[Из песочницы] Планирование в Go: Часть I — Планировщик ОС
Привет, Хабр! Представляю вашему вниманию перевод статьи «Scheduling In Go: Part I — OS Scheduler» автора Билла Кеннеди, о том, как работает внутренний планировщик Go.
Это первый пост в серии из трех частей, который даст представление о механике и семантике, лежащей в основе планировщика в Go. Этот пост посвящен планировщику операционной системы. Начнем!
Внутренняя архитектура планировщика Go позволяет вашим многопоточным программам быть более эффективными и производительными. Важно иметь общее понимание того, как работают планировщики ОС и Go для правильного проектирования многопоточного программного обеспечения. Я опишу достаточно деталей, чтобы вы могли наглядно представить, как все работает, чтобы на практике принимать лучшие решения.
Планировщик ОС
Планировщики операционной системы являются сложным программным обеспечением. Они должны учитывать расположение и настройку оборудования, на котором они работают. Это включает в себя, помимо прочего, наличие нескольких процессоров и ядер, кэшей ЦП и NUMA. Без этого знания планировщик не может быть настолько эффективным, насколько это возможно.
Ваша программа — это просто набор машинных инструкций, которые должны выполняться последовательно один за другим. Чтобы это произошло, операционная система использует концепцию потока. Задачей потока является учет и последовательное выполнение назначенного ему набора инструкций. Выполнение продолжается до тех пор, пока не останется больше инструкций для выполнения потоком. Вот почему я называю поток, «путь исполнения».
Каждая программа, которую вы запускаете, создает процесс, а каждому процессу — начальный поток. Потоки имеют возможность создавать больше потоков. Все эти разные потоки работают независимо друг от друга, и решения по планированию принимаются на уровне потоков, а не на уровне процессов. Потоки могут работать одновременно (каждый по очереди на отдельном ядре) или параллельно (каждый работает одновременно на разных ядрах). Потоки также поддерживают свое собственное состояние, чтобы обеспечить безопасное, локальное и независимое выполнение их инструкций.
Планировщик ОС отвечает за то, чтобы ядра не простаивали, если есть потоки, которые могут выполняться. Это также должно создать иллюзию того, что все потоки, которые могут выполняться, выполняются одновременно. В процессе создания этой иллюзии планировщик должен запускать потоки с более высоким приоритетом по сравнению с потоками с более низким приоритетом. Тем не менее, потоки с более низким приоритетом не могут быть лишены времени выполнения. Планировщик также должен максимально сократить задержки при планировании, принимая быстрые и умные решения.
Чтобы лучше понять все это, полезно описать и определить несколько важных понятий.
Выполнение инструкций
Счетчик команд, также (instruction pointer) (IP) позволяет потоку отслеживать следующую команду для выполнения. В большинстве процессоров IP указывает на следующую инструкцию, а не на текущую.

Если вы когда-либо видели трассировку стека из программы Go, вы могли заметить эти маленькие шестнадцатеричные числа в конце каждой строки. Смотрите + 0×39 и + 0×72 в листинге 1.
Листинг 1
goroutine 1 [running]:
main.example(0xc000042748, 0x2, 0x4, 0x106abae, 0x5, 0xa)
stack_trace/example1/example1.go:13 +0x39 <- Здесь
main.main()
stack_trace/example1/example1.go:8 +0x72 <- И здесь
Эти числа представляют смещение значения IP от вершины соответствующей функции. Значение смещения + 0×39 для IP представляет следующую инструкцию, которую поток выполнил бы внутри примерной функции, если бы программа не запаниковала. Значение смещения IP 0 + x72 является следующей инструкцией внутри основной функции, если управление вернулось к этой функции. Что еще более важно, инструкция перед указателем сообщает вам, какая инструкция выполнялась.
Посмотрите на программу ниже в листинге 2, которая вызвала трассировку стека из листинга 1.
Листинг 2
// https://github.com/ardanlabs/gotraining/blob/master/topics/go/profiling/stack_trace/example1/example1.go
07 func main() {
08 example(make([]string, 2, 4), "hello", 10)
09 }
12 func example(slice []string, str string, i int) {
13 panic("Want stack trace")
14 }
Шестнадцатеричное число + 0×39 представляет смещение IP для инструкции внутри примерной функции, которая на 57 (основание 10) байтов ниже начальной инструкции для функции. В листинге 3 ниже вы можете увидеть objdump примера функции из двоичного файла. Найдите 12-ю инструкцию, которая указана внизу. Обратите внимание на строку кода над этой инструкцией — вызов паники.
Листинг 3
func example(slice []string, str string, i int) {
0x104dfa 065488b0c2530000000 MOVQ GS:0x30, CX
0x104dfa9 483b6110 CMPQ 0x10(CX), SP
0x104dfad 762c JBE 0x104dfdb
0x104dfaf 4883ec18 SUBQ $0x18, SP
0x104dfb3 48896c2410 MOVQ BP, 0x10(SP)
0x104dfb8 488d6c2410 LEAQ 0x10(SP), BP
panic("Want stack trace")
0x104dfbd 488d059ca20000 LEAQ runtime.types+41504(SB), AX
0x104dfc4 48890424 MOVQ AX, 0(SP)
0x104dfc8 488d05a1870200 LEAQ main.statictmp_0(SB), AX
0x104dfcf 4889442408 MOVQ AX, 0x8(SP)
0x104dfd4 e8c735fdff CALL runtime.gopanic(SB)
0x104dfd9 0f0b UD2 <--- Здесь IP(+0x39)
Помните: IP указывает на следующую инструкцию, а не текущую. В листинге 3 приведен хороший пример инструкций на основе amd64, которые поток для этой программы Go выполняет последовательно.
Состояния потоков
Другим важным понятием является состояние потока. Поток может находиться в одном из трех состояний: Ожидание, Готовность или Выполнение.
Ожидание: это означает, что поток остановлен и ожидает чего-то для продолжения. Это может происходить по таким причинам, как ожидание аппаратного обеспечения (диск, сеть), операционной системы (системные вызовы) или вызовов синхронизации (атомарные, мьютексы). Эти типы задержек являются основной причиной плохой производительности.
Готовность: это означает, что поток требует времени на ядре, чтобы он мог выполнять назначенные ему машинные инструкции. Если у вас много потоков, которым нужно время, потоки должны ждать дольше, чтобы получить время. Кроме того, сокращается отдельное количество времени, которое получает каждый поток, поскольку большее количество потоков конкурирует за время. Этот тип задержки планирования также может быть причиной плохой производительности.
Выполнение: Это означает, что поток размещен на ядре и выполняет свои машинные инструкции.
Типы работ
Поток может выполнять два типа работ. Первый называется CPU-Bound, а второй — IO-Bound.
CPU-Bound: это работа, которая никогда не создает ситуацию, когда поток может быть переведен в состояние ожидания. Это работа, которая постоянно делает расчеты. Поток, вычисляющий число Pi до N-й цифры, будет привязан к ЦП.
IO-Bound: это работа, которая заставляет потоки переходить в состояние ожидания. Это работа, которая заключается в запросе доступа к ресурсу по сети или выполнении системных вызовов в операционной системе. Поток, которому необходим доступ к базе данных, будет IO-Bound. Я бы включил события синхронизации (мьютексы, атомарные), которые заставляют поток ждать как часть этой категории.
Переключение контекста
Если вы работаете в Linux, Mac или Windows, вы работаете в операционной системе с вытесняющим планировщиком.
Невытесняющие (non-preemptive) алгоритмы основаны на том, что активному потоку позволяется выполняться, пока он сам, по собственной инициативе, не отдаст управление операционной системе для того, чтобы та выбрала из очереди другой готовый к выполнению поток.Вытесняющие (preemptive) алгоритмы — это такие способы планирования потоков, в которых решение о переключении процессора с выполнения одного потока на выполнение другого потока принимается операционной системой, а не активной задачей.
Это означает несколько важных вещей.
Во-первых, это означает, что планировщик непредсказуем, когда речь заходит о том, какие потоки будут выбраны для запуска в любой момент времени. Приоритеты потоков вместе с событиями (например, получение данных в сети) делают невозможным определение того, что планировщик выберет и когда.
Во-вторых, это означает, что вы никогда не должны писать код, основанный на некотором предполагаемом поведении, которое вам повезло испытать, но не гарантируется, что оно будет происходить каждый раз. Легко позволить себе думать, потому что я видел, как это происходило 1000 раз, это гарантированное поведение. Вы должны контролировать синхронизацию и оркестровку потоков, если вам нужен детерминизм в вашем приложении.
Процесс прекращения выполнения процессором одной задачи с сохранением всей необходимой информации и состояния, необходимых для последующего продолжения с прерванного места, и восстановления и загрузки состояния задачи, к выполнению которой переходит процессор называется переключением контекста (ПК). ПК происходит, когда планировщик берет поток выполнения из ядра и заменяет его потоком из состояния готовности. Поток, выбранный из очереди выполнения, переходит в состояние «Выполнение». Поток, который был извлечен, может вернуться в состояние готовности (если он все еще имеет возможность запуска) или в состояние ожидания (если был заменен из-за типа запроса IO-Bound).
ПК считается дорогостоящей операцией. Величина задержки, возникающей во время ПК, зависит от различных факторов, но вполне разумно, чтобы она занимала от ~ 1000 до ~ 1500 наносекунд. Учитывая, что аппаратное обеспечение должно быть в состоянии разумно выполнять (в среднем) 12 инструкций в наносекунду на ядро, переключение контекста может стоить от ~ 12k до ~ 18k инструкций задержки. По сути, ваша программа теряет способность выполнять большое количество инструкций во время переключения контекста.
Если у вас есть программа, ориентированная на работу, связанную с IO, то переключение контекста будет преимуществом. Как только поток переходит в состояние ожидания, его место занимает другой поток в состоянии готовности. Это позволяет ядру всегда выполнять работу. Это один из самых важных аспектов планирования. Не позволяйте ядру бездействовать, если есть работа (потоки в состоянии «Готовность»).
Если ваша программа ориентирована на работу с привязкой к ЦП, переключение контекста станет кошмаром производительности. Поскольку у потока всегда есть работа, переключение контекста останавливает эту работу. Эта ситуация резко контрастирует с тем, что происходит с нагрузкой IO-Bound.
Меньше — больше
Ранее, когда у процессоров было только одно ядро, планирование не было слишком сложным. Поскольку у вас был один процессор с одним ядром, только один поток мог выполняться в любой момент времени. Идея состояла в том, чтобы определить период планировщика и попытаться выполнить все потоки в состоянии готовности, в течение этого периода времени. Нет проблем: возьмите период планирования и разделите его на количество потоков, которые необходимо выполнить.
Например, если вы определили период вашего планировщика равным 10 мс (миллисекунд), и у вас есть 2 потока, то каждый поток получает 5 мс каждый. Если у вас есть 5 потоков, каждый поток получает 2 мс. Однако что происходит, когда у вас есть 100 потоков? Предоставление каждому потоку отрезка времени в 10 мкс (микросекунд) не работает, потому что вы потратите значительное количество времени на ПК.
Что вам нужно, так это ограничить, насколько короткими могут быть временные срезы. В последнем сценарии, если минимальный интервал времени составлял 2 мс, а у вас 100 потоков, период планировщика необходимо увеличить до 2000 мс или 2 сек. Что, если было 1000 потоков, теперь вы смотрите на период планировщика 20 сек. В этом простом примере все потоки запускаются один раз в течение 20 сек, если каждый поток использует свой временной интервал.
Имейте в виду, что это очень простой взгляд на эти проблемы. Планировщик должен принимать во внимание большее количество проблем. Вы контролируете количество потоков, которые вы используете в своем приложении. Когда нужно рассмотреть больше потоков и происходит работа, связанная с IO, возникает еще больше хаоса и не детерминированного поведения. Решение проблем занимают больше времени, чтобы запланировать и выполнить.
Вот почему правило «Меньше значит больше». Меньше потоков в состоянии «Готовность» означает меньше затрат на планирование и больше времени, которое каждый поток получает с течением времени. Чем больше потоков в состоянии «Готовность», тем меньше времени получает каждый поток. Это означает, что со временем будет выполняться меньше вашей работы.
Ищем баланс
Необходимо найти баланс между количеством ядер, которое у вас есть, и количеством потоков, которое необходимо для достижения максимальной пропускной способности для вашего приложения. Когда дело доходит до управления этим балансом, пулы потоков были отличным ответом. Я покажу вам во второй части, что в Go больше нет этой необходимости. Я думаю, что это одна из приятных вещей, которую в Go сделали для облегчения разработки многопоточных приложений.
До написания кода на Go я написал код на C ++ и C # для NT. В этой операционной системе использование пулов потоков IOCP (IO Completion Ports) было критически важным для написания многопоточного программного обеспечения. Как инженер, вам нужно было выяснить, сколько пулов потоков вам нужно, и максимальное количество потоков для любого данного пула, чтобы максимизировать пропускную способность для числа ядер, которые у вас есть.
При написании веб-сервисов, взаимодействующих с базой данных, магическое число 3 потока на ядро, всегда обеспечивало наилучшую пропускную способность в NT. Другими словами, 3 потока на ядро минимизировали затраты времени на переключение контекста, максимально увеличив время выполнения на ядрах. При создании пула потоков IOCP я знал, что нужно начинать минимум с 1 потока и максимум с 3 потоками на каждое ядро, идентифицированное на хост-компьютере.
Если бы я использовал 2 потока на ядро, это заняло бы больше времени, чтобы выполнить всю работу, потому что у меня был простой, когда я мог выполнять работу. Если я использовал 4 потока на ядро, это также занимало больше времени, потому что у меня было больше задержек при ПК. Баланс 3 потоков на ядро по любой причине всегда казался магическим числом в NT.
Что делать, если ваш сервис выполняет много разных видов задач? Это может создать разные и противоречивые задержки. Возможно, он также создает множество различных системных событий, которые необходимо обработать. Может оказаться невозможным найти магическое число, которое работает все время для всех различных рабочих нагрузок. Когда речь идет об использовании пулов потоков для настройки производительности службы, очень сложно найти правильную согласованную конфигурацию.
Кэш процессора
Доступ к данным из основной памяти имеет такую высокую стоимость задержки (от ~ 100 до ~ 300 тактов), что процессоры и ядра имеют локальные кэши для хранения данных близко к аппаратным потокам, которые в них нуждаются. Доступ к данным из кеша обходится намного дешевле (от 3 до 40 тактов) в зависимости от доступа к кешу. Сегодня одним из аспектов производительности является то, насколько эффективно вы можете передавать данные в процессор, чтобы уменьшить эти задержки доступа к данным. При написании многопоточных приложений, которые изменяют состояние, необходимо учитывать механику системы кеширования.

Обмен данными между процессором и основной памятью осуществляется с использованием строк кэша. Строка кэша — это 64-байтовый фрагмент памяти, который обменивается между основной памятью и системой кэширования. Каждое ядро получает свою собственную копию любой строки кэша, в которой оно нуждается, что означает, что аппаратное обеспечение использует семантику значений. Вот почему мутации в памяти в многопоточных приложениях могут создавать кошмары производительности.
Когда несколько потоков, работающих параллельно, обращаются к одному и тому же значению данных или даже к значениям данных рядом друг с другом, они будут получать доступ к данным в одной строке кэша. Любой поток, работающий на любом ядре, получит свою копию этой же строки кэша.
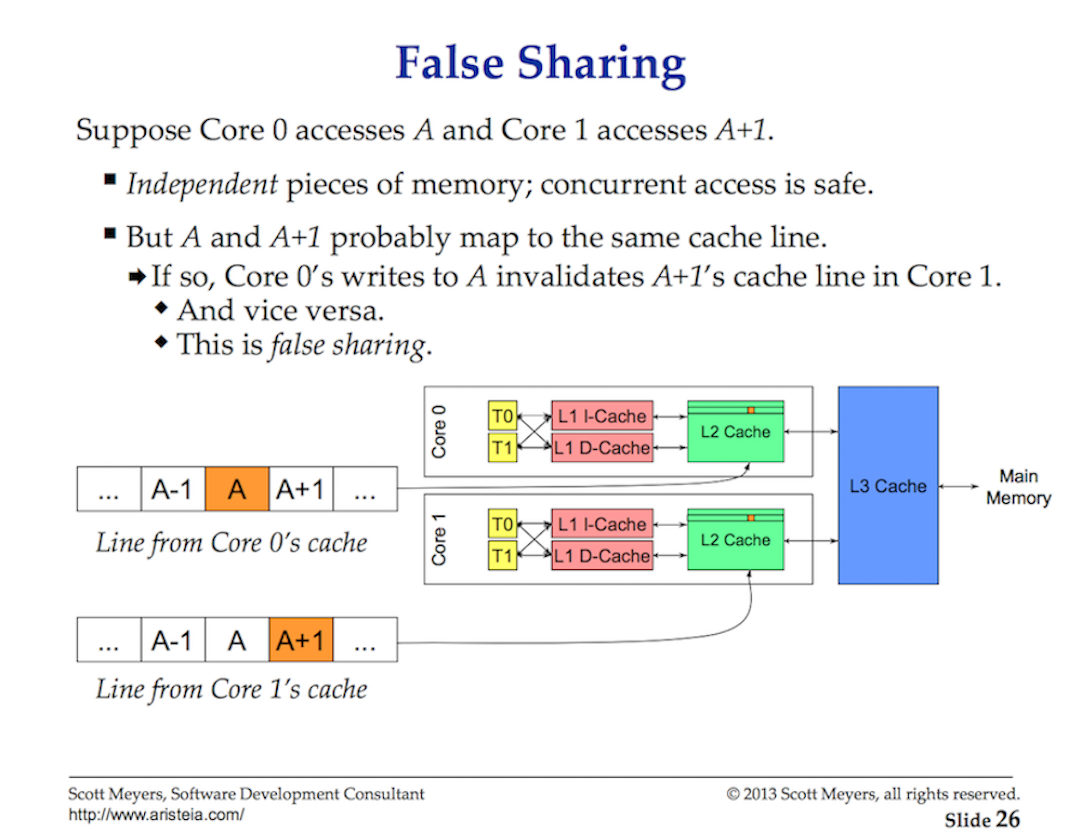
Если один поток в данном ядре вносит изменения в свою копию строки кэша, то с помощью аппаратного обеспечения все остальные копии той же строки кэша должны быть помечены как грязные. Когда Поток пытается получить доступ на чтение или запись к грязной строке кэша, доступ к основной памяти (от ~ 100 до ~ 300 тактовых циклов) необходим для получения новой копии строки кэша.
Может быть, на 2-ядерном процессоре это не имеет большого значения, но как быть с 32-ядерным процессором, на котором 32 потока работают параллельно, все получают и изменяют данные в одной строке кэша? А как насчет системы с двумя физическими процессорами по 16 ядер в каждом? Это будет хуже из-за дополнительной задержки для связи между процессорами. Приложение будет перебирать память, а производительность будет ужасной, и, скорее всего, вы не поймете, почему.
Это называется проблемой когерентности кэша, а также приводит к таким проблемам, как ложное совместное использование. При написании многопоточных приложений, которые будут изменять общее состояние, системы кэширования должны быть приняты во внимание.
Итог
Эта первая часть поста дает представление о том, что вы должны учитывать в отношении потоков и планировщика ОС при написании многопоточных приложений. Эти вещи и учитывает планировщик Go. В следующем посте я опишу семантику планировщика Go и то, как они связаны с этой информацией. Затем, наконец, вы увидите все это в действии, запустив пару программ.
