[Из песочницы] Особенности проектирования модели данных для NoSQL
Введение
 «Нужно бежать со всех ног, чтобы только оставаться на месте,
«Нужно бежать со всех ног, чтобы только оставаться на месте,
а чтобы куда-то попасть, надо бежать как минимум вдвое быстрее!»
(с) Алиса в стране чудес
Некоторое время назад меня попросили прочитать лекцию аналитикам нашей компании на тему проектирования моделей данных, ведь сидя долгое время на проектах (порою по нескольку лет) мы упускаем из виду происходящее вокруг в мире ИТ-технологий. В нашей компании (уж так получилось) на многих проектах не используются NoSQL-базы данных (по крайней мере пока), поэтому в своей лекции я отдельно уделил им некоторое внимание на примере HBase и постарался ориентировать изложение материала на тех, кто с ними никогда не работал. В частности, я иллюстрировал некоторые особенности проектирования модели данных на примере, который несколько лет назад прочитал в статье «Introduction to HB ase Schema Design» by Amandeep Khurana. Разбирая примеры, я сравнивал между собой несколько вариантов решения одной и той же задачи, чтобы лучше донести до слушателей основные идеи.
Недавно, «от нечего делать», я задался вопросом (длинные майские выходные в режиме карантина к этому особенно располагают), насколько теоретические выкладки будут соответствовать практике? Собственно, так и родилась идея этой статьи. Разработчик, который не первый день работает с NoSQL, возможно и не почерпнет из нее что-то новое (и поэтому может сразу помотать полстатьи). Но для аналитиков, которые еще не работали плотно с NoSQL, полагаю, она будет полезна для получения базовых представлений об особенностях проектирования моделей данных для HBase.
Разбор примера
На мой взгляд, прежде чем начать использовать NoSQL базы данных, необходимо хорошо подумать и взвесить «за» и «против». Часто задачу скорее всего можно решить и на традиционных реляционных СУБД. Поэтому лучше не использовать NoSQL без существенных на то оснований. Если все же было принято решение использовать NoSQL базу данных, то следует учесть, что подходы к проектированию здесь несколько отличаются. Особенно некоторые из них могут быть непривычны тем, кто до этого имел дело только с реляционными СУБД (по моим наблюдениям). Так, в «реляционном» мире мы обычно идем от моделирования предметной области, и уже потом при необходимости проводим денормализацию модели. В NoSQL же мы сразу должны учитывать предполагаемые сценарии работы с данными и изначально денормализовывать данные. Кроме того, есть ряд других отличий, о которых будет написано ниже.
Рассмотрим следующую «синтетическую» задачу, с которой и будем далее работать:
Необходимо спроектировать структуру хранения списка друзей пользователей некой абстрактной социальной сети. Для упрощения будем полагать, что все связи у нас направленные (как в Инстаграмме, а не в Linkedin). Структура должна позволять эффективно:
- Отвечать на вопрос, читает ли пользователь А пользователя Б (шаблон чтения)
- Позволять добавлять/удалять связи в случае подписки/отписки пользователя А от пользователя Б (шаблон изменения данных)
Конечно же, вариантов решения задачи множество. В обычной реляционной БД мы бы скорее всего просто сделали бы таблицу связей (возможно, типизированную, если, например, требуется хранить пользовательскую группу: семья, работа и т.п., в которую входит данный «друг»), а для оптимизации скорости доступа добавили бы индексы/партиционирование. Скорее всего итоговая таблица выглядела бы примерно вот так:
здесь и далее для наглядности и лучшего понимания вместо ID буду указывать имена
В случае же с HBase мы знаем, что:
- эффективный поиск, не приводящий к full table scan, возможен исключительно по ключу
- собственно, поэтому писать привычные многим SQL-запросы к подобным базам – плохая идея; технически, конечно, вы можете из той же Impala отправить SQL-запрос с Join’ами и прочей логикой в HBase, но вот насколько это будет эффективно…
Поэтому ID пользователя мы вынуждены использовать как ключ. А первой мыслью на тему «где и как хранить ID друзей?» может быть идея хранения их в колонках. Этот самый очевидный и «наивный» вариант будет выглядеть примерно так (назовем его Вариант 1 (default), чтобы ссылаться в дальнейшем):
Здесь каждая строка соответствует одному пользователю сети. Колонки имеют имена: 1, 2, … — по количеству друзей, и в колонках хранятся ID друзей. Важно заметить, что у каждой строки будет разное число колонок. В примере на рисунке выше одна строка имеет три колонки (1, 2 и 3), а вторая – только две (1 и 2) – здесь мы сами воспользовались двумя свойствами HBase, которых нет у реляционных БД:
- возможностью динамически менять состав колонок (добавляем друга -> добавляем колонку, удаляем друга -> удаляем колонку)
- у разных строк может быть различный состав колонок
Проверим нашу структуру на соответствие требованиям задачи:
- Чтение данных: для того, чтобы понять, подписан ли Вася на Олю, нам надо будет вычитать всю строку по ключу RowKey = «Вася» и перебирать значения колонок, пока не «встретим» в них Олю. Или перебрать значения всех колонок, «не встретить» Олю и вернуть ответ False;
- Изменение данных: добавление друга: для подобной задачи нам так же потребуется вычитать всю строку по ключу RowKey = «Вася», чтобы посчитать общее количество его друзей. Это общее кол-во друзей нам необходимо, чтобы определить номер колонки, в которую надо записать ID нового друга.
- Изменение данных: удаление друга:
- Необходимо вычитать всю строку по ключу RowKey = «Вася» и перебирать колонки для того, чтобы найти ту самую, в которой записан удаляемый друг;
- Далее нам, после удаления друга, надо «сдвинуть» все данные на одну колонку, чтобы не получить «разрывов» в их нумерации.
Давайте теперь оценим, насколько данные алгоритмы, которые нам необходимо будет реализовывать на стороне «условного приложения», будут производительны, используя О-символику. Обозначим размер нашей гипотетической социальной сети как n. Тогда максимальное число друзей у одного пользователя может быть (n-1). Этой (-1) мы можем в дальнейшем пренебречь для наших целей, так как в рамках использования О-символики она несущественна.
- Чтение данных: необходимо вычитать всю строку и перебрать в пределе все ее колонки. Значит верхняя оценка затрат будет примерно О(n)
- Изменение данных: добавление друга: для определения количества друзей требуется перебрать все колонки строки, после чего вставить новую колонку => О(n)
- Изменение данных: удаление друга:
- Аналогично добавлению – требуется в пределе перебрать все колонки => О(n)
- После удаления колонок нам надо «сдвинуть» их. Если реализовывать это «в лоб», то в пределе потребуется еще до (n-1) операций. Но мы здесь и далее в практической части применим иной подход, который будет реализовывать «псевдо-сдвиг» за фиксированное кол-во операций – то есть на него будет тратиться константное время вне зависимости от n. Этим константным временем (если быть точным, то О(2)) по сравнению с О(n) можно пренебречь. Подход проиллюстрирован на рисунке ниже: мы просто копируем данные из «последней» колонки в ту, из которой надо удалить данные, после чего удаляем последнюю колонку:
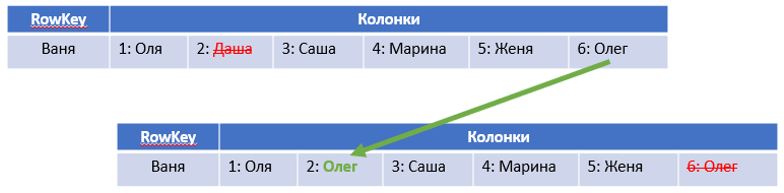
Итого, во всех сценариях мы получили асимптотическую вычислительную сложность O(n).
Наверное, вы уже заметили, что нам приходится почти всегда вычитывать из базы всю строку целиком, причем в двух случаях из трех только для того, чтобы перебрать все колонки и посчитать общее кол-во друзей. Поэтому в качестве попытки оптимизации можно добавить колонку «count», в которой хранить общее число друзей каждого пользователя сети. В этом случае мы можем не вычитывать всю строку целиком для подсчета общего кол-ва друзей, а прочитать только одну колонку «count». Главное, не забывать обновлять «count» при манипуляции с данными. Т.о. получаем улучшенный Вариант 2 (count):
По сравнению с первым вариантом:
- Чтение данных: для получения ответа на вопрос «Читает ли Вася Олю?» ничего не изменилось => О(n)
- Изменение данных: добавление друга: Мы упростили вставку нового друга, так как теперь нам не надо вычитывать всю строку и перебирать ее колонки, а можно получить только значение колонки «count» и т.о. сразу определить номер колонки для вставки нового друга. Это приводит к снижению вычислительной сложности до О(1)
- Изменение данных: удаление друга: При удалении друга мы можем так же воспользоваться данной колонкой, чтобы снизить количество операций ввода-вывода при «сдвиге» данных на одну ячейку влево. Но необходимость перебора колонок для поиска той, которую необходимо удалить, все равно остается, поэтому => O(n)
- С другой стороны, теперь нам при обновлении данных необходимо каждый раз обновлять и колонку «count», но на это уходит константное время, которым в рамках О-символики можно пренебречь
В целом вариант 2 видится чуть более оптимальным, но это скорее «эволюция вместо революции». Для совершения «революции» нам понадобится Вариант 3 (col).
Перевернем все «с ног на голову»: назначим именем колонки идентификатор пользователя! Что будет записано в самой колонке – для нас уже не суть важно, пусть будет цифра 1 (вообще, из полезного там можно хранить, например, группу «семья/друзья/и т.п.»). Данный подход может удивить неподготовленного «обывателя», который до этого не имел опыта работы с NoSQL-базами, но именно он позволяет использовать потенциал HBase в данной задаче намного эффективнее:
Здесь мы получаем сразу несколько преимуществ. Чтобы их понять, проанализируем новую структуру и оценим вычислительную сложность:
- Чтение данных: для того, чтобы ответить на вопрос, подписан ли Вася на Олю, достаточно прочитать одну колонку «Оля»: если она есть, то ответ True, если нет – False => O(1)
- Изменение данных: добавление друга: Добавление друга: достаточно просто добавить новую колонку «ID друга» => O(1)
- Изменение данных: удаление друга: достаточно просто удалить колонку «ID друга» => O(1)
Как видим, существенным преимуществом такой модели хранения является то, что мы во всех необходимых нам сценариях оперируем только одной колонкой, избегая вычитывания из базы всей строки и тем более, перебора всех колонок этой строки. На этом можно было бы остановиться, но…
Можно озадачиться и пойти еще немного дальше по пути оптимизации производительности и уменьшения операций ввода-вывода при обращении к базе. Что если хранить полную информацию о связи непосредственно в самом ключе строки? То есть сделать ключ составным вида userID.friendID? В этом случае нам вообще можно даже не вычитывать колонки строки (Вариант 4(row)):
Очевидно, что оценка всех сценариев манипуляции с данными в такой структуре также, как и в предыдущем варианте будет О(1). Разница с вариантом 3 будет уже исключительно в эффективности операций ввода-вывода в БД.
Ну и последний «бантик». Легко заметить, что в варианте 4 у нас ключ строки будет иметь переменную длину, что, возможно, может повлиять на производительность (тут вспоминаем, что HBase хранит данные как набор байтов и строки в таблицах отсортированы по ключу). Плюс у нас есть разделитель, который в некоторых сценариях может потребоваться обрабатывать. Чтобы исключить это влияние, можно использовать хэши от userID и friendID, и так как оба хэша будут иметь постоянную длину, то можно просто конкатенировать их, без разделителя. Тогда данные в таблице будут выглядеть так (Вариант 5(hash)):
Очевидно, что алгоритмическая сложность работы с такой структурой по рассматриваемом нами сценариями, будет такая же, как у варианта 4 – то есть О(1).
Итого, сведем все наши оценки вычислительной сложности в одну таблицу:
Как видно, варианты 3-5 выглядят наиболее предпочтительным и теоретически обеспечивает выполнение всех необходимых сценариев манипуляции с данными за константное время. В условии нашей задачи нет явного требования по получению списка всех друзей пользователя, но в реальной проектной деятельности нам, как хорошим аналитикам, хорошо бы «предвидеть», что подобная задача может возникнуть и «подстелить соломку». Поэтому мои симпатии на стороне варианта 3. Но вполне вероятно, что в реальном проекте данный запрос могл быть уже решен иными средствами, поэтому без общего видения всей задачи лучше не делать окончательных выводов.
Подготовка эксперимента
Вышеизложенные теоретические рассуждения хотелось бы проверить на практике – это и было целью возникшей на долгих выходных задумки. Для этого необходимо оценить скорость работы нашего «условного приложения» во всех описанных сценариях использования базы, а также рост этого времени с ростом размера социальной сети (n). Целевым параметром, который нас интересует и который мы будем замерять в ходе эксперимента, является время, затраченное «условным приложением», на выполнение одной «бизнес-операции». Под «бизнес-операцией» мы понимаем одну из следующих:
- Добавление одного нового друга
- Проверка, является ли пользователь А другом пользователя Б
- Удаление одно друга
Таким образом, с учетом обозначенных в изначальной постановке требований, сценарий проверки вырисовывается следующий:
- Запись данных. Сгенерировать случайным образом исходную сеть размером n. Для большего приближения к "реальному миру" количество друзей у каждого пользователя – так же случайная величина. Замерить время, за которое наше «условное приложение» запишет в HBase все сгенерированные данные. Потом полученное время разделить на общее количество добавленных друзей – так мы получим среднее время на одну «бизнес-операцию»
- Чтение данных. Для каждого пользователя составить список «личностей», для которых надо получить ответ, подписан ли на них пользователь или нет. Длина списка = примерно кол-ву друзей пользователя, причем для половины проверяемых друзей ответ должен быть «Да», а для другой половины – «Нет». Проверка производится в таком порядке, чтобы ответы «Да» и «Нет» чередовались (то есть в каждом втором случае нам придется перебирать все колонки строки для вариантов 1 и 2). Общее время проверки затем разделить на количество проверяемых друзей для получения среднего времени на проверку одного субъекта.
- Удаление данных. Удалить у пользователя всех друзей. Причем порядок удаления – случайный (то есть «перемешиваем» изначальный список, использовавшийся для записи данных). Общее время проверки затем разделить на количество удаляемых друзей для получения среднего времени на одну проверку.
Сценарии необходимо прогнать для каждого из 5 вариантов моделей данных и для разных размеров социальной сети, чтобы посмотреть, как меняется время с ее ростом. В рамках одного n связи в сети и список пользователей для проверки должны быть, естественно, одинаковыми для всех 5 вариантов.
Для лучшего понимания ниже привожу пример сгенерированных данных для n= 5. Написанный «генератор» дает на выходе три словаря ID-шников:
- первый – для вставки
- второй – для проверки
- третий – для удаления
{0: [1], 1: [4, 5, 3, 2, 1], 2: [1, 2], 3: [2, 4, 1, 5, 3], 4: [2, 1]} # всего 15 друзей
{0: [1, 10800], 1: [5, 10800, 2, 10801, 4, 10802], 2: [1, 10800], 3: [3, 10800, 1, 10801, 5, 10802], 4: [2, 10800]} # всего 18 проверяемых субъектов
{0: [1], 1: [1, 3, 2, 5, 4], 2: [1, 2], 3: [4, 1, 2, 3, 5], 4: [1, 2]} # всего 15 друзей
Как можно заметить, все ID, большие 10 000 в словаре для проверки – это как раз те, которые заведомо дадут ответ False. Вставка, проверка и удаление «друзей» производятся именно в указанной в словаре последовательности.
Эксперимент проводился на ноутбуке под управлением Windows 10, где в одном докер-контейнере была запущена база HBase, а в другом – Python с Jypyter Notebook. Докеру было выделено 2 ядра CPU и 2 Гб оперативной памяти. Вся логика, как и эмуляции работы «условного приложения», так и «обвязка» для генерации тестовых данных и замера времени были написаны на Python. Для работы с HBase использовалась библиотека happybase , для вычисления хэшей (MD5) для варианта 5 — hashlib
С учетом вычислительной мощности конкретного ноутбука экспериментально был выбран запуск для n = 10, 30, …. 170 – когда общее время работы полного цикла тестирования (все сценарии для всех вариантов для всех n) было еще более-менее разумным и умещалось во время одного чаепития (в среднем 15 минут).
Тут необходимо сделать ремарку, что в данном эксперименте мы в первую очередь оцениваем не абсолютные цифры производительности. Даже относительное сравнение разных двух вариантов может быть не совсем корректным. Сейчас нас интересует именно характер изменения времени в зависимости от n, так как с учетом указанной выше конфигурации «тестового стенда» получить временные оценки, «очищенные» от влияния случайных и прочих факторов, очень сложно (да и такой задачи не ставилось).
Результат эксперимента
Первый тест – как меняется время, затрачиваемое на заполнение списка друзей. Результат – на графике ниже.
Вариантs 3-5 ожидаемо показывают практически константное время «бизнес-операции», которое не зависит от роста размера сети и неотличимую разницу в производительности.
Вариант 2 показывает тоже константную, но чуть худшую производительность, причем практически ровно в 2 раза относительно вариантов 3-5. И это не может не радовать, так соотноситься с теорией – в этом варианте количество операций ввода-вывода в/из HBase как раз 2 раза больше. Это может служить косвенным свидетельством, что наш тестовый стенд в принципе дает неплохую точность.
Вариант 1 так же ожидаемо оказывается самым медленным и демонстрирует линейный от размера сети рост времени, затрачиваемого на добавление одно друга.
Посмотрим теперь результаты второго теста.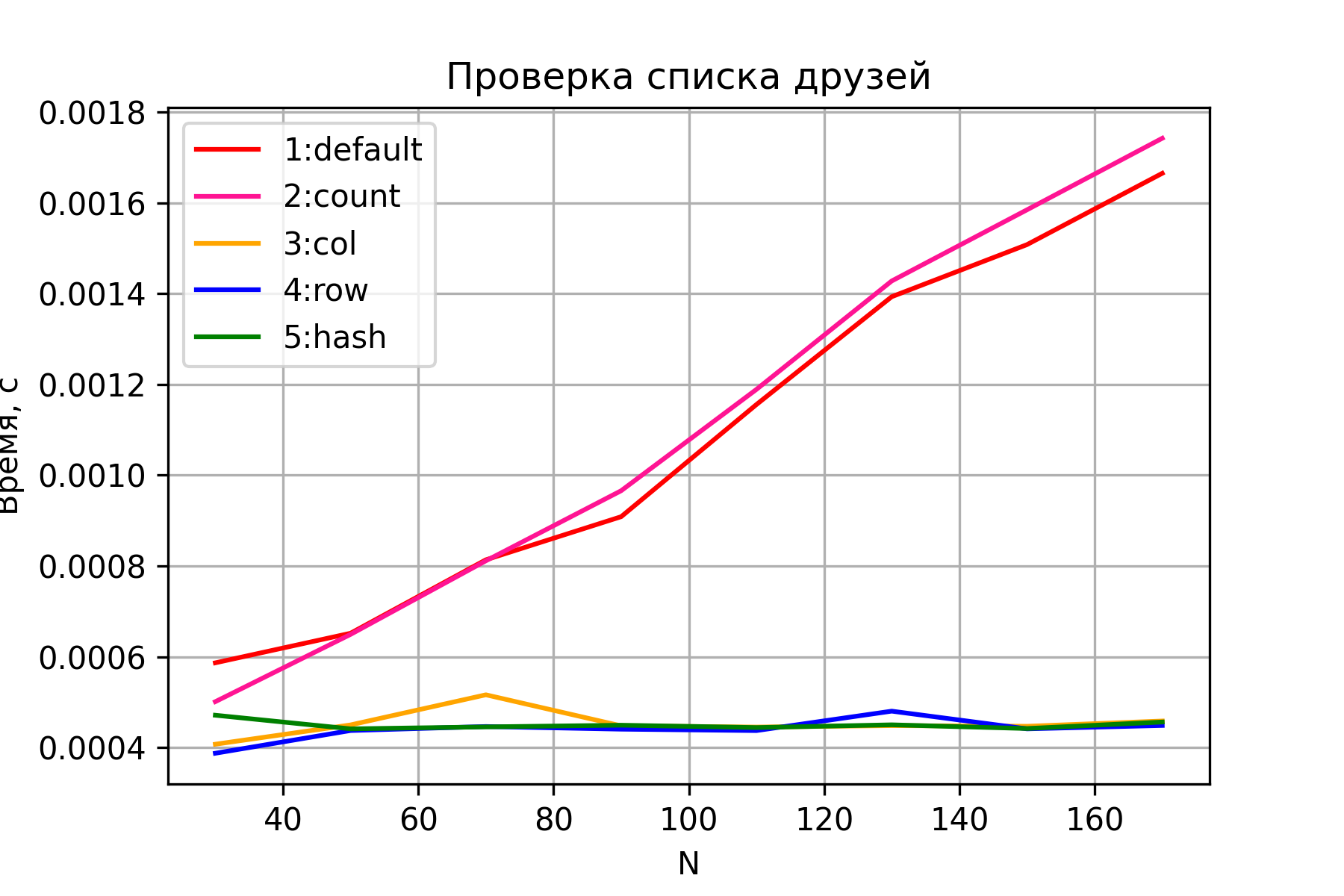
Варианты 3-5 опять же ведет себя ожидаемо – константное время, не зависящее от размера сети. Варианты 1 и 2 демонстрируют линейный рост времени при росте размера сети и схожую производительность. Причем вариант 2 оказывается чуть медленнее – по всей видимости из-за необходимости вычитки и обработки дополнительной колонки «count», что при росте n становится более заметным. Но я все же воздержусь от каких-либо выводов, так как точность данного сравнения все же невысока. Кроме того, данные соотношения (какой вариант, 1 или 2, быстрее) менялись от запуска к запуску (при этом сохраняя характер зависимости и "идя ноздря в ноздрю").
Ну и последний график – результат тестирования удаления.

Здесь опять же без сюрпризов. Варианты 3-5 осуществляют удаление за константное время.
Причем, что интересно, варианты 4 и 5, в отличии от предыдущих сценариев, показывают заметную чуть худшую производительность, чем вариант 3. По всей видимости, операция удаления строки – более затратная, нежели операция удаления колонки, что в целом логично.
Варианты 1 и 2, ожидаемо, демонстрируют линейный рост времени. При этом вариант 2 стабильно медленнее варианта 1 – из-за дополнительной операции ввода-вывода по «обслуживанию» колонки count.
Общие выводы эксперимента:
- Варианты 3-5 демонстрируют бОльшую эффективность, так как они использует преимущества HBase; при этом их производительность отличается друг относительно друга на константу и не зависит от размера сети.
- Разница между вариантами 4 и 5 не была зафиксирована. Но это не значит, что вариант 5 не следует использовать. Вполне вероятно, что используемый сценарий эксперимента с учетом ТТХ тестового стенда не позволил ее выявить.
- Характер роста времени, необходимого на выполнение «бизнес-операций» с данными, в целом подтвердил полученные ранее теоретические выкладки для всех вариантов.
Эпилог
Проведенные грубые эксперименты не следует воспринимать как абсолютную истину. Есть множество факторов, которые не были учтены и вносили искажения в результаты (особенно хорошо эти флуктуации видны на графиках при небольшом размере сети). Например, скорость работы thrift, который используется happybase, объем и способ реализации логики, которая у меня была написана на Python (не берусь утверждать, что код был написан оптимально и эффективно использовал возможности всех компонент), возможно особенности кэширования HBase, фоновая активность Windows 10 на моем ноутбуке и т.п. В целом можно считать, что все теоретические выкладки экспериментально показали свою состоятельность. Ну или как минимум опровергнуть их таким вот «наскоком в лоб» не получилось.
В заключении — рекомендации всем, кто только начинает проектировать модели данных в HBase: абстрагируйтесь от предыдущего опыта работы с реляционными базами и помните «заповеди»:
- Проектируя, идем от задачи и шаблонов манипуляции с данными, а не от модели предметной области
- Эффективный доступ (без full table scan) – только по ключу
- Денормализация
- Разные строки могу содержать разные колонки
- Динамический состав колонок
