[Из песочницы] Покойся с миром, REST. Долгих лет жизни GraphQL
Комментарии (37)
 Amareis
Amareis
26 июля 2017 в 15:04
0↑
↓
Вот только вчера потыкал палочкой гитхабовский GraphQL, остался доволен, особенно explorer порадовал.
Вообще, с подобными технологиями скоро уже действительно будет всё выглядеть так, что изменение одного поля в БД точечно изменяет строчку в компоненте на экране тысяч пользователей по всему миру (ну и в обратную сторону, конечно). Разработчику останется только писать словарики, прокидывающие названия полей)
26 июля 2017 в 15:19
+3↑
↓
Такое и сейчас везде где программист не настолько ленив что бы поднять вебсокеты для реалтайма и уведомлять клиентов об изменении.
 sopov
sopov
26 июля 2017 в 15:24
0↑
↓
N+1 SQL-запросы можно фильтровать на уровне middleware в Express.js или по хэшу запроса и только для авторизованных пользователей.
Может кто поделится Best Practics?26 июля 2017 в 15:31
+1↑
↓
Было бы интереснее почитать сравнение GraphQL и ODATA (http://www.odata.org), которая давно решает эту же задачу.
26 июля 2017 в 15:43
+7↑
↓
И только после шести запросов мы можем собрать ответы и обеспечить компонент необходимыми данными.
Полнейший бред. Бэкенд может спокойно возвращать вложенный JSON. Сейчас бэкенд на .NET так работает, Django REST это умеет.
Т.е. вместо того чтобы найти нормального бэкенд разработчика предлагается ещё больше всё усложнить.
26 июля 2017 в 18:51
+1↑
↓
Проблема здесь не во вложенности JSON, а в том, что если мы делаем ресурс person, то запрос этого ресурса не должен возвращать что-то, кроме данных самого ресурса и гиперссылок на связанные ресурсы. Соответственно, чтобы вытащить какую-то незначительную информацию для отображения (имя связанного ресурса film, например), придется выполнять все эти дополнительные запросы. Я не большой знаток HATEOAS, но предполагаю что конкретно эту задачу в рамках RESTful архитектуры даже можно решить его средствами (доп. полем displayName).В целом же я сторонник той трактовки REST, которая предполагает создание отдельного ресурса, возвращающего максимум информации минимумом запросов. В приведенном примере это был бы ресурс personRoot.
 zelenin
zelenin
26 июля 2017 в 19:11
0↑
↓
запрос этого ресурса не должен возвращать что-то, кроме данных самого ресурса и гиперссылок на связанные ресурсы
это не так. существование ресурсов — вот парадигма rest. Должны ли вложенные документы быть или нет, rest не говорит. rest — это вообще не спека. Это набор общих принципов. Все, что в прицнипах не оговорено, ты волен делать сам. Одна из спек rest — jsonAPI — например описывает возможность вложенных полей.
26 июля 2017 в 19:35
0↑
↓
возможности опасны) вложенные сущности — это избыточность, которая не всегда нужна.
понятно, что нужно соблюдать баланс, но всё-таки в общем случае лучше иметь еще и расширенную версию ресурса, чем только одну, но перегруженную.-
zelenin
26 июля 2017 в 19:40
+2↑
↓
ну в graphql же у вас есть возможность вложенности. Опасно вам стало?
rest не описывает вложенность., но никому не мешает написать спеку с описанной вложеностью, и методами для частичного получения полей и документов.
А graphql это сделал, и сделал неплохо, и сделал досконально — в этом соль.26 июля 2017 в 20:00
0↑
↓
согласен., но изначальный комментарий про вложенность JSON для меня всё равно звучит странно)
26 июля 2017 в 20:30
+1↑
↓
Что мешает создать endpoint на бэкенде, который будет возращать только нужную информацию?
Film возвращать как дочерний объект с полями ID и Name например.Посыл статьи «не смогли реализовать REST API попробуем GraphQL».
Если уж хвалить GraphQL так за какие-то реальные преимущества, а не возможность решить надуманные проблемы.
Смотрю Graphene-Django, есть интересная фича фильтровать данные по параметру например, это реально полезно и может сэкономить время и силы.
В общем как с реактом, идея хорошая, ждём пока будет достойная реализация.
 Hypuk
Hypuk
26 июля 2017 в 15:54
0↑
↓
Для тех кто хочет изучить GraphQL есть бесплатные видео уроки — www.howtographql.com26 июля 2017 в 16:11
+1↑
↓
Все эти GraphQL и ODATA хороши только тогда когда репозиторий умеет загружать данные с достаточной гранулярности.Чаще всего оказывается что запрашивать данные с такой гранулярностью не получатся и начинается подход — «Загрузим все, а потом отфильтруем в памяти».
Что напрочь убивает всю задумку.
26 июля 2017 в 16:48
+6↑
↓
Везде так клево описывается graphql, но только со стороны фронтэнда. А ведь в реальности это мы уносим всю сложность с фронта на бэк, где нам нужно уметь разгрбеать эти запросы как-то. И общая сложность проекта в целом растет.
Поэтому для большинства проектов я бы сказал слишком громкий заголовок у статьи viru0
viru0
26 июля 2017 в 17:09
–2↑
↓
Вот я тоже о том же подумал. Перепарсить из этого graphql в SQL, да еще и в какой то нормальный запрос к mongo — та еще задача.
Я в случае с mongo те-же 6 запросов в итоге будут, если films и persons в разных коллекциях лежат. teux
teux
26 июля 2017 в 17:24 (комментарий был изменён)
0↑
↓
Конечно, GraphQL не панацея. Но такого подхода определенно не хватало.
Есть также взгляд, что RESTful API можно делать поверх GrpahQL API26 июля 2017 в 19:07
0↑
↓
Более того, почему-то GraphQL всегда рассматривается в контексте маппинга на sql-запросы. А если какая-то часть данных лежит в sql, какая-то — в другом хранилище, а остальная — в третьем. В этом случае сложность бэкенда перекроет все плюсы.
Вот реально, GraphQL продвигают фронтендеры, потому что упрощается их работа.-
teux
26 июля 2017 в 19:27
–1↑
↓
В этом случае сложность бэкенда перекроет все плюсы
Какую дополнительную сложность приносит GraphQL в подобной ситуации?
Мне кажется, не сильно усложняет, может и не усложняет вовсе. Но я не бекендер, мне не видноСо стороны фронта, кончено, упрощение встретят «на ура». Но причина не в лени.
Какой проект не возьми, везде свои решения для запроса данных, кеширования, асинхронных уведомлений от сервера. Каждый раз думаешь, когда мы слезем с велосипеда в этой части?И тягу к идеальному нельзя задвинуть. Оптимизация запросов на клиенте, отсутствие избыточного пейлоада, повышение отзывчивости — это хорошо, это правильно.
И к слову, чтобы все это применить на клиенте, тоже надо руки приложить. Особенно такой фреймворк,
как Relay Modern. По меньшей мере придется как следует разобраться с вебпаком, чтобы применить правильный лоадер для graphql-схемы, поставить плагин в бабель, изучить React, понять что есть HOC. Не скажу, что GraphQL это прямо подарок лентяю.
 AikoKirino
AikoKirino
26 июля 2017 в 17:13
+1↑
↓
В очередной раз прочитав статью о хваленом GraphQL задаюсь вопросами:
Какие проблемы оно решает?
Чем лучше старого-доброго RPC?
Почему его сравнивают с REST?26 июля 2017 в 17:16
–3↑
↓
Что за хайп вокруг GraphQL?REST — это не
GET — /people/{id}
:)GraphQL — сам подмножество REST.
Безграмотность.
 madkite
madkite
26 июля 2017 в 19:33
+2↑
↓
В GraphQL можно, например, сделать мутацию GET-запросом, а это идёт вразрез идеологии REST. Так что рассматривать GraphQL как подмножество REST не очень корректно.
 Alex_ME
Alex_ME
26 июля 2017 в 17:35
0↑
↓
Не совсем понимаю, какое правильно применения у этой технологии. Сам с REST API полноценно не работал (не создавал), и могу ошибаться по поводу того, как должно быть правильно и канонично.
Как я понимаю, чаще всего в реальном приложении, api представляет сложнее, чем простой CRUD, требующей выполнения какой-то логики на бэкенде для обработки запросов к endpoint’ам.
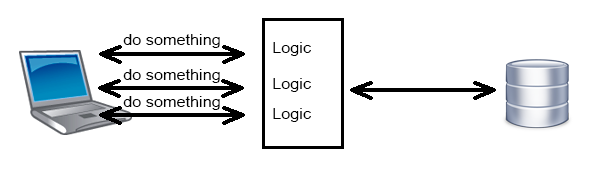
GraphQL выглядит как Data Access Level и неплохо ложиться на SQL и всякие ORM поверх него. Но где в таком случае сама логика? «Позади» GraphQL, т.е. GraphQL обращается не к данным из хранилища, а к бизнес логике?
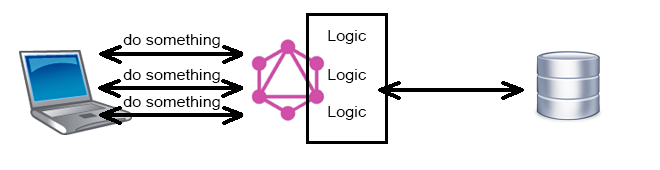
Но в таком случае скорее всего невозможна та гибкость, о которой пишут, ведь априори логика реализует какой-то ограниченный функционал.
Или может быть сейчас вообще всю логику переносят на клиент, оставляя на бэкенде лишь CRUD доступ к данным и авторизацию+аутентификацию?
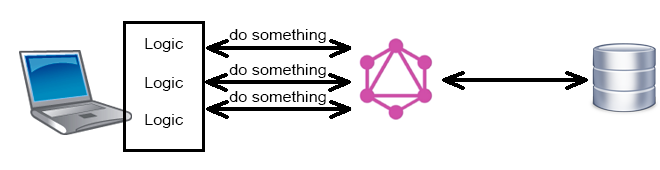
-
teux
26 июля 2017 в 18:03
0↑
↓
Как я понимаю (сам только начал изучать), логика запроса данных — в функциях-резолверах. Они связаны с полями и являются частью схемы GraphQL. Прочая бизнес-логика — в event-driven келбеках.Например, на graph.cool для этих целей предлагается использовать функции. Они позволяют сделать что-то на разных этапах обработки запроса. На скриншоте показан выбор этапа при создании функции.

Сами функции могут хоститься на облачных сервисах типа AWS Lambda.
Если пишете свой GraphQL бекенд, то используете какую-то библиотеку. Она, наверняка, будет предлагать аналогичный механизм келбеков.
26 июля 2017 в 18:25
0↑
↓
Ого. Но строить целую архитектуру проекта основываясь на языке запросов мне кажется неэффективным. Бизнес-логика и CUD пускай лучше остаются вне скоупа задач, решаемых с помощью GraphQL.-
zelenin
26 июля 2017 в 19:04
0↑
↓
не целую архитектуру, а взаимодействие с фронтэндом.
если предположить, что ваше приложение построено на некоем сервисном слое, то graphql — это то, что до сервисного слоя, и то, что после. Бизнес логика остается с вами.26 июля 2017 в 19:22
0↑
↓
и то, что после
Я правильно понял, вы предлагаете GQL использовать для доступа к сырым данным (это обычно БД)?Но главное — это то, что GQL крут именно возможностью гибко запрашивать информацию целыми графами. Изменять состояние этими же целыми графами — очень нетривиальная задача, и я бы не рисковал реализовывать (или использовать реализованную в числе первых… ну миллиона) настолько сложную систему.
GQL — для чтения, REST/RPC/чтотоеще — для записи.
-
zelenin
26 июля 2017 в 19:48
0↑
↓
да, перечитал свой коммент и понял что неправильно сформулировал. Читать так:
если предположить, что ваше приложение построено на некоем сервисном слое, то graphql — это то, что до сервисного слоя во время реквеста, и то, что после во время респонса. Бизнес логика остается с вами.
request → graphql → сервисный слой → бизнес-логика → сервисный слой → graphql → response
26 июля 2017 в 19:58
0↑
↓
в моей практике большая часть БЛ приходится на флоу записи, а не чтения. соответственно, главный мой вопрос (к teux, в основном): вы предполагаете использовать GQL для записи?-
zelenin
26 июля 2017 в 20:04
0↑
↓
вы навреное не понимаете как graphql работает. graphql ничего сам не записывает и ничего не читает. он принимает запрос, валидирует его, роутит в определенный ресолвер, где вы чем хотите тем и обработаете. И после обработки выплюнет результат.
Обработка (чтение или запись) всегда остается на вашей совести. -
teux
26 июля 2017 в 20:47
0↑
↓
Вынужден слегка поправить ваш вопрос. С моей стороны нет каких-либо предложений, но GQL, как известно, используется для записи.Мне кажется, вы видите проблему в том, что запись не может быть столь же произвольно безграничной, как получение данных. Блокировки–транзакции–индексирование на уровне БД ограничивают попытки менять данные произвольным образом. Все ради поддержания целостности и доступности данных.
Но GQL не дает абсолютной свободы ни в запросах, ни в мутации. Это только кажется, что любой путь в графе доступен. Представление данных в виде графа позволяет делать крутые оптимизации на фронте. Но на беке, чтобы путь в графе был доступен, он должен быть разрешен схемой.
Некоторые сервисы, например graph.cool, имеют два варианта API — упрощенный и полнофункциональный. В упрощенном API для всех типов данных неявно создаются разрешения на доступ к их полям, а если какое-то поле связано с другим типом, то и к узлам этого типа. В полном API ситуация строже — нужно самостоятельно определить разрешенные для чтения пути.
С мутациями все еще строже. Нет никакой произвольности. В схеме должны определять доступные мутации. Каждая мутация — это функция, которая может проверить входные данные и сделать нужные запросы к БД. Клиенту доступна та или иная мутация, он может вызывать ее с разными параметрами, но он не может через GQL менять любые данные в графе, как заблагорассудится.
PS. На мое знание GQL пока нельзя полагаться — только недавно стал изучать GQL и больше со стороны фронта.
 QuickJoey
QuickJoey
26 июля 2017 в 18:25
0↑
↓
Есть такая штука , которая делает очень удобным вызов функций (любых, выборка, или изменение данных) из GraphQL. Если предположить, что вся бизнес-логика построена на функциях и триггерах Postgres, получается законченное решение.p. s. Я не веб-программист, если порю чушь, извините.
 hVostt
hVostt
26 июля 2017 в 19:17 (комментарий был изменён)
+1↑
↓
ИМХО, чтобы GraphQL взлетел, надо написать очень много мощных tool для бекенда, которые будут обеспечивать то, что называется «говорить на нескольких языках».Представьте себе, что сегодня изобрели язык SQL, но ещё нет ни одной СУБД, которая с ним работает. Какой смысл в SQL тогда? Никакого. Что с этим языком можно делать обычному программисту? Ничего.
Собственно, пока не будет развитой системы библиотек, поддерживающих GraphQL нативно, чтобы действительно можно было заниматься решением непосредственных задач, а не тратить всё время на то, чтобы это хоть как-то шевелилось, во имя далёкого светлого будущего, использование GQL остаётся больше академической задачей, чем практической.
-
madkite
26 июля 2017 в 19:36
0↑
↓
Та вроде бы уже хватает библиотек, хотя всё же заметен перекос в сторону ноды.
-
hVostt
26 июля 2017 в 19:47
+1↑
↓
На сколько я вижу, эти библиотеки пока что, грубо говоря, из области «парсинг SQL» :)
Могу ошибаться, но профита для себя (и для нашей компании) пока не вижу.
Но интерес присутствует, наблюдаю уже давно.-
zelenin
26 июля 2017 в 19:59
0↑
↓
На сколько я вижу, эти библиотеки пока что, грубо говоря, из области «парсинг SQL»
поясните фразу.
GraphQL никак не относится с sql, и все что там парсится — это json-оподобный язык запросов фронта.-
hVostt
26 июля 2017 в 20:07
+1↑
↓
Я и не говорил, что относится. Просто привёл пример, представим, что сегодня изобрели SQL, но ещё ни одна СУБД не поддерживает SQL. Какой от него прок? Даже если сам по себе как язык SQL замечательный. Но потом вы говорите, вон же библиотеки есть. Я говорю, вижу, уровень этих библиотек «парсинг SQL» в контексте приведённого мною примера.Если я захочу использовать GQL, то у меня 80% времени (если не все 100) уйдёт тупо на обеспечение его поддержки, собственными костылями и подпорками в виде тех библиотек.
Возьмём для сравнения OData. Я, как программист на .NET, имея под рукой любую СУБД, сложную и развитую схему данных, Entity Framework, подключаю OData и получаю полностью работоспособного сервера, который может обрабатывать OData-запросы с клиентов, отдавать мета-данные и схему, делать фильтрацию по любым полям, сортировку, агрегацию, запрашивать за один round-trip целые графы данных и это будет транслироваться в очень эффективные SQL.
GQL на сегодняшний день может похвастаться только идеей. Но не реализацией. И пока вчистую проигрывает той же OData по всем фронтам. Это не значит, что его время не наступит. Но чтобы его двигать, надо получать пользу прямо сейчас, а не когда мы перепишем весь свой код под GQL, навтыкаем костылей и заставим шевелиться, то тогда может быть, должно быть, всё вообще станет радужно и прекрасно.
 jreznot
jreznot
26 июля 2017 в 21:34 (комментарий был изменён)
0↑
↓
В платформе, которую мы разрабатываем, есть похожий механизм с названием Views. Для запросов можно указать дерево требуемых полей и связей (а точнее имя одного из представлений, зарегистрированных на сервере). Front-end разработчики довольны и могут вытаскивать из REST-API данные с нужной детализацией.Пример в доке: https://doc.cuba-platform.com/manual-6.5/rest_api_v2_ex_get_entities_list.html
Так что совсем не обязательно внедрять GraphQL, можно использовать существующие языки, дополнительно лишь описывая требования к глубине детализации.
