[Из песочницы] Обработка трафика в облаке. Кому нужна виртуализация сетевых функций (NFV)?
 Сегодня хочу рассказать о концепции, которая в ближайшие несколько лет в корне изменит дизайны сетей связи и телекомуникационных услуг — о виртуализации сетевых функций, Network Functions Virtualization.
Сегодня хочу рассказать о концепции, которая в ближайшие несколько лет в корне изменит дизайны сетей связи и телекомуникационных услуг — о виртуализации сетевых функций, Network Functions Virtualization.
В отличие от повсеместно распространённой виртуализации приложений, сетевые функции перенести в облако гораздо сложнее, а некоторые из них вообще невозможно. Я расскажу о задачах и принципах NFV, об истории этой инициативы и её нынешнем статусе, об ограничениях и недостатках этого подхода, поделюсь своими мыслями о том, какие задачи с её помощью решаемы, а какие — принципиально нет.
Если мы необходимое нам приложение отвяжем от оборудования и заставим работать в изолированном программном контейнере вместо «железа», мы сможем назвать это приложение виртуализированным. Идеи виртуализации сопровождают IT-индустрию c момента появления первых ЭВМ — с 60ых годов прошлого века инженеры решали задачи разделения одного большого мэйнфрэйма на несколько изолированных проектов. В «нулевых» человечество вновь столкнулось с похожей задачей — на этот раз понадобилось эффективно разделять серверные ресурсы между множеством их потребителей-клиентов. Помимо самой возможности «нарезать» аппаратный ресурс, виртуализация несёт колоссальные выгоды.
Сосуществование нескольких приложений на общем железе выгоднее, чем работа их на выделенных серверах — виртуализированному решению для такой же производительности требуется меньше серверов; такое решение более компактно, расходует меньше электроэнергии, требует меньше сетевых портов и соединений. Новые способы доставки приложений в виде шаблона виртуальной машины позволяют покупателю отказаться от навязываемого ранее аппаратного сервера, но при этом получать все преимущества «коробочного» решения. Возможности современных гипервизоров и систем управления привнесли много нового в плане масштабирования, отказоустойчивости, различных оптимизаций. Виртуализация переформатировала ИТ-рынок: сформировалось понятие «облачных» сервисов различных моделей — SaaS, IaaS, PaaS. Однако, закономерности программно-прикладной сферы не в полной мере применимы к сфере сетевой.
Современные телекоммуникационные сети содержат большое количество фирменного оборудования, как правило, очень специализированного, заточенного под конкретную операцию: одно устройство обеспечивает NAT, другое ограничивает скорость доступа и считает трафик, третье осуществляет родительский контроль и фильтрацию содержимого, еще одно отвечает за функции фаервола. Для сложившегося разделения функций между сетевой аппаратурой есть несколько причин: во-первых, каждый сетевой вендор, так уж сложилось, специализируется на нескольких функциях, в которых данная конкретная компания имеет свои наработки и ноу-хау. Другая вероятная причина сводится к очень специфической начинке таких устройств, имеющей мало общего с серверами общего назначения. Поэтому, оператор-эксплуатант таких решений поневоле вынужден любой ценой поддерживать сложившееся «разнообразие». Запуск новой услуги требует установки нового комплекта оборудования, поддерживающего необходимую функцию. Это, в свою очередь, требует выделения дополнительных площадей, дополнительного электропитания, логистики «железа», его монтажа и пусконаладки.
Сейчас очевидно, что сеть из физических «коробок», каждая из которых выполняет лишь одну-единственную функцию, это не самая оптимальная модель для развития. Помимо высоких капитальных и операционных затрат, такой дизайн очень инертен, не позволяет оператору наращивать портфель предоставляемых услуг так быстро, как того требуют акционеры. Сеть должна быть намного более гибкой и динамичной, способствовать внедрению любого нового сервиса, его быстрой активации по запросу абонента и освобождению занятых ресурсов при деактивации услуги.
Функции, которые выполняют сетевые устройства, значительно различаются своими характеристиками и возможностями по их виртуализации. Некоторые целесообразно перенести в облако, а другие — категорически нельзя отделять от сетевой аппаратуры. Передача данных так или иначе связана с перемещением сетевых пакетов из одной географической точки в другую, и в каждой из этих точек, на каждом узле связи, должно, как минимум, присутствовать реальное сетевое устройство с нужным количеством сетевых портов — коммутатор или маршрутизатор.
Пересылка — forwarding/routing/switching — это самая примитивная операция над сетевым пакетом, которую выполняет сетевое устройство. По сути — копирование с одного порта на другой, иногда с заменой определённых полей фрэйма или пакета. Данная операция на большинстве платформ выполняется специальным комплексом, «заточенным» под быстрый поиск соответствия в специальной, троичной памяти TCAM и замену нужных полей пакета «на лету». Специализированный ASIC, используемый в маршрутизаторах и коммутаторах (его ещё называют Network Processor / Network Processing Unit) для таких примитивных задач более приспособлен — работает быстрее, расходует меньше энергии, примитивен, компакетен и дёшев.
Для сравнения, реализация такого же функционала программными средствами на general purpose CPU, с обращением к внешним данным через сложный стэк ввода-вывода (через ядро и драйвер), резко уменьшила бы производительность, да и в формате сервера невозможно было бы обеспечить нужную плотность портов.
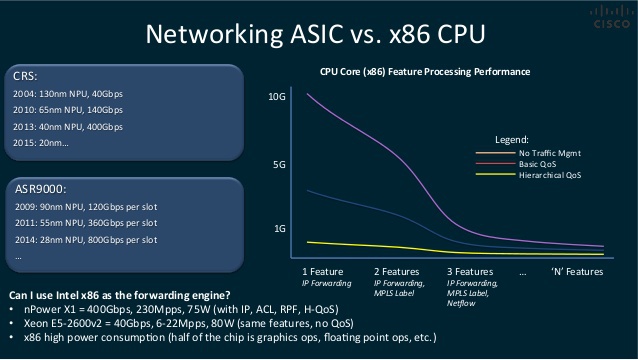
Слайд Cisco о преимуществах NP, и о влиянии фич на производительность forwarding’а
Пересылку данных вместе со всей низкоуровневой логикой, которая обрабатывает каждый пакет, условно выделяют в плоскость передачи данных, Data Plane. Почти вся сигнализация — протоколы обнаружения соседства, протоколы маршрутизации и управления трафиком, различные механизмы балансировки, предотвращения петель, телеметрии, управления сервисами и полосой пропускания, авторизации, аутентификации и аккаунтинга — все они относятся к плоскости управления — Control Plane. Чем интенсивнее Control Plane и чем «тоньше» Data Plane — тем более целесообразно виртуализировать эту сетевую функцию, перенести её с сетевого железа на сервер. И наоборот, чем «толще» Data Plane и чем примитивнее Control Plane — тем функция сложнее в виртуализации, и лучше её оставить внутри сетевого устройства.
CE (Customer Edge) маршрутизаторы имеют очень широкий функционал Data Plane — от простого роутинга до поддержки специальных методов маршрутизации PBR/ABF, от примитивных ACL до сложного Zone-Based фаерволлинга, такие роутеры подерживают различные стандарты энкапсуляции и туннелирования (GRE/IPIP/MPLS/OTV), трансляцию сетевых адресов (NAT, PAT), сложные QoS-политики (policing, shaping, marking, scheduling). Функционал Control Plane тоже очень широк — от примитивных ARP/ND до сложнейших фич типа MPLS Traffic Engineering. Подобный Branch-маршрутизатор, с нагрузкой несколько десятков или сотен мегабит в секунду может быть прекрасно виртуализирован — на промышленном сервере можно разместить десяток-другой таких элементов.
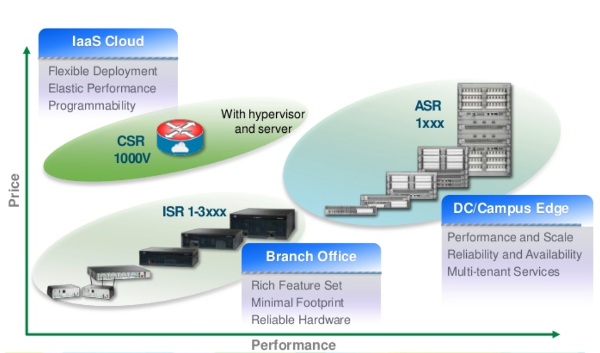
ниша для применения виртуального CE-маршрутизатора Cisco CSR1000v относительно аппаратных платформ
P/PE маршрутизаторы, имеющие похожий функционал, предназначены для установки сети оператора, и их data-plane обрабатывает колоссальное количество трафика: от сотен гигабит до десятков терабит в секунду. При этом они должны иметь максимальную плотность портов. Стоит ли говорить, что сервер традиционной архитектуры не рассчитан на такие объемы данных, которыми оперируют маршрутизаторы провайдерского класса. Их DataPlane слишком «толст» и не интересен для виртуализации. По аналогии с операторскими роутерами, почти невозможна виртуализация высокопроизводительных коммутаторов, широко использующихся в ЦОДах.

16×40GE-портовый модуль простенького коммутатора. Под большим радиатором скрыт NPU Broadcom Trident II, обеспечивающий 640 честных Gbps.
Единственное, что иногда может или должно быть виртуальным применительно, а таким великанам — лишь плоскость управления, полностью или частично. Data Plane в этом случае полностью остаётся на устройстве, а сама пересылка пакетов выполняется по таблицам, запрограммированным внешней системой. Такой системой может являться не только традиционный контроллер SDN в узком понимании (работающий по OpenFlow стандарту) — это может быть любой оркестратор, медиатор, драйвер сетевого элемента с поддержкой любого доступного интерфейса (CLI, NetConf, SNMP).
Под эту же категорию подпадает такой традиционный элемент, как скажем, BGP Route-Reflector, «разливающий» по сети таблицы маршрутизации BGP. Такие элементы хорошо подходят для виртуализации, но на сети оператора их считанные единицы. NFV-концепция касается скорее динамических, абонентских, массовых, а не инфраструктурных сервисов.
Забегая вперёд скажу, что вынесенный Control Plane и такое понятие как SDN соотносятся с NFV в несколько другом ключе — скорее как элемент сетевой инфраструктуры для самого NFV, а не как функция.
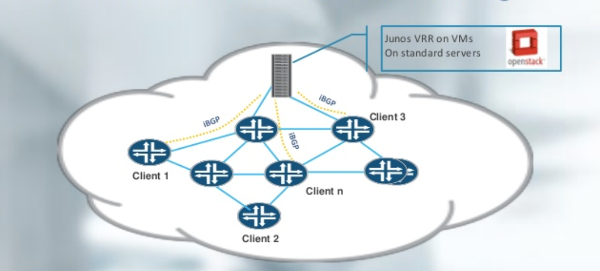
виртуализованный BGP Route-Reflector Juniper на стандартном сервере
CPE (Customer Premises Equipment или Residential Gateway) — та самая коробочка, устанавливаемая в квартире абонента, куда приходит кабель от оператора. Она раздает интернет на все устройства в квартире и является центральной точкой его домашней сети: на ней работает DHCP-сервер, кэширующий DNS-сервер, клиент протокола, по которому «общается» с провайдером: PPPoE/L2TP/PPTP/DHCP/802.1x. Из dataplane-фич определяющими также являются NAT и Firewall. От коробочки с портом для включения операторского кабеля в любом случае никуда не деться, и требования к устройству остаются прежними: маленький, симпатичный, беспроблемный, дешевый девайс. Эти чаяния давно уловили производители электроники, и на нашем рынке доступны такие устройства на любой вкус и кошелек. Надо отдать должное вендорам наиболее распространенных чипсетов таких «мыльниц»: их вычислительная способность может быть очень высокой, а такие ресурсоемкие функции как NAT и коммутация могут быть реализованы аппаратно.
Такие устройства на данный момент не отвечают требованиям операторов скорее из-за недостатка функционала: провайдер зачастую не может оценить их состояние и загрузку, они часто являются узким местом для предоставления услуги; оператор не видит локальную сеть абонента и не управляет настройками CPE, что затрудняет диагностику; отсутствие необходимых фич на этом элементе затрудняет запуск новых услуг; обновление ПО этих устройств, как правило, проводится несвоевременно, что привносит дополнительные риски. Я уверен, что в ближайшее время нас ждет переосмысление модели таких услуг, как родительский контроль, интернет-кинозал, управление умным домом, бэкап и репликация, хранение и просмотр видезаписей с домашних камер видеонаблюдения, сервисов наподобие «рабочего стола школьника» и т.д., и значительную роль в этом сыграет CPE, виртуализованные в домене оператора. Наличие индивидуального абонентского vCPE-контейнера, через который проходит абонентский трафик, вероятно, изменит принцип учёта потребления услуг: объектом тарификации, наконец, сможет стать не только трафик, а вычислительный или дисковые ресурс. «Коробочка с антенной» в такой услуге останется на своём месте в абонентской квартире, но будет иметь самый минимальный набор функций.
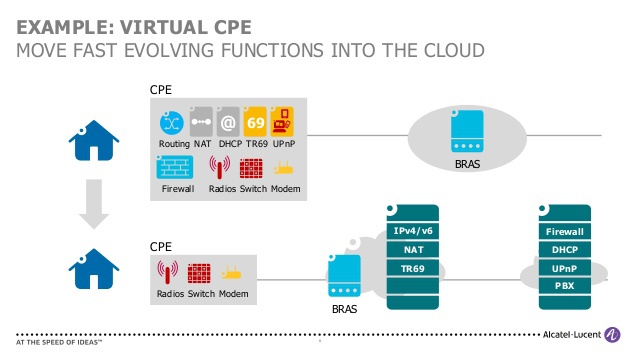
слайд Alcatel-Lucent наглядно иллюстрирует перенос сетевых функций с CPE-устройства в облако
BNG/BRAS — так называются роутеры-шлюзы, через которые абоненты оператора выходят в Интернет. Именно эти маршрутизаторы выполняют «дозирование» и учёт потребляемых услуг в соответствии с тарифным планом по каждому из пользователей. На эти устройства приходится колоссальная вычислительная нагрузка — каждого абонента необходимо авторизовать в AAA-системе по протоколу RADIUS, получить уникальные правила и атрибуты по каждой из сессий чтобы создать для каждого свой, уникальный сервис со своими классами и ограничениями, правилами учета и адресации, политиками QoS и ACL. Этот элемент отвечает за назначение адресов, поддерживает работу сигнализации ARP/ND/PPP/LCP/DHCP с десятками и сотнями тысяч абонентских устройств. По каждой сессии BNG должен понимать сколько трафика попало в тот или иной класс, сколько времени длилась сессия, кому перекрыть доступ в Интернет, кого «завернуть» на портал, а кому увеличить скорость. Нужно ли говорить, что эти железяки должны обладать очень производительным Control Plane? BNG имеет сетевые процессоры еще более сложные, чем на P или PE платформах! Помимо пересылки пакетов эта умная железка вытворяет с ними более интересные «упражнения»: каждая абонентская сессия программируется в сетевой процессор, по каждой может вестись по несколько счётчиков, у каждой могут быть свои правила, свои классификаторы, свои скорости доступа.
Такая «пакетная магия» невозможна без дополнительных аппаратных средств: сотен тысяч счетчиков и огромных объемов специальных типов памяти: TCAM’а для классификаторов и списков доступа, пакетной памяти для организации очередей. Некоторые технологии абонентского доступа используют туннелирование (L2TP/PPPoE), и тогда на BNG возлагается ещё и энкапсуляция-декапсуляция данных, а чем больше операций выполняется над сетевым пакетом, тем больше преимуществ имеет ASIC перед x86. Впрочем, виртуализованный BNG может быть интересен при суммарных объёмах трафика не более нескольких единиц Gbps, с очень динамичными сервисами и большим количеством сессий и bringup/teardown событий. Хороший пример — WiFi на транспорте: с малым объемом трафика, высокой динамикой, с наличием дополнительных сервисов вроде баннерной рекламы, которые можно разместить на том же кластере серверов, где развернут vBNG.
NAT — трансляция сетевых адресов — в связи с возникшим дефицитом публичных адресов, находящихся в распоряжении операторов связи, эта фича стала в последние годы востребована не только в Enterprise и SMB, но и в SP-сегменте. NAT-функционал относится к одной и самых ресурсоёмких Data Plane функций и требует значительных вычислительных ресурсов. Сложность её связана с огромным количеством одновременно отслеживаемых соединений. Открытие лишь одной этой страницы (со всеми объектами и картинками) создала, использовала и закрыла сотни трансляций на NAT устройстве. Конечно же, в том случае, если ваш оператор использует NAT. Клиенты пиринговых файлообменных сетей генерируют многие тысячи трансляций на один мегабит полосы.
Развитие упрощённых режимов NAT (так называемых Carrier-Grade режимов) позволило добиться увеличения производительности, однако выполнение NAT на сетевых процессорах сегодня скорее исключение, чем правило. Большой объём трафика, который должен обслуживать комплекс NAT сегодня реализуется на высокопроизводительных серверах, устанавливаемых в слот одного из центральных маршрутизаторов на сети. Данный подход позволяет избежать внешних сетевых соединений — комплекс подключается напрямую на backplane роутера и выглядит для маршрутизатора как еще один линейный модуль.

Мультисервисный маршрутизатор Huawei ME-60 c установленным SFU-модулем, на котором может быть запущен Carrier-Grade NAT
Еще одна яркая характеристика NAT — толщина — его возможно разделить на более мелкие части путём дробления пула адресов, но это сделает его менее эффективным. Чем он централизованнее — тем лучше используется доступный адресный ресурс. Из-за толщины, больших объемов трафика и большой вычислительной нагрузки NAT является интересным кейсом для концепции распределённого NFV (dNFV), когда сетевые функции логически централизованы (имеем единый пул адресов и ресурсов и единую точка управления), но при этом территориально распределены по узлам и находятся топологически близко к узлам транзита обслуживаемого трафика.
Security: Функционал сетевой безопасности по своим свойствам близок к NAT — также характеризуется огромным количеством и динамикой состояний (Stateful FW, NGFW, IDS, IPS, Антивирус, Антиспам), большим потреблением памяти и ресурсов CPU, что делает его интересным для виртуализации. В отличие от NAT, этот сервис нельзя назвать толстым. Его можно делить вплоть до соотношения 1 абонент на 1 контейнер, поэтому данная услуга считается одним из самых явных use-case для NFV.
DPI — глубокая инспекция пакетов — функция, позволяющая оператору связи ограничивать или определять уровень сервиса (квоту, скорость) для определённого типа приложения или содержимого. Одним из примеров может служить такая распространённая услуга «родительский контроль», при активации которой организуется прохождение абонентского трафика через фильтр на основании класса посещаемого ресурса. Data Plane этого сервиса обычно реализуется программными средствами, а интересная оператору производительность может начинаться с достаточно малых величин — это тоже один из ярких юз-кейсов.
MMSC/IMS — IP Multimedia Subsystem — «пограничный» элемент для предоставления голосовых сервисов, трансляции телевидения, стриминга видео для таких приложений, как домашний кинотеатр или видеонаблюдение, различных мультимедийных меню и сервиса обмена мгновенными сообщениями. Отлично дополняет портфолио операторских услуг.
Инфраструктурные элементы мобильных сетей GSM/UMTS/LTE/WiFi: беспроводные контроллеры, EPC, IMS, CSN, SMSC, PCC, GWc, GWu, PGW, SGW, HSS, PCRF — эти функции имеют высокие требования по вычислительным ресурсам, а по объёму передаваемых данных — скорее умеренные. Лишь некоторые из них имеют ряд особенностей, связанные с обеспечением необходимых параметров QoS.
Для полноты картины упомяну такие приложения, как DHCP, DNS, HTTP-серверы (с широчайшим выбором доступных WEB-приложений), HTTP Proxy (включая различные оптимизаторы, ускорители и URL-фильтры), SIP Proxy и т.д. Их можно относить к сетевым функциям, можно спорить и относить их к Application-уровню модели OSI, но, в любом случае, они востребованы и легко виртуализируемы, и также могут служить составными «кирпичиками» услуг нового поколения.
Итак, с самими функциями более-менее ясно. Осталось понять каким образом их возможно комбинировать друг с другом, как обеспечивать изоляцию сетевых соединений между этими виртуальными элементами, безопасность, масштабируемость и отказоустойчивость, как сделать систему прозрачной и управляемой, в конце концов, какое выбрать оборудование — вычислительное и сетевое — и как его настроить. Ради ответов на эти вопросы семь крупнейших зарубежных провайдеров (AT&T, BT, Deutsche Telekom, Orange, Telecom Italia, Telefonica и Verizon) решили объединить свои усилия в исследованиях и в 2013 г. создали рабочую группу под эгидой Европейского института по стандартизации в области электросвязи ETSI. Позже к их экспериментам присоединились десятки производителей сетевого оборудования и ПО, и на данный момент в NFV ISG входит несколько сотен участников.
На сетях участников-операторов были организованы несколько тестовых зон и распределены темы исследований и наиболее интересные вопросы для изучения. Практические наработки фиксируются, обобщаются и публикуются для последующего комментирования и исправления и по результатам работы формулируются новые вопросы. Ещё год назад технология NFV была мало наполнена конкретикой, но с каждой новой публикацией мозаика будущего стандарта выглядит всё полнее.
Примечательно, что успешный опыт «пилотирования» зачастую перенимается и тиражируется «как есть», и даже несмотря на «проприетарность» и пока ещё отсутствие полноценного открытого стандарта, ряд вендоров, желающих занять эту востребованную нишу, уже предоставляет не только сами виртуальные элементы, но и целостные решения NFV, разного масштаба, разной степени готовности и полноты, по-разному реализованные.
В 2014 году к вендорско-провайдерским инициативам присоединилось OpenSource сообщество Linux Foundation, чем был дан старт проекту платформы с открытым исходным кодом — OPNFV, который должен расширить интерес индустрии к использованию общедоступных и открытых продуктов в этой нише. Например, для сети подошёл бы OpenvSwitch и OpenDaylight, для слоя виртуализации — OpenStack, в качестве хранилища — Ceph, в роли гипервизора — KVM, хостовая и гостевая ОС — Linux. Сегодня доступен первый релиз этого продукта, Arno. Активности по стандартизации NFV также замечены в таких отраслевых организациях, как, например, MEF или TM Forum.
В соответствии со спецификациями ETSI, NFV домен состоит из трёх условных компонентов: 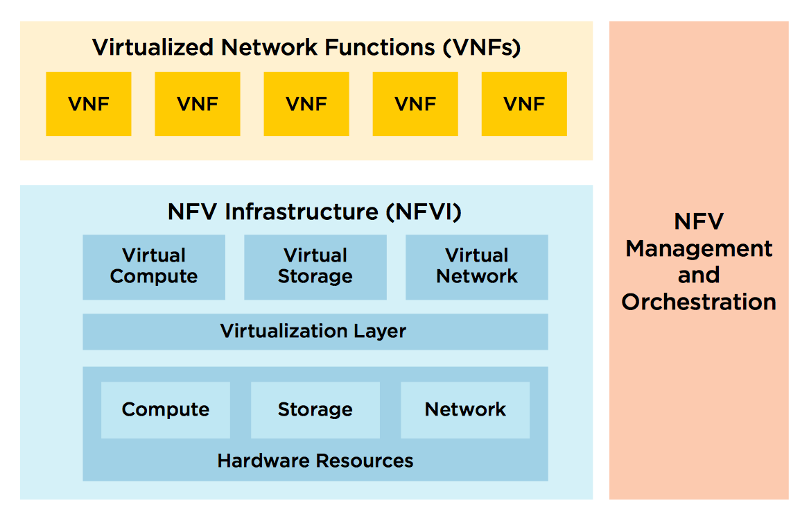
1. Virtualized Network Functions (VNF) — те самые сетевые функции, о которых шла речь выше. Как правило, под VNF-элементом подразумевается виртуальная машина или набор виртуальных машин, и их совокупность определяет верхнюю плоскость решения. Т.к. VNF-элементу предстоит быть динамически настроенным, предусмотрен еще один суб-блок в его составе или находящийся над ним — Element Management System (EMS).
2. NFV Infrastructure (NFVI) — физические ресурсы, их компоненты и настройки: сетевые устройства, хранилища, серверы и дополняющие их виртуальные ресурсы: гипервизоры, система виртуализации, виртуальные коммутаторы. Они, находясь на нижнем уровне, формирует нижнюю плоскость «пирога».
3. NFV Management and Orchestration (MANO) — «обвязка», управляющая жизненным циклом виртуальных элементов и нижележащей инфраструктурой — обозначается вертикальным прямоугольником, имеющим связи с обеими плоскостями решения через компоненты (Managers), отвечающие за управление конкретной плоскостью. Над менеджерами расположен оркестратор, роль которого заключается в разделении команд на два домена, в которых требуется произвести изменения.
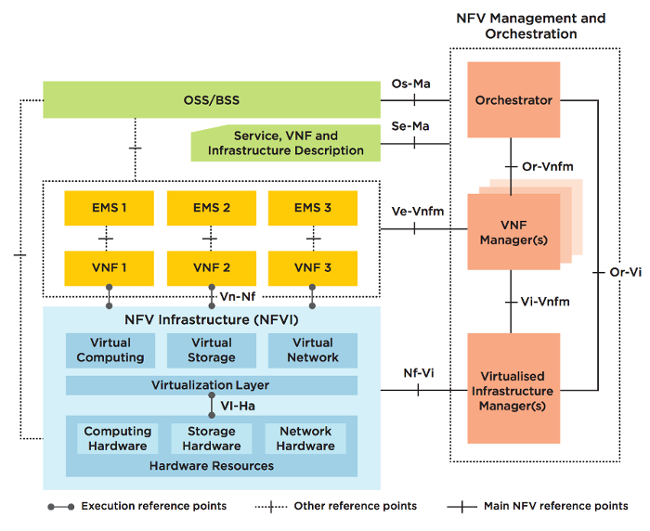
Над всеми тремя основными элементами расположены традиционные операторские Operations/Business support systems (OSS/BSS): системы мониторинга, управления, биллинга, провиженинга услуг, порталы самообслуживания, в которые NFV интегрируется либо как единый элемент (через MANO), либо интерфейсами NFVI- и VNF-плоскостей по отдельности.
Несмотря на актуальность самой концепции NFV и её пригодность для широкого спектра операторских задач, разрабатанные ETSI спецификации описывают лишь общую архитектуру, затрагивают лишь некоторые вопросы дизайна, безопасности и производительности. Накопленного опыта всё ещё мало, поэтому интересно было бы рассмотреть и сравнить между собой конкретные решения. Какие продукты взяты за их основу, каким образом обеспечивается оптимальная производительность, как организован service-chaining и как организовано сообщение с сетью оператора. Поэтому в следующей статье на эту тему мы детально рассмотрим одну из доступных NFV-платформ.
