[Из песочницы] Лучший Pull Request
Относительно недавно мне посчастливилось присоединиться к команде разработки Bitbucket Server в Atlassian (до сентября он был известен как Stash). В какой-то момент мне стало любопытно, как этот продукт освещён на Хабре, и к моему удивлению, нашлось лишь несколько заметок о нём, подавляющее большинство которых на сегодняшний день уже устарело.
В связи с этим я решил опробовать себя в роли рассказчика и затронуть техническую сторону Bitbucket. Прошу не рассматривать моё намерение как попытку рекламы, ибо я совершенно не преследую эту цель. Если эта статья обнаружит интерес со стороны читателей, я буду рад развивать тему и постараюсь ответить на возникающие вопросы.
Позвольте начать с перевода статьи Тима Петтерсена «A better pull request» о том, как должен выглядеть pull request, чтобы наиболее эффективно решать возложенную на него задачу.
Мне хотелось бы пользоваться привычными названиями и в письменной речи, однако некоторые термины я не буду даже транслитерировать, поскольку, на мой взгляд, они становятся слишком корявыми, и потому оставлю их в английском написании, — прошу понять и простить. С другой стороны, я открыт критике и предложениям, поэтому если вы считаете, что есть лучший способ выразить тот или иной термин, прошу делиться этими мыслями. Спасибо.
Если вы используете Git, то наверняка пользуетесь и pull request-ами. Они в той или иной форме существуют с момента появления распределённых систем управления версиями. До того, как Bitbucket и GitHub предложили удобный веб-интерфейс, pull request мог представлять собой простое письмо от Алисы с просьбой забрать какие-то изменения из её репозитория. Если они были стóящими, вы могли выполнить несколько команд, чтобы влить эти изменения в вашу основную ветку master:
$ git remote add alice git://bitbucket.org/alice/bleak.git
$ git checkout master
$ git pull alice master
Разумеется, включать изменения от Алисы в master не глядя — это далеко не лучшая идея: ведь master содержит код, который вы собираетесь поставлять клиентам, а потому наверняка хотите внимательно следить за тем, что в него попадает. Более правильный путь, чем простое включение изменений в master, — это сначала влить их в отдельную ветку и проанализировать перед тем, как cливать в master:
$ git fetch alice
$ git diff master...alice/master
Приведённая команда git diff с синтаксисом трёх точек (в дальнейшем «triple dot» git diff) покажет изменения между вершиной ветки alice/branch и её merge base — общим предком с локальной веткой master, иначе говоря, с точкой расхождения истории коммитов этих веток. В сущности, это будут ровно те изменения, которые Алиса просит нас включить в основную ветку.

git diff master…alice/master эквивалентен git diff A B
На первый взгляд, это кажется разумным способом проверки изменений pull request-а. Действительно, на момент написания статьи, именно такой алгоритм сравнения применяется в реализации pull request-ов в большинстве инструментов, предоставляющих хостинг git-репозиториев.
Несмотря на это, есть несколько проблем в использовании «triple dot» git diff для анализа изменений pull request-а. В реальном проекте основная ветка, скорее всего, будет сильно отличаться от любой ветки функциональности (в дальнейшем feature-ветка). Работа над задачами ведётся в отдельных ветках, которые по окончании вливаются в master. Когда master продвигается вперёд, простой git diff от вершины feature-ветки до её merge base уже недостаточен для отображения настоящего различия между этими ветками: он покажет разницу вершины feature-ветки лишь с одним из предыдущих состояний master.

Ветка master продвигается за счёт вливания новых изменений. Результат git diff master…alice/master не отражает этих изменений master.
Почему же невозможность увидеть эти изменения в ходе анализа pull request-а является проблемой? Тому есть две причины.
Конфликты слияния (merge conflicts)
С первой проблемой вы наверняка регулярно сталкиваетесь — конфликты слияния. Если в вашей feature-ветке вы измените файл, который в то же время был изменён в master, git diff по-прежнему будет отображать только изменения, сделанные вами в feature-ветке. Однако при попытке выполнить git merge вы столкнётесь с ошибкой: git расставит маркеры конфликтов в файлах вашей рабочей копии, поскольку сливаемые ветки имеют противоречивые изменения, — такие, которые git не в состоянии разрешить даже с помощью продвинутых стратегий слияния.
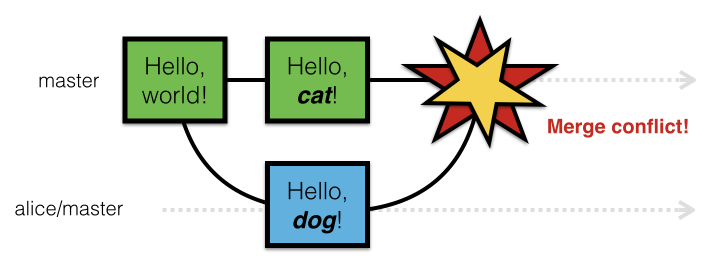
Конфликт слияния
Вряд ли кому-то нравится заниматься разрешением конфликтов слияния, но они являются данностью любой системы контроля версий, — по крайней мере, из тех, которые не поддерживают блокирование на уровне файла (которое, в свою очередь, имеет ряд своих проблем).
Однако конфликты слияния — это меньшая неприятность, с которой вы можете столкнуться при использовании «triple dot» git diff для pull request-ов, по сравнению с другой проблемой: особый тип логического конфликта будет успешно слит, но сможет внести коварную ошибку в кодовую базу.
Логические конфликты, остающиеся незамеченными во время слияния
Если разработчики модифицируют разные части одного и того же файла в разных ветках, появляется вероятность того, что они создадут такой конфликт. В некоторых случаях разные изменения, которые исправно работают по отдельности и отлично сливаются безо всяких конфликтов с точки зрения системы контроля версий, могут внести логическую ошибку в код, будучи применёнными вместе.
Это может произойти различными путями, однако самым распространённым является вариант, когда два разработчика случайно замечают и исправляют одну и ту же ошибку в двух разных ветках. Представьте, что приведённый ниже код на javascript вычисляет стоимость авиабилета:
// flat fees and taxes
var customsFee = 5.5;
var immigrationFee = 7;
var federalTransportTax = .025;
function calculateAirfare(baseFare) {
var fare = baseFare;
fare += immigrationFee;
fare *= (1 + federalTransportTax);
return fare;
}
Здесь содержится очевидная ошибка: автор забыл включить в расчёт таможенный сбор!
Теперь представьте двух разработчиков, Алису и Боба, каждый из которых заметил эту ошибку и исправил её независимо от другого в своей ветке.
Алиса добавила строку для учёта customsFee перед immigrationFee:
function calculateAirfare(baseFare) {
var fare = baseFare;
+++ fare += customsFee; // Fixed it! Phew. Glad we didn't ship that! - Alice
fare += immigrationFee;
fare *= (1 + federalTransportTax);
return fare;
}
Боб сделал аналогичную правку, однако поместил её после immigrationFee:
function calculateAirfare(baseFare) {
var fare = baseFare;
fare += immigrationFee;
+++ fare += customsFee; // Fixed it! Gee, lucky I caught that one. - Bob
fare *= (1 + federalTransportTax);
return fare;
}
Поскольку в каждой из этих веток были изменены разные строки кода, слияние обеих с master пройдёт успешно одно за другим. Однако теперь master будет содержать обе добавленные строки, а значит, клиенты будут дважды платить таможенный сбор:
function calculateAirfare(baseFare) {
var fare = baseFare;
fare += customsFee; // Fixed it! Phew. Glad we didn't ship that! - Alice
fare += immigrationFee;
fare += customsFee; // Fixed it! Gee, lucky I caught that one. - Bob
fare *= (1 + federalTransportTax);
return fare;
}
(Это, разумеется, надуманный пример, однако дублированный код или логика могут вызвать весьма серьёзные проблемы: к примеру, дыру в реализации SSL/TLS в iOS.)
Предположим, что вы сначала слили в master изменения pull request-а Алисы. Вот что показал бы pull request Боба, если бы вы использовали «triple dot» git diff:
function calculateAirfare(baseFare) {
var fare = baseFare;
fare += immigrationFee;
+++ fare += customsFee; // Fixed it! Gee, lucky I caught that one. - Bob
fare *= (1 + federalTransportTax);
return fare;
}
Поскольку вы анализируете изменения по сравнению с общим предком, нет никакого предупреждения об угрозе ошибки, которая случится, когда вы нажмёте на кнопку слияния.
На самом же деле, при анализе pull request-а вы хотели бы видеть, как master изменится после слияния изменений из ветки Боба:
function calculateAirfare(baseFare) {
var fare = baseFare;
fare += customsFee; // Fixed it! Phew. Glad we didn't ship that! - Alice
fare += immigrationFee;
+++ fare += customsFee; // Fixed it! Gee, lucky I caught that one. - Bob
fare *= (1 + federalTransportTax);
return fare;
}
Здесь явно обозначена проблема. Рецензент pull request-а, будем надеяться, заметит дублированную строчку и уведомит Боба о том, что код нужно доработать, и тем самым предотвратит попадание серьёзной ошибки в master и, в конечном счёте, в готовый продукт.
Таким образом мы решили реализовать показ изменений в pull request-ах в Bitbucket. При просмотре pull request-а вы видите, как на самом деле будет выглядеть результат слияния (т.е. фактически, результирующий коммит). Чтобы осуществить это, мы производим настоящее слияние веток и показываем разницу между получившимся коммитом и верхушкой целевой ветки pull request-а:
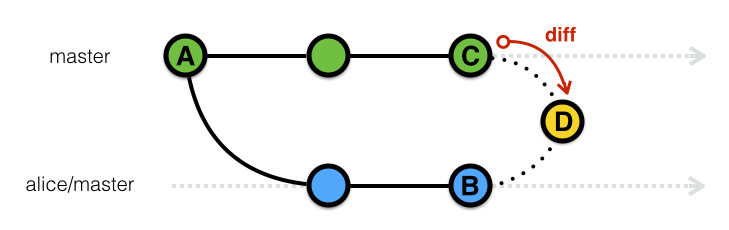
git diff C D, где D — это коммит, получившийся в результате слияния, показывает все различия между двумя ветками
Если вам интересно, я разместил одинаковый репозиторий на нескольких хостингах, чтобы вы сами смогли увидеть описанную разницу между алгоритмами сравнения:
Сравнение на основе коммита слияния, используемое в Bitbucket, показывает фактические изменения, которые будут применены, когда вы выполните слияние. Загвоздка в том, что этот алгоритм сложнее в реализации и требует значительно больше ресурсов для выполнения.
Продвижение веток
Во-первых, коммит слияния D на самом деле ещё не существует, а его создание — относительно дорогой процесс. Во-вторых, недостаточно просто создать коммит D и на этом закончить: B и C, родительские коммиты для нашего коммита слияния, могут поменяться в любое время. Мы называем изменение любого из родительских коммитов пересмотром (rescope) pull request-а, поскольку оно, по сути, модифицирует тот набор изменений, который будет применён в результате слияния pull request-а. Если ваш pull request нацелен на нагруженную ветку вроде master, он наверняка пересматривается очень часто.

Коммиты слияния создаются каждый раз, когда любая из веток pull request-а изменяется
Фактически, каждый раз когда кто-то коммитит или сливает pull request в master или feature-ветку, Bitbucket должен создать новый коммит слияния, чтобы показать актуальную разницу между ветками в pull request-е.
Обработка конфликтов слияния
Другая проблема при выполнении слияния для отображения разницы меджу ветками в pull request-е заключается в том, что время от времени вам придётся иметь дело с конфликтами слияния. Поскольку git сервер работает в неинтерактивном режиме, разрешать такие конфликты будет некому. Это ещё больше усложняет задачу, но на деле оказывается преимуществом. В Bitbucket мы действительно включаем маркеры конфликтов в коммит слияния D, а затем помечаем их при отображении разницы между ветками, чтобы явно указать вам на то, что pull request содержит конфликты:
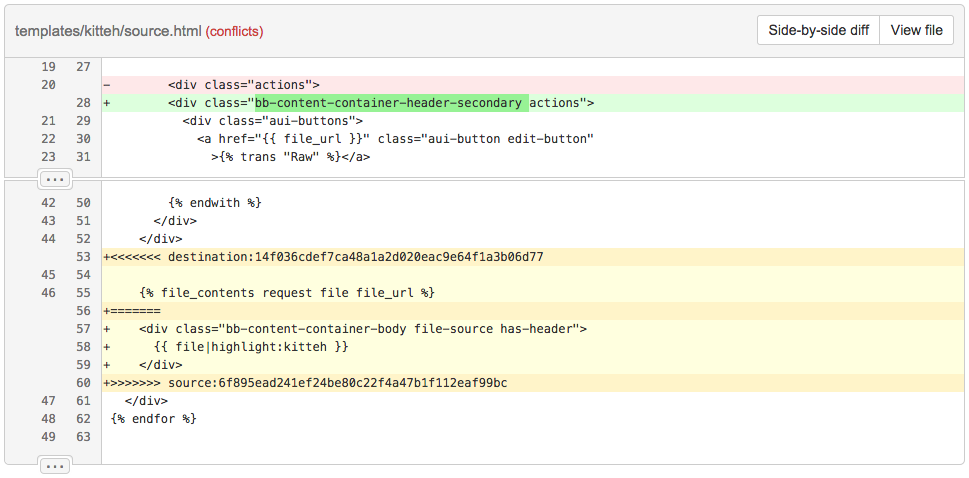
Зелёные строки добавлены, красные — удалены, а жёлтые означают конфликт
Таким образом, мы не только заранее выявляем, что pull request содержит конфликт, но и позволяем рецензентам обсудить, как именно он должен быть разрешён. Поскольку конфликт всегда затрагивает, как минимум, две стороны, мы считаем, что pull request — это лучшее место для нахождения подходящего способа его разрешения.
Несмотря на дополнительную сложность реализации и ресурсоёмкость используемого подхода, я считаю, что выбранный нами в Bitbucket подход предоставляет наиболее точную и практичную разницу между ветками pull request-а.
Автор оригинальной статьи — Тим Петтерсен, участвовал в разработке JIRA, FishEye/Crucible и Stash. С начала 2013 года он рассказывает о процессах разработки, git, непрерывной интеграции и поставке (continuous integration/deployment) и инструментах Atlassian для разработчиков, особенно о Bitbucket. Тим регулярно публикует заметки об этих и других вещах в Twitter под псевдонимом @kannonboy.
Надеюсь, что эта статья оказалась интересной. Буду рад ответить на вопросы и комментарии.
