[Из песочницы] Опыт решения проблемы созданием OLAP-куба, используя С#
Предыстория Хотел бы поделиться своим небольшим опытом, который я приобрел на работе в одном государственном учреждении. Как я туда попал — не важно, но это важно знать, т.к. это налагает свою специфику на условия, в которых приходилось решать поставленную задачу. Стоит так же отметить, что основные мои знания и скудный опыт в программировании относятся к .Net технологиям.Описание задачи: существует и по сей день созданная лет 10 назад информационная система, которая собирает отчетную информацию, по разным, периодически изменяющимся статистическим показателям, от разных филиалов организации по региону. Инфраструктура информационного взаимодействия системы указана на рисунке ниже. Показатели в DW описаны неявно.
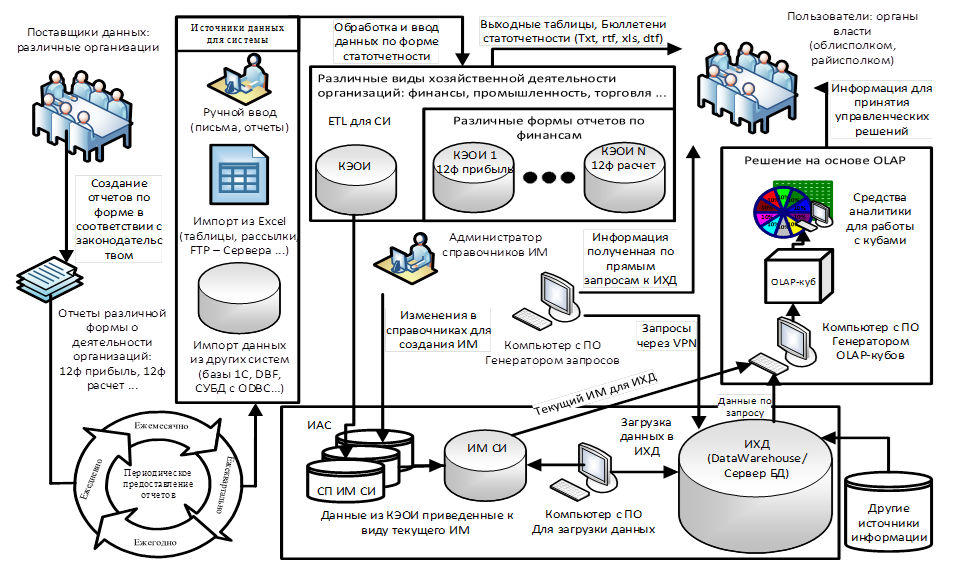 Короткое пояснение к рисунку:
Короткое пояснение к рисунку:
0. DW. Хранилище данных на Oracle с очень не простой моделью.1. СИ. Статистическая информация — показатели бухгалтерской, финансовой и т.п. отчетности.2. КЭОИ. Комплексы электронной обработки статистической информации, созданные локально.3. ИМ. Интерфейсный массив — модель описывающая какие перечни СИ есть в DW.4. СП ИМ СИ. Система подготовки интерфейсных массивов статистической информации предназначена для сбора данных из КЭОИ, преобразования их в формат ИМ и передачи этого массива для загрузки в DW.
Описание задачи Проблема: Конечный пользователь используя ПО на Java, через прямые запросы к DW получает информацию. Никаких исходников разумеется нет. Модель хранилища менять нельзя. В базе за 10 лет стало много данных, я работал с бэкапом в 25 ГБ, но запросы ПО выполнялись отвратительно долго.Задача: Нужно сделать так, чтобы можно было посмотреть нужную информацию, но не ожидая по часу. Ну и цитирую: «Шоб удобно было, и если можно в Excel»
Решение Догадливый читатель заметил по рисунку, что решением стало использование OLAP кубов в качестве киосков данных. Но путь к нему был не очень явным…Как я все-таки к этому пришел: После периода изучения проблемы в информационной системы я наткнулся на понятие «Аналитической пирамиды» и связанным с ней понятием OLAP.
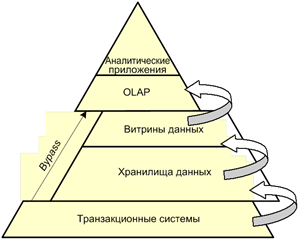
Пришел к ниже следующему выводу:
Поскольку пользователю нужна были данные, которые удачно ложились в структуру стандартного куда модели звезда, куб должен был содержать агрегированную информацию распределенную по времени, территории и подотчетной организации, в зависимости от филиала гос.конторы, то само по себе напрашивалось как-то автоматизировать процесс создания куба, для отдельных филиалов, организаций и нужных перечней показателей, что уменьшит объем лишних данных.
Мой .Net профиль означал использование Microsoft Analysis Services, в качестве OLAP–сервера, который, как видно на сравнении моделей, поддерживает модель Локальных OLAP кубов, которые работают оффлайн без сервера и легко просматриваются в Excel, если указать их в качестве источника многомерных данных.Чтобы автоматизировать процесс создания кубов, нам нужно делать это программно. В .Net есть объектная модель AMO для OLAP.
Исходным примером программного создания серверного OLAP-куба послужила эта статья.
В моем случае я задавал определенные имена таблиц из своего DW для определенного куба. Хотя, соглашусь, что логика получилась немного извращенной. При этом нужно отметить, что для программной работы с данными хранящимися в кубе использовал ADO MD. Это хорошо описано в цикле вот этих хабровских статей.Здесь очень наглядно показано, как соотносятся сущности серверного ядра OLAP, такие как AMO и ADO MD.
Итак, после того, как мы создали куб на сервере и успешно вывели его содержимое в консольном окне, как осуществить столь вожделенное открытие его в Excel? — Можно стандартно подключиться к серверной версии через Menu\Data\From other sources; — Можно сразу с генерировать локальный куб, т.е. файл отчета с расширением .cube это хорошо описано в этой статье. Собственно, интересной особенностью является то, что сервер вначале превращает данные куба в XML, что открывает другое пространство для творчества.
Заключение Бюрократическая волокита с отчетами одного чиновника стала немного легче, поскольку, создав куб однажды, можно было удобно работать c данными до начала следующего отчетного периода. Хотя с моей точки зрения, это уж очень бюджетное решение проблемы.Кроме того, есть еще интересные возможности по программной работе с кубами, я сам не знаю обо всех, но всегда интересно узнать что-то новое. Предлагаю делиться в комментариях, к примеру: использовать LINQ или проводить модульное тестирование на С#, используя ADO MD и MDX, как это описано в этой статье.
