[Из песочницы] Копирование данных с веб-сайта с помощью R и библиотеки rvest
Чтобы проводить анализ данных, необходимо сначала эти данные собрать. Для этой цели есть много разных методов. В этой статье мы будем говорить о копировании данных непосредственно с веб-сайта, или о скрейпинге (scraping). На Хабре есть несколько статей о том, как сделать копирование с помощью Python. Мы будем использовать язык R (вер.3.4.2) и его библиотеку rvest. В качестве примера рассмотрим копирование данных с Google Scholar (GS).
GS — это поисковая система, которая ищет информацию не во всем Интернете, а только в опубликованных статьях, или патентах. Это может быть очень полезно. Например, при поиске научных статей по некоторым ключевым словам. Для этого в строке поиска надо ввести эти слова. Или, допустим необходимо найти статьи, опубликованные определенным автором. Для этого можно просто набрать его фамилию, но лучше использовать ключевое слово 'author', и ввести что-то вроде 'author: «D Smith»'.
Давайте сделаем такой поиск и посмотрим на результат.
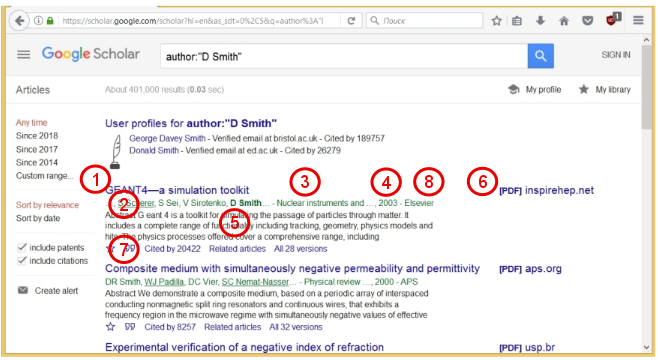
GS показывает, что найдено порядка 400 тыс. статей. Для каждой статьи дается ее название (1), фамилии авторов (2), название журнала (3), год выпуска (4), и краткая аннотация (5). Если доступен PDF-файл статьи, то справа дается соответствующая ссылка (6). Также для каждой статьи указывается важный параметр (7), а именно, сколько раз данная статья упоминалась в других работах («Cited by »). Этот параметр показывает насколько востребована данная работа. Используя данный параметр по нескольким статьям, можно оценить продуктивность и «востребованность» ученого. Это — так называемый индекс Хирша (H-index) ученого. По Википедии, индекс Хирша определяется следующим образом:
«Учёный имеет индекс h, если h из его Np статей цитируются как минимум h раз каждая, в то время как оставшиеся (Np — h) статей цитируются не более чем h раз каждая».
Другими словами, если список всех статей некоторого автора упорядочить по убыванию числа цитирований $inline$N_c$inline$, то порядковый номер $inline$n$inline$ последней статьи, для которой выполняется условие $inline$n \le N_c$inline$, и есть индекс Хирша. В связи с тем, что различные научные фонды и организации сейчас уделяют особое внимание индексу Хирша и другим наукометрическим показателям, люди научились «накручивать» эти показатели. Но это уже другая история.
В данной статье мы будем вести поиск по статьям определенного автора. Для примера возьмем российского ученого Алексея Яковлевича Червоненкиса. А.Я. Червоненкис — известный российский ученый в области информатики, внес значительный вклад в теорию анализа данных и машинного обучения. Он трагически погиб в 2014 году.
Мы будем собирать следующие 7 параметров статей: Название статьи (1), Список авторов (2), Название журнала (3), Год выпуска (4), Издательство (8), Число цитирований (7), Ссылка на цитирующие статьи (7). Последний параметр нужен, например, если мы хотим посмотреть взаимосвязи авторов, выявить сеть (network) людей, ведущих исследования в определенном направлении.
Подготовка
Сначала надо установить пакет rvest. Для этого используем следующую команду R:
install.packages(rvest)Теперь нам нужен инструмент, который показывает, какому компоненту кода веб-страницы соответствует тот или иной параметр. Можно использовать инструменты встроенные в браузер. Например, в Мозилле можно выбрать в Меню: «Инструменты → Веб-разработка → Инспектор». Будет показан НТМЛ-код веб страницы. Тогда, наводя курсор на некоторый элемент страницы, можно видеть, какой CSS код ему соответствует. Но мы поступим проще. Мы будем использовать инструмент SelectorGadget. Для этого надо пойти на указанный сайт и добавить ссылку на код (находится в конце описания программы) в Закладки вашего браузера.

Теперь находясь на любой странице, можно кликнуть на данную закладку, и появится удобный инструмент, позволяющий определять компоненты кода данной страницы (подробности, см. ниже).
Перед копированием данных также полезно изучить свойства веб-страницы, а именно, как меняется вид страницы от вида запроса, каким адресам соответствуют различные линки и т.д. Итак, мы будем искать статьи А.Я. Червоненкиса по следующему запросу: author: «A Chervonenkis». Это соответствует следующему адресу:
https://scholar.google.com/scholar?hl=en&as_sdt=1%2C5&as_vis=1&q=author%3A%22A+Chervonenkis%22&btnG=При таком синтаксисе запроса, не учитываются патенты, а также статьи, которые ссылаются на Червоненкиса, но в которых он не является автором.
Копирование данных
Теперь займемся программой по копированию данных. Сначала подключаем библиотеку rvest:
library(rvest)Далее задаем необходимый адрес и считываем НТМL-код веб-страницы:
url <- 'https://scholar.google.com/scholar?hl=en&as_sdt=1%2C5&as_vis=1&q=author%3A%22A+Chervonenkis%22&btnG='
wpage <- read_html(url)Теперь скопируем названия статей. Для этого запускаем SelectorGadget, и кликаем на название какой-то статьи. Это название выделяется зеленым цветом, но также выделяются (желтым цветом) и другие компоненты страницы. Строка SelectorGadget’a показывает, что изначально выбраны 152 компонента.
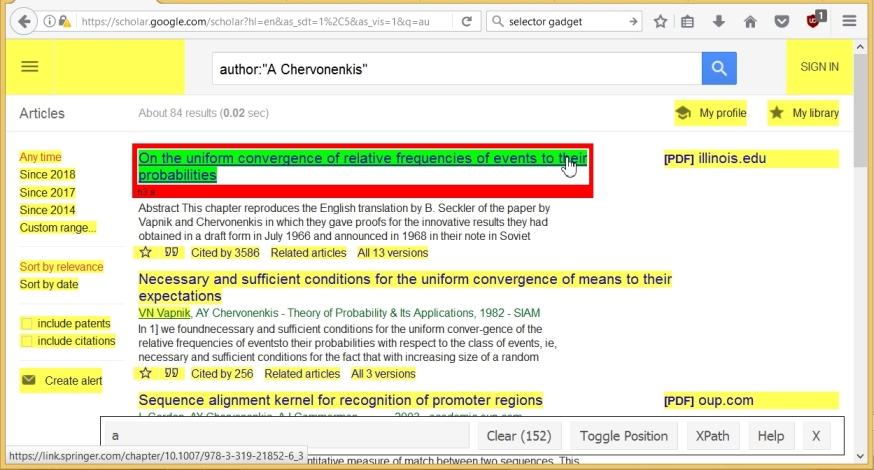
Теперь мы просто кликаем на ненужные нам компоненты. В итоге, их остается только 10 (по числу статей на странице), а также в строке SelectorGadget’a дается имя компонента, соответствующего названию статьи, а именно ».gs_rt a».
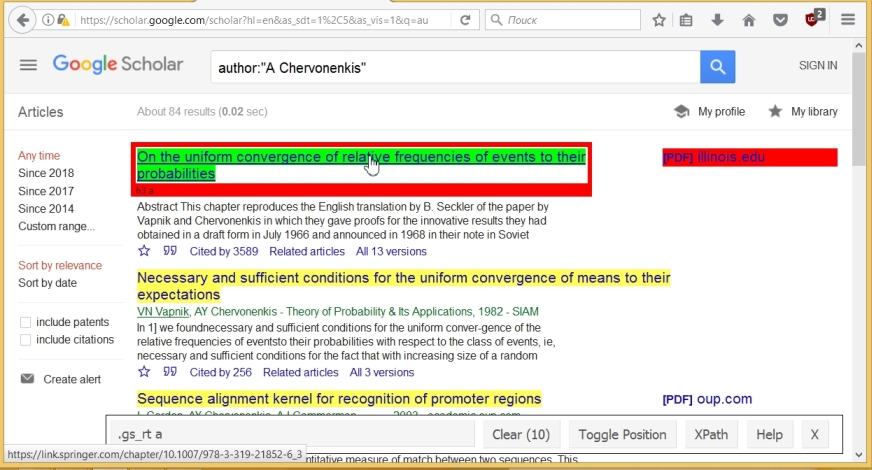
Используя это имя мы можем скопировать все названия, и конвертировать их в текстовый формат с помощью следующих команд (последняя команда дает структуру переменной titles):
titles <- html_nodes(wpage, '.gs_rt a')
titles <- html_text(titles)
str(titles)
## chr [1:10] "On the uniform convergence of relative frequencies of ..."Здесь и далее, после символов '##' показан вывод программы (в усеченном виде).
Аналогично, определяем, что имена авторов, название журнала, год, и издательство соответствуют компоненте ».gs_a». При этом, текст этой компоненты имеет следующий формат »<авторы>-<журнал, год>-<издательство>». Извлекаем текст из ».gs_a», выделяем нужные нам параметры (authors, journals, year, publ) в соответствии с форматом, убираем ненужные знаки и пробелы
# Scrap combined data, convert to text format:
comb <- html_nodes(wpage,'.gs_a')
comb <- html_text(comb)
str(comb)
## chr [1:10] "VN Vapnik, AY Chervonenkis - Measures of complexity, ..."
lst <- strsplit(comb, '-')
# Find authors, journal, year, publisher, extracting components of list
authors <- sapply(lst, '[[', 1) # Take 1st component of list
publ <- sapply(lst, '[[', 3)
lst1 <- strsplit( sapply(lst, '[[', 2), ',')
journals <- sapply(lst1, '[[', 1)
year <- sapply(lst1, '[[', 2)
# Replace 3 dots with ~, trim spaces, convert 'year' to numeric :
authors <- trimws(gsub(authors, pattern= '…', replacement= '~'))
journals <- trimws(gsub(journals, pattern= '…', replacement= '~'))
year <- as.numeric(gsub(year, pattern= '…', replacement= '~'))
publ <- trimws(gsub(publ, pattern= '…', replacement= '~'))
str(authors)
## chr [1:10] "VN Vapnik, AY Chervonenkis " "VN Vapnik, AY Chervonenkis " ...Отметим, что иногда название журнала содержит дефис »-». В этом случае, процедура выделения параметров из исходной строки несколько изменится.
Далее с помощью SelectorGadget определяем имя компоненты для числа цитирований на статью, убираем лишние слова и преобразуем данные в числовой формат
cit0 <- html_nodes(wpage,'#gs_res_ccl_mid a:nth-child(3)')
cit <- html_text(cit0)
lst <- strsplit(cit, ' ')
cit <- as.numeric(sapply(lst, '[[', 3))
str(cit)
## num [1:10] 3586 256 136 102 30 ...И наконец, извлекаем соответствующий линк:
cit_link <- html_attr(cit0, 'href')
str(cit_link)
## chr [1:10] "/scholar?cites=3657561935311739131&as_sdt=2005&..."Теперь у нас есть 7 векторов (titles, authors, journals, year, publ, cit, cit_link) для наших 7 параметров. Мы можем объединить их в единую структуру (dataframe)
df1 <- data.frame(titles= titles, authors= authors,
journals= journals, year= year, publ = publ,
cit= cit, cit_link= cit_link, stringsAsFactors = FALSE)Можно программно перейти на следующую страницу, добавив в адрес 'start=n&', где n/10+1 соответствует номеру страницы. Таким образом, можно собрать информацию по всем статьям
автора. Далее, используя ссылки на цитирующие статьи (cit_link), можно найти данные и по другим авторам.
В заключение, несколько замечаний. В Условиях пользования услугами Гугла написано следующее:
«Don«t misuse our Services. For example, don«t interfere with our Services or try to access them using a method other than the interface and the instructions that we provide.»
Информация в Интернете свидетельствует о том, что Гугл отслеживает доступ к его веб-страницам, в частности в GS. Если Гугл подозревает, что информация извлекается с помощью бота, он может ограничить или закрыть доступ к информации с определенного IP-адреса. Например, если запросы идут слишком часто, или через равные промежутки времени, то такое поведение рассматривается, как подозрительное.
Рассмотренный метод можно легко адаптировать к другим веб-сайтам. Комбинация R, rvest SelectorGadget делает копирование данных достаточно простым.
При подготовке данной статьи использовалась информация отсюда.
