[Из песочницы] Как устроена локализация в Netflix — перевод
Привет, Хабр! Представляю вашему вниманию перевод материала «Localization Technologies at Netflix», написанного командой Netflix про внутренние процессы локализации и программы, разработанные специально для этого. 
Программа локализации в Netflix базируется на трех принципах: безупречная лингвистика, гармоничная атмосфера в коллективе и передовые технологии.
Мы не боимся экспериментировать и пробовать новые процессы и инструменты, выступать против общепринятых в локализации норм — благодаря этому мы продвинулись так далеко! Работать в Netflix — значит быть первопроходцем.
В этой статье мы рассказываем о двух технологиях, которые приведут нас к МИРОВОМУ господству… Подробнее под катом.
Netflix Global String Repository
Netflix достиг успеха не потому, что мы делаем качественный контент, а потому, как мы подаем этот контент. Большая часть успеха — это интуитивно понятный, простой в использовании и локализованный пользовательский интерфейс (UI). Netflix доступен на разных платформах: веб-версия, Apple iOS, Google Android, Sony PlayStation, Microsoft Xbox, в телевизорах Sony, Panasonic и так далее. У каждой из этих платформ свои требования к интернализации, что представляет собой серьезный вызов для нашей команды.
Вот примеры, когда требуется локализация UI:
- добавление нового языка
- добавление новых функций
- изменения в уже существующих текстах и данных
Перевод текста для UI — не автоматизированный процесс; во время перевода менеджеры по локализации работают вместе с командой разработки для того, чтобы четко понимать, к чему относится та или иная строка, на какие языки ее нужно перевести и к какому сроку нужно предоставить локализованные файлы. Все становится намного сложнее, когда несколько фич разрабатываются параллельно и ведутся в разных ветках Git.
После того, как перевод выполнен, приложение собирают, тестируют и размещают на платформе. Для некоторых устройств требуется получить подтверждение от третьей стороны (например, от Apple). Все это провоцирует нежелательную задержку сроков. Особенно неприятными являются случаи экстренного внесения правок.
Но что, если сделать процесс локализации открытым для всех стейкхолдеров — и для команды разработки, и для локализаторов? Что, если нам не нужно будет больше пересобирать билды каждый раз, когда вносятся правки в текст?
Для решения этих проблем мы разработали глобальное хранилище строк UI, которое называется Global String Repository; здесь хранятся локализованные строки, которые подставляются в среду для выполнения кода. Мы интегрировали Global String Repository в техпроцесс локализации, таким образом, они взаимно дополняют друг друга.
Global String Repository разделяет пакеты локализации и пространство имен (заполнители). В пакете локализации хранятся все данные по строкам на всех языках. Заполнители — это плейс-холдеры для пакетов, над которыми работает команда. Во время разработки используются стандартные заполнители. Рабочий процесс выглядит так:
- Разработчик вносит изменения в английскую версию строки в пакете (в пространстве имен–заполнителей)
- Автоматически запускается процесс перевода
- Лингвисты завершают перевод
- Переводчики делают комплекты в заполнителях доступными
Когда происходит интеграция с Global String Repository, есть два типа поведения приложения:
- Во время исполнения: позволяет быстро вносить изменения в UI
- Во время сборки: использование Global String Repository отдельно для локализации, а пакеты с данными — со сборкой (билдом)
Global String Repository делает возможной интеграцию на этапе сборки предоставляя доступ к локализованным данным через REST API.
Мы открываем Global String Repository через API Netflix, таким образом к нему применяются те же самые масштабирование и требования, что и к метаданным других API. Для приложений, которые интегрируются во время исполнения, это критически важная часть. У нас 60 миллионов пользователей, которые запускают Netflix на разных устройствах, поэтому Global String Repository является приоритетной задачей.
Как и у Netflix, у Global String Repository микросервисная архитектура. Микросервис — это веб-приложение на Java (выполненное в Apache Cassandra и ElasticSearch), которое размещено в трех регионах AWS. Мы собираем статистические данные для каждого запроса к API.
Интерфейс Global String Repository разработан на Node.js, Bootstrap и Backbone и размещен в AWS.
На стороне пользователя Global String Repository использует REST API для получения данных и предлагает клиент Java со встроенным кэшированием.
Несмотря на то, что мы проделали большой путь и активно развиваем Global String Repository, нам есть к чему стремиться. Вот над чем мы работаем сейчас:
- Разрабатываем поддержку строк с числовыми переменными и строки с идентификаторами гендеров
- Развиваем устойчивость наших технических решений к сбоям
- Улучшаем процессы масштабирования
- Поддерживаем экспорт в разные форматы (Android XML, Microsoft .Resx и т.д.)
Global String Repository не имеет привязки к бизнес-домену Netflix, поэтому мы планируем выпустить его как программное обеспечение с открытым исходным кодом.
Hydra
Netflix — глобальный сервис, который поддерживает множество локалей в мириадах различных комбинаций на разных устройствах/UI; ручное тестирование в таком случае не подходит. Раньше команда локализаторов и разработчиков UI тестировала все вручную на разных устройствах — от консолей до iOS и Android; так мы проверяли все строки на соответствие контексту и UI (например, нет ли «обрезания» текста).
Но философия Netflix такова — мы стремимся к совершенству. Такой подход позволяет нам переосмысливать то, что мы делаем. Так родилась Hydra.
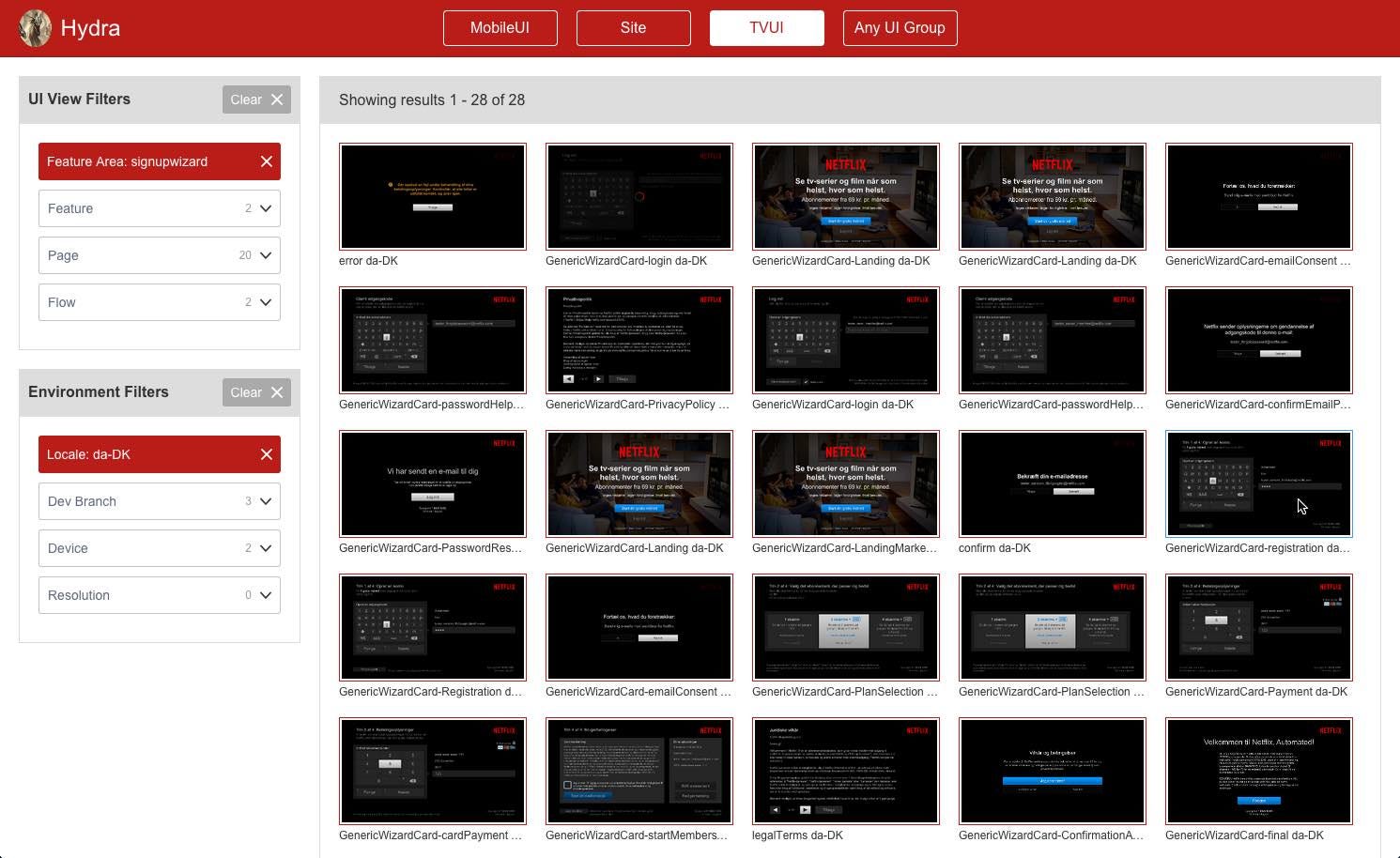
Задача Hydra — создание каталога всех возможных вариантов уникального экрана, который будет показывать именно тот экран, который требуется (поиск осуществляется по фильтрам, например, можно выбрать устройство и локали). Например, будучи специалистом по немецкой локализации, вы можете настроить фильтрацию таким образом, что увидите весь путь, который проходят незарегистрированные пользователи на PS3, веб-сайте и Android. Эти же экраны можно посмотреть в том темпе, в котором пользователь будет открывать их на своем устройстве.
Работа с экранами в Hydra
Инструмент Hydra не работает с экранами напрямую; он служит для их каталогизации и отображения. Чтобы взять отображение экрана из каталога Hydra, мы используем нашу модель автоматизации UI. С помощью Jenkins CI тесты, управляемые данными, работают параллельно во всех поддерживаемых локалях: так создаются скриншоты, которые публикуются в Hydra с соответствующими метаданными (имя страницы, область функций, платформа UI и один критический фрагмент метаданных, — уникальное экранное определение).
Уникальное экранное определение нужно для того, чтобы составить полный каталог экранов без ложных совпадений. Это позволяет сравнить большее количество экранов в долгосрочной перспективе, так как изображение каждого экрана сравнивается с самим собой. Определение уникального экрана отличается от UI к UI; для браузера это сочетание имени страницы, браузера, разрешения, локальной среды и среды разработки.
Технология
Hydra — это полностековое веб-приложение, размещенное в AWS. Back-end на Java выполняет две основных функции: обрабатывает входящие скриншоты и предоставляет данные для бэк-энда через REST API.
Когда автоматизация UI отправляет экран в Hydra, сам файл изображения записывается на S3, что обеспечивает его бесконечное хранение (плюс-минус), а метаданные гораздо меньшего размера записываются в базу данных RDS, чтобы впоследствии запрашивать их через REST API. Конечные точки REST (REST endpoints) обеспечивают отображение параметров строки запроса на запросы MySQL.
Например:
REST/v1/lists/distinctList?item=feature&selectors=uigroup,TVUI;area,signupwizard;locale,da-DK
В этом запросе содержатся параметры для выбора необходимых данных из Базы:
select distinct feature where uigroup = ‘TVUI’ AND area = ‘signupwizard’ AND locale = ‘da-DK’
Фронт-энд JavaScript, который использует knockout.js, позволяет пользователям выбирать фильтры и просматривать экраны, соответствующие этим фильтрам. Содержимое фильтров, а также экраны, которые соответствуют выбранным фильтрам, обеспечиваются вызовами конечных точек REST, упомянутых выше.
Масштабирование приложения
После установки Hydra и запуска автоматизации добавить новые локали так же легко, как добавить одну строку в существующий файл свойств, который отправляется в Data Provider фреймворка testNG. Экраны с новой локалью будут отображаться со следующими работающими сборками Jenkins.
Что дальше?
Нам нужно внедрить функцию, которая будет оповещать о том, что экран изменился. На данный момент, если строка меняется, нет ничего, что автоматически бы оповещало об этом. Hydra может превратиться в более или менее рабочую очередь, и тогда эксперты по локализации смогут войти в систему и увидеть только конкретный набор экранов, которые изменились.
Еще одна фича — иметь возможность сопоставлять отдельные строки ключей с тем, какие экраны нужно отображать. Это позволит переводчику изменить строку, а затем выполнить поиск по ключу и увидеть экраны, на которые повлияло это изменение; так переводчик увидит, как эта строка изменяется в контексте заранее.
Мы не боимся решать сложные задачи. Netflix станет глобальным сервисом, и наша команда по локализации будет расширяться. Подобные вызовы позволяют нам привлечь самых талантливых людей, и мы создаем команду, способную сделать то, что считается невозможным.
