответственного за заказы, делать их ежедневно из сводного прайс-листа по нескольким поставщикам, не допуская дублирования, по минимальным ценам, исключая товары с неподходящими сроками годности. При этом общая номенклатура составляет несколько десятков тысяч единиц.Мы живем в современном мире, где рутинные операции за нас выполняет компьютер. Поэтому Вы можете сказать: «Давайте используем компьютер, и он сделает всю черную работу за нас!». «У вас же есть база данных, содержащая статистику продаж различных лекарств?» — продолжите Вы — «Так почему же не использовать эту статистику для прогноза продаж и создания автоматической заявки на требуемые препараты? «Да, в первом приближении вы будете правы. Такие решения есть в программных комплексах, автоматизирующих аптеки в России. Но есть одно очень большое «НО». Все эти решения не будут корректно работать, пока Вы не создадите группы товаров.
Объясню: Есть препарат: «Донормил 15 мг Таб. Х30» производства Upsa Laboratoir Франция и «Донормил таб. 15 мг № 30» Aventis/Bristol-Myers Squibb — Франция. В базе данных это совершенно два разных препарата имеющих разный идентификатор и разное название, НО это одно и тоже. Если Вы будете учитывать статистику по этим двум разным товарам — то вы получите не правильный результат.
Для того чтобы получить достоверную информацию по движению и необходимости заказа товара необходимо создавать группы идентичных товаров. Как правило, создавать группы нужно вручную и обработать большое количество записей. Если есть выделенный сотрудник, который может в течение долгого периода времени работать над наполнением справочника «Группы товаров», то это более-менее реально (однако следует учитывать, что при поступлении новых товаров, справочник нужно постоянно дорабатывать). В рамках небольшого аптечного пункта, где обычно работают два-три человека за прилавком, такой возможности просто нет.
Встает вопрос: «Какие есть алгоритмы позволяющие находить одинаковые лекарственные препараты?». Первое, что приходит на ум — это расчет расстояния Левенштейна. Но тут мы сталкиваемся с ограничением данного алгоритма — расстояние Левенштейна для разных товаров «Линекс капс. х16» и «Линекс капс. х32» (расстояние равно двум), меньше чем у одинаковых товаров «Линекс капс. х16» и «Линекс N16 капс» (расстояние равно девяти). Проблема в том, что поставщики могут менять слова местами, заменять сокращения количества (кто-то пишет №, кто-то N, кто-то X), объема и т.п. Объединить одинаковые товары с помощью штрих кода невозможно. Одинаковые препараты, произведенные разными фабриками, имеют разный штрих код. Более того, один и тот же препарат, производимый на одном заводе, может иметь другой штрих код после прохождения перерегистрации.
После долгих поисков я пришел к следующему алгоритму поиска одинаковых препаратов:
1. Для первого приближения (поиска «похожих» препаратов) используется алгоритм N-Грамм. Этот алгоритм составляет все возможные комбинации подстрок, с длиной вплоть до указанной, и подсчитывает их совпадения. Количество совпадений, разделенное на число вариантов, объявляется коэффициентом схожести строк для фиксированного N (я выбрал значение 3) и выдается в качестве результата работы функции.
Например, для «Линекс капс N16» и «Линекс N16 капс», строки разбиваются на 3-граммы:
Сравниваемая подстрока Подстроки второй строки Совпадения Кол-во совпадений Кол-во вариантов Коэффициент похожести Лин Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да ине Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да нек Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да eкс Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да кс Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да 11 13 с к Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Нет ка Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да кап Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да апс Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да пс Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Нет с N Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да N1 Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да N16 Лин, ине, нек, екс, кс, с N, N1, N16,16,6 к, ка, кап, апс Да (11+12)/(13+13)=0,88 Лин Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да ине Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да нек Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да екс Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да кс Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да с N Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да N1 Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да 12 13 N16 Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да 16 Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да 6 к Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Нет ка Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да кап Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да апс Лин, ине, нек, екс, кс, с к, ка, кап, апс, пс, с N, N1, N16 Да Результат равен 0,88.
Таким образом, мы объединяем препараты, для которых ключевые слова поменяны местами. Однако у данного алгоритма есть два недостатка: а) Алгоритм объединяет препараты с «x10» и «x20», «г.» и «мг.» и т.д.; б) Резко возрастает нагрузка на базу данных — словарь грамм занимает очень большой объем. Например, для справочника товарно-материальных ценностей объемом примерно 30 тысяч записей, словарь 3-грамм содержит 900 тысяч записей. Для прайса в 47 тысяч записей (объединенный прайс от нескольких поставщиков), словарь содержит уже 1,7 миллиона записей.
2. Для окончательного наполнения справочника «Группы товаров» (после которого требуется работа человека) исходный справочник материальных ценностей разбивается на словарь слов. Создается мета-справочник «ключевых» свойств препаратов: а) Объем; б) Количество; в) Количество активного вещества; г) Лекарственное вещество; д) Цвет, вкус; и т.д.
Мета-справочник, содержит данные о синонимах, соответствиях (например: г = 1000 мг) и способе поиска свойств в словаре. Исключив среди «похожих» препаратов (результат работы первого алгоритма) препараты для которых различаются «ключевые» свойства мы получим справочник «Группы товаров».
Указанный алгоритм позволяет автоматически наполнить справочник «Группы товаров», который уже в дальнейшем редактируется пользователем.
Следующий вопрос, который я должен был решить, был вопрос «какой алгоритм предсказания» использовать? Поскольку я не хотел использовать сложные и ресурсоемкие алгоритмы и к тому же аптека работает только первый год (отсутствует сезонность), я выбрал алгоритм Двойного экспоненциального сглаживания.
Формулы выглядят так:
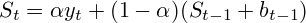
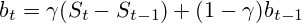
где 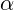 и
и  принимают значения из диапазона [0;1]y — реальное количество продаж;
принимают значения из диапазона [0;1]y — реальное количество продаж;

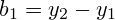
Для прогнозирования следующего значения используется формула: 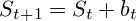 Для прогнозирования нескольких значений:
Для прогнозирования нескольких значений: 
Как мы видим, для расчета прогноза нужно знать значение двух переменных — и . Оптимальные значения и выбирается из минимума квадратичной ошибки прогноза (сумма квадратов разницы количества реально проданного товара и прогноза). Таким образом, перед нами стоит классическая задача поиска минимума функции нескольких переменных с линейными ограничениями.
В школе, когда я только изучал Fortram, Папа купил книгу Дж. Форсайта «Машинные методы математических вычислений». Помню свое удивление от первого знакомства с вычислением с плавающей точкой, понятие «Машинное эпсилон». Вспомнив, про эту книгу, я нашел в ней алгоритм поиска минимума, но только для функции одной переменной. Для функции нескольких переменных автор отсылал читателя к недоделанному (1977 год, на момент написания книги) пакету MINPACK из Национальной лаборатории в Аргоне. Представляете мое удивление, когда я нашел данный пакет, написанный на Fortran’е, нашел пакет MINPACK C/C++ и пообщался с автором «перевода» с Fortran’а на C.
На сегодняшний момент для прогноза продаж лекарств, мною реализован программный комплекс, состоящий: а) Библиотеки для MS SQL сервера (dll), реализованной в виде расширенных хранимых процедур, написанных на C++ и реализующих расчет прогноза; б) Базы данных MS SQL сервера, содержащей справочники словарей, метаданные и хранимые процедуры: расчета прогноза, сопоставления товарно-материальных ценностей и прайс-листа и другие.в) Клиента, в котором пользователь делает прогноз, работает со справочниками и прайс-листами.
Внедрение программного комплекса в разы ускорило работу по заказу товаров и повысило эффективность работы аптеки. И что более главное — вернуло жену в семью!
Реализованный мною программный комплекс жестко привязан к одному вендору, автоматизирующему аптечный бизнес на территории России. Используя универсальность подхода, можно реализовать аналогичное решение и для других программных продуктов. Указанный алгоритм можно применить не только в аптечном бизнесе, но и в любом другом, где есть большая номенклатура однотипных товаров, и есть необходимость в объединении справочника товарно-материальных ценностей и прогнозе продаж в условиях жесткой конкуренции и постоянного изменения рынка.
