[Из песочницы] Как устроен гибридный игровой ИИ и в чём его преимущества
В продолжение некогда поднятой в нашем блоге темы игрового искусственного интеллекта поговорим о том, насколько применимо к нему машинное обучение и в каком виде. Своим опытом и выбранными на его основе решениями поделился эксперт по вопросам ИИ в Apex Game Tools Якоб Расмуссен.

В последние годы ведётся много разговоров о том, что машинное обучение кардинально изменит игровую индустрию, ведь эта технология уже стала прорывной во многих других цифровых приложениях. Но не стоит забывать, что игры устроены намного сложнее, чем симулятор вождения автомобиля, программа управления дроном или алгоритмы распознавания лиц на изображении.
Пока в игровой индустрии по-прежнему принято использовать традиционные методы ИИ, такие как метод конечных автоматов, деревья поведения и — в последнее время всё чаще — Utility-based AI (системы, основанные на полезности). Такие ИИ также называют design-based (искусственным дизайн-интеллектом) или экспертными системами. Но становится всё более очевидным — и игрокам в первую очередь, — что эти системы всё менее подходят для создания действительно продвинутых противников, которые могли бы имитировать поведение игроков. В особенности это касается креативных решений. Это можно объяснить тем, что разработчики искусственного интеллекта не в состоянии учесть все возможные тактики и стратегии поведения и удачно реализовать их в традиционных системах ИИ. Для игроков это часто оборачивается тем, что становится скучно и предсказуемо играть с противником, чья линия поведения легко запоминается.
К такому результату приводит множество причин, но одна из главных — неспособность ИИ к обучению. Поэтому при создании искусственного интеллекта противника само собой приходит на ум решение о переходе к машинному обучению, которое отлично зарекомендовало себя во многих других приложениях. Но есть несколько нюансов, которые стоит учитывать. Так, игровой ИИ должен уметь адаптироваться к любой ситуации и использовать преимущества, которые она ему даёт, а также приспосабливаться к различным игровым стилям соперников — живых игроков и других ИИ.
Как обстоят дела сейчас
Британская компания DeepMind, занимающаяся вопросами разработки искусственного интеллекта, недавно показала, каким образом ИИ могут самостоятельно учиться играть в игры, усваивать их правила и находить способы пройти игру или победить в ней — правда, пока только на примере простых игр, таких как ранние игры Atari — например, шахматы и японская логическая игра го. Результаты, полученные для них, показывают, что искусственный интеллект в состоянии сформировать для себя адекватную оценку происходящего на поле. Если же говорить об адаптации ИИ к различным стилям игры оппонента, то результаты пока не столь впечатляющие.
В наше время нейронные сети уже научились распознавать изображения и водить автомобили. Но эти функции можно реализовать и при помощи сравнительно простых архитектур, даже если в результате они окажутся довольно глубокими и объёмными. Так, ИИ для распознавания изображений на Facebook имеет глубину порядка 100 слоёв, из-за чего напоминает биологический мозг — по количеству и сложности взаимосвязей между нейронами, образующими одну большую сеть.
Игровой ИИ
Что касается применения машинного обучения в игровой индустрии, здесь существует ряд ограничений, из-за которых не всегда получается использовать этот вид архитектуры. К ним относятся системные требования, в частности, относящиеся к ЦП, которые определяют способность компьютера к обработке сложной игровой структуры и пригодность его для игрового сторителлинга и геймплея.
Таким образом выходит, что во многих играх для реализации сложной системы искусственого интеллекта нет возможности организовать необходимое аппаратное обеспечение и тем более кластер серверов, который существует, например, для сетей распознавания изображений в Facebook. Иногда и вовсе должны одновременно работать несколько ИИ — и не только на компьютерах, но и на мобильных устройствах, и на других менее производительных платформах. Всё это накладывает ограничения на размер и сложность архитектуры машинного обучения, ведь все вычисления ещё и должны выполняться с длительностью кадра порядка 1 или 2 миллисекунды. Конечно, можно использовать различные технологии оптимизации и распределения нагрузки между кадрами, но всё равно не удаётся избавиться от этих ограничений совсем.
Серьёзные проблемы для ИИ может вызвать сложность игры. Ведь в таких играх, как, например, StarCraft II, механика игры в разы сложнее, чем в играх Atari. Поэтому не стоит ожидать, что при заданной частоте кадра и с известными системными требованиями машинное обучение обязательно справится с изучением всего состояния игры целиком и сможет с ним взаимодействовать. Как игрок часто руководствуется интуицией на ранних этапах игры, так и ИИ должен научиться первичной обработке состояния игры для упрощения дальнейшего её прохождения. Например, в одном из последних API для Starcraft II на картах отображается только та информация, которую разработчики сочли важной: в одном случае ИИ пользовался уменьшенным видом всей территории карты, во втором — подобно игроку, он мог двигать камеру, и тогда его восприятие ограничивалось информацией на экране.
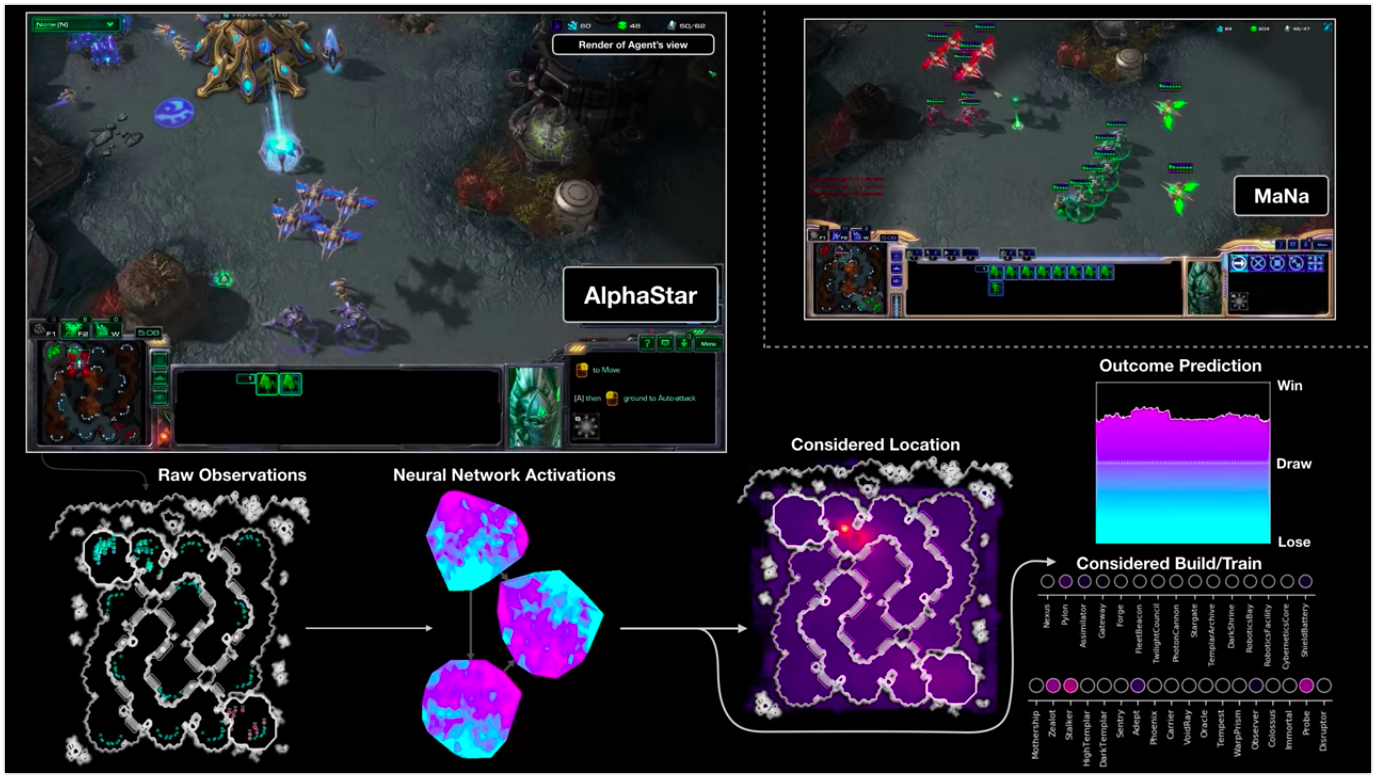
Визуализация игры ИИ AlphaStar против игрока в StarSraft II: на скриншоте изображены «сырые» исходные наблюдения, активность нейронной сети, некоторые из её возможных действий и координат, а также предполагаемый исход матча
Это особенно актуальный аспект в случае игр. Зачастую к игровому искусственному интеллекту неприменимы общепринятые методы решения проблем машинного обучения. Например, обычно он не обязан выигрывать или делать всё от него зависящее для победы, как было в случае с играми Atari. Чаще роль ИИ состоит в том, чтобы сделать прохождение игры более захватывающим. Ему может быть необходимо играть роль и вести себя так, как предполагает характер персонажа, за которого он ответственен. Таким образом, игровые ИИ больше завязаны на геймдизайне и сторителлинге и должны обладать необходимыми инструментами, чтобы управлять своим поведением для достижения поставленной цели. Машинное обучение в чистом виде не всегда для этого подходит —, а значит, нужно искать что-то другое.
Практические проблемы машинного обучения
Эти проблемы всплыли при разработке искусственного интеллекта на основе машинного обучения для Unleash, где ИИ должны вести себя как обычные игроки — то есть, быть такими же гибкими и находчивыми.
Как и Starcraft II, Unleashed устроена намного сложнее, чем шахматы и го для Atari. Игровой процесс в ней интуитивно понятен и легко осваивается, но для того, чтобы по-настоящему в ней преуспеть, необходимы определённые навыки управления метой. Игрок должен выстраивать лабиринты, натравливать на врагов монстров и продумывать свою стратегию в экономике, нападении и защите сооружений на протяжении всей игры. Для этого ему необходимо блефовать и просчитывать чужие ходы наперёд, а также управлять психологической метой — именно она делает из покера нечто большее, чем просто статистическую игру.

Скриншот из Unleashed
В поисках наиболее подходящей для этих целей архитектуры сначала в игру в практически неизменном виде внедрили такие технологии, как нейроэволюция и глубокое обучение, и проверили, как они покажут себя в сыром виде в качестве ИИ противника.
Это было ужасно.
Быстро стало очевидным, что в Unleashed нужно решить много глобальных проблем, под которые сложно приспособить машинное обучение.
Одна из них — построение эффективного лабиринта. Как и во многих играх, целью которых является защита башни, здесь игрокам необходимо выстроить вокруг неё лабиринт, через который будут прорываться монстры. Их, в свою очередь, необходимо устранить при помощи оружия, расставленного по лабиринту. В идеале лабиринт должен быть как можно более длинным, чтобы успеть нанести монстрам достаточное количество урона и не дать им достигнуть башни. Для некоторых видов оружия монстры более уязвимы, чем для других, поэтому для большей эффективности их стоит разместить в лабиринте раньше, чем все остальные. Особенность Unleash заключается в том, что не существует идеального лабиринта: в игре столько видов монстров, что так или иначе кто-то из них беспрепятственно пройдёт через какой-либо участок лабиринта. Любой лабиринт необходимо адаптировать под новых монстров, запускаемых другими игроками. Таким образом, было необходимо не просто научить искусственный интеллект строить лабиринты — нужно было научить его создавать эффективные лабиринты для различных сценариев, с какими только можно столкнуться как в ранней, так и в поздней версии игры.
Также ИИ должен был научиться просчитывать, какие монстры появятся в лабиринте. Это своего рода обратная проблема по отношению к построению лабиринта. Как и во многих других играх, в Unleash недостаточно просто нарастить армию и отправить её в стан врага: необходимо также шпионить за вражеской обороной и так структурировать войско, чтобы максимально эффективно ударить по болевым точкам противника. Армия монстров должна так взаимодействовать друг с другом, чтобы наиболее успешно прорваться через лабиринт. Иногда необходимо также выпустить монстров в определённом порядке в зависимости от их функций и роли. Это тоже увеличивает количество различных комбинаций.
Наконец, поскольку игрок должен как создавать лабиринты, так и собирать армию монстров, ИИ тоже нужно научиться находить баланс в нападении и обороне. Также стоит учесть, что чем больше игрок наращивает армию монстров и чем больше строит лабиринт, тем больше ему необходимо ресурсов для этого. Поэтому правильная стратегия нападения крайне важна как для экономики в процессе игры, так и для победы в ней. И для обеспечения состязательности ИИ должен уметь располагать ресурсами так, чтобы создать мощную армию монстров, не ставя при этом под угрозу силу лабиринта. Вкладываться по максимуму в монстров может быть экономически выгодно, но это повышает риск захвата лабиринта монстрами противника. Если же сделать ставку на укрепление защиты лабиринта, это может подкосить вашу экономику. Ни один из этих сценариев не приведёт к победе. Таким образом, проблема оптимизации в Unleashed оказывается масштабнее, чем в случае шахмат или Starcraft, и включает в себя необходимость жертвовать чем-либо и просчитывать свою выгоду на несколько шагов вперёд.
По мере обучения искусственного интеллекта всплывает множество ранее не учтённых проблем. Так, поначалу ИИ часто достигал определённого уровня развития, при котором он начинал понимать некоторые аспекты игры — например, какое оружие в лабиринте эффективно против конкретных типов монстров или какие монстры лучше всего проходят определённые участки лабиринта. Но обучение было медленным и приводило к выработке однообразных стратегий.
Необходимость параллельных подходов
В то время как обучение ИИ, основанных на машинном обучении, развивалось медленно и не особенно успешно, для других этапов тестирования и разработки стал необходим лучший ИИ и более надёжные сопернические ИИ. Для их реализации был использована архитектура Utility, с помощью которой можно создавать специальные ИИ для тестирования и проверки качества игры, внутриигровых тестов и балансировки оружия и монстров, и создания конкретных лабиринтов и монстров. Однако в ходе разработки Unleash создатели и сами оттачивали навыки в её прохождении, а затем решили использовать полученные знания для создания более сложного Utility ИИ. Так стало понятно, что многие проблемы, возникающие в системах искусственного интеллекта, основанных на машинном обучении, можно легко решить с помощью Utility систем, использующих заложенные в них знания, и наоборот.
Например, более эффективные лабиринты лучше строить при помощи Utility ИИ, основывающихся на базах знаний, составленных по результатам внутренних тестов. Можно легко описать и запрограммировать алгоритм построения лабиринта и расположения в нём оружия таким образом, как было бы проще оборонять башню от конкретных монстров живому игроку. А вот создание армии монстров на основе знаний о базе противника явилось сложной задачей для таких ИИ, поскольку количество различных условий и комбинаций, которые необходимо учитывать, поражало воображение. С таким видом архитектуры ИИ поиск подходящих наборов монстров занял бы бесконечно долгое время. Тогда при условии заданных ограничений глубокое обучение было бы идеальным решением для данной задачи.
Создание гибридных ИИ
Итак, было решено объединить два подхода и таким образом создать гибридную систему искусственного интеллекта на основе машинного обучения и Utility. Идея состояла в том, что там, где было необходимо обработать огромное количество комбинаций и состояний игры, или где требовалось обучить её чему-либо, использовалось машинное обучение. Для других задач, где лучше полагаться на личный опыт разработчиков, были задействованы системы Utility. Преимущество этого подхода заключается ещё и в том, что при необходимости можно лучше контролировать поведение ИИ, чтобы обеспечить более точное его следование заданной цели. Например, можно использовать Utility ИИ для обеспечения баланса между нападением и обороной и созданием таким образом различных уровней агрессии, а можно создать различные конфигурации лабиринтов для различных ИИ, чтобы сформировать для них индивидуальные стили игры. Также можно задать нейросетям определённые системы ценностей для формирования различных предпочтений при наборе воздушных или наземных монстров и таким образом тоже добавить отдельным ИИ индивидуальности. Есть ещё много других опций для реализации проектных решений, и все они подчёркивают сильные стороны того или иного вида архитектуры ИИ.
Гибридный подход также явился ответом на другой вопрос, вставший перед командой разработчиков в процессе разработки искусственного интеллекта для Unleash: стоит ли применять единую глобальную глубокую нейросеть на основе машинного обучения, чтобы учесть все входные и выходные данные, или лучше спроектировать ИИ с иерархической структурой?
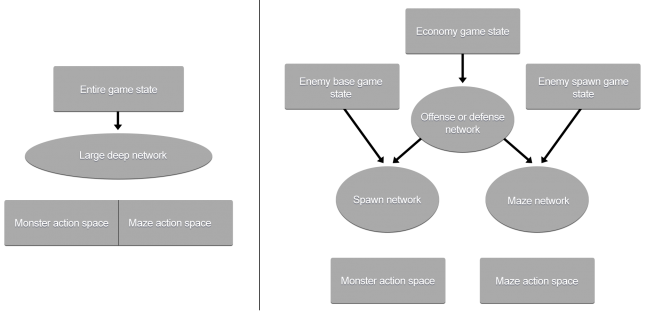
Две архитектуры, использованные в Unleash: слева — большая глубокая нейросеть с собственной единой архитектурой, справа — иерархическая система, в которой у каждой сети есть своя задача
И всё же хотелось бы создать общий подход к системе искусственного интеллекта, в архитектуру которой разработчики не закладывали бы собственный опыт. Однако чем больше осуществлялось входов в игру, тем больше разрасталась нейросеть. При этом нельзя было разделить обучение ИИ и обучать их чему-то одному: либо защите, либо нападению. И возникали опасения, что более общий подход привел бы к существенному увеличению числа вычислений.
Отсюда возникла идея создания иерархической архитектуры, в которой каждую конкретную задачу выполняла бы специализированная нейросеть. Согласно этой идее, сначала искусственному интеллекту необходимо принять решение о распределении ресурсов на нападение (увеличение армии монстров) и защиту (строительство лабиринта). Как только он это делает, он переходит на следующий слой в соответствии со своим выбором и получает доступ к необходимой части состояния игры, после чего принимает подробные решения о том, каких выбрать монстров и какое оружие установить в лабиринте.
Заключение и следующие шаги
При гибридном подходе Utility ИИ со включенными в него сетями на основе машинного обучения напоминает иерархическую архитектуру. А она, в свою очередь, похожа на биологический мозг, в котором разные нервные центры отвечают каждый за свою задачу.
Сейчас ИИ противника в Unleash очень трудно победить: они в состоянии приспособиться к любой ситуации в игре, —, но при этом разработчики могут менять их настройки по своему усмотрению. По мнению автора статьи, со временем гибридный подход должен получить большее распространение и появиться во многих других играх. Возможно, когда-нибудь удастся внедрить в игровой процесс искусственный интеллект на основе машинного обучения в чистом виде. Но, очевидно, для этого ещё понадобится время. Пока же цель состоит в нахождении такой архитектуры, которая сама подстроится под стоящие перед ней задачи и найдёт оптимальные способы их решения.
