[Из песочницы] .NET Managed + C unmanaged: какова цена?
Спустя некоторое время я все же выделил себе время изучить этот вопрос более детально, а наблюдениями хочу поделиться с вами.
Зачем?
Этот вопрос задаст любой уважающий себя программист. Вести проект на двух различных языках — дело очень сомнительное, тем более неуправляемый код действительно сложен в реализации, отладке и поддержке. Но лишь сама возможность реализовать функционал, который будет работать быстрее, уже достойна рассмотрения, особенно в критически важных участках или в высоко нагруженных приложениях.
Другой возможный ответ: функционал уже реализован в unamaged виде! Зачем переписывать решение целиком, если можно не очень большими затратами обернуть все в .NET и использовать оттуда?
В двух словах — такое действительно встречается. А мы лишь посмотрим, что да как.
Лирика
Весь код писался в Visual Studio Community 2015. Для оценки я использовал свой рабоче-игровой компьютер, с i5–3470 на борту, 12-ю гигабайтами 1333MHz двухканальной оперативной памяти, а также жестким диском на 7200 rpm. Замеры производились с помощью System.Diagnostics.Stopwatch, который точнее DateTime, потому что реализован поверх PerformanceCounter. Тесты запускались на Release вариантах сборок, чтобы исключить возможность того, что в действительности все будет немного иначе. Версия фрэймворка .NET 4.5.2, а C++ проект компилировался с флагом /TC (Compile as C).
Заранее прошу прощения за обилие кода, но без него будет сложно понять, чего именно я добивался. Большую часть слишком нудного или незначительного кода я вынес в спойлеры, а другую и вовсе вырезал из статьи (изначально она была еще длиннее).
Вызов функций
Свое исследование я решил начать именно с замера скорости вызова функций. Причин на это было несколько. Во-первых, функции все равно придется вызывать, а вызываются функции из загружаемых dll не очень быстро, в сравнении с кодом в том же модуле. Во-вторых, примерно таким образом реализовано большинство существующих C#-оберток поверх любого неуправляемого кода (напр. sharpgl, openal-cs, а sharpdx ушел куда-то не в ту сторону). Собственно, это самый очевидный способ встраивания неуправляемого кода, и самый простой.
Перед тем как начать непосредственно измерения, нужно подумать, как мы будем хранить и оценивать результаты наших измерений. «CSV!», подумал я, и написал простенький класс для хранения данных в этом формате:
public class CSVReport : IDisposable
{
int columnsCount;
StreamWriter writer;
public CSVReport(string path, params string[] header)
{
columnsCount = header.Length;
writer = new StreamWriter(path);
writer.Write(header[0]);
for (int i = 1; i < header.Length; i++)
writer.Write("," + header[i]);
writer.Write("\r\n");
}
public void Write(params object[] values)
{
if (values.Length != columnsCount)
throw new ArgumentException("Columns count for row didn't match table columns count");
writer.Write(values[0].ToString());
for (int i = 1; i < values.Length; i++)
writer.Write("," + values[i].ToString());
writer.Write("\r\n");
}
public void Dispose()
{
writer.Close();
}
}Не самый функциональный вариант, но для моей цели пойдет с лихвой. А для тестирования было принято решение написать простой класс, который умеет лишь суммировать числа и хранить результат. Вот так он выглядит:
class Summer
{
public int Sum
{
get; private set;
}
public Summer()
{
Sum = 0;
}
public void Add(int a)
{
Sum += a;
}
public void Reset()
{
Sum = 0;
}
}Но это управляемый вариант. Нам же нужен еще неуправляемый. Поэтому создаем шаблонный dll проект и сразу же добавляем туда файл, например, api.h, в который запихиваем определения экспорта:
#ifndef _API_H_
#define _API_H_
#define EXPORT __declspec(dllexport)
#define STD_API __stdcall
#endifРядышком положим summer.c, и реализуем весь необходимый нам функционал:
#include "api.h"
int sum;
EXPORT void STD_API summer_init( void )
{
sum = 0;
}
EXPORT void STD_API summer_add( int value )
{
sum += value;
}
EXPORT int STD_API summer_sum( void )
{
return sum;
}Теперь нам нужен класс-обертка над этим безобразием:
class SummerUnmanaged
{
const string dllName = @"unmanaged_test.dll";
[DllImport(dllName)]
private static extern void summer_init();
[DllImport(dllName)]
private static extern void summer_add(int v);
[DllImport(dllName)]
private static extern int summer_sum();
public int Sum
{
get
{
return summer_sum();
}
}
public SummerUnmanaged()
{
summer_init();
}
public void Add(int a)
{
summer_add(a);
}
public void Reset()
{
summer_init();
}
}В итоге получилось именно то, чего я и хотел. Есть две совершенно одинаковые для использования реализации: одна на C#, вторая на Си. Теперь можно и посмотреть, что из этого выйдет! Напишем код, который замерит время выполнения n вызовов одного и другого класса:
static void TestCall()
{
Console.WriteLine("Function calls...");
Stopwatch sw = new Stopwatch();
Summer s_managed = new Summer();
SummerUnmanaged s_unmanaged = new SummerUnmanaged();
Random r = new Random();
int[] data;
CSVReport report = new CSVReport("fun_call.csv", "elements", "C# managed", "C unmanaged");
data = new int[1000000];
for (int j = 0; j < 1000000; j++)
data[j] = r.Next(-1, 2); // Генерируем мусор
for (int i=0; i<100; i++)
{
// Чтобы не ждать у консоли погоды
Console.Write("\r{0}/100", i+1);
int length = 10000*i;
long managedTime = 0, unmanagedTime = 0;
Thread.Sleep(10);
s_managed.Reset();
sw.Start();
for (int j = 0; j < length; j++)
{
s_managed.Add(data[j]);
}
sw.Stop();
managedTime = sw.ElapsedTicks;
sw.Reset();
sw.Start();
for(int j=0; jОсталось только вызвать эту функцию где-нибудь в мэйне, да поглядеть отчет в fun_call.csv. Для наглядности я не буду приводить скучные и сухие цифры, а выведу лишь график. По вертикали — время в тиках, по горизонтали — количество вызовов функции.
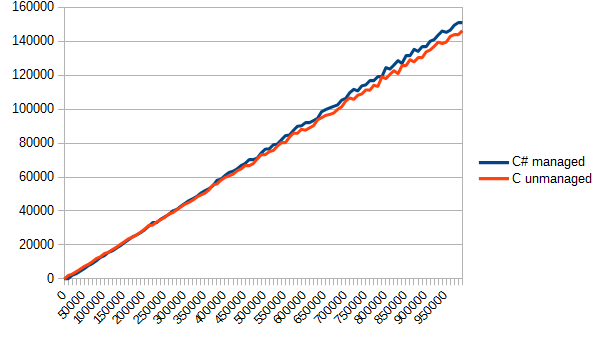
Результат меня немного удивил. C# явно был фаворитом в данном тесте. Все-таки, тот же модуль, да и возможность инлайнить…, но в результате оба варианта оказались приблизительно одинаковыми. Собственно, в данном случае такое разделение кода оказалось бессмысленным — ничего не выиграли, а проект усложнили.
Массивы
Размышления о результатах были не долгими, и я тут же понял — нужно отсылать данные не по одному элементу, а массивами. Настало время модернизировать код. Допишем функционал:
public void AddMany(int[] data)
{
int length = data.Length;
for (int i = 0; i < length; i++)
Sum += i;
}И, собственно, Си часть:
EXPORT int STD_API summer_add_many( int* data, int length )
{
for ( int i = 0; i < length; i++ )
sum += data[ i ];
} [DllImport(dllName)]
private static extern void summer_add_many(int[] data, int length);
public void AddMany(int[] data)
{
summer_add_many(data, data.Length);
}Соответственно, пришлось переписать и функцию измерения производительности. Полная версия в спойлере, а в двух словах: теперь мы генерируем массив из n случайных элементов и вызываем функцию их сложения.
static void TestArrays()
{
Console.WriteLine("Arrays...");
Stopwatch sw = new Stopwatch();
Summer s_managed = new Summer();
SummerUnmanaged s_unmanaged = new SummerUnmanaged();
Random r = new Random();
int[] data;
CSVReport report = new CSVReport("arrays.csv", "elements", "C# managed", "C unmanaged");
for (int i = 0; i < 100; i++)
{
Console.Write("\r{0}/100", i+1);
int length = 10000 * i;
long managedTime = 0, unmanagedTime = 0;
data = new int[length];
for (int j = 0; j < length; j++) // Генерируем мусор
data[j] = r.Next(-1, 2);
s_managed.Reset();
sw.Start();
s_managed.AddMany(data);
sw.Stop();
managedTime = sw.ElapsedTicks;
sw.Reset();
sw.Start();
s_unmanaged.AddMany(data);
sw.Stop();
unmanagedTime = sw.ElapsedTicks;
report.Write(length, managedTime, unmanagedTime);
}
report.Dispose();
Console.WriteLine();
}Запускаем, проверяем отчет. По вертикали все еще время в тиках, по горизонтали — количество элементов массива.
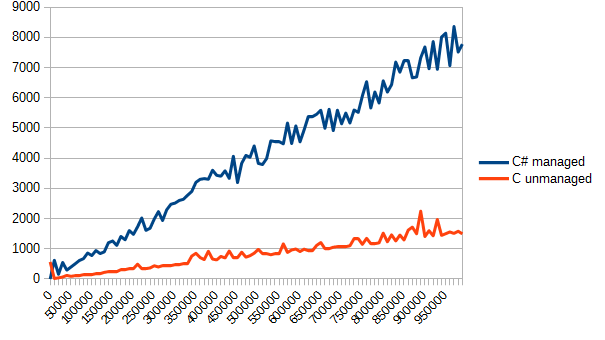
Видно невооруженным глазом — Си значительно лучше справляется с банальной обработкой массивов. Но это и есть цена за «управляемость» — в то время, как управляемый код в случае переполнения, выхода за границы массива, несовпадения фазы Луны с фазой Марса мягко кинет эксепшн, то си-код может запросто перезаписать не свою память и делать вид, что так и надо.
Чтение файла
Убедившись, что обрабатывать крупные массивы данных в Си быстрее, я решил — надо читать файлы. Это решение было вызвано желанием проверить, насколько шустро код сможет общаться с системой.
Для этих целей я сгенерировал стопку файлов (конечно же, линейно возрастающих в своем размере)
static void Generate()
{
Random r = new Random();
for(int i=0; i<100; i++)
{
BinaryWriter writer = new BinaryWriter(File.OpenWrite("file" + i.ToString()));
for(int j=0; j<200000*i; j++)
{
writer.Write(r.Next(-1, 2));
}
writer.Close();
Console.WriteLine("Generating {0}", i);
}
}В итоге самый большой файл получился 75 мегабайт, чего было вполне себе достаточно. Для теста я не стал выделять отдельный класс, а набыдлокодил прямо в класс мэина. Почему бы и нет, собственно.
static int FileSum(string path)
{
BinaryReader br = new BinaryReader(File.OpenRead(path));
int sum = 0;
long length = br.BaseStream.Length;
while(br.BaseStream.Position != length)
{
sum += br.ReadInt32();
}
br.Close();
return sum;
}Как видно из кода, задачу я поставил следующую: просуммировать все целые числа из файла. Соответствующая реализация на Си:
EXPORT int STD_API file_sum( const char* path )
{
FILE *f = fopen( path, "rb" );
if ( !f )
return 0;
int sum = 0;
while ( !feof( f ) )
{
int add;
fread( &add, sizeof( int ), 1, f );
sum += add;
}
fclose( f );
return sum;
}Теперь осталось циклически прочитать все файлы, да измерить скорость работы каждой реализации. Код функции замера приводить не буду (его можно составить и самому) и перейду сразу к наглядным демонстрациям.
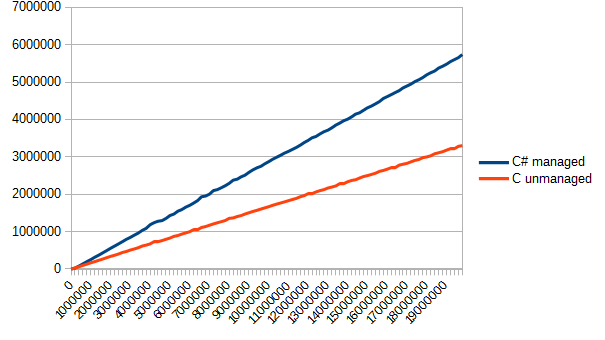
Как видно из данного графика, Си оказался немного быстрее (примерно в полтора раза). Но выигрыш есть выигрыш.
Где-то на этом моменте меня понесло немного в степь (или куда-то еще), но не поделиться этими размышлениями я не могу. Любопытных прошу в спойлер, а всех остальных прошу перейти к следующей части моих исследований.
long length = br.BaseStream.Length;
byte[] buffer = new byte[100000*4];
while(br.BaseStream.Position != length)
{
int read = br.Read(buffer, 0, 100000*4);
for(int i=0; i int sum = 0;
int *buffer = malloc( 100000 * sizeof( int ) );
while ( !feof( f ) )
{
int read = fread( buffer, sizeof( int ), 100000, f );
for ( int i = 0; i < read; i++ )
{
sum += buffer[ i ];
}
}Этот тест я не захотел включать в «основу» статьи, и на то была одна причина: тест не совсем справедливый. Си явно лучше подходил для такой задачи, потому что может писать что угодно и куда угодно, а вот в C# пришлось дополнительно конвертировать все побайтово, из-за чего я получил то, что получил:
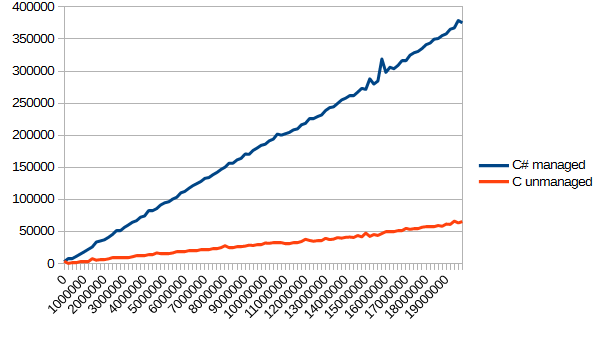
Я склонен думать, что такая разница в производительности вызвана именно необходимостью дополнительно конвертировать байты в слова. Вообще, эта тема заслуживает отдельной статьи, которую я может быть даже напишу.
Возвращение массивов
Следующим шагом в замерах производительности стало возвращение более сложных типов, потому что общаться числами целыми и с плавающей точкой будет не всегда удобно. Поэтому нужно проверить, насколько быстро можно приводить неуправляемые области памяти к управляемым. Для этого было принято решение реализовать простую задачу: чтение файла целиком и возвращение его содержимого в виде массива байтов.
На чистом C# такая задача реализуется весьма просто, но чтобы связать Си код с C# кодом в данном случае придется сделать кое-что еще.
Для начала, решение на C#
static byte[] FileRead(string path)
{
BinaryReader br = new BinaryReader(File.OpenRead(path));
byte[] ret = br.ReadBytes((int)br.BaseStream.Length);
br.Close();
return ret;
}И соответствующее решение на Си:
EXPORT char* STD_API file_read( const char* path, int* read )
{
FILE *f = fopen( path, "rb" );
if ( !f )
return 0;
fseek( f, 0, SEEK_END );
long length = ftell( f );
fseek( f, 0, SEEK_SET );
read = length;
int sum = 0;
uint8_t *buffer = malloc( length );
int read_f = fread( buffer, 1, length, f );
fclose( f );
return buffer;
}Для успешного вызова такой функции из C# нам придется написать обертку, которая вызовет эту функцию, скопирует данные из неуправляемой памяти в управляемую, да освободит неуправляемый участок:
static byte[] FileReadUnmanaged(string path)
{
int length = 0;
IntPtr unmanaged = file_read(path, ref length);
byte[] managed = new byte[length];
Marshal.Copy(unmanaged, managed, 0, length);
Marshal.FreeHGlobal(unmanaged); // Мы же не желаем протекать?
return managed;
}В функции замера изменились только соответствующие вызовы измеряемых функций. А результат выглядит вот так:
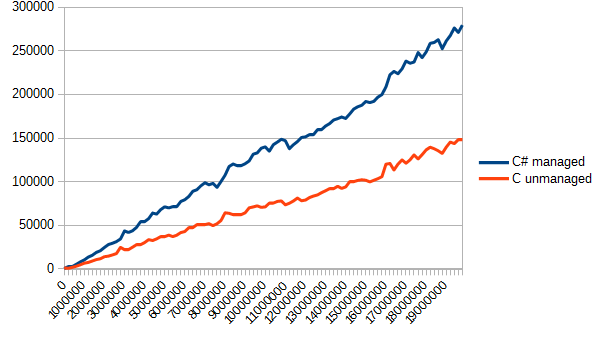
Даже с потерями времени на копирование памяти Си снова оказался в лидерах, выполняя поставленную задачу примерно в 2 раза быстрее. Честно говоря, я ожидал немного других результатов (учитывая данные второго теста). Скорее всего из-за того, что чтение данных даже крупной пачкой в C# происходит достаточно медленно. В Си же потрея времени идет при копировании неуправляемой памяти в управляемую.
Реальная задача
Логическим заключением всех проведенных мною тестов было таким: реализовать какой-нибудь полноценный алгоритм на C# и на Си. Быстродействие оценить.
За алгоритм я принял чтение несжатого TGA файла с 32 битами на пиксель, да приведение его в нормальное RGBA представление (TGA формат подразумевает хранение цвета как BGRA). Чтобы жизнь не казалась маслом, возвращать будем не байты, а структуры Color:
struct Color
{
public byte r, g, b, a;
}Реализация алгоритма довольно емкая, да и вряд ли интересна. Поэтому она вынесена в спойлер, чтобы не мозолить глаза тем, кому не интересно.
static Color[] TGARead(string path)
{
byte[] header;
BinaryReader br = new BinaryReader(File.OpenRead(path));
header = br.ReadBytes(18);
int width = (header[13] << 8) + header[12]; // Небольшая магия, чтобы получить short
int height = (header[15] << 8) + header[14]; // Little-Endian, сначала младшие разряды
byte[] data;
data = br.ReadBytes(width * height * 4);
Color[] colors = new Color[width * height];
for(int i=0; i(colors);
colors += 4;
}
Marshal.FreeHGlobal(save);
return ret;
}
И Сишный вариант:
#include "api.h"
#include
#include
// Ведет к беде, если структура выровняется
// не по 4 байтам
typedef struct {
char r, g, b, a;
} COLOR;
// Костыль, чтобы читать структуру целиком
#pragma pack(push)
#pragma pack(1)
typedef struct {
char idlength;
char colourmaptype;
char datatypecode;
short colourmaporigin;
short colourmaplength;
char colourmapdepth;
short x_origin;
short y_origin;
short width;
short height;
char bitsperpixel;
char imagedescriptor;
} TGAHeader;
#pragma pack(pop)
EXPORT COLOR* tga_read( const char* path, int* width, int* height )
{
TGAHeader header;
FILE *f = fopen( path, "rb" );
fread( &header, sizeof( TGAHeader ), 1, f );
COLOR *colors = malloc( sizeof( COLOR ) * header.height * header.width );
fread( colors, sizeof( COLOR ), header.height * header.width, f );
for ( int i = 0; i < header.width * header.height; i++ )
{
char t = colors[ i ].r;
colors[ i ].r = colors[ i ].b;
colors[ i ].b = t;
}
fclose( f );
return colors;
} Теперь дело осталось за малым. Нарисовать простое TGA изображение и загружать его n раз. Результат получился таким (по вертикали как обычно, по горизонтали — количество чтений файла).
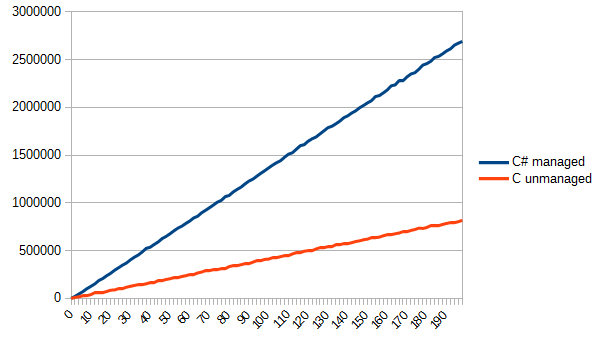
Тут нужно отметить, что я нагло использовал возможности Си в его пользу. Читать из файла прямо в структуры существенно облегчило жизнь (а в случае, когда структуры выровняются не по 4 байтам, будет веселая отладка). Однако результатом я доволен. Такой вот незамысловатый алгоритм получилось эффективно реализовать на Си, и эффективно его же использовать в C#. Соответственно, я получил ответ на изначальный вопрос: выиграть действительно можно, но не всегда. Иногда можно выиграть незначительно, иногда не выиграть вовсе, а иногда выиграть в несколько и больше раз.
Сухой остаток
В целом, сама идея выносить реализацию чего-то на другой язык сомнительна, как я и написал в самом начале. В конце концов, применения такому способу ускорения кода можно найти достаточно мало. Если открытие файла начинает вешать UI — можно вынести загрузку в отдельный фоновый поток, и тогда загрузка даже в секунду не вызовет ни у кого серьезных затруднений.
Соответственно, так извращаться стоит только тогда, когда производительность действительно необходима, и добиться ее другими путями уже не получается (а в таких случаях обычно пишут сразу на Си или С++). Или если уже есть готовый алгоритм, который можно использовать, а не изобретать велосипед.
Хочется отметить, что простая обертка над неуправляемой dll особого выигрыша в производительности не даст, и вся «шустрость» неуправляемых языков начинает раскрываться только при обработке достаточно больших объемов данных, так что на это тоже стоит обратить внимание. Однако и от использования такой обертки хуже не станет.
C# очень хорошо справляется с передачей управляемых ресурсов неуправляемому коду, но обратное превращение происходит не так быстро, как хотелось бы. Поэтому частого преобразования данных желательно избегать и держать неуправляемые ресурсы в неуправляемом коде. Если нет необходимости эти данные править / читать в управляемом коде, то можно использовать IntPtr для хранения указателей, а оставшуюся работу вынести целиком в неуправляемый код.
Конечно, можно (и даже нужно) провести дополнительные исследования перед принятием окончательного решения о переносе кода в неуправляемые сборки. Но и с текущей информацией можно принять решение о целесообразности таких действий.
А на этом у меня все. Спасибо, если дочитали до конца!
Комментарии (13)
7 апреля 2017 в 18:28 (комментарий был изменён)
0↑
↓
Замеры производились с помощью System.Diagnostics.Stopwatch, который точнее DateTime, потому что реализован поверх PerformanceCounter.
Why not BenchmarkDotNet? GrimMaple
GrimMaple
7 апреля 2017 в 19:25
+2↑
↓
Потому что до этого комментария не знал о существовании такого инструмента. Теперь знаю, спасибо :)
7 апреля 2017 в 18:38 (комментарий был изменён)
+1↑
↓
А проверьте еще c# unmanaged.-
GrimMaple
7 апреля 2017 в 19:27
0↑
↓
Если вы про unsafe, то я не самый большой его поклонник. Не нравится, как он выглядит. Впрочем, можно будет как-нибудь и его посмотреть.7 апреля 2017 в 20:02
0↑
↓
Нравится/не нравится это не про бенчмарки=)
Без него сравнение не полное. По идее получится что-то среднее…
А может иногда и быстрее c+p/invoke-
GrimMaple
7 апреля 2017 в 20:25
0↑
↓
Хороший аргумент. Попробую заняться этим вопросом, когда появится желание+свободное время :)
 maaGames
maaGames
7 апреля 2017 в 18:52
0↑
↓
А теперь перепишите с указателями, вместо счётчика цикла. Я про С. Videoman
Videoman
7 апреля 2017 в 18:58
+1↑
↓
И ничего не будет. Только замусорится семантика. Может быть будет даже хуже.-
maaGames
7 апреля 2017 в 19:00
0↑
↓
Если оптимизирующий компилятор сам не заменил индекс на указатель, то очень даже будет.
Более того, итератор гораздо более семантически «чист», чем индекс массива.-
Videoman
7 апреля 2017 в 19:07 (комментарий был изменён)
+2↑
↓
При работе со значениями у оптимизатора гораздо больше уверенности при оптимизации и руки развязаны. Когда вы применяете указатели, вы легко его можете запутать и он пессимизирует оптимизацию. На сомом деле, в коде с указателями невозможно понять (за исключение ну уж совсем тривиальных случаев) ссылаются ли два указателя на один объект или на два разных. Я всегда применяю магию с указателям, когда не хочу чтобы компилятор выкинул «мертвый», по его мнению код. Стоит только выкинуть указатели, и оптимизатор начинает выкидывать методы пачками.-
maaGames
7 апреля 2017 в 19:13
0↑
↓
Сумма значений в массиве. Тут целый один итератор, плюс ещё один указатель на конец массива. Запутаться может только неосилятор, но никак не компилятор. На мой взгляд, в данной конкретной ситуации с указателями код гораздо проще, чем с индексом. Не говоря о том, что это «более STL-ориентированно».) Индексы нужны только в том случае, если обработка происходит не последовательно, а с шагом не равным единице. Или если цикл хочется распараллелить. Называть инкремент указателя магией… Впрочем, для C# программистов указатели и впрямь могут казаться магией…
-
GrimMaple
7 апреля 2017 в 19:45
+1↑
↓
Заморочился, переписал:int* end = data + length; while ( data != end ) sum += *data++;
Результат не изменился почти никак, как и отметил Videoman
Как-то так. Но идея была интересная.
 crea7or
crea7or
7 апреля 2017 в 19:22
0↑
↓
Я для того же делал два проекта for fun при поиске совпадений степеней по теореме Эйлера, ну c# проигрывает с++, но не сказать чтобы прямо очень.
