[Из песочницы] Сравнение алгоритмов распознавания аудио для Second Screen
Введение
На сегодняшний день существует множество методов распознавания звука. В самом общем виде большинство методов состоят из алгоритма построения сигнатуры (fingerprints) сигнала (максимально компактного и при этом наиболее точно описывающего трек набора признаков), алгоритма ее поиска в базе данных и алгоритма отсечения ложных срабатываний. Перед нами стояла задача выбора технологии для построения second screen приложений. При этом сравнение алгоритмов распознавания на основе известных точностных характеристик является довольно условным, поскольку эти характеристики получены на разных тестовых данных и при разных ошибках первого рода (false positives). Также, исходя из контекста задачи, нас интересовала эффективность алгоритма применительно к распознаванию аудиосигнала телеэфира, при искажениях обусловленных параметрами микрофонов современных мобильных устройств.Поскольку в открытых источниках сравнительных данных, удовлетворяющих нашим требованиям, найдено не было, было решено провести собственное исследование алгоритмов распознавания звука, с учетом специфики аудиопотока и искажений. В качестве потенциальных кандидатов мы остановили свой выбор на алгоритмах J. Haitsma и A. Wang. Оба широко известны и основаны на анализе частотно-временных признаков, полученных с помощью оконного преобразования Фурье.
При этом сравнение алгоритмов распознавания на основе известных точностных характеристик является довольно условным, поскольку эти характеристики получены на разных тестовых данных и при разных ошибках первого рода (false positives). Также, исходя из контекста задачи, нас интересовала эффективность алгоритма применительно к распознаванию аудиосигнала телеэфира, при искажениях обусловленных параметрами микрофонов современных мобильных устройств.Поскольку в открытых источниках сравнительных данных, удовлетворяющих нашим требованиям, найдено не было, было решено провести собственное исследование алгоритмов распознавания звука, с учетом специфики аудиопотока и искажений. В качестве потенциальных кандидатов мы остановили свой выбор на алгоритмах J. Haitsma и A. Wang. Оба широко известны и основаны на анализе частотно-временных признаков, полученных с помощью оконного преобразования Фурье.
Описание рассматриваемых методов построения сигнатур
Схема построения сигнатуры аудиосигнала, предложенная Jaap Haitsma и Ton Kalker в работе [1], приведена на рисунке 1. В таблице 1 показаны образы, получаемые на каждом этапе алгоритма.
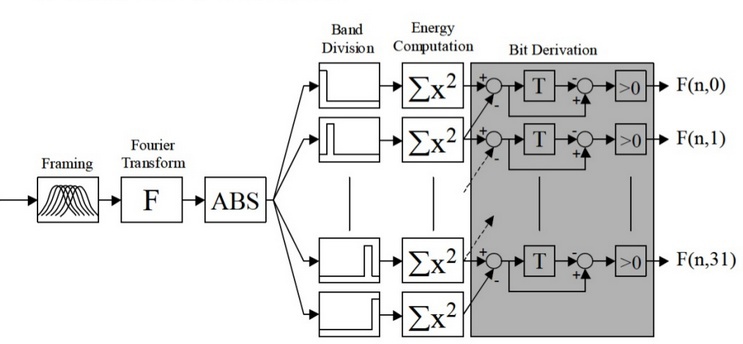 Рисунок 1 — Схема построения сигнатуры Jaap Haitsma и Ton Kalker
Спектрограмма сигнала строится с использованием окна Ханна с перекрытием 31/32. Например, для размера окна 0,37 с шаг дискретизации спектрограммы по оси времени равен 11,6 мс. На следующем этапе алгоритм делит частотную ось на 33 поддиапазона в mel масштабе, и для каждого момента времени вычисляется суммарная энергия в поддиапазоне. Полученное временное распределение энергии кодируется в соответствии с выражением:
Рисунок 1 — Схема построения сигнатуры Jaap Haitsma и Ton Kalker
Спектрограмма сигнала строится с использованием окна Ханна с перекрытием 31/32. Например, для размера окна 0,37 с шаг дискретизации спектрограммы по оси времени равен 11,6 мс. На следующем этапе алгоритм делит частотную ось на 33 поддиапазона в mel масштабе, и для каждого момента времени вычисляется суммарная энергия в поддиапазоне. Полученное временное распределение энергии кодируется в соответствии с выражением: 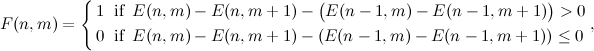 где
где 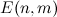 — энергия
— энергия 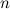 -го фрейма в поддиапазоне
-го фрейма в поддиапазоне  .Таблица 1 — Основные этапы построения сигнатуры Jaap Haitsma и Ton Kalker
.Таблица 1 — Основные этапы построения сигнатуры Jaap Haitsma и Ton Kalker
Таким образом, каждый интервал сигнала в 11,6 мс описывается 32-битным словом. Как показали экспериментальные исследования [1], для надежного и устойчивого ко многим видам искажений распознавания достаточно 256 слов, что соответствует 3 секундному запросу.Подход к распознаванию, предложенный Avery Li-Chun Wang [2], основан на пиках амплитуды спектрограммы и их связях в пары, называемые созвездиями.
Основная трудность в реализации данного подхода заключается в алгоритме поиска пиков, устойчивых к искажениям. В работах [3, 4] представлены примеры соответствующих методик. Среди множества локальных максимумов спектрограммы выбираются пики с максимальной энергией. При этом, чтобы описание трека было устойчиво к шумам, необходимо обеспечить их разнообразие по частоте и по времени. Для этого используются различные техники размытия и порогового отсечения [3, 4]. Спектрограмма аудиотрека, как правило, разбивается на фреймы по оси времени, каждый из которых характеризуется определенным количеством пиков. Ограничивая таким образом их плотность, удается оставить пики с максимальной вероятностью выживания, и при этом детально описать изменение спектра во времени. В качестве примера в таблице 2 представлены образы, получаемые на основных этапах алгоритма.
Таблица 2 — Основные этапы построения сигнатуры предложенной A. Wang
Для ускорения процесса поиска пики объединяются в пары — каждый пик связывается с некоторым количеством других пиков, расположенных правее по оси времени в рамках определенной целевой зоны. Коэффициент ускорения приближенно оценивается уравнением: 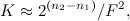 где
где 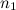 и
и 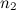 — количество бит, требуемое для кодирования пика и их пар соответственно;
— количество бит, требуемое для кодирования пика и их пар соответственно; 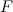 — количество пиков, связываемых с опорным (коэффициент разветвления).При этом увеличение уникальности хеша сопровождается уменьшением вероятности его выживания, которая приближенно оценивается как:
— количество пиков, связываемых с опорным (коэффициент разветвления).При этом увеличение уникальности хеша сопровождается уменьшением вероятности его выживания, которая приближенно оценивается как:
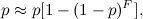 где
где 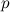 — вероятность выживания пика спектрограммы.Следовательно, необходимо найти значения плотности пиков и коэффициента разветвления , обеспечивающего компромисс между скоростью поиска и вероятностью распознавания сигнала.Сигнатура сигнала состоит из двух компонентов: хеш пары и кода ее смещения по оси времени. Минимальное количество бит, необходимое для кодирования пары определяется уравнением:
— вероятность выживания пика спектрограммы.Следовательно, необходимо найти значения плотности пиков и коэффициента разветвления , обеспечивающего компромисс между скоростью поиска и вероятностью распознавания сигнала.Сигнатура сигнала состоит из двух компонентов: хеш пары и кода ее смещения по оси времени. Минимальное количество бит, необходимое для кодирования пары определяется уравнением:
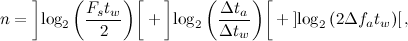 где
где 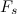 — частота дискретизации сигнала;
— частота дискретизации сигнала; 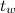 ,
, 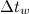 — размер и шаг окна, используемого при построении спектрограммы;
— размер и шаг окна, используемого при построении спектрограммы;  ,
,  — соответственно максимально допустимое расстояние по оси времени и оси частот между пиками пары;
— соответственно максимально допустимое расстояние по оси времени и оси частот между пиками пары;  — взятие ближайшего наибольшего целого числа.Результаты экспериментального исследования
Исходя из области использования, сравнение рассмотренных выше подходов распознавания проводилось на базе аудиотреков теле эфира суммарной длительностью 2000 мин. В качестве тестовых сигналов использовались записи оригинальных треков, воспроизведенных на телевизоре и записанных на мобильные устройства iPhone 4, Nexus 7, Samsung GT3100 на разных удалениях от источника сигнала при наличии посторонних шумов, свойственных окружающей обстановке. Тестовые моносигналы имели частоту дискретизации 8 кГц при кодировании амплитуды 16 битами. Из них были сформированы 2000 тестовых запросов длительностью 4 с.При использовании сигнатуры J. Haitsma поиск осуществлялся методом brute force — непосредственным сравнением запроса с каждым фрагментом в базе данных на основе метрики Хэмминга. Запрос считался найденным, если при побитовом сравнении его сигнатура и сигнатура найденного фрагмента совпадали более чем на 65%.
— взятие ближайшего наибольшего целого числа.Результаты экспериментального исследования
Исходя из области использования, сравнение рассмотренных выше подходов распознавания проводилось на базе аудиотреков теле эфира суммарной длительностью 2000 мин. В качестве тестовых сигналов использовались записи оригинальных треков, воспроизведенных на телевизоре и записанных на мобильные устройства iPhone 4, Nexus 7, Samsung GT3100 на разных удалениях от источника сигнала при наличии посторонних шумов, свойственных окружающей обстановке. Тестовые моносигналы имели частоту дискретизации 8 кГц при кодировании амплитуды 16 битами. Из них были сформированы 2000 тестовых запросов длительностью 4 с.При использовании сигнатуры J. Haitsma поиск осуществлялся методом brute force — непосредственным сравнением запроса с каждым фрагментом в базе данных на основе метрики Хэмминга. Запрос считался найденным, если при побитовом сравнении его сигнатура и сигнатура найденного фрагмента совпадали более чем на 65%.
Построение сигнатур на принципах Wang производилось при размере окна Ханна 64 мс, со сдвигом 32 мс. Был реализован собственный вариант поиска пиков спектрограммы, более удачно подходивший для распознавания аудиосигнала телеэфира по сравнению с прототипом [3]. Фрагмент длительностью 4 с в среднем характеризовался 200 пиками и описывался 1000 парами. Для принятия решения использовалась формализация понятия уникальности пика на графике оценок (score) за каждый вариант ответов, имеющихся в базе данных. Запрос считался распознанным, если score был уникальным.
В таблице 3 показаны результаты точности полученных алгоритмов распознавания. Аудиофрагмент считался правильно распознанным, если был верно определен оригинальный трек и смещение запроса в нем.
Таблица 3 — Сравнение точности алгоритмов распознавания
Алгоритм Мобильное устройство iPhone 4 Nexus 7 Samsung GT3100 fp, % fn, % fp, % fn, % fp, % fn, % J. Haitsma, T. Kalker 0,6 8 0,6 10 0,5 9 На принципах A. Wang 0,6 20 0,6 25 0,6 24 Примечание: fp — ошибки первого рода (false positives); fn — ошибки второго рода (false negatives). Заключение Алгоритм J. Haitsma использует интегральный подход для описания распределения энергии по поддиапазонам частот, дифференциальный подход для кодирования ее изменения в овремени, а также сравнение сигнатур на основе расстояния Хэмминга. Всё это делает данный метод потенциально устойчивым к искажениям. В то время как доля совпавших пар пиков спектрограммы колеблется от 1% до 3%, что не лучшим образом сказывается на помехоустойчивости и приводит к потери в вероятности распознавания.Однако для использования всего потенциала сигнатур J. Haitsma поиск запроса в базе необходимо осуществлять методом brute force. Наша реализация алгоритма для GPU на видеокарте Radeon R9 290X обеспечивает параллельный поиск 2048 запросов за 0,6 с. Написанный с использованием библиотеки libevent сервер позволяет выдерживать нагрузку 1900 rps, при среднем времени ответа 0,8 с. При этом промышленные видеокарты дороги, а обычные приходится ставить в стандартные корпуса ATX, которые имеют размер минимум 3 unit. В одном таком корпусе у нас получилось разместить две карты. В то же время наша реализация сервера распознавания на принципах A. Wang, на машине Xeon® CPU E5–2660 v2 @ 2.20GHz/32Gb выдерживает нагрузку 2500 rps при среднем времени ответа 8 мс.
Хотелось бы отметить, что мы не исключаем возможности получения более оптимальных реализаций алгоритмов, и к полученным результатам следует относиться как к оценочным, не претендующим на абсолютность.
Список литературы Jaap Haitsma, Ton Kalker «A Highly Robust Audio Fingerprinting Syste» Avery Li-Chun Wang «An Industrial-Strength Audio Search Algorithm» D. Ellis «Robust Landmark-Based Audio Fingerprinting» Е. Крофто «Как Яндекс распознаёт музыку с микрофона»
