[Из песочницы] Сравнение скорости построения линейных моделей в R и Eviews
Если Вам необходимо оценить эконометрическую модель с небольшим количеством наблюдений, то софт, в котором это можно сделать определяется исключительно Вашими предпочтениями и финансовыми возможностями. Но если количество наблюдений большое? Регрессия не всегда оценивается в одно мгновение. В этом посте я сравниваю время оценки линейной регрессии в R и Eviews в зависимости от количества наблюдений.Для проведения этого теста будем использовать простую линейную регрессию: yi= 10 + 5xi + εi
Количество наблюдений N в регрессии будем менять и сравнивать время оценки для каждого. Я взял N oт 100 000 до 10 000 000 с шагом в 100 000.
Что из этого получилосьРезультаты R (Линейная и логарифмическая модели)
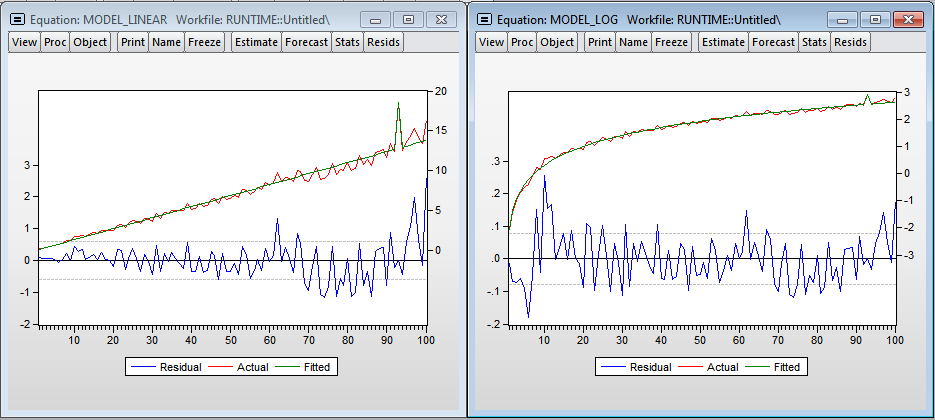
Я добавил переменную dum — дамми на одно из наблюдений (видно выброс на графике, в этот момент мне нужно было открыть браузер). Как и ожидалось, количество наблюдений значимо влияет на время построения регрессии. Мультипликативная модель дает более красивые результаты. Даже есть намёк на нормальность остатков в регрессии. По линейной модели получаем, что каждый дополнительный миллион наблюдений увеличивает время построения на 1.39 секунды, а модель в логарифмах показывает эластичность количества наблюдений по времени 1.014 (т.е. если количество наблюдений увеличится на 1%, то время расчета регрессии увеличится на 1.014%).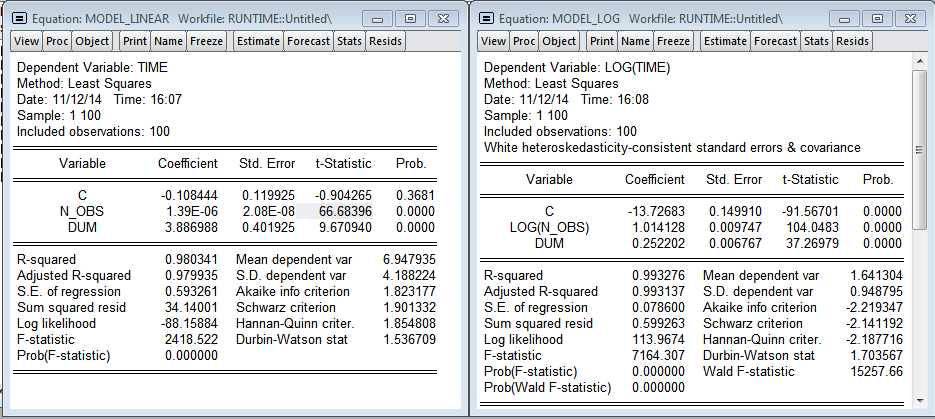
Гистограммы остатков
Визуально гистограммы остатков моделей не похожи на нормальное распределение, а значит оценки, полученные в моделях смещенные, т.к., скорее всего, не учитываем значимую переменную — уровень загрузки процессора. Тем не менее в логарифмической модели можно принять гипотезу о нормальности (т.к. критическое значение тестовой статистики Харки-Бера 8.9% и превышает стандартный критический уровень значимости в 5%).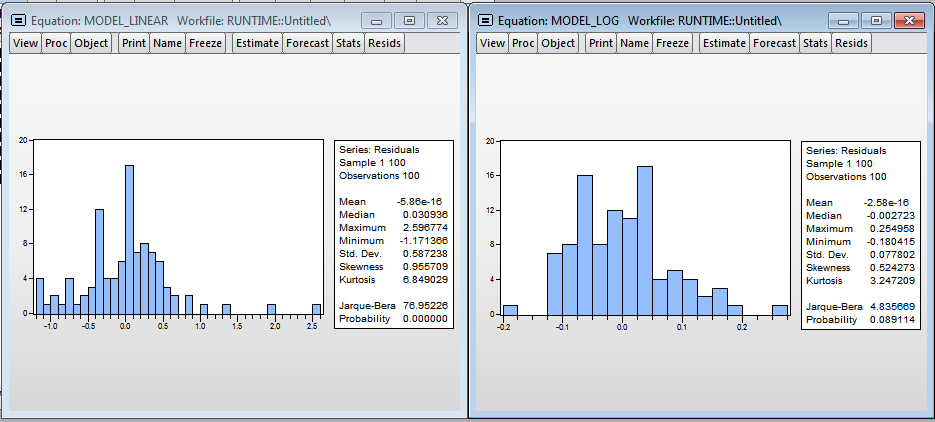
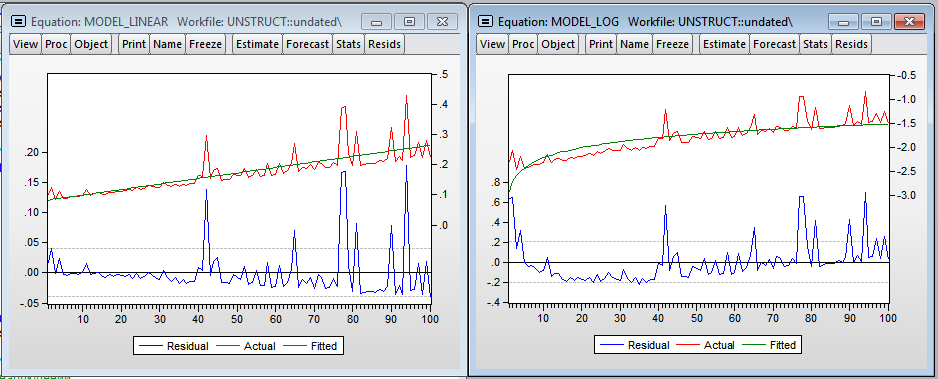
Результаты Eviews (Линейная и логарифмическая модели)
Модели, полученные в Eviews не так качественно описывают зависимость времени построения от количества наблюдений. Линейная модель предсказывает, что дополнительный миллион наблюдений увеличит время оценивания модели на 0.18 секунд (в 75.8 раз меньше, чем в R). В логарифмической модели эластичность — 0.306 (в 3.3 раза меньше чем в R)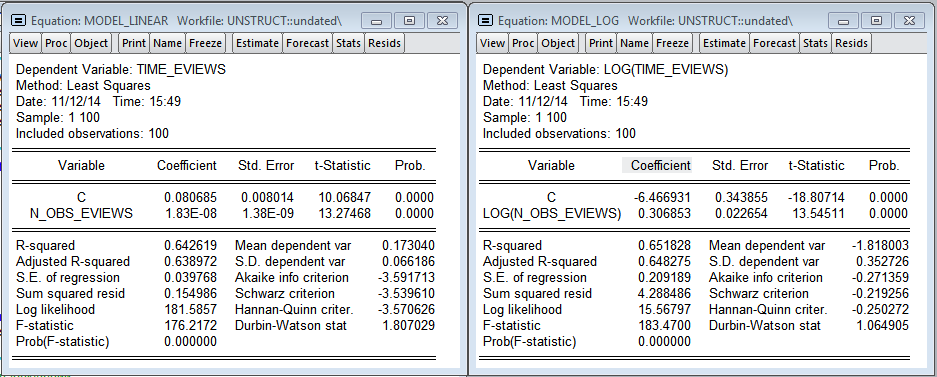
На графиках видно значительное количество выбросов, что, скорее всего, говорит о намного более значимом влиянии загрузки процессора на время вычисления в Eviews. Присутствует гетероскедастичность в ошибках, что свидетельствует в пользу включения переменной — уровня загрузки процессора в модель. Нужно отметить, что Eviews практически не потребляет оперативную память, в то время как R кумулятивно увеличивает объем потребляемой памяти для своих нужд и не освобождает ее до закрытия программы.
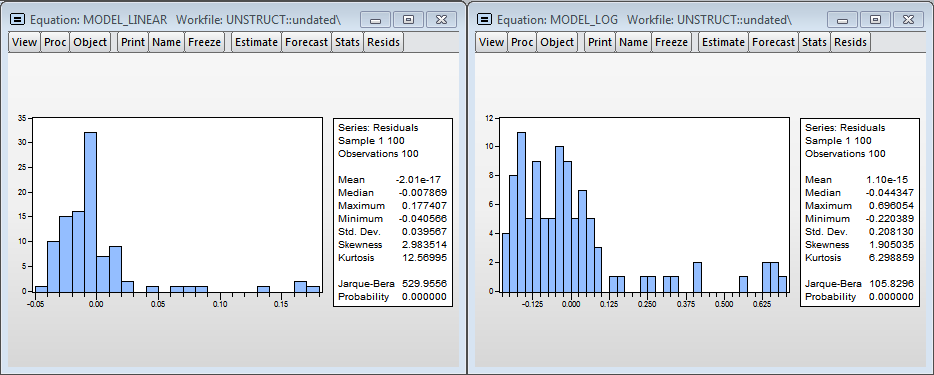
Опять же, остатки в моделях не нормальные, нужно добавлять ещё переменных.
В конце хочу сказать, что не стоит сразу записывать это в R как минус. Возможно, такое разное время вычисления получилось потому, что функция lm (), которую я использовал в R создает большой объект типа lm в котором содержится много информации об оцененной модели и для 100 000 наблюдений уже весит около 23 Mb, который опять же, хранится в оперативной памяти. Если вам будет интересно можно повторить похожий тест, используя какие-либо другие функции из R или, например, реализовать алгоритм gradient descent, о котором можно посмотреть здесь.
Код в R library (ggplot2)
#Создаем векторы, которые будут содержать кол-во наблюдений и время выполнения N <- seq(100000,10000000, by = 100000) time.vector <- rep(0,length(N))
#Строим линейную регрессию для каждого кол-ва наблюдений из вектора N и запоминаем время построения count = 1 for (n in N) { X <- matrix(c(rep(1,n),seq(1:n)),ncol = 2) y <- matrix(X[, 1] * 10 + 5 * X[, 2] + rnorm(n,0,1))
t <- Sys.time() lm1 <- lm(y ~ 0 + X) t1 <- Sys.time() lm1.time <- t1 - t time.vector[count] <- lm1.time count <- count + 1 }
#Рисуем картинку и записываем данные в файл times <- data.frame(N,time.vector) names(times) <- c('N_obs','Time') ggplot(data = times, aes(N_obs, Time, size = 2)) + geom_point() write.csv(times,'times.csv') Код в Eviews 'Создаем workfile, вектор кол-ва наблюдений и времени исполнения wfcreate(wf=unstruct, page=undated) u 10000000 scalar time_elapsed = 0 series time_eviews = 0 series n_obs_eviews = 0
'Строим линейную модель, такую же как в R, по таким же кол-вам наблюдений, запоминаем время построения for! n = 1 to 100 smpl @first @first + ! n * 100000 — 1 series trend = @trend+1 series y = 10 + 5 * trend + nrnd tic equation eq1.ls y c trend time_elapsed = @toc smpl @first + ! n — 1 @first + ! n — 1 time_eviews = time_elapsed n_obs_eviews = ! n * 100000 next smpl @first @first + 99
'Оцениваем линейную и логарифмическую модели времени от кол-ва наблюдений equation model_linear.ls time_eviews c n_obs_eviews show model_linear
equation model_log.ls log (time_eviews) c log (n_obs_eviews) show model_log
