[Из песочницы] Создание приложений с помощью Mediapipe
Сегодня множество сервисов используют в своей работе нейросетевые модели. При этом из-за невысокой производительности клиентских устройств вычисления в большинстве случаев производятся на сервере. Однако производительность смартфонов с каждым годом растет и сейчас становится возможным запуск небольших моделей на клиентских устройствах. Возникает вопрос: как это сделать? Помимо запуска модели требуется выполнять предобработку и постобработку данных. К тому же, есть как минимум две платформы, где это нужно реализовать: android и iOS. Mediapipe — фреймворк для запуска пайплайнов (предобработка данных, запуск (inference) модели, а также постобработка результатов модели) машинного обучения, позволяющий решить описанные выше проблемы и упростить написание кроссплатформенного кода для запуска моделей.

- Обзор системы сборки Bazel
- Фреймворк Mediapipe
- Что такое Mediapipe. Из чего состоит и зачем нужен
- HelloWorld приложение на Mediapipe
- Запуск модели с помощью Mediapipe
- Создание приложения с помощью Mediapipe
- Заключение
В Mediapipe для сборки используется Bazel. Я столкнулся с этой системой сборки впервые, поэтому параллельно с Mediapipe разбирался c Bazel, собирая информацию с разных источников и наступая на грабли. Поэтому, перед тем, как рассказать о самом Mediapipe, мне хотелось бы дать небольшое введение по системе сборки Bazel, которая используется для сборки Mediapipe и проектов на его основе. Bazel — система сборки от Google, доработанная версия их внутренней системы сборки Blaze, выложенная в общий доступ. Bazel позволяет в одном проекте объединять различные языки и фреймворки простой командой:
bazel build TARGETКак система сборки понимает, какой именно инструмент необходимо использовать для того или иного таргета? Для начала необходимо понять, из чего складывается Bazel-проект. Главным файлом проекта является текстовый файл WORKSPACE, в котором указываются все зависимости проекта. Говоря обо всех зависимостях, подразумеваются транзитивные зависимости тоже. Иными словами, если проект зависит от A, который зависит от B, то необходимо будет указать в WORKSPACE файле как зависимость от A, так и от B. Из-за этого WORKSPACE может сильно разрастаться, что можно будет заметить в дальнейшем примере работы с Mediapipe. Разработчики Bazel объясняют такое решение тем, что при изменении у прямых зависимостей проекта их зависимостей, которые используются в текущем проекте, проект может ломаться и искать проблему становится очень сложно, поэтому требуется явно указать всё, от чего зависит проект. Вот как может выглядить пример файла WORKSPACE:
# Загрузка правила для получения зависимостей скачиванием
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")
# Скачивание зависимости с набором правил для сборки c++
http_archive(
name = "rules_cc",
strip_prefix = "rules_cc-master",
urls = ["https://github.com/bazelbuild/rules_cc/archive/master.zip"],
)
# Скачивание зависимости googletest
http_archive(
name = "com_google_googletest",
strip_prefix = "googletest-master",
urls = ["https://github.com/google/googletest/archive/master.zip"],
)Файл состоит из правил (bazel rule). Каждое из этих правил — функция на языке Starlark. Расширяемость и универсальность Bazel обеспечивается за счет возможности написания правил, с помощью которых можно добавлять в систему сборки новые возможности, новые языки и экосистемы. Например, в указанном выше примере сначала загружается правило http_archive для загрузки зависимостей, а затем с помощью http_archive загружается набор правил для сборки C++ проектов и библиотека googletest.
Помимо файла WORKSPACE любой Bazel проект содержит некоторое количество файлов BUILD. BUILD файл описывает директорию, в которой он находится, как модуль и содержит описание таргетов для сборки. Вот так выглядит BUILD файл для сборки C++ проекта с одним файлом:
cc_binary(
name="HelloWorld",
srcs=["main.cpp"],
copts=["-Wall", "-Wpedantic", "-Werror"]
)В данном случае используется единственное правило, создающее таргет для сборки, которое было загружено в файле WORKSPACE с помощью http_archive. Для получения простого Bazel-проекта досточно добавить файл с исходным кодом main.cpp.
- ./WORKSPACE
- ./Source/BUILD
- ./Source/main.cpp
Для сборки этого проекта достаточно выполнить команду
bazel build //Source:HelloWorldгде Source — модуль, HelloWorld — таргет в модуле.
Правило вызовет cmake, результат сборки (исполняемый файл) будет расположен в ./bazel-bin.
Добавлять всё зависимости и исходники таргета в одно правило часто может быть затруднительно, правила могут разрастаться и быть трудноподдерживаемыми, а также много кода может дублироваться. Для решения данной проблемы в Bazel есть библиотеки (libraries).
cc_library(
name = "lib",
hdrs = ["utils.h"],
srcs = ["utils.cpp"],
visibility = [
"//visibility:public",
],
)
cc_binary(
name="HelloWorld",
srcs=["main.cpp"],
deps=[":lib"],
copts=["-Wall", "-Wpedantic", "-Werror"]
)Библиотеки могут располагаться как в одном BUILD файле, так и в разных модулях или в разных проектах. Чтобы указать зависимость от модуля в другом проекте, необходимо до // написать название проекта
@some_repository//Module:libBazel содержит набор встроенных правил, подходящих для большинства случаев. Помимо http_archive, зависимости можно добавлять с помощью git_repository, local_repository и др.
Mediapipe — кроссплатформенный фреймворк для запуска пайплайнов машинного обучения. Сам пайплайн задается в форме графа, граф состоит из следующих элементов (в скобках указывается оригинальный термин):
- Вершины графа (Calculators) — это некоторые преобразования для данных (пакетов). У каждого калькулятора должен быть как минимум один входящий и как минимум один исходящий поток. Калькулятор представляет из себя C++ класс, реализующий интерфейс CalculatorBase:
static Status GetContract(CalculatorContract*);— статический метод, в котором калькулятор описывает форматы данных, которые ждет на вход и готов отдать на выход.Status Open(CalculatorContext*);— инициализация калькулятора при создании графа. Здесь, например, может быть загрузка данных, требуемых для работы.Status Process(CalculatorContext*);— обработка поступившего пакета.Status Close(CalculatorContext*);— закрытие вершины.
- Ребра графа (Streams) задают связи между калькуляторами. С помощью потоков по графу перемещаются пакеты с данными. Поток может быть внутренний, входной (input) и исходящий (output). Внутренний поток соединяет два калькулятора, по входному потоку из внешнего кода в граф попадают данные, а с помощью исходящего потока граф отправляет данные наружу, в вызывающий код.
- Пакет (Packet) — единица данных, перемещаемая по потокам и обрабатываемая калькулятором. Каждый пакет несёт в себе данные определенного типа — это может быть строка, целое число, массив чисел с плавающей запятой или пользовательский тип, описанный и сериализуемый в protobuf. Каждый пакет содержит в себе timestamp — отметку времени, ассоциированную с пакетом. Необходима для того, чтобы отличать, какой пакет был раньше, какой позже, напрямую с реальным временем не связано.
Графы описываются в формате protobuf.
Mediapipe позволяет из калькуляторов составлять необходимый пайплайн для запуска модели, а затем просто встраивать его в приложения на разных платформах. Сейчас разработчики заявляют о поддержке нескольких дистрибутивов Linux, WSL, MacOS, Android, iOS. В Mediapipe есть встроенные калькуляторы для запуска TensorFlow и TFLite моделей. Поддержки других фреймворков машинного обучения сейчас нет, но так как можно создавать собственные калькуляторы и встраивать их в граф, то возможность добавления поддержки других фреймворков есть.
Далее на примерах показано, как использовать Mediapipe. Здесь будут разобраны самые примитивные примеры, показывающие решение упрощенных учебных задач. Более сложные и практические примеры есть в репозитории Mediapipe, но разбираться с нуля по ним может быть сложно, полезно начинать с чего-то максимально простого.
Для начала мы рассмотрим самый простой граф, состоящий из одного калькулятора, который повторяет N раз пакет, полученный на вход.

Проект содержит описание графа в .pbtxt файле, реализацию калькулятора и код приложения в main.cpp.
├── hello-world
│ ├── BUILD
│ ├── graph.pbtxt
│ ├── main.cpp
│ ├── RepeatNTimesCalculator.cpp
│ └── RepeatNTimesCalculator.proto
└── WORKSPACEКонфигурация графа выглядит следующим образом:
input_stream: "in"
output_stream: "out"
node {
calculator: "RepeatNTimesCalculator"
input_stream: "in"
output_stream: "OUTPUT_TAG:out"
node_options: {
[type.googleapis.com/mediapipe_demonstration.RepeatNTimesCalculatoOptions] {
n: 3
}
}
}Калькулятор RepeatNTimesCalculator написать достаточно просто. Для этого необходимо реализовать GetContract, в котором будет указан тип входных и выходных пакетов, Open, в котором загружается количество повторений из конфигурации графа, а также метод Process, выполняющий повторение поступившего на вход пакета.
class RepeatNTimesCalculator : public mediapipe::CalculatorBase {
public:
static mediapipe::Status GetContract(mediapipe::CalculatorContract* cc) {
// На вход ожидается поток без тега с пакетами, содержащими строки
cc->Inputs().Get("", 0).Set();
// Из калькулятора выходит поток с тегом OUTPUT_TAG, в котором пакеты со строками
cc->Outputs().Get("OUTPUT_TAG", 0).Set();
return mediapipe::OkStatus();
}
mediapipe::Status Open(mediapipe::CalculatorContext* cc) final {
// Загрузка параметров калькулятора, указанных при описании графа
const auto& options = cc->Options();
// n - количество повторений входного сигнала на выходе
n_ = options.n();
return mediapipe::OkStatus();
}
mediapipe::Status Process(mediapipe::CalculatorContext* cc) final {
// Получение текста из входного пакета
// Из массива входных потоков берется поток без тега с нулевым индексом
// И из него достается содержимое типа std::string
auto txt = cc->Inputs().Index(0).Value().Get();
for (int i = 0; i < n_; ++i) {
// Создание пакета с содержимым из входного
auto packet = mediapipe::MakePacket(txt).At(cc->InputTimestamp() + i);
// Отправка пакета по потоку с тегом OUTPUT_TAG и индексом 0
cc->Outputs().Get("OUTPUT_TAG", 0).AddPacket(packet);
}
return mediapipe::OkStatus();
}
private:
int n_;
};
// Макрос для регистрации калькулятора
REGISTER_CALCULATOR(RepeatNTimesCalculator); Весь класс располагается в .cpp файле, заголовочный файл не требуется, регистрацию класса производит макрос REGISTER_CALCULATOR.
Помимо самого кода калькулятора нам необходимо определить proto-файл с конфигурацией калькулятора. В данном примере это RepeatNTimesCalculatoOptions, который используется для указания того, сколько раз необходимо повторить входной сигнал на выходе.
syntax = "proto2";
package mediapipe_demonstration;
import "mediapipe/framework/calculator_options.proto";
message RepeatNTimesCalculatoOptions {
extend mediapipe.CalculatorOptions {
optional RepeatNTimesCalculatoOptions ext = 350607623;
}
required int32 n = 2;
}Теперь достаточно запустить полученный граф в коде приложения:
mediapipe::Status RunGraph() {
// Загрузка графа из файла
std::ifstream file("./hello-world/graph.pbtxt");
std::string graph_file_content;
graph_file_content.assign(
std::istreambuf_iterator(file),
std::istreambuf_iterator());
mediapipe::CalculatorGraphConfig config =
mediapipe::ParseTextProtoOrDie(graph_file_content);
// Инициализация графа
mediapipe::CalculatorGraph graph;
MP_RETURN_IF_ERROR(graph.Initialize(config));
// Подписка на выходной поток
ASSIGN_OR_RETURN(mediapipe::OutputStreamPoller poller, graph.AddOutputStreamPoller("out"));
// Запуск графа
MP_RETURN_IF_ERROR(graph.StartRun({}));
// Отправка пакета на вход и закрытие входного потока
auto input_packet = mediapipe::MakePacket("Hello!").At(mediapipe::Timestamp(0));
MP_RETURN_IF_ERROR(graph.AddPacketToInputStream("in", input_packet));
MP_RETURN_IF_ERROR(graph.CloseInputStream("in"));
// Получение пакета на выходе
mediapipe::Packet packet;
while (poller.Next(&packet)) {
std::cout << packet.Get() << std::endl;
}
return graph.WaitUntilDone();
} Наконец, чтобы собрать всё воедино, необходимо написать BUILD файл с набором правил сборки для файла настроек калькулятора, исходного кода калькулятора и вызывающего кода.
load("@mediapipe_repository//mediapipe/framework/port:build_config.bzl", "mediapipe_cc_proto_library")
# Правило сборки для настроек калькулятора
proto_library(
name = "repeat_n_times_calculator_proto",
srcs = ["RepeatNTimesCalculator.proto"],
visibility = ["//visibility:public"],
deps = [
"@mediapipe_repository//mediapipe/framework:calculator_proto",
],
)
# Правило сборки для кода калькулятора
mediapipe_cc_proto_library(
name = "repeat_n_times_calculator_cc_proto",
srcs = ["RepeatNTimesCalculator.proto"],
cc_deps = [
"@mediapipe_repository//mediapipe/framework:calculator_cc_proto",
],
visibility = ["//visibility:public"],
deps = [":repeat_n_times_calculator_proto"],
)
# Правило сборки калькулятора. Указано название, список исходников и зависимости
cc_library(
name = "repeat_n_times_calculator",
srcs = ["RepeatNTimesCalculator.cpp"],
visibility = [
"//visibility:public",
],
deps = [
":repeat_n_times_calculator_cc_proto",
"@mediapipe_repository//mediapipe/framework:calculator_framework",
"@mediapipe_repository//mediapipe/framework/port:status",
],
alwayslink = 1,
)
# Правило сборки исполняемого файла, который будет запускать граф.
cc_binary(
name = "HelloMediapipe",
srcs = ["main.cpp"],
deps = [
"repeat_n_times_calculator",
"@mediapipe_repository//mediapipe/framework/port:logging",
"@mediapipe_repository//mediapipe/framework/port:parse_text_proto",
"@mediapipe_repository//mediapipe/framework/port:status",
],
)Сборка и запуск:
$ bazel-2.0.0 build --define MEDIAPIPE_DISABLE_GPU=1 //hello-world:HelloMediapipe
...
INFO: Build completed successfully, 4 total actions
$ ./bazel-bin/hello-world/HelloMediapipe
Hello!
Hello!
Hello!Данный пример демонстрирует пример запуска графа Mediapipe, однако не имеет отношения к запуску ML моделей.
Теперь рассмотрим, как с помощью Mediapipe запускать tflite модели на разных устройствах. Мы хотим сделать классификацию фотографий на телефоне и десктопе. Для этого возьмем готовую и сконвертированную сеть, обученную на ImageNet1k. В отличие от предыдущего пункта, дополнительных калькуляторов создавать не требуется, стандартных вполне достаточно. Проект состоит из двух приложений, а также файла модели и графа.
├── inference
│ ├── android/src/main/java/com/com/mediapipe_demonstration/inference
│ │ ├── AndroidManifest.xml
│ │ ├── BUILD
│ │ ├── MainActivity.kt
│ │ └── res
│ │ └── ...
│ ├── BUILD
│ ├── desktop
│ │ ├── BUILD
│ │ └── main.cpp
│ ├── graph.pbtxt
│ ├── img.jpg
│ └── mobilenetv2_imagenet.tflite
└── WORKSPACEГраф выглядит следующим образом:

input_stream: "in"
output_stream: "out"
node: {
calculator: "ImageTransformationCalculator"
input_stream: "IMAGE:in"
output_stream: "IMAGE:transformed_input"
node_options: {
[type.googleapis.com/mediapipe.ImageTransformationCalculatorOptions] {
output_width: 224
output_height: 224
}
}
}
node {
calculator: "TfLiteConverterCalculator"
input_stream: "IMAGE:transformed_input"
output_stream: "TENSORS:image_tensor"
node_options: {
[type.googleapis.com/mediapipe.TfLiteConverterCalculatorOptions] {
zero_center: false
}
}
}
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:image_tensor"
output_stream: "TENSORS:prediction_tensor"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "inference/mobilenetv2_imagenet.tflite"
}
}
}
node {
calculator: "TfLiteTensorsToFloatsCalculator"
input_stream: "TENSORS:prediction_tensor"
output_stream: "FLOATS:out"
}Граф содержит 4 калькулятора:
- Изменение размера входного изображения на 224×224.
- Нормализация на диапазон [-1, 1] (параметр калькулятора zero_center: false, по умолчанию нормализация проводится на [0, 1]), а затем преобразование из изображения в формате ImageFrame (представление изображения в Mediapipe, именно с этим форматом работает большинство калькуляторов, обрабатывающих изображения) в
TfLiteTensor(точнееstd::vectorразмера 1). Пакет с данными типа TfLiteTensor необходим следующему калькулятору (согласно егоGetContract), который выполняет запуск модели. - Запуск модели.
- Преобразование выходного тезнора
TfLiteTensorв вектор чиселstd::vector. Обратное преобразование для выдачи приложению массива чисел с предсказаниями.
Теперь достаточно запустить граф и отправить в него данные, так как все части составленного графа уже реализованы.
Запуск графа на десктопе похож на рассмотренный пример выше. Разница в предобработке входных данных и постобработке выходных. Ниже представлен код, загружающий фотографию, отправляющий ее в граф и выводящий индекс наиболее вероятного класса.
// Загрузка изображения
auto img_mat = cv::imread("./inference/img.jpg");
// Преобразование изображения в пакет
auto input_frame = std::make_unique(
mediapipe::ImageFormat::SRGB, img_mat.cols, img_mat.rows,
mediapipe::ImageFrame::kDefaultAlignmentBoundary);
cv::Mat input_frame_mat = mediapipe::formats::MatView(input_frame.get());
img_mat.copyTo(input_frame_mat);
auto frame = mediapipe::Adopt(input_frame.release()).At(mediapipe::Timestamp(0));
// Отправка пакета в граф
MP_RETURN_IF_ERROR(graph.AddPacketToInputStream("in", frame));
MP_RETURN_IF_ERROR(graph.CloseInputStream("in"));
// Получение результата их графа с выводом предсказания
mediapipe::Packet packet;
while (poller.Next(&packet)) {
auto predictions = packet.Get>();
int idx = std::max_element(predictions.begin(), predictions.end()) - predictions.begin();
std::cout << idx << std::endl;
} Теперь можем запустить код и проверить, что изображено на фотографии:

$ bazel-2.0.0 build --define MEDIAPIPE_DISABLE_GPU=1 //inference/desktop:Inference
...
INFO: Build completed successfully, 3 total actions
$ ./bazel-bin/inference/desktop/Inference
INFO: Initialized TensorFlow Lite runtime.
151151 метка в ImageNet соответствует «Chihuahua».
Теперь получим такое же поведение на смартфоне. Нам нужно написать Activity, которая при запуске (метод onCreate) загружает файл с графом, а затем инициализирует Mediapipe. В данном случае граф хранится в бинарном protobuf-представлении. В приложении есть кнопка, по нажатию на которую открывается галерея для выбора изображения. После выбора выполняется метод onActivityResult, который выбранную фотографию отправляет в граф. Также важно не забыть загрузить нативную Mediapipe библиотеку в конструкторе объекта-компаньона (статический конструктор).
class MainActivity : AppCompatActivity() {
val PICK_IMAGE = 1
var mpGraph: Graph? = null
var timestamp = 0L
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
this.setContentView(R.layout.activity_main)
val outputTv = findViewById(R.id.outputTv)
val button = findViewById Соберем приложение и загрузим его на смартфон для отладки:
$ bazel-2.0.0 mobile-install --start_app -c opt --config=android_arm64 //inference/android/src/main/java/com/mediapipe_demonstration/inference:InferenceВ приложении можно выбрать фото из галереи и предсказать, что же на фотографии изображено:

Результат аналогичен тому, который был получен для десктоп приложения.
В данном разделе приведены только участки кода, полный код примеров можно посмотреть на github
Более сложные и практические примеры расположены в репозитории Mediapipe
Теперь рассмотрим более практический пример. Представим сервис по распознаванию моделей автомобилей. Есть приложение, через которое можно сфотографировать авто и отправить на сервер. Есть сервер, который для присланной фотографии запускает модель классификации и отдает полученный результат на клиент. Количество пользователей растет, нагрузка на сервер тоже и требуется решать проблему производительности. Перед нами встает два варианта:
- Добавить еще мощности для сервера, докупить GPU, добавить несколько серверов;
- Перенести часть вычислений на клиент.
Выбираем второй вариант, для его реализации можно воспользоваться Mediapipe. Теперь приложение должно не только снимать автомобиль, но также находить его в кадре и переводить его в некоторый вектор чисел, потому что передавать по сети около тысячи чисел проще, чем целое изображение. Далее такой вектор будем называть дескриптором. Нам потребуется две модели: модель детекции автомобиля в кадре и модель для получения дескриптора из участка кадра, на котором первая модель обнаружила автомобиль.
За основу приложения может быть использован пример для Mediapipe, решающий задачу детекции. В качестве сети для получения дескрипторов возьмем классифицирующую сеть, обученную на ImageNet1k, дообучим её для классификации автомобилей на Stanford Cars Dataset. После этого дескриптор автомобиля можно будет получить перед первым полносвязным слоем. Схематичная схема сети:

На этапе обучения сеть оптимизируется через выход с logit-ами с помощью NLL loss. Затем «голову» сети можно откинуть и получать дескрипторы после mean pool.
Структура проекта включает в себя Android приложение, калькуляторы для Mediapipe, Mediapipe граф, модель для получения дескрипторов и серверный код.
.
├── Android/src/main/java/com/kshmax/objectrecognition
│ └── objectrecognition
│ ├── AndroidManifest.xml
│ ├── BUILD
│ ├── MainActivity.kt
│ ├── Models.kt
│ ├── ObjectDetectionFrameProcessor.java
│ └── res
│ └── ...
├── Calculators
│ ├── BoundaryBoxCropCalculator.cpp
│ ├── BUILD
│ ├── ClickLocation.proto
│ ├── DetectionFilterCalculator.cpp
│ ├── DetectionFilterCalculator.proto
├── Graphs
│ ├── BUILD
│ └── ObjectRecognitionGraph.pbtxt
├── Models
│ ├── BUILD
│ └── car_vectorizer.tflite
├── Server
│ ├── labels.npy
│ ├── server.py
│ └── vectors.npy
└── WORKSPACEMediapipe граф для приложения выглядит следующим образом:

Калькуляторы на белом фоне взяты из оригинального примера, а калькуляторы на голубом фоне добавлены мной.
Представленный граф гораздо объемнее, чем рассмотренные ранее. Это связано с тем, что данные стали потоковыми, предобработка и постобработка увеличилась. Частота видеопотока ограничивается производительностью модели детекции: пока сеть определяет автомобили на одном кадре, все последующие кадры откидываются. Это реализовано с помощью FlowLimiter и обратного ребра. На выход из графа в данной задаче поступает видеопоток с наложенными рамками машин. AnnotationOverlay накладывает на исходный кадр рамку, полученную в результате работы модели детекции. После этого кадр отправляется в приложение и выводится на экран.
В этот процесс был добавлен DetectionFilter, потому что в результате работы модели может быть много различных классов, а для решения задачи нужен только класс автомобиль. Для этого я написал калькулятор DetectionFilter, который на вход принимал массив детекшенов, а на выходе были только те, классы которых указаны в настройках калькулятора в графе.
Метод Process для DetectionFilter калькулятора представлен ниже:
mediapipe::Status DetectionFilterCalculator::Process(mediapipe::CalculatorContext *cc) {
const auto& input_detections = cc->Inputs().Get("", 0).Get>();
std::vector<::mediapipe::Detection> output_detections;
for (const auto& input_detection : input_detections) {
bool next_detection = false;
for (int pass_id : pass_ids_) {
for (int label_id : input_detection.label_id()) {
if (pass_id == label_id) {
output_detections.push_back(input_detection);
next_detection = true;
break;
}
}
if (next_detection) {
break;
}
}
}
auto out_packet = mediapipe::MakePacket>(output_detections).At(cc->InputTimestamp());
cc->Outputs().Get("", 0).AddPacket(out_packet);
return mediapipe::OkStatus();
} DetectionFilterCalculator добавляется в граф следующим образом:
node {
calculator: "DetectionFilterCalculator"
input_stream: "filtered_detections"
output_stream: "car_detections"
node_options: {
[type.googleapis.com/objectrecognition.DetectionFilterCalculatorOptions] {
pass_id: 3
}
}
}Теперь пользователь на экране увидит только обнаруженные автомобили. Когда пользователь захочет узнать модель автомобиля, он нажимает по рамке, в которую автомобиль обведен.

Информация о нажатии передается внутрь графа через входной поток ScreenTap, а затем попадает в BoundaryBoxCrop. Важно заметить, что пакеты из ScreenTap также проходят через FlowLimiter, хотя очевидно, что они приходят в граф гораздо реже, чем пакеты с кадрами видео из камеры. Это связано с тем, что входные потоки должны быть синхронизированы, иными словами, обработка пакетов начнется только тогда, когда на вход поступит кадр и информация о нажатии по экрану. Отправкой кадров из камеры в граф занимается стандартный класс FrameProcessor, поэтому для отправки кадров и координат нажатия мне понадобилось написать собственный ObjectDetectionFrameProcessor.
Сначала я пытался отправлять в входной поток ScreenTap пакеты только при нажатии на экран, но столкнулся с непонятным поведением, при котором через граф проходил только один пакет, а потом ни один калькулятор не вызывался и в приложении был «черный экран». Решением данной проблемы стала синхронная отправка в граф пакета с кадром и пакета с информацией о нажатии. Чаще всего пакет с информацией о нажатии пустой, но в случае, когда пользователь нажимает на экран, то пакет заполняется координатами экрана (причем, в данной задаче удобно, чтобы координаты были нормализованы в [0, 1]).
BoundaryBoxCrop на входе проверяет, что в пакет с информацией по нажатию не пустой. Если он не пустой, то из DetectionFilter берутся полученные рамки, из FlowLimiter берется текущий кадр, предварительно пересланный из GPU в CPU. Этой информации достаточно, чтобы определить, по какой рамке было произведено нажатие, а затем вырезать её из общего кадра.
mediapipe::Status BoundaryBoxCropCalculator::Process(mediapipe::CalculatorContext *cc) {
auto& detections_packet = cc->Inputs().Get("DETECTION", 0);
auto& frames_packet = cc->Inputs().Get("IMAGE", 0);
auto& click_packet = cc->Inputs().Get("CLICK", 0);
if (detections_packet.IsEmpty()
|| frames_packet.IsEmpty()
|| click_packet.IsEmpty()) {
return mediapipe::OkStatus();
}
const std::vector& detections =
detections_packet.Get>();
const mediapipe::ImageFrame& image_frame = frames_packet.Get();
// Java код записывает сериализованный protobuf как строку, поэтому его нужно вручную разбирать.
auto click_location_str = click_packet.Get();
objectrecognition::ClickLocation click_location;
click_location.ParseFromString(click_location_str);
// Нажатия не было, выходим без дальнейшей обработки
if (click_location.x() == -1 || click_location.y() == -1) {
return mediapipe::OkStatus();
}
// Определение по какой рамке было нажатие
absl::optional detection = FindOverlappedDetection(click_location, detections);
if (detection.has_value()) {
// если нажатие было по рамке, то изображение внутри рамки вырезается
std::unique_ptr cropped_image = CropImage(image_frame, detection.value());
cc->Outputs().Get("", 0).Add(cropped_image.release(), cc->InputTimestamp());
}
return mediapipe::OkStatus();
}
absl::optional BoundaryBoxCropCalculator::FindOverlappedDetection(
const objectrecognition::ClickLocation& click_location,
const std::vector& detections) {
for (const auto& input_detection : detections) {
const auto& b_box = input_detection.location_data().relative_bounding_box();
if (b_box.xmin() < click_location.x() && click_location.x() < (b_box.xmin() + b_box.width())
&& b_box.ymin() < click_location.y() && click_location.y() < (b_box.ymin() + b_box.height())) {
return input_detection;
}
}
return absl::nullopt;
}
std::unique_ptr BoundaryBoxCropCalculator::CropImage(
const mediapipe::ImageFrame& image_frame,
const mediapipe::Detection& detection) {
const uint8* pixel_data = image_frame.PixelData();
const auto& b_box = detection.location_data().relative_bounding_box();
int height = static_cast(b_box.height() * static_cast(image_frame.Height()));
int width = static_cast(b_box.width() * static_cast(image_frame.Width()));
int xmin = static_cast(b_box.xmin() * static_cast(image_frame.Width()));
int ymin = static_cast(b_box.ymin() * static_cast(image_frame.Height()));
if (xmin < 0) {
width += xmin;
xmin = 0;
}
if (ymin < 0) {
height += ymin;
ymin = 0;
}
if (width > image_frame.Width()) {
width = image_frame.Width();
}
if (height > image_frame.Height()) {
height = image_frame.Height();
}
std::vector pixels;
pixels.reserve(height * width * image_frame.NumberOfChannels());
for (int y = ymin; y < ymin + height; ++y) {
int row_offset = y * image_frame.WidthStep();
for (int x = xmin; x < xmin + width; ++x) {
for (int ch = 0; ch < image_frame.NumberOfChannels(); ++ch) {
pixels.push_back(pixel_data[row_offset + x * image_frame.NumberOfChannels() + ch]);
}
}
}
std::unique_ptr cropped_image = std::make_unique();
cropped_image->CopyPixelData(image_frame.Format(), width, height, pixels.data(),
mediapipe::ImageFrame::kDefaultAlignmentBoundary);
return cropped_image;
}
После этого вырезанное изображение необходимо предобработать стандартными калькуляторами и запустить модель для получения дескриптора. Полученный дескриптор конвертируется из TfLiteTensor в массив чисел и отправляется на выход из графа в приложение.
Приложение (Java код) получает массив, отправляет его по HTTP на сервер. Сервер представляет из себя простой сервис, который находит для данного дескриптора находит ближайший к нему среди «эталонных» дескрипторов автомобилей и отвечает клиенту названием модели ближайшего вектора. Близость может определяться разными способами, в данном случае использовалось косинусное расстояние (косинус между двумя векторами).
Всё, что остается клиенту — это вывести пользователю результат распознавания. Вот как это выглядит на практике:
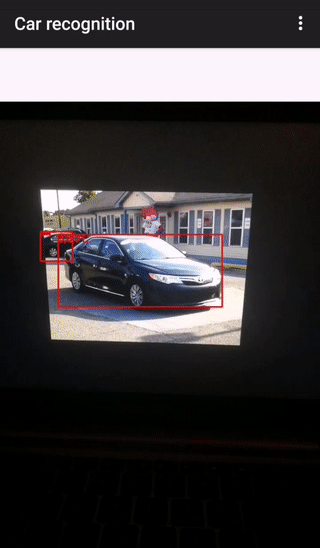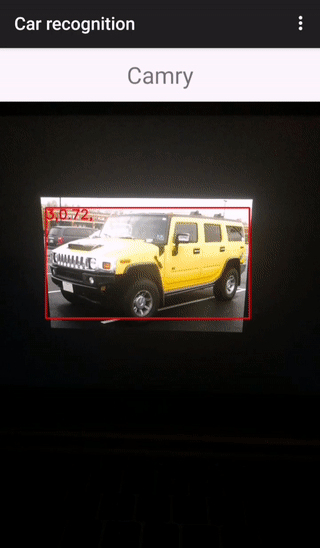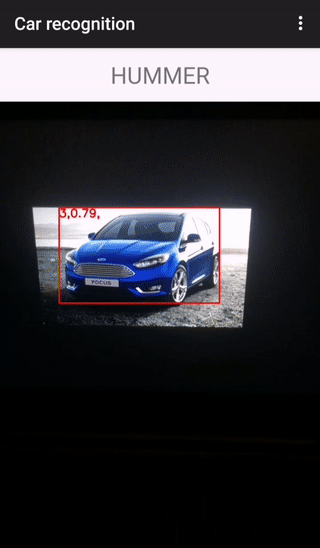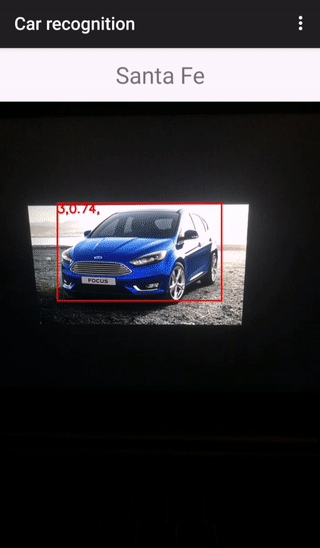
Демонстрация проведена на трех автомобилях. Первые две модели распознаны правильно (сервер содержит вектора для camry и hummer), а вот с ford focus вышла ошибка, т.к. на сервере нет вектора-эталона, тем не менее был выбран самый близкий (Hyundai SantaFe).
В верхнем ряду представлены 4 фотографии, по которым вычислялись эталонные дескрипторы, на нижней фотографии была проведена демонстрация.

Итак, в результате получено приложение, выполняющее всю ресурсоемкую работу по детекции и распознаванию, а также простенький сервер, оперирующий только массивами чисел и близостью между векторами. При этом по сети изображения в явном виде не передается, а передается более сжатое представление, что позволяет пользоваться сервисом при медленном соединении.
В статье рассмотрены примеры реализаций приложений, использующих в своей работе модели машинного обучения с помощью Mediapipe, продемонстрирован подход к реализации приложений, предназначенных для распознавания, анализа изображений, звуков и текста. При этом удалось реализовать real-time детекцию на устройстве без передачи больших картинок через мобильный интернет. Естественным образом такая концепция улучшает UX, ведь пользователь видит, что именно он отправляет в поиск. При этом рассмотренный пример для распознавания автомобилей является прототипом и демонстрацией proof-of-concept, поэтому содержит недочеты и направления для развития:
- Вырезание изображения и запуск сети для получения вектора выполняются на CPU, тогда как часть с детекцией, взятая из оригинального примера, выполняется на GPU. Перенос всего на GPU позволит ускорить выполнение и сэкономить на пересылках между CPU и GPU;
- Добавление трекинга и выполнение распознавания не по нажатию на рамку, а в реальном времени. Это добавит интерактивности и позволит распознавать несколько автомобилей одновременно;
- Использование квантованных дескрипторов;
- Перенесение облечненного индекса на клиент для ответа на популярные запросы без необходимости совершать запрос;
- Оптимизация поиска ближайшего эталона на сервере. Вместо линейного поиска ближайшего вектора могут применяться алгоритмы ANN.
