[Из песочницы] Разработка визуальных тестов на базе Gemini и Storybook
Привет, Хабр! В этой статье я хочу поделиться опытом разработки визуальных тестов в нашей команде.
Так получилось, что о тестировании верстки мы задумались не сразу. Ну съедет какая-нибудь рамка на пару пикселей, ну поправим. В конце концов, есть же тестировщики — мимо них и муха не пролетит. Но человеческий фактор все-таки не обманешь — обнаружить незначительные изменения в пользовательском интерфейсе далеко не всегда физически возможно даже тестировщику. Вопрос встал ребром, когда была затеяна серьезная оптимизация верстки и переход на БЭМ. Тут без потерь бы точно не обошлось и нам позарез стал нужен автоматизированный способ обнаружения ситуаций, когда в результате правок что-то в UI начинает меняться не так, как было задумано, или не там, где было задумано.
Про модульное тестирование кода знает любой разработчик. Модульные тесты дают уверенность, что изменения в коде ничего не сломали. Ну, по крайней мере, не сломали в той части, на которую есть тесты. Тот же принцип можно применить и для пользовательского интерфейса. Подобно тому, как модульные тесты тестируют классы, визуальные тесты тестируют визуальные компоненты, из которых строится пользовательский интерфейс приложения.
Для визуальных компонент можно писать и «классические» модульные тесты, которые, например, инициируют рендеринг компоненты с разными значениями входных параметров и проверяют ожидаемое состояние DOM-дерева с помощью assert-утверждений, сравнивая с эталоном либо отдельные элементы, либо снимок DOM-дерева компоненты в целом. Визуальные тесты тоже основаны на снимках, но уже на снимках визуального отображения компоненты (скриншотах). Суть визуального теста в том, чтобы сравнить снимок, полученный в ходе теста с эталонным и, в случае обнаружения различий, либо принять новый снимок как эталонный, либо исправить баг, послуживший причиной этих различий.
Конечно, «скринить» отдельные визуальные компоненты не слишком-то эффективно. Компоненты не живут вакууме и их отображение может зависеть либо от компонент верхнего уровня, либо от соседних. Как бы мы ни тестировали отдельно взятые компоненты, картинка в целом может иметь дефекты. С другой стороны, если делать снимки всего окна приложения, то на многих снимках будут присутствовать одни и те же компоненты, а это значит, что при изменении какой-то одной компоненты мы будем вынуждены обновлять все снимки, в которых эта компонента присутствует.
Истина, как обычно, где-то посередине — можно отрисовать всю страницу приложения, но делать снимок только одной какой-то области, под которую создается тест, в частном случае эта область может совпадать с областью конкретной компоненты, но это уже будет компонента не в вакууме, а во вполне себе реальном окружении. И это уже будет похоже на модульный визуальный тест, хотя вряд ли можно говорить о модульности если «модуль» что-то знает об окружении. Ну да ладно, не так уж важно, к какой категории тестов отнести визуальные тесты — к модульным или интеграционным. Как говорится, «вам шашечки или ехать»?
Выбор инструмента
Для ускорения выполнения тестов рендеринг страниц можно делать в каком-либо headless-браузере, который выполняет всю работу в памяти без отображения на экране и обеспечивает максимальное быстродействие. Но в нашем случае было критически важно обеспечить работу приложения в Internet Explorer (IE), который не имеет headless-режима, и нам нужен был инструмент для программного управления браузерами. К счастью, все уже придумано до нас и такой инструмент есть — называется он Selenium. В рамках проекта Selenium разрабатываются драйверы для управления различными браузерами, в том числе и драйвер для IE. Selenium сервер может управлять браузерами не только на локально, но и удаленно, образуя кластер из selenium-серверов, так называемый selenium grid.
Selenium — мощный инструмент, но порог вхождения в него достаточно высок. Мы решили поискать готовые инструменты для визуального тестирования на базе Selenium и наткнулись на замечательный продукт от Яндекс, который называется Gemini. Gemini умеет делать снимки, в том числе снимки определенной области страницы, сравнивать снимки с эталонными, визуализируя разницу и учитывая такие моменты как антиалиасинг или мигающий курсор. Кроме того, Gemini умеет делать повторы выполнения упавших тестов, распараллеливать выполнение тестов и много других полезных плюшек. В общем, мы решили попробовать.
Тесты на gemini пишутся очень просто. Для начала нужно подготовить инфраструктуру — установить selenium-standalone и запустить selenium server. Затем сконфигурировать gemini, указав в конфигурации адрес тестируемого приложения (rootUrl), адрес selenium-сервера (gridUrl), состав и конфигурацию браузеров, а также необходимые плагины для формирования отчетов, оптимизации сжатия снимков. Пример конфигурации:
//.gemini.js
module.exports = {
rootUrl: 'http://my-app.ru',
gridUrl: 'http://127.0.0.1:4444/wd/hub',
browsers: {
chrome: {
windowSize: '1920x1080',
screenshotsDir:'gemini/screens/1920x1080'
desiredCapabilities: {
browserName: 'chrome'
}
}
},
system: {
projectRoot: '',
plugins: {
'html-reporter/gemini': {
enabled: true,
path: './report'
},
'gemini-optipng': true
},
exclude: [ '**/report/*' ],
diffColor: '#EC041E'
}
};
Сами тесты представляют собой набор suites, в каждом из которых делается один или более снимков (states). До выполнения снимка (метод capture ()) можно задать снимаемую область страницы с помощью метода setCaptureElements (), а также выполнить при необходимости какие-то подготовительные действия в контексте браузера с использованием либо методов объекта actions, либо с помощью произвольного кода на JavaScript — для этого в actions есть метод executeJS ().
Пример:
gemini.suite('login-dialog', suite => {
suite.setUrl('/')
.setCaptureElements('.login__form')
.capture('default');
.capture('focused', actions => actions.focus('.login__editor'));
});Тестовые данные
Инструмент для тестов был выбран, но до окончательного решения вопроса было еще далеко. Нужно было понять, что делать с данными, отображаемыми в снимках. Напомню, что в тестах мы решили отрисовывать не отдельно взятые компоненты, а всю страницу приложения, чтобы тестировать визуальные компоненты не вакууме, а в реальном окружении других компонент. Если для отрисовки отдельной компоненты достаточно передать в ee props (я сейчас говорю о react-компонентах) нужные тестовые данные, то для рендеринга всей страницы приложения данных нужно гораздо больше и подготовка окружения для такого теста может стать головной болью.
Можно, конечно, оставить получение данных самому приложению, чтобы во время выполнения теста оно выполняло запросы к бэкенду, который, в свою очередь, получал бы данные из какой-то эталонной базы данных, но как тогда быть с версионированием? Базу данных в git-репозиторий не положишь. Нет, ну можно конечно, но есть же какие-то приличия.
Как вариант, для выполнения тестов можно подменить реальный бэкенд-сервер фейковым, который отдавал бы веб-приложению не данные из базы, а статические данные, хранящиеся, например, в формате json, уже вместе с исходниками. Однако, подготовка таких данных тоже не слишком тривиальна. Мы решили пойти более легким путем — не вытаскивать данные с сервера, а просто перед выполнением теста восстанавливать состояние приложения (в нашем случае это состояние redux-хранилища), которое было в приложении на момент снятия эталонного снимка.
Для сериализации текущего состояния redux-хранилища в объект window добавлен метод snapshot ():
export const snapshotStore = (store: Object, fileName: string): string => {
let state = store.getState();
const file = new Blob(
[ JSON.stringify(state, null, 2) ],
{ type: 'application/json' }
);
let a = document.createElement('a');
a.href = URL.createObjectURL(file);
a.download = `${fileName}.testdata.json`;
a.click();
return `State downloaded to ${a.download}`;
};
const store = createStore(reducer);
if (process.env.NODE_ENV !== 'production') {
window.snapshot = fileName => snapshotStore(store, fileName);
};
С помощью этого метода, используя командную строку консоли браузера, можно сохранить текущее состояние redux-хранилища в файл:
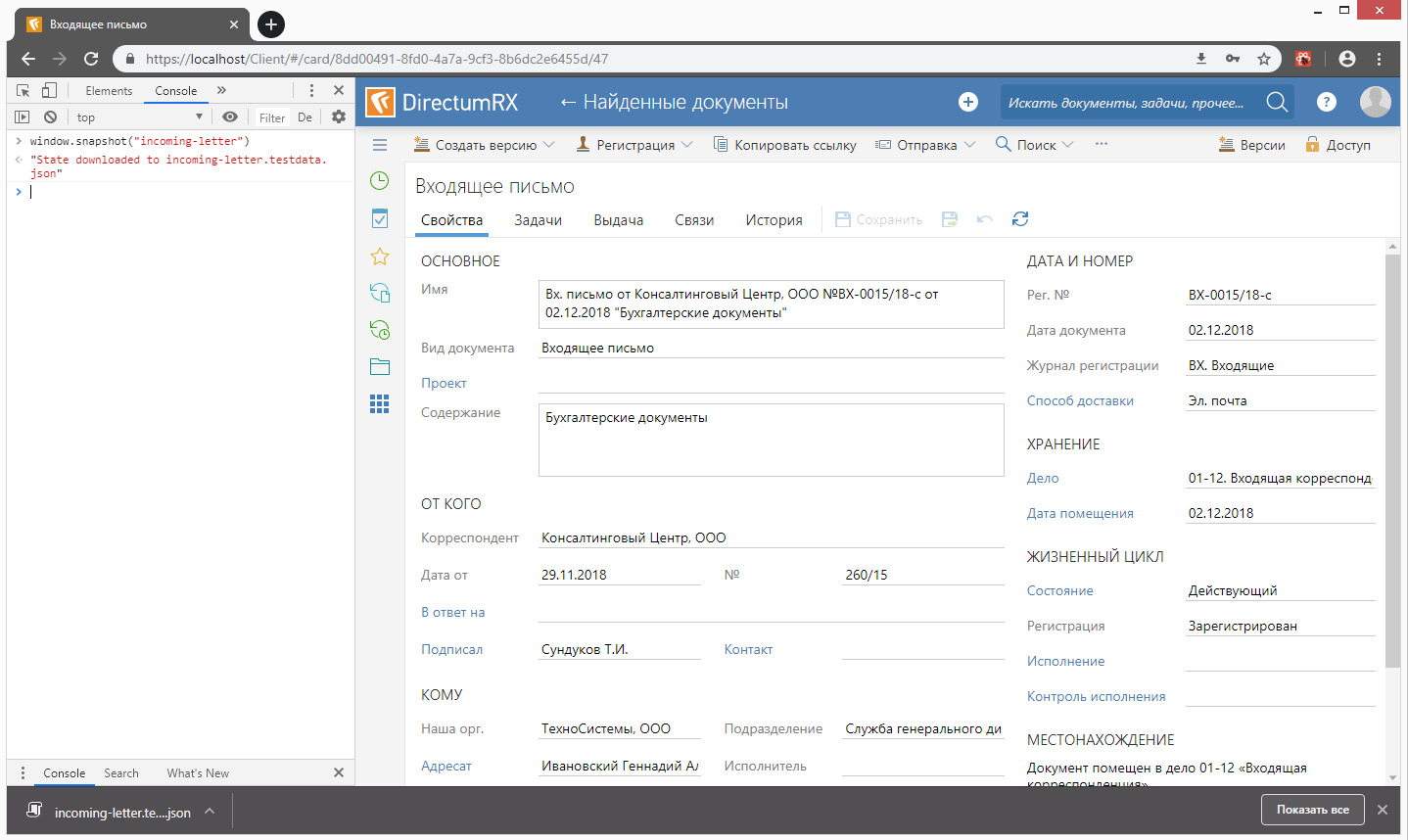
В качестве инфраструктуры для визуальных тестов был выбран Storybook — инструмент для интерактивной разработки библиотек визуальных компонент. Основная идея была в том, чтобы вместо различных состояний компонент в дереве stories зафиксировать различные состояния нашего приложения и использовать эти состояния для снятия скриншотов. В конце концов, принципиальной разницы между простыми и сложными компонентами нет, разве что в подготовке окружения.
Итак, каждый визуальный тест — это story, перед отрисовкой которого восстанавливается ранее сохраненное в файл состояние redux-хранилища. Делается это с помощью компоненты Provider из библиотеки react-redux, в свойство store которой передается десериализованное состояние, восстановленное из сохраненного ранее файла:
import preloadedState from './incoming-letter.testdata';
const store = createStore(rootReducer, preloadedState);
storiesOf('regression/Cards', module)
.add('IncomingLetter', () => {
return (
);
});
В примере выше ContextContainer — это компонента, которая включает в себя «скелет» приложения — дерево навигации, шапку и область контента. В области контента могут отрисовываться различные компоненты (список, карточка, диалог и т.п.) в зависимости от текущего состояния redux-хранилища. Для того, чтобы компонента не выполняла лишних запросов к бэкенду на вход ей передаются соответствующие свойства-заглушки.
В контексте Storybook это выглядит примерно так:
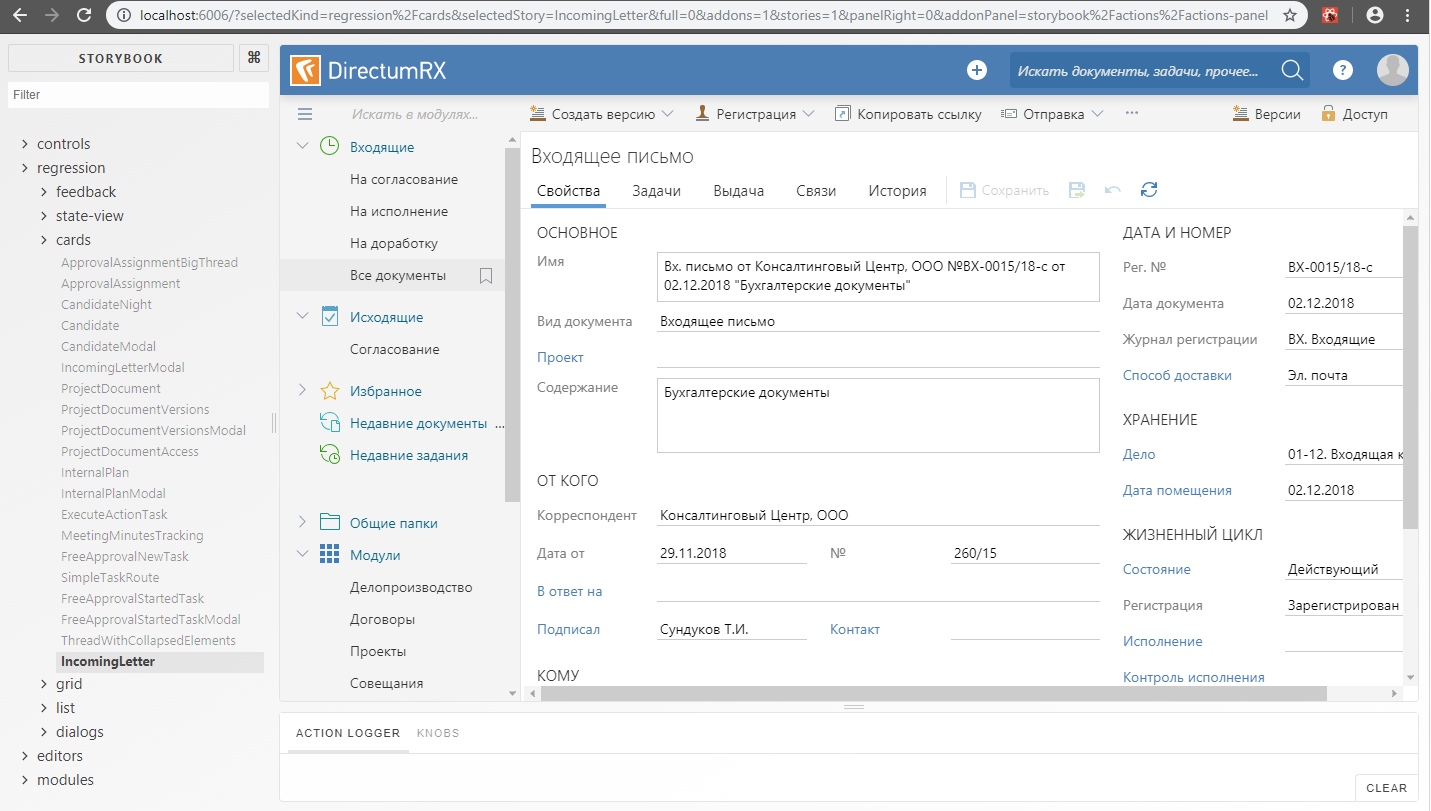
Gemini + Storybook
Итак, с данными для тестов мы разобрались. Следующая задача — подружить Gemini и Storybook. На первый взгляд все просто — в конфиге Gemini мы указываем адрес тестируемого приложения. В нашем случае это адрес Storybook-сервера. Нужно только поднять storybook-сервер перед запуском gemini-тестов. Можно сделать это непосредственно из кода, используя подписку на события Gemini START_RUNNER и END_RUNNER:
const port = 6006;
const cofiguration = {
rootUrl:`localhost:${port}`,
gridUrl: seleniumGridHubUrl,
browsers: {
'chrome': {
screenshotsDir:'gemini/screens',
desiredCapabilities: chromeCapabilities
}
}
};
const Gemini = require('gemini');
const HttpServer = require('http-server');
const runner = new Gemini(cofiguration);
const server = HttpServer.createServer({ root: './storybook-static'});
runner.on(runner.events.START_RUNNER, () => {
console.log(`storybook server is listening on ${port}...`);
server.listen(port);
});
runner.on(runner.events.END_RUNNER, () => {
server.close();
console.log('storybook server is closed');
});
runner
.readTests(path)
.done(tests => runner.test(tests));
В качестве сервера для тестов использовался http-server, отдающий содержимое папки со статически собранным storybook (для сборки статического storybook используется команда build-storybook).
До сих пор все шло гладко, но проблемы не заставили себя ждать. Дело в том, что storybook отображает story внутри фрейма. Изначально мы хотели иметь возможность задавать выборочную область снимка с помощью setCaptureElements (), но сделать это можно только, если указать адрес фрейма в качестве адреса для suite, примерно так:
gemini.suite('VisualRegression', suite =>
suite.setUrl('http://localhost:6006/iframe.html?selectedKind=regression%2Fcards&selectedStory=IncomingLetter')
.setCaptureElements('.some-component')
.capture('IncomingLetter')
);
Но тогда получается, что для каждого снимка мы должны создавать собственный suite, т.к. URL можно задать для suite в целом, но не для отдельного снимка в рамках suite. При этом нужно понимать, что каждый suite выполняется в отдельной сессии браузера. Это, в принципе, правильно — тесты не должны зависеть друг от друга, но открытие отдельной сессии браузера и последующая за этим загрузка Storybook занимает довольно большое время, гораздо большее, чем просто перемещение по stories в рамках уже открытого Storybook. Поэтому при большом количестве suites время выполнения тестов сильно проседает. Частично проблему можно решить распараллеливанием выполнения тестов, но распараллеливание отнимает много ресурсов (память, процессор). Поэтому, решив сэкономить на ресурсах и при этом не слишком потерять в длительности прогона тестов, от открытия фрейма в отдельном окне браузера мы отказались. Тесты выполняются в рамках одной сессии браузера, но перед каждым снимком выполняется загрузка очередного story во фрейм так, как если бы мы просто открыли storybook и стали кликать на отдельные узлы в дереве stories. Область снимка — весь фрейм:
gemini.suite('VisualRegression', suite =>
suite.setUrl('/')
.setCaptureElements('#storybook-preview-iframe')
.capture('IncomingLetter', actions => openStory(actions, 'IncomingLetter'))
.capture('ProjectDocument', actions => openStory(actions, 'ProjectDocumentAccess'))
.capture('RelatedDocuments', actions => {
openStory(actions, 'RelatedDocuments');
hover(actions, '.related-documents-tree-item__title', 4);
})
);
К сожалению, в таком варианте, кроме возможности выбора области снимка мы потеряли еще и возможность использования стандартных actions движка Gemini для работы с элементами DOM-дерева (mouseDown (), mouseMove (), focus () и т.п.), т.к. элементы внутри фрейма Gemini не «видит». Но у нас осталась возможность использования функции executeJS (), с помощью которой можно выполнять код на JavaScript в контексте браузера. На базе этой функции мы реализовали необходимые нам аналоги стандартных actions, которые работают уже в контексте фрейма Storybook. Здесь нам пришлось немного «поколдовать» с тем, чтобы передать значения параметров из контекста теста в контекст браузера — executeJS (), к сожалению, не предоставляет такой возможности. Поэтому на первый взгляд код выглядит несколько странно — функция переводится в строку, часть кода заменяется значениями параметров, а в ExecuteJs () функция восстанавливается из строки с помощью eval ():
function openStory(actions, storyName) {
const storyNameLowered = storyName.toLowerCase();
const clickTo = function(window) {
Array.from(window.document.querySelectorAll('a')).filter(
function(el) {
return el.textContent.toLowerCase() === 'storyNameLowered';
})[0].click();
};
actions.executeJS(eval(`(${clickTo.toString().replace('storyNameLowered', storyNameLowered)})`));
}
function dispatchEvents(actions, targets, index, events) {
const dispatch = function(window) {
const document = window.document.querySelector('#storybook-preview-iframe').contentWindow.document;
const target = document.querySelectorAll('targets')[index || 0];
events.forEach(function(event) {
const clickEvent = document.createEvent('MouseEvents');
clickEvent.initEvent(event, true, true);
target.dispatchEvent(clickEvent);
});
};
actions.executeJS(eval(`(${dispatch.toString()
.replace('targets', targets)
.replace('index', index)
.replace('events', `["${events.join('","')}"]`)})`
));
}
function hover(actions, selectors, index) {
dispatchEvents(actions, selectors, index, [
'mouseenter',
'mouseover'
]);
}
module.exports = {
openStory: openStory,
hover: hover
};
Повторы выполнения
После того, как визуальные тесты были написаны и начали работать выяснилось, что некоторые тесты проходят не очень стабильно. Где-то иконка не успеет отрисоваться, где-то выделение не снимется и мы получаем несовпадение с эталонным снимком. Поэтому было решено включить переповторы выполнения тестов. Однако в Gemini переповторы работают для всего suite, а как уже было сказано выше, мы старались избегать ситуаций, когда на каждый снимок делается свой suite — это слишком замедляет выполнение тестов. С другой стороны, чем больше снимков делается рамках одного suite, тем больше вероятность того, что повторное выполнение suite может свалиться также, как и предыдущее. Поэтому пришлось реализовать переповторы. В нашей схеме повтор выполнения делается не для всего suite, а только для тех снимков, которые не прошли на предыдущем неудачном прогоне. Для этого в обработчике события TEST_RESULT мы анализируем результат сравнения снимка с эталоном, и для не прошедших сравнение снимков, и только для них, создаем новый suite:
const SuiteCollection = require('gemini/lib/suite-collection');
const Suite = require('gemini/lib/suite');
let retrySuiteCollection;
let retryCount = 2;
runner.on(runner.events.BEGIN, () => {
retrySuiteCollection = new SuiteCollection();
});
runner.on(runner.events.TEST_RESULT, args => {
const testId = `${args.state.name}/${args.suite.name}/${args.browserId}`;
if (!args.equal) {
if (retryCount > 0)
console.log(chalk.yellow(`failed ${testId}`));
else
console.log(chalk.red(`failed ${testId}`));
let suite = retrySuiteCollection.topLevelSuites().find(s => s.name === args.suite.name);
if (!suite) {
suite = new Suite(args.suite.name);
suite.url = args.suite.url;
suite.file = args.suite.file;
suite.path = args.suite.path;
suite.captureSelectors = [ ...args.suite.captureSelectors ];
suite.browsers = [ ...args.suite.browsers ];
suite.skipped = [ ...args.suite.skipped ];
suite.beforeActions = [ ...args.suite.beforeActions ];
retrySuiteCollection.add(suite);
}
if (!suite.states.find(s => s.name === args.state.name)) {
suite.addState(args.state.clone());
}
}
else
console.log(chalk.green(`passed ${testId}`));
});
Кстати, событие TEST_RESULT пригодилось еще и для визуализации прогресса выполнения тестов по мере их прохождения. Теперь разработчику не нужно ждать, когда выполнятся все тесты, он может прервать выполнение, если видит, что что-то пошло не так. При прерывании выполнения тестов Gemini корректно закроет сессии браузеров, открытые selenium-сервером.
По завершении прогона тестов, если новый suite не пустой, запускаем его на выполнение пока не будет исчерпано максимальное количество повторов:
function onComplete(result) {
if ((retryCount--) > 0 && result.failed > 0 && retrySuiteCollection.topLevelSuites().length > 0) {
runner.test(retrySuiteCollection, {}).done(onComplete);
}
}
runner.readTests(path).done(tests => runner.test(tests).done(onComplete));Резюме
На сегодняшний день мы имеем около полусотни визуальных тестов, покрывающих основные визуальные состояния нашего приложения. Про полное покрытие тестами UI говорить, конечно, не приходится, но мы пока и не ставили такой цели. Тесты успешно работают как на рабочих местах разработчиков, так и на билд-агентах. Пока тесты выполняются только в контексте Chrome и Internet Explorer, но в перспективе возможно подключение и других браузеров. Все это хозяйство обслуживает Selemium grid с двумя node, развернутыми на виртуальных машинах.
Периодически мы сталкиваемся с тем, что после выхода новой версии Chrome приходится обновлять и эталонные снимки из-за того, что какие-то элементы стали отображаться чуть-чуть по-другому (например, скроллеры), но с этим уж ничего не поделаешь. Редко, но бывает, что при изменении структуры redux-хранилища приходится заново переснимать сохраненные состояния для тестов. Восстановить именно такое же состояние, которое было в тесте на момент его создания, конечно, не просто. Как правило, никто уже и не помнит на какой базе данных были сделаны эти снимки и приходится делать новый снимок уже на других данных. Это проблема, но не очень большая. Для ее решения можно делать снимки на демо-базе, благо скрипты для ее генерации у нас имеются и поддерживаются в актуальном состоянии.
