[Из песочницы] Построение стакана котировок (FullOrderBook) по историческим данным

Совсем недавно решал задачу построения стакана котировок на основе исторических данных Московской Биржи. В открытых источниках ничего подобного не нашел, пришлось начинать с нуля и копать самому. Есть некоторые нюансы, о которых нужно знать. Про них буду упоминать по ходу.
Про биржевую торговлю, инфраструктуру и тестирование алгоритмов на исторических данных много писал и пишет IT Invest, спасибо ему. От себя добавлю, что на данных OrderLogs мы анализируем глубину рынка, ликвидность, спреды и еще много чего. Результаты используем в наших торговых алгоритмах.
Специально выбрал Фондовый рынок, так как тут больше всего вопросов. Валютный и Срочный рынок имеют свои особенности, но там проще. Реализация алгоритма на Java, код на GitHub.
Цель: Получить стакан котировок на любой момент времени.
Что на входе?
Файл со всеми заявками/сделками (Full Order Log), полученный от Биржи за 1 день, простой CSV формат, объем ~ 1 Гб. Описание формата и примеры данных есть на сайте Биржи. Вот фрагмент файла:

- Код бумаги — торговый код инструмента
- Buy/Sell — напраление заявки купить или продать
- Время — в формате HHMMSSZZZ (101738829 = 10 ч 17 мин 38 сек 829 мс)
- ID заявки — по нему отслеживаем жизнь заявки
- Тип события — {1 — пришла заявка, 0 — удалена заявка, 2 — сделка}
- Цена — цена в руб. за 1 бумагу
- Объем — объем заявки/сделки в количестве бумаг
- ID сделки — заполняется если тип события=2
- Цена сделки — заполняется если тип события=2
Так как данные получены прямо из торговой системы, то поле «Время» — это время фиксации событий в торговой системе. Это надо принять к сведению. Кто получает маркетдату через FAST, тем данные приходят с задержкой (latency ~ 0.1 мс в зоне колокации). Это я к тому, что, если вы тестируете алгоритмы на данных Биржи, то там во времени не учитываются задержки, которые есть в наших реалиях. Так что если такие времена не критичны, можно «забить» на latency.
Фондовый рынок стартует в 9:50 и закрывается в 18:50, проходя 3 фазы:
09:50 — 10:00 — Аукцион открытия (Формируется цена открытия)
10:00 — 18:40 — Основные торги
18:40 — 18:50 — Аукцион закрытия (формируется цена закрытия)
Файл содержит только «Основные торги» + неисполенные заявки с аукциона открытия.
Алгоритм сборки
Понадобится 2 типа объекта «Orders» и «OrderBook». Orders — это дискретные заявки (строка в файле). А объект OrderBook — это агрегированные по цене заявки имеющий 2 поля: цена и объем, т.е. складываем все объемы с одинаковой ценой.
Давайте соберем стакан для инструмента «XXXX» на момент времени AABBCCDDD. С первой строки начинаем собирать заявки (объекты Orders), касающиеся бумаги «XXXX» в коллекции. Заявки Buy в одну, Sell в другую. И будем перебирать все заявки пока time<=AABBCCDDD.
Если тип события = 1 (поставить заявку), добавляем заявку в коллекцию Buy или Sell в зависимости от направления заявки.
Если тип события = 0 (удалить заявку), то по номеру заявки находим ее в коллекции и удаляем. Она там непременно должна быть, ибо по логике, нельзя удалить то, чего нет. Если не нашли нужную заявку, надо бить тревогу (либо ошибка в самих данных, либо ошиблись мы сами).
Если тип события = 2 (сделка), то по номеру заявки находим ее в коллекции и смотрим на ее объем:
- Если V1=V2 (V1 — объем заявки в коллекции, V2 — объем сделки), то заявку удаляем из коллекции. Это значит, что заявка исполнилась полностью;
- Если V1>V2, то в коллекции изменяем объем V1 на V1-V2. Это значит, что заявка исполнилась частично. А часть осталась в стакане;
- Если V1
Типы событий = 2 всегда идут попарно — две стороны сделки. Как только нарушается условие time
Заявки типа «По рынку»
У рыночныех заявок в поле цена указывается »0». Такие заявки, так же обрабатываем как обычные. Они исполняются в моменте.
Заявки типа «Айсберг»
Айсберг заявки также встречаются в ордерлогах. Как показала практика, их невозможно идетифицировать наверняка. При формировании данных Биржа применяет свой алгоритм, который скрывает «айсберги». Но все равно, в некоторых случаях они мелькают, например висит заявка с объемом 10, а когда превращается в сделку — объем уже 100.
Знание этой информации достаточно, чтобы собирать стаканы, анализировать спреды и глубину рынка.
А теперь самое вкусное: давайте проверим наш алгоритм на практике. 2 февраля 2016 специально сделал скриншоты с терминала Bloomberg со стаканом, зафиксировав время. Инструменты брал не самые ликвидные: Яндекс (YNDX), Камаз (KMAZ)… дабы избежать сложности с синхронизацией времени. Паралельно собрал стакан на Биржевых данных описанным выше алгоритмом. Вот результат на 16:56:21:
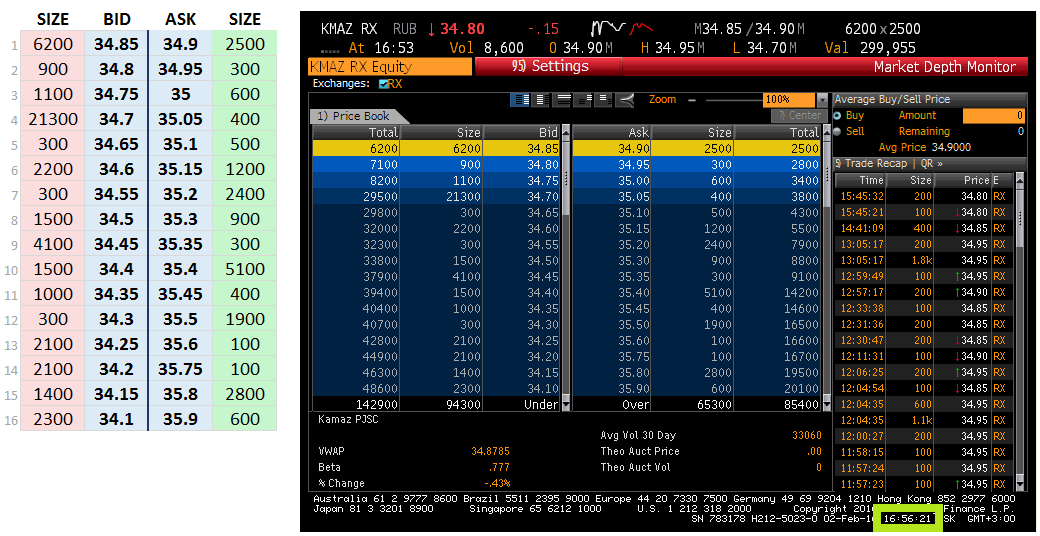
Данные идентичны.
Пару слов о скорости
В потоке около 15 млн записей, где содержится около 300 инструментов. Самый ликвидный инструмент SBER за целый торговый день прогоняет за 20 сек. Для SBERа глубина стакана в ту или другую сторону — 500–600 ценовых уровней. Если через каждый «час» сохранять состояние стакана, время обработки сокращается до секунды, что меня вполне устраивает. А если еще записать нужный инструмет в отдельный поток, время сократится до десятых секунд.
Таким образом, стакан по любому инструменту на любой момент времени получаем менее чем за 1 секунду. Уверен, кто-то сможет предложить более эффективный алгоритм, буду рад.
P.S.: Кусок исторических данных можно взять на сайте Биржи бесплатно. Если нужны данные имено за 2 февраля, выгружу на Я.Диск (~1Gb). Дайте знать.
