[Из песочницы] Как мы парсили декларации о доходах при помощи открытых данных
Уже второй год я занимаюсь государственными открытыми данными РФ и работой с госорганами и пора бы начинать рассказывать интересные истории о том, как появляются данные. Однако сегодня речь пойдет о более привычной для разработчика области — парсинге данных для проекта «Декларатор» и о том, какую неожиданную пользу могут при этом принести открытые данные.
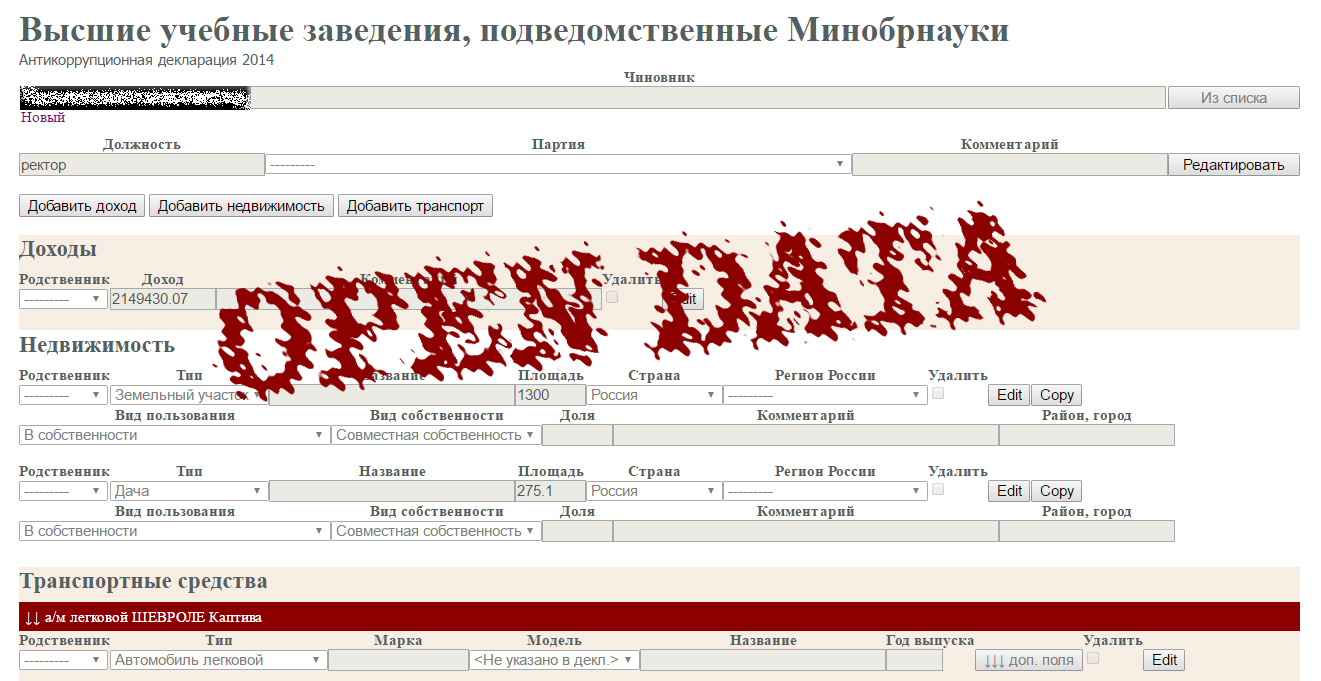
«Декларатор» — это постоянно пополняемая база деклараций о доходах и имуществе публичных должностных лиц: депутатов, чиновников, судей, представителей региональной и муниципальной власти, иных органов, госкорпораций и госкомпанией. Проект работает как информационно-справочная база для СМИ, активистов, занимающихся общественным контролем, и исследователей.
В России сведения о доходах должны публиковать более миллиона человек.
Интересный факт: существуют единые правила для госсайтов по размещению деклараций о доходах (в частности, они всегда находятся в разделе «Противодействие коррупции») и отвечает за всю эту тему Министерство труда и социальной защиты РФ. Массовое размещение деклараций происходит в мае. Далее у Минтруда есть всего месяц на то, чтобы провести мониторинг по всем без исключения сайтам, обязанным размещать информацию. Мониторинг проводится вручную.
Есть несколько проблем, связанных с публикацией деклараций:
- каждое ведомство делает это на собственном сайте;
- не существует единого стандарта для публикации деклараций;
- информацию могут удалить вскоре после публикации;
- являясь общедоступными по закону, декларации до сих пор не публикуются в машиночитаемом виде.
Интересующиеся могут прочитать подробности в приказе Минтруда 530н, а если кратко: раздел «Противодействие коррупции» должен находиться в одном клике от главной страницы и содержать несколько обязательных подразделов с жестко заданными названиями, среди которых нас интересует один — «Сведения о доходах, расходах, об имуществе и обязательствах имущественного характера». Именно в нем, без ограничения доступа, в табличной форме, в том числе в форматах .doc, .docx, .excel, .rtf (п.15 Требований), размещаются декларации о доходах госчиновников.
При этом, как прямо указано в документе, «должна быть обеспечена возможность поиска по тексту файла и копирования фрагментов текста» — вот это и делает возможным создание парсеров.
О декларациях
Декларация о доходах каждого чиновника содержит информацию об объектах недвижимости, находящихся в собственности, в пользовании, сведения о транспортных средствах, сведения о доходах и источниках доходов. В декларации перечислены не только чиновники, но и члены их семей. Если повезет, сводный файл создается по предложенному Минтрудом шаблону формы сведений о доходах, что сильно облегчает задачи написания универсального парсера.
Первым объектом интереса стало Министерство образования и науки. Пробный парсер, для деклараций о доходах федеральных государственных служащих за 2014 год на 306 человек, был написан быстро и достаточно безболезненно. После этого мы решили перейти к тому, что обычно вызывает наибольшее количество запросов исследователей — сведениям о доходах ректоров вузов. И тут-то начались сложности с декларациями за 2014 год подведомственных учреждений Минобрнауки.
Быстрый анализ показал, что только ректоров в этом файле 272 человека и их явно надо как-то группировать. Группировать решили по регионам. Однако в декларации указывается лишь должность и название учреждения.
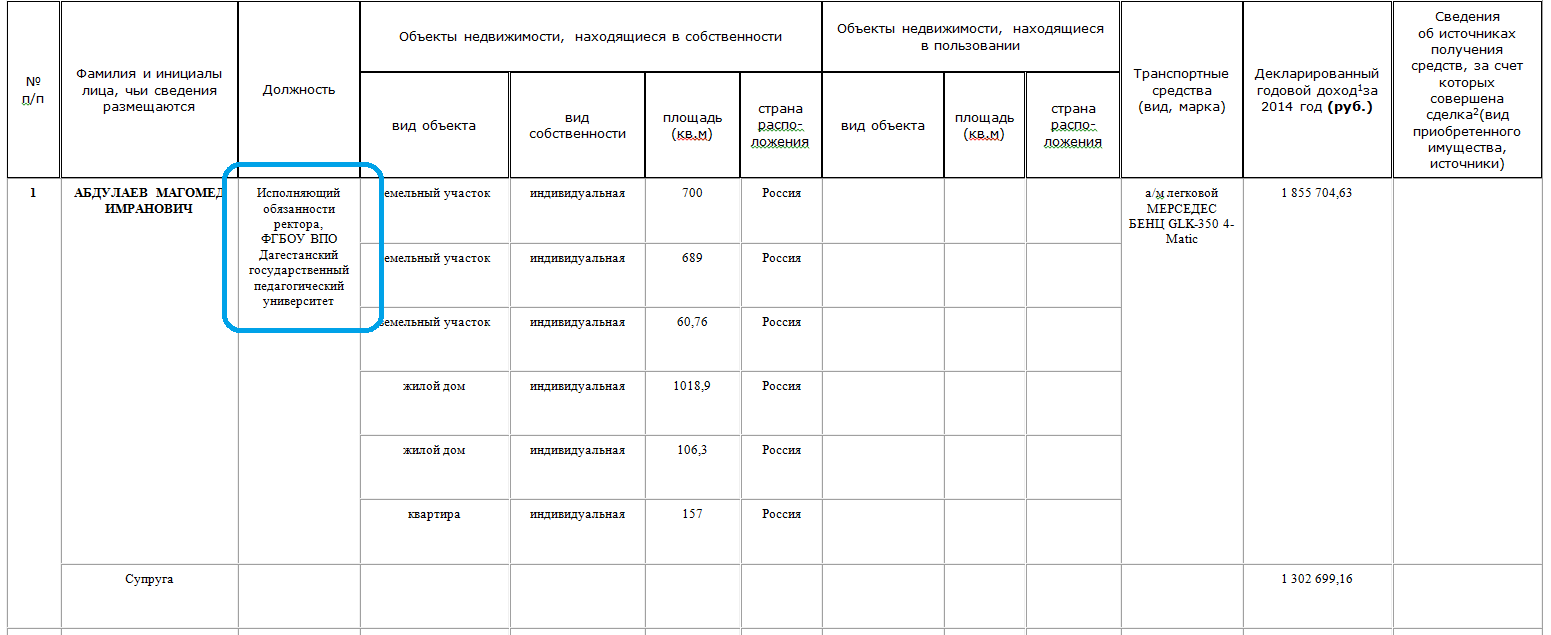
Почти три сотни уникальных высших учебных заведений разыскивать руками совсем не хотелось. Вот здесь и пригодились открытые данные Рособрнадзора под названием «Сводный реестр лицензий на осуществление образовательной деятельности». Реестр очень информативный, но имеет достаточно сложный формат и заслуживает отдельной статьи. К чести Рособрнадзора, он представлен в формате xml вместо традиционного для госорганов csv, и не содержит ошибок в структуре, поэтому его удалось использовать в качестве базы данных без какой-либо предварительной обработки. (ссылка по состоянию на 16.05.2016 временно не работает, поэтому реестр пока можно взять здесь).
О задаче
Итак, исходная задача: вытащить из декларации о доходах данные по ректорам, определить для них регион и сгенерировать файлы xml специального формата для плагина Заполнятор, через который происходит загрузка данных на сайт Декларатора.
Плагин имитирует действия пользователя на сайте, автоматически заполняя формы. И как выяснилось в процессе тестирования, у него есть ограничения на количество записей, которые он способен обработать за один раз…
На входе имеем файл формата .doc, содержащий в себе данные о доходах 1561 чиновников. Так как нам нужны данные не только по чиновникам, но и по членам их семей, по факту мы должны обработать информацию по 3347 людям.
Реализация
Детали реализации парсера деклараций смотрите на гитхабе, скажу только, что понадобилось много предварительной обработки для удаления лишних и зачастую неожиданных символов: @»[\r\n\a\b\u000b]», а также шаманство с транспортными средствами, до сих пор не законченное из-за таких вот случаев (это одна ячейка таблицы в MS Word):

Реестр
Переходим к основной задаче — матчингу названий вузов деклараций и реестра Рособрнадзора. Ее решение с подбором регулярных выражений в результате заняло значительно больше времени, чем написание самого парсера. Хотя кода там получилось намного меньше.
Записи для каждой лицензии в реестре Рособрнадзора имеют (в очень сокращенном виде) такую структуру:
г. Москва
77
федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Московский государственный университет дизайна и технологии»
ФГБОУ ВПО «МГУДТ»
58302c2c-16f2-0772-3cf1-ebacbde89ecd
федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Московский государственный университет дизайна и технологии»
ФГБОУ ВПО «МГУДТ»
г. Москва
77
…
EduOrgFullName — это сведения о самой лицензии, для головной организации. В тегах ActualEducationOrganization содержится информация обо всех учреждениях, подчиненных головной организации (а их может быть очень много — институты в составе университета, филиалы и многое другое). Поэтому решение выглядело просто и очевидно: найти соответствия названий из деклараций для тега FullName или ShortName реестра и выяснить, какой регион им соответствует.
Особенности реестра: в качестве кавычек используются исключительно «елки», наименование типа учреждения («федеральное государственное…») в теге FullName записывается полностью в нижнем регистре.
Препроцессинг
Однако, по-видимому, формат написания названий вузов в декларациях был ограничен лишь фантазией тех, кто подавал декларации. В итоге имеем разнообразие регистров и написаний, от Федеральное государственное бюджетное учреждение высшего образования «Московский государственный университет технологий и управления имени К.Г. Разумовского (ПКУ)» и ФГАОУ ВПО «Национальный исследовательский ядерный университет «МИФИ» до ФГАОУ «ВПО БФУ ИМ.И. КАНТА» (причем в другом месте декларации он был записан уже как ФГАОУ ВПО «Балтийский федеральный университет имени Иммануила Канта»). Свой вуз я долго не могла найти парсером. Неудивительно для ФГБОУ ВПО «МГУДТ»…
Большое разнообразие наблюдалось в написании кавычек. В основном в декларациях записаны прямые «английские» кавычки вместо привычных русских елочек, самый убийственный вариант для парсинга был «Санкт-Петербургский государственный электротехнический университет «ЛЭТИ» им. В.И. Ульянова (Ленина)» (похоже, его не осилил и парсер хабра). Дважды встретились экзотические »« (Волгоград, Москва), а в Ростове додумались до варианта ФГБОУ ВПО <<Ростовский государственный экономический университет (РИНХ)>> (между прочим, 10 вхождений в декларации).
Так вот, оказалось, что XPath в xml ищет очень быстро, умеет находить частичные соответствия, но увы — только в полном соответствии с регистром букв. Если переопределить функцию поиска, проблема исчезает, и с ней заодно исчезает и скорость.
Первым делом пришлось убрать повторяющуюся часть — тип учреждения — и оставить только фактическое название. И здесь ждало открытие: помимо ФГБОУ (а также ФГАОУ, ФГБУ) ВПО, ДПО ли ВО оказалось, что есть еще учреждения «инклюзивного высшего образования», то есть ФГБОУИ ВО… А стандартная формулировка «федеральное государственное бюджетное образовательное учреждение высшего профессионального образования» может заменяться на «федеральное государственное бюджетное учреждение высшего профессионального образования» — сможете найти отличие?
В итоге получилась вот такая конструкция на регулярных выражениях:
orgname = Regex.Replace(orgname, @"(.*)(ФГ(Б|А)ОУ\s)((В|Д)П?О)?", "");
orgname = Regex.Replace(orgname,
@"(федеральн[а-яё]*\s|Федеральн[а-яё]*\s)?(государственн[а-яё]*\s|Государственн[а-яё]*\s)?(.*)?(учрежден[а-яё]*\s|Учрежден[а-яё]*\s)(инклюзивн[а-яё]*\s|инклюзивн[а-яё]*\s)?(дополнит[а-яё]*\s|Дополнит[а-яё]*\s|высше[а-яё]*\s|Высше[а-яё]*\s)(профессиональн[а-яё]*\s|Профессиональн[а-яё]*\s)?(образован[а-яё]*|Образован[а-яё]*)", "");
orgname = Regex.Replace(orgname, @"(федеральн[а-яё]*\s|Федеральн[а-яё]*\s)?(государственн[а-яё]*\s|Государственн[а-яё]*\s)?(.*)?(учрежден[а-яё]*\s|Учрежден[а-яё]*\s)", "");
Причем порядок команд здесь имеет большое значение. Ну и борьба с кавычками:
if (orgname.Contains("<<"))
orgname = Regex.Replace(orgname, @"(.*<<)(.+)(>>.*)", "$2");
if (orgname.Contains('«'))
orgname = Regex.Replace(orgname, @"(.*«)(.+)(».*)", "$2");
if (orgname.Contains('"'))
orgname = Regex.Replace(orgname, @"(.*")(.+)(”.*)", "$2");
Большая проблема оказалась с вузами, которые были названы в чью-то честь, так как:
- могли встретиться варианты «им.» и «имени» и в различных регистрах;
- само имя могло быть написано любым вариантом в любом регистре и с любым количеством пробелов (или без них), например: ИМ.И. КАНТА, имени Ивана Федорова, им. В.И. Ульянова (Ленина), им.Н.И. Лобачевского.
Из-за непредсказуемости написания было проще убрать «имени кого» целиком:
orgname = Regex.Replace(orgname, "(имени.*)", "");
orgname = Regex.Replace(orgname, @"(им\..*)", "");
К счастью, название вуза при этом не теряло в уникальности.
И все равно оставались «упрямые» случаи, которые не хотели находиться никаким образом. Это были вузы, названия которых состояли из аббревиатур: ЛЭТИ, НИНХ, СТАНКИН и снова мой любимый МГУДТ. Решение:
Match tempmatch = Regex.Match(orgname, @"[А-ЯЁ]{2,}");
tempname = orgname.Substring(tempmatch.Index, tempmatch.Length);
Как ни странно, даже после этого в неопознанные попало несколько десятков вузов. Анализ показал, что часть их них были написаны с опечатками, в основном из-за пропуска или перестановки букв. Лидером стала опечатка «Москвоский». А в Кузбассе, судя по капсу, очень любят свой вуз, но вот грамотность у них подкачала: «Федеральное государственное бюджетное образовательное учереждение высшего профессионального образования КУЗБАССКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ ИМЕНИ Т.Ф. ГОРБАЧЕВА».
Много проблем было с пробелами:
- в реестре Рособрнадзора в некоторых названия попадаются сдвоенные пробелы;
- в названиях некоторых вузов есть тире. И эти тире абсолютно по-разному могли сочетаться с пробелами. Например, в декларации прописан «Волгодонский инженерно — технический институт — филиал федерального государственного автономного образовательного учреждения высшего профессионального образования «Национальный исследовательский ядерный университет «МИФИ», в реестре то же самое название выглядит как «Волгодонский инженерно-технический институт…». При этом был и такой случай: «Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Государственный университет — учебно-научно-производственный комплекс».
Но количество неопознанных вузов почему-то не спешило сокращаться. И дело было в совсем неожиданной проблеме, которая в итоге привела к модификации алгоритма поиска. Оказалось, что лицензия на образовательную деятельность могла быть зарегистрирована на одно название учреждения, а официальное название вуза чуть-чуть, но отличалось. Например, были пары «академия — университет», «институт — университет».
В реестре это выглядело так:
федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Брянская государственная инженерно-технологическая академия»
ФГБОУ ВПО «БГИТА» )
и
федеральное государственное бюджетное образовательное учреждение высшего образования «Брянский государственный инженерно-технологический университет»
ФГБОУ ВО «Брянский государственный инженерно-технологический университет», ФГБОУ ВО «БГИТУ», БГИТУ
Причем в декларации могло быть указано любое из них. Несколько вузов по не известной пока причине вообще не имели тегов FullName и ShortName.
Отдельно про Крым: «федеральное государственное автономное образовательное учреждение высшего образования «Крымский федеральный университет имени В.И. Вернадского» вообще не имело в реестре указания на регион.
Окончательная на данный момент версия алгоритма парсинга выдает вот такие результаты.
Пример готового файла для Заполнятора (вузы для г. Москва).
Немного статистики
В декларации подведов Минобрнауки 1561 работников организаций, вместе с членами семей их 3347 человек, в файле 770 страниц, неожиданно 32 таблицы.
272 ректора, т.е. более 272 уникальных вузов, из них 8 вузов написаны с ошибками или опечатками.
4 вуза вообще не значатся в реестре Рособрнадзора. Это:
- Федеральное государственное бюджетное образовательное учреждение высшего образования «Арктический государственный институт культуры и искусств»;
- Федеральное государственное бюджетное образовательное учреждение дополнительного профессионального образования «Государственный институт новых форм обучения»;
- Федеральное государственное бюджетное образовательное учреждение дополнительного профессионального образования «Институт непрерывного образования взрослых»;
- Федеральное государственное бюджетное образовательное учреждение дополнительного профессионального образования «Новомосковский институт повышения квалификации руководящих работников и специалистов химической промышленности».
В заключение еще раз ссылка на проект. Парсер будет работать и на декларациях других госорганов, созданных по тому же шаблону.
Полезные ссылки
НПА:
Указ Президента Российской Федерации от 8 июля 2013 г. № 613 «Вопросы противодействия коррупции», ст. 6 про обязанности Министерства труда и социальной защиты.
Указ Президента Российской Федерации от 8 июля 2013 г. № 613 «Вопросы противодействия коррупции», Порядок размещения сведений о доходах, расходах, об имуществе и обязательствах имущественного характера отдельных категорий лиц и членов их семей на официальных сайтах федеральных государственных органов, органов государственной власти субъектов Российской Федерации и организаций и предоставления этих сведений общероссийским средствам массовой информации для опубликования про обязанности Министерства труда и социальной защиты, п. 4 «Сведения о доходах, расходах, об имуществе и обязательствах имущественного характера … ежегодно обновляются в течение 14 рабочих дней со дня истечения срока, установленного для их подачи».
Указ Президента Российской Федерации от 8 июля 2013 г. № 613 «Вопросы противодействия коррупции», Статья 8. Обязанность представлять сведения о доходах, об имуществе и обязательствах имущественного характера.
Все НПА по антикоррупционному законодательству.
НПА Минтруда
Программирование:
Сервис проверки регулярных выражений
Хелп по регулярным выражениям в C#
Классы знаков регулярных выражений для C#, а также проект с простой реализацией безрегистрового поиска по xml: ссылка.
