[Из песочницы] Обзор двух курсов специализации «Machine Learning» ресурса Coursera
Машинное обучение не связано с моей текущей специальностью. Интерес к нему был вызван желанием ознакомиться с тем, чему сейчас уделено немало внимания. В мои университетские времена (2003–2010 г.) эта тема не затрагивалась, поэтому машинное обучение и большие данные являются для меня неизвестной областью. Мне хотелось бы выстроить в голове представление об этой теме и уметь решать простые задачи, чтобы по мере необходимости углубляться во что-то конкретное.
Было несколько причин, побудивших выбрать именно портал «Coursera» и именно этот курс. Во-первых, читать статьи на разрозненные темы о мало знакомом предмете не приносит пользы, т.к. знания не систематизируются. Следовательно, возникает необходимость в выстроенном курсе. Во-вторых, был отрицательный опыт прослушивания лекций, где авторы очень долго пытались объяснить очевидные вещи, до сути так и не доходя. Что привлекло меня в курсе «Machine Learning», это то что, лекторы Carlos Guestrin и Emily Fox выглядят крайне увлечёнными своим предметом (passioned & excited), говорят быстро и по делу. И кроме того, заметно, что авторы имеют дело с практическим применением, т. е. с индустрией.
По словам авторов курса, причиной его создания была попытка донести задачи машинного обучения до широкой аудитории, т.е. для тех, у кого подготовка проходила в разных областях. К главным отличиям можно отнести то, что сперва делается акцент на конкретных задачах, которые можно встретить в существующих приложениях, и на то, как машинное обучение может помочь решить их. Затем разбираются применяемые методы, то как они устроены и как могут быть полезны. Таким образом, можно увидеть на простых примерах, как машинное обучение может быть применено на практике. Тем более, что в наши дни, по словам авторов, последствия применения машинного обучения заметны. Раньше оно воспринималось по-другому. Некий набор данных подавался на вход мало понятного алгоритма, в результате чего делался вывод «мой график лучше твоего», и результаты отсылались в научный журнал.
Занятия делятся на теоретическую и практическую часть, и на тесты. В теоретической части начитываются лекции (на английском языке, английские или испанские субтитры). Имеются pdf презентации, по которым можно готовиться к тестам. Также на форуме даны ссылки на дополнительную литературу. В 1-ом курсе «Machine Learning Foundations: A Case Study Approach» есть лекции, где обучают работать в интерактивной оболочке IPython. Здесь рассказывают об основах программирования на языке Python (только всё необходимое, чтобы иметь возможность выполнять задания). Помимо этого, имеются лекции, где рассказывают о принципах работы с библиотекой GraphLab Create. Тесты делятся на теоретические и практические. Вопросы в теоретических тестах требуют понимания, поверхностно прослушать материал и успешно сдать тест вряд ли получиться. Иногда лекций недостаточно и приходится пользоваться дополнительными материалами. Стоит отметить, что здесь в одном уроке вы можете сами себе продемонстрировать при помощи заданий основные теоретические моменты.
Практическая часть представляет собой тест с заданиями. Выполнение заданий предполагает умение обработать большой набор данных, а также произвести операции над ними. Авторы рекомендуют использовать библиотеку GraphLab Create, которая имеет API на языке Python. С её помощью вы сможете загружать из файла массивы данных в удобные структуры (SFrame). Эти структуры позволяют визуализировать данные (специальные интерактивные графики) и удобно их изменять (добавлять колонки, применять операции над строками и т. д.). В библиотеке имеются алгоритмы машинного обучения, с которыми предстоит работать. Для выполнения заданий можно использовать шаблон, реализованный в web-оболочке IPython Notebook. Это файл, который хранит каркас функций, а также рекомендации. Для локальной работы с GraphLab Create и IPython Notebook авторы рекомендуют использовать инсталлятор Anaconda. Также можно работать на web-сервисе Amazon EC2, где все необходимые программы уже установлены. Мною был выбран второй вариант, т. к. можно сразу приступить к работе.
Теперь стоит рассказать о плане курсов. Первый курс специализации «Machine Learning Foundations: A Case Study Approach» является вводным. Лекции первой недели посвящены описанию языка Python, библиотеке GraphLab Create. Также авторы кратко рассказывают, о содержании других курсов специализации. Это очень полезно, т. к. обозначенный план действий не даёт забывать в какую сторону вы двигаетесь и что должны уметь делать по итогам обучения. Остальные недели содержат введение в темы, которые будут подробно раскрыты в будущих курсах. То, что дано в этих введениях, требует хорошего понимания, также нужно уметь пользоваться алгоритмами в практических заданиях. Стоит отметить, что эти задания наглядно демонстрируют прочитанную теорию. Ниже приведён план курса «Machine Learning Foundations: A Case Study Approach».
- Неделя 1. Введение. Авторы описывают учебные примеры, которые будут приведены в течение следующих недель данного курса. Этим же примерам подробно посвящены последующие курсы специализации. Авторы рассказывают, как методы машинного обучения помогают решить существующие задачи. Учат работать с GraphLab Create. Есть введение в язык Python и в оболочку IPython Notebook. Приводятся схемы структуры курса (пример смотри на рисунке 1).
- Неделя 2. Регрессия: прогнозирование цен на недвижимость («Regression: Predicting House Prices»). Здесь рассказывают о методах, которые позволяют по имеющимся данным [цена за дом — его параметры], предсказать цену за дом, параметров которого нет в наборе. Регрессии посвящён второй курс специализации «Machine Learning: Regression».
- Неделя 3. Классификация: анализ тональности текста («Classification: Analyzing Sentiment»). Авторы рассказывают о способах классификации объектов. В качестве примеров приводятся такие задачи, как выставление оценки ресторану на основании текстов отзывов; определение тематики статей по их содержанию; определение того, что изображено на картинке. Классификации посвящён третий курс специализации «Machine Learning: Classification».
- Неделя 4. Кластеризация и поиск подобия: извлечение документов («Clustering and Similarity: Retrieving Documents»). В качестве учебного примера здесь приведена задача рекомендации пользователю статей в зависимости статей, которые он уже прочитал. Рассказывают о методах представления текстовых документов и способах измерения подобия между ними. Описывают задачи кластеризации объектов (процесса их группирования по определённым признакам). Кластеризации посвящён четвёртый курс специализации «Machine Learning: Clustering & Retrieval».
- Неделя 5. Рекомендация продуктов («Recommending Products»). Здесь рассказывают о приложениях, где системы рекомендации могут быть полезны; о способах построения систем рекомендации; о метриках оценки эффективности систем рекомендации. Системам рекомендации посвящён пятый курс специализации «Machine Learning: Recommender Systems & Dimensionality Reduction».
- Неделя 6. Глубинное обучение: поиск изображений («Deep Learning: Searching for Images»). Последняя неделя посвящена многоуровневым нейронным сетям. Более подробно эта тема раскрыта в последнем курсе специализации «Machine Learning Capstone: An Intelligent Application with Deep Learning».
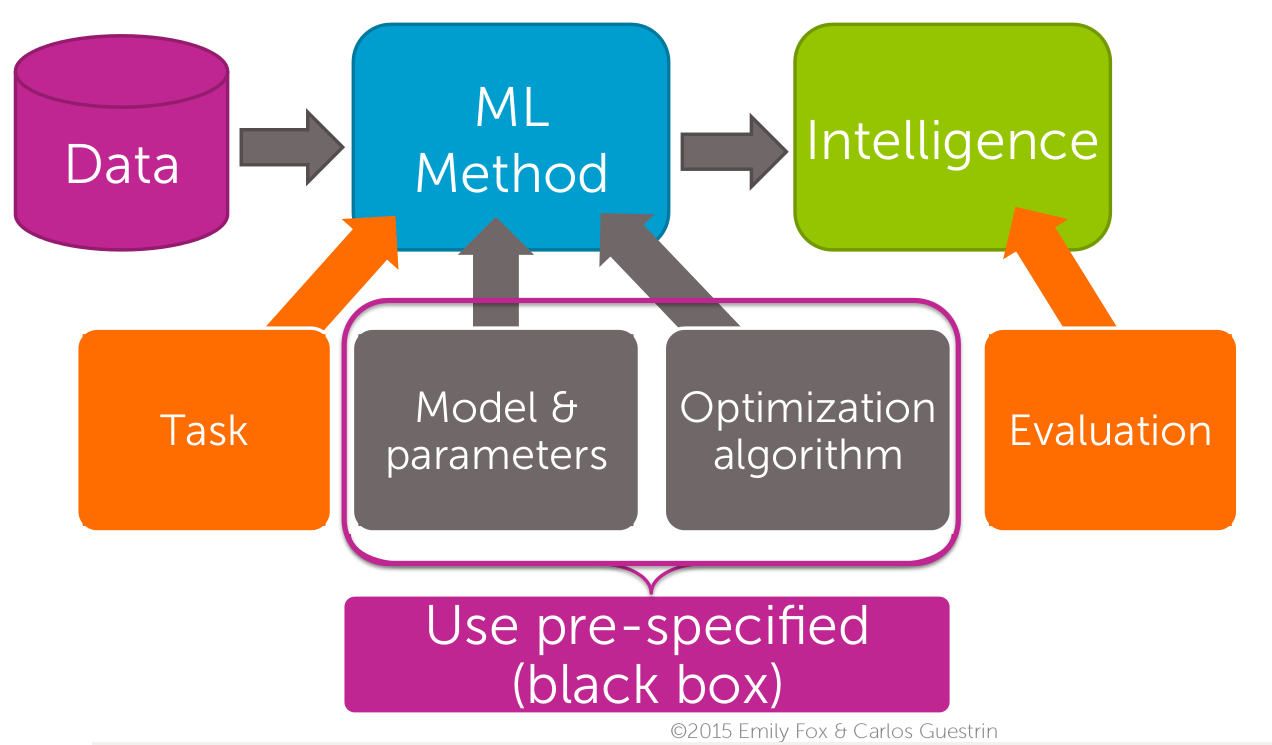
Рисунок 1. Структура специализации Machine Learning (взято из материалов курса «Machine Learning: Regression», ©2015 Emily Fox & Carlos Guestrin)
Для прохождения второго курса специализации «Machine Learning: Regression» требуется иметь представление о производных, матрицах, векторах и базовых операциях над ними. Полезным будет умение создавать хотя бы простые программы на языке Python. Краткое описание второго курса специализации «Machine Learning: Regression» приведено ниже.
- Введение. Авторы рассказывают, какое место занимает регрессия в области машинного обучения. Перечисляются приложения, где регрессия используется, и описываются задачи учебного примера — прогнозирования цен на недвижимость. Даётся обзор тем, который предстоит изучить. Эти темы проиллюстрированы на рисунке 2. В качестве моделей рассматриваются линейная регрессия (Linear regression), регуляризация (Regularization) двух типов (Ridge, Lasso), регрессия по ближайшим соседям (nearest neighbour regression), ядерная регрессия (непараметрическая регрессия — ядерное сглаживание) (kernel regression). Разобраны такие алгоритмы, как градиентный спуск (gradient descent), градиент координат (coordinate descent). Ключевыми терминами курса являются функция потерь (loss functions), компромисс между смещением и дисперсией (bias-variance tradeoff), кросс-валидация (cross-validation), разрежённость (sparsity), переобучение (overfitting), выбор модели (model selection), выбор характеристик (feature selection) (Прошу прощения, если перевод некорректен).
- Неделя 1. Простая регрессия (Simple regression). Объясняется принцип этой модели, и говорится об особенностях выбора её входных данных. Вводится метрика оценки качества простой линейной регрессии. Приведены алгоритмы расчёта параметров модели, оптимизирующих метрики качества (градиентный спуск). Объясняется смысл параметров. Показывается, как осуществлять прогноз с помощью рассчитанных параметров. Обсуждаются источники ошибок.
- Неделя 2. Множественная регрессия (Multiple regression). Рассказывается о полиномиальной регрессии и выводится модель регрессии с несколькими параметрами. Демонстрируется процесс минимизации метрики оценки качества и описываются алгоритмы вычисления параметров модели регрессии (градиентный спуск и градиент координат). Описывается алгоритм формирования предсказаний.
- Неделя 3. Оценка производительности (Assessing performance). Вопросы, обсуждаемые в течение этой недели: метрики оценки качества модели; свойства функции потерь в сравнении с ошибкой обучения, ошибкой обобщения и тестовой ошибкой; последствия выбора тестовой ошибки в качестве метрики оценки производительности; компромисс выбора пропорции разбиения данных на тестовый и обучающий наборы; источники ошибки спрогнозированных данных; выбор сложности модели; валидационный набор.
- Неделя 4. Гребневая регрессия (Ridge regression). Рассматривается поведение рассчитанных параметров модели при её избыточном обучении; описание зависимости коэффициентов модели от параметра регулировки гребневой регрессии; реализация алгоритма градиентного спуска; алгоритм кросс-валидации для выбора наилучшего параметра регулировки.
- Неделя 5. Лассо регрессия (Lasso regression). Обсуждается выбор значимых параметров модели. Сравниваются «жадные» и оптимальные алгоритмы. Демонстрируются зависимости коэффициентов модели от параметра регулировки лассо регрессии. Описывается алгоритм кросс-валидации для выбора наилучшего параметра регулировки.
- Неделя 6. Метод ближайших соседей и непараметрическая регрессия с ядерным сглаживанием (Nearest neighbor and kernel regression). Перечислены причины использования метода ближайших соседей. Дано определение ядерной регрессии и приведены примеры её использования.
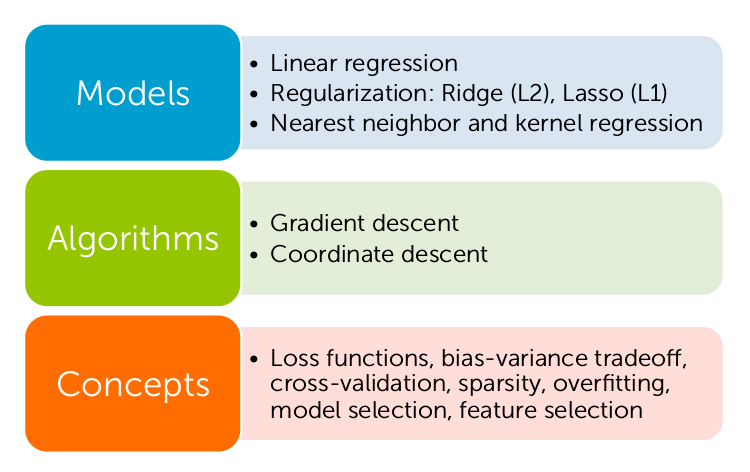
Рисунок 2. Темы, изучаемые в курсе «Machine Learning: Regression» (Взято из материалов курса «Machine Learning: Regression», ©2015 Emily Fox & Carlos Guestrin)
Нагрузка, распределённая по неделям, адекватная. Однако, второй курс «Machine Learning: Regression» является более насыщенным. Если вы опаздываете более чем на две недели, вам будет предложено переключиться на другую сессию, но этого делать не обязательно. Лекции мною прослушивались в течение рабочей недели, в пятницу или на выходных выполнялись практические задания. На них у меня уходило около трёх часов.
В заключении хотелось бы сказать, что описанные курсы специальности «Machine Learning» произвели хорошее впечатление. К достоинствам я отношу практические задания, они тщательно продуманы и иллюстрируют теорию. Мне понравились лекции, которые являются ёмкими и в которых нет «воды». Курсы структурированы, имеются схемы, которые помогают понять, какую «часть» машинного обучения вы сейчас изучаете, что вы знаете и чему предстоит научиться. Недостатками является то, что иногда прочитанной теории не хватает. Хотелось бы больше ссылок на другие ресурсы, хотя на официальном форуме приведены рекомендуемые книги, которые там же можно и скачать. В целом, курсы специализации «Machine Learning», будут весьма полезны, если вы хотите научиться практически применять методы машинного обучения.
