[Из песочницы] Обучение с подкреплением для самых маленьких
Обучение с подкреплением — это метод машинного обучения, при котором происходит обучение модели, которая не имеет сведений о системе, но имеет возможность производить какие-либо действия в ней. Действия переводят систему в новое состояние и модель получает от системы некоторое вознаграждение. Рассмотрим работу метода на примере, показанном в видео. В описании к видео находится код для Arduino, который реализуем на Python.
Задача
С помощью метода «обучение с подкреплением» необходимо научить тележку отъезжать от стены на максимальное расстояние. Награда представлена в виде значения изменения расстояния от стены до тележки при движении. Измерение расстояния D от стены производится дальномером. Движение в данном примере возможно только при определенном смещении «привода», состоящего из двух стрел S1 и S2. Стрелы представляют собой два сервопривода с направляющими, соединенными в виде «колена». Каждый сервопривод в данном примере может поворачиваться на 6 одинаковых углов. Модель имеет возможность совершить 4 действия, которые представляют собой управление двумя сервоприводами, действие 0 и 1 поворачивают первый сервопривод на определенный угол по часовой и против часовой стрелке, действие 2 и 3 поворачивают второй сервопривод на определенный угол по часовой и против часовой стрелке. На рисунке 1 показан рабочий прототип тележки.

Рис. 1. Прототип тележки для экспериментов с машинным обучением
На рисунке 2 красным цветом выделена стрела S2, синим цветом — стрела S1, черным цветом — 2 сервопривода.

Рис. 2. Двигатель системы
Схема системы показана на рисунке 3. Расстояние до стены обозначено D, желтым показан дальномер, красным и черным выделен привод системы.

Рис. 3. Схема системы
Диапазон возможных положений для S1 и S2 показан на рисунке 4:

Рис. 4.а. Диапазон положений стрелы S1

Рис. 4.б. Диапазон положений стрелы S2
Пограничные положения привода показаны на рисунке 5:
При S1 = S2 = 5 максимальная дальность от земли.
При S1 = S2 = 0 минимальная дальность до земли.
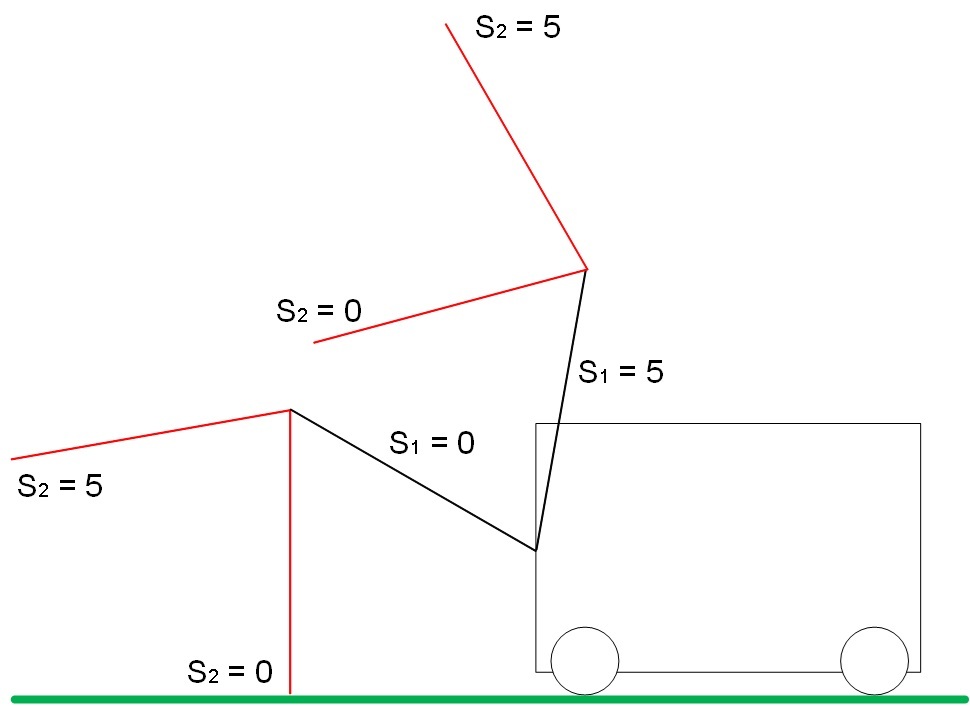
Рис. 5. Пограничные положения стрел S1 и S2
У «привода» 4 степени свободы. Действие (action) изменяет положение стрел S1 и S2 в пространстве по определённому принципу. Виды действий показаны на рисунке 6.
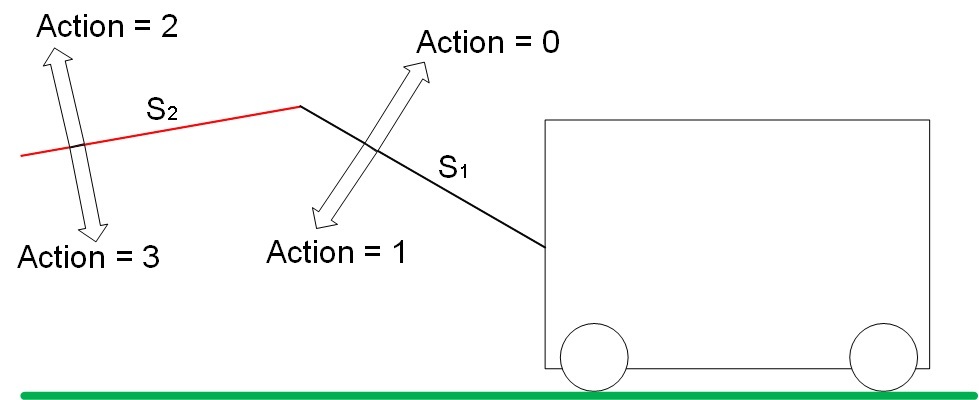
Рис. 6. Виды действий (Action) в системе
Действие 0 увеличивает значение S1. Действие 1 уменьшает значение S1.
Действие 2 увеличивает значение S2. Действие 3 уменьшает значение S2.
Движение
В нашей задаче тележка приводится в движение всего в 2х случаях:
В положении S1 =0, S2 = 1 действие 3 приводит в движение тележку от стены, система получает положительное вознаграждение, равное изменению расстояния до стены. В нашем примере вознаграждение равно 1.
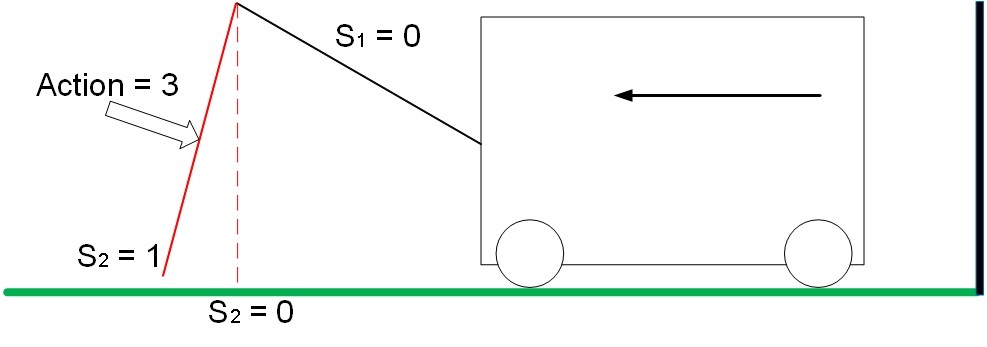
Рис. 7. Движение системы с положительным вознаграждением
В положении S1 = 0, S2 = 0 действие 2 приводит в движение тележку к стене, система получает отрицательное вознаграждение, равное изменению расстояния до стены. В нашем примере вознаграждение равно -1.

Рис. 8. Движение системы с отрицательным вознаграждением
При остальных состояниях и любых действиях «привода» система будет стоять на месте и вознаграждение будет равно 0.
Хочется отметить, что стабильным динамическим состоянием системы будет последовательность действий 0–2–1–3 из состояния S1=S2=0, в котором тележка будет двигаться в положительном направлении при минимальном количестве затраченных действий. Подняли колено — разогнули колено — опустили колено — согнули колено = тележка сдвинулась вперед, повтор. Таким образом, с помощью метода машинного обучения необходимо найти такое состояние системы, такую определенную последовательность действий, награда за которые будет получена не сразу (действия 0–2–1 — награда за которые равна 0, но которые необходимы для получения 1 за последующее действие 3).
Метод Q-Learning
Основой метода Q-Learning является матрица весов состояния системы. Матрица Q представляет собой совокупность всевозможных состояний системы и весов реакции системы на различные действия.
В данной задаче возможных комбинаций параметров системы 36 = 6^2. В каждом из 36 состояний системы возможно произвести 4 различных действия (Action = 0,1,2,3).
На рисунке 9 показано первоначальное состояние матрицы Q. Нулевая колонка содержит индекс строки, первая строка — значение S1, вторая — значение S2, последние 4 колонки равны весам при действиях равных 0, 1, 2 и 3. Каждая строка представляет собой уникальное состояние системы.
При инициализации таблицы все значения весов приравняем 10.
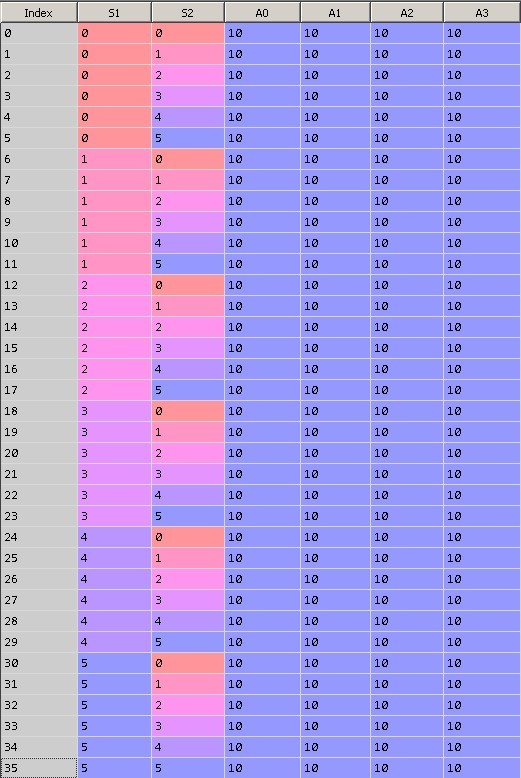
Рис. 9. Инициализация матрицы Q
После обучения модели (~15000 итераций) матрица Q имеет вид, показанный на рисунке 10.

Рис. 10. Матрица Q после 15000 итераций обучения
Обратите внимание, действия с весами, равными 10, невозможны в системе, поэтому значение весов не изменилось. Например, в крайнем положении при S1=S2=0 нельзя выполнить действие 1 и 3, так как это ограничение физической среды. Эти пограничные действия запрещены в нашей модели, поэтому 10тки алгоритм не использует.
Рассмотрим результат работы алгоритма:
…
Iteration: 14991, was: S1=0 S2=0, action= 0, now: S1=1 S2=0, prize: 0
Iteration: 14992, was: S1=1 S2=0, action= 2, now: S1=1 S2=1, prize: 0
Iteration: 14993, was: S1=1 S2=1, action= 1, now: S1=0 S2=1, prize: 0
Iteration: 14994, was: S1=0 S2=1, action= 3, now: S1=0 S2=0, prize: 1
Iteration: 14995, was: S1=0 S2=0, action= 0, now: S1=1 S2=0, prize: 0
Iteration: 14996, was: S1=1 S2=0, action= 2, now: S1=1 S2=1, prize: 0
Iteration: 14997, was: S1=1 S2=1, action= 1, now: S1=0 S2=1, prize: 0
Iteration: 14998, was: S1=0 S2=1, action= 3, now: S1=0 S2=0, prize: 1
Iteration: 14999, was: S1=0 S2=0, action= 0, now: S1=1 S2=0, prize: 0
Рассмотрим подробнее:
Возьмем итерацию 14991 в качестве текущего состояния.
1. Текущее состояние системы S1=S2=0, этому состоянию соответствует строка с индексом 0. Наибольшим значением является 0.617 (значения равные 10 игнорируем, описано выше), оно соответствует Action = 0. Значит, согласно матрице Q при состоянии системы S1=S2=0 мы производим действие 0. Действие 0 увеличивает значение угла поворота сервопривода S1 (S1 = 1).
2. Следующему состоянию S1=1, S2=0 соответствует строка с индексом 6. Максимальное значение веса соответствует Action = 2. Производим действие 2 — увеличение S2 (S2 = 1).
3. Следующему состоянию S1=1, S2=1 соответствует строка с индексом 7. Максимальное значение веса соответствует Action = 1. Производим действие 1 — уменьшение S1 (S1 = 0).
4. Следующему состоянию S1=0, S2=1 соответствует строка с индексом 1. Максимальное значение веса соответствует Action = 3. Производим действие 3 — уменьшение S2 (S2 = 0).
5. В итоге вернулись в состояние S1=S2=0 и заработали 1 очко вознаграждения.
На рисунке 11 показан принцип выбор оптимального действия.

Рис. 11.а. Матрица Q

Рис. 11.б. Матрица Q
Рассмотрим подробнее процесс обучения.
minus = 0;
plus = 0;
initializeQ();
for t in range(1,15000):
epsilon = math.exp(-float(t)/explorationConst);
s01 = s1; s02 = s2
current_action = getAction();
setSPrime(current_action);
setPhysicalState(current_action);
r = getDeltaDistanceRolled();
lookAheadValue = getLookAhead();
sample = r + gamma*lookAheadValue;
if t > 14900:
print 'Time: %(0)d, was: %(1)d %(2)d, action: %(3)d, now: %(4)d %(5)d, prize: %(6)d ' % \
{"0": t, "1": s01, "2": s02, "3": current_action, "4": s1, "5": s2, "6": r}
Q.iloc[s, current_action] = Q.iloc[s, current_action] + alpha*(sample - Q.iloc[s, current_action] ) ;
s = sPrime;
if deltaDistance == 1:
plus += 1;
if deltaDistance == -1:
minus += 1;
print( minus, plus )
Полный код на GitHub.
Установим начальное положение колена в крайнее верхнее положение:
s1=s2=5.Инициализируем матрицу Q, заполнив начальным значением:
initializeQ();Вычислим параметр epsilon. Это вес «случайности» действия алгоритма в нашем расчёте. Чем больше итераций обучения прошло, тем меньше случайных значений действий будут выбраны:
epsilon = math.exp(-float(t)/explorationConst)Для первой итерации:
epsilon = 0.996672Сохраним текущее состояние:
s01 = s1; s02 = s2Получим «лучшее» значение действия:
current_action = getAction();Рассмотрим функцию поподробнее.
Функция getAction () выдает значение действия, которому соответствует максимальный вес при текущем состоянии системы. Берется текущее состояние системы в матрице Q и выбирается действие, которому соответствует максимальный вес. Обратим внимание, что в этой функции реализован механизм выбора случайного действия. С увеличением числа итераций случайный выбор действия уменьшается. Это сделано, для того, чтобы алгоритм не зацикливался на первых найденных вариантах и мог пойти по другому пути, который может оказаться лучше.
В исходном начальном положении стрел возможны только два действия 1 и 3. Алгоритм выбрал действие 1.
Далее определим номер строки в матрице Q для следующего состояние системы, в которое система перейдет после выполнения действия, которое мы получили в предыдущем шаге.
setSPrime(current_action);В реальной физической среде после выполнения действия мы получили бы вознаграждение, если последовало движение, но так как движение тележки моделируется, необходимо ввести вспомогательные функции эмуляции реакции физической среды на действия. (setPhysicalState и getDeltaDistanceRolled ())
Выполним функции:
setPhysicalState(current_action);r = getDeltaDistanceRolled();После выполнения действия нам необходимо обновить коэффициент этого действия в матрице Q для соответствующего состояния системы. Логично, что, если действие привело к положительной награде, то коэффициент, в нашем алгоритме, должен уменьшиться на меньшее значение, чем при отрицательном вознаграждении.
Теперь самое интересное — для расчета веса текущего шага заглянем в будущее.
При определении оптимального действия, которое нужно совершить в текущем состоянии, мы выбираем наибольший вес в матрице Q. Так как мы знаем новое состояние системы, в которое мы перешли, то можем найти максимальное значение веса из таблицы Q для этого состояния:
lookAheadValue = getLookAhead();В самом начале оно равно 10. И используем значение веса, еще не выполненного действия, для подсчета текущего веса.
sample = r + gamma*lookAheadValue;
sample = 7.5
Q.iloc[s, current_action] = Q.iloc[s, current_action] + alpha*(sample - Q.iloc[s, current_action] ) ;
Q.iloc[s, current_action] = 9.75Т.е. мы использовали значение веса следующего шага, для расчета веса шага текущего. Чем больше вес следующего шага, тем меньше мы уменьшим вес текущего (согласно формуле), и тем текущий шаг будет предпочтительнее в следующий раз.
Этот простой трюк дает хорошие результаты сходимости алгоритма.
Масштабирование алгоритма
Данный алгоритм можно расширить на большее количество степеней свободы системы (s_features), и большее количество значений, которые принимает степень свободы (s_states), но в небольших пределах. Достаточно быстро матрица Q займет всю оперативную память. Ниже пример кода построения сводной матрицы состояний и весов модели. При количестве «стрел» s_features = 5 и количестве различных положений стрелы s_states = 10 матрица Q имеет размеры (100000, 9).
import numpy as np
s_features = 5
s_states = 10
numActions = 4
data = np.empty((s_states**s_features, s_features + numActions), dtype='int')
for h in range(0, s_features):
k = 0
N = s_states**(s_features-1-1*h)
for q in range(0, s_states**h):
for i in range(0, s_states):
for j in range(0, N):
data[k, h] = i
k += 1
for i in range(s_states**s_features):
for j in range(numActions):
data[i,j+s_features] = 10.0;
data.shape
# (100000L, 9L)
Вывод
Этот простой метод показывает «чудеса» машинного обучения, когда модель ничего не зная об окружающей среде обучается и находит оптимальное состояние, при котором награда за действия максимальна, причем награда присуждается не сразу, за какое либо действие, а за последовательность действий.
Спасибо за внимание!
