[Из песочницы] Фармакокинетическое моделирование в Julia: практическое использование DiffEquations.jl и Optim.jl
Фармакокинетическая модель — это часто упрощенное математическое описание того, как изменяется концентрация (количество) исследуемого вещества во времени в биологической системе. Упрощенное потому, что организм — сложный механизм в котором абсорбция, распределение, метаболизм и выведение веществ (ADME) может происходить различными путями в зависимости, как от самого вещества, так и от текущего состояния организма и не редко с не очевидными обратными связями. Поэтому отразить и описать все возможные факторы, действующие на кинетику вещества практически невозможно и в большинстве случаев не целесообразно. Тем не менее, возможно представление, в котором вещество распределено в ограниченных областях организма, которые будут далее называться камерами, а переход вещества из одной камеры в другую описывается определенным уравнением.
Фармакокинетическое моделирование можно рассматривать как частный случай нелинейного моделирования. Для этого широко используются коммерческие пакеты, таких как: Phoenix WinNonlin, NONMEM, Monolix и т.д., которые позволяют получить оценки параметров модели разной (произвольной) сложности. Существуют также пакеты доступные для среды вычислений R Project (nlme, nls, saemix) и Julia (CurveFit.jl, LsqFit.jl, NLreg.jl), которые можно использовать для определения параметров фармакокинетических моделей. Ограничения пакетов R Project и Julia связаны с тем, что исследователь должен задать нелинейную функцию в явном виде, что не всегда возможно. Кроме того, не все указанные пакеты обладают достаточным функционалом для оценки модели со смешанными эффектами (случайными и фиксированными эффектами).
Несколько особняком стоит Pumas.jl, т.к. несмотря на серьезный заявленный функционал пакет не получил широкого распространения (возможно пока), вероятно этому (широкому распространению) мешает невнятная лицензия использования. Цель данной работы: описание основных подходов к фармакокинетическому моделированию, построение фармакокинетической модели в виде системы дифференциальных уравнений, подбор параметров фармакокинетической модели.
Модели можно классифицировать по количеству камер, способу поступления и интервалу дозирования вещества, механизму (функции) элиминации:
- Количество камер:
- Однокамерные
- Двухкамерных
- Трехкамерные (и более)
- Способ поступления:
- Внутривенно болюсно
- Внутривенно инфузионно
- Внутрь (per os)
- Интервал дозирования:
- Однократно
- Многократно
- Механизм элиминации:
- Линейный
- Согласно уравнению Михаэлиса-Ментен
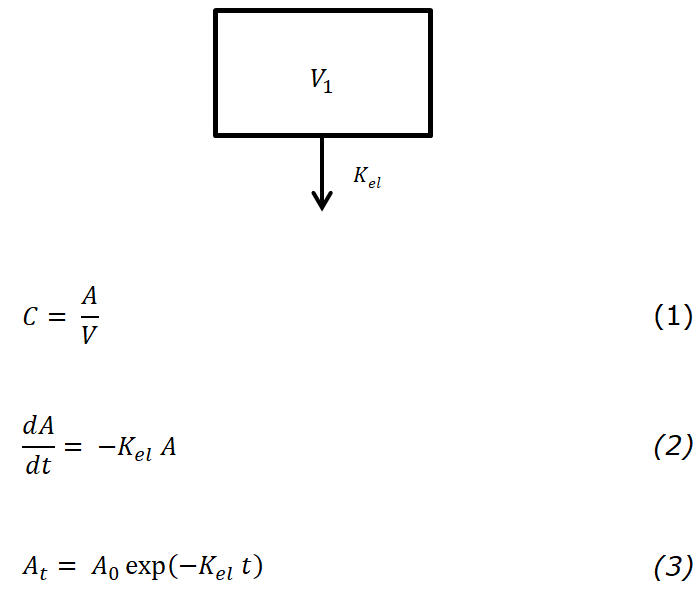
Простейшая однокамерная модель представляет собой одну камеру, в которой распределено вещество, в этом случае считается, что вещество быстро распределяется: относительно быстро переносится из кровотока в ткани и обратно, т.е. ограничивающее влияние периферических камер незначительно и не учитывается. Представим, что вещество уже попало и распределилось в организме, тогда изменение его концентрации во времени можно представить в виде следующего дифференциального уравнения 2 (однокамерная модель для болюсного внутривенного введения), при решении которого будет получена функция зависимости концентрации от времени 3. Где: A — количество вещества, K — константа, определяющая переход из одной камеры в другую (в частном случае Kel — константа элиминации), t — время, отношение концентрации С и количества вещества A описывается выражением 1, где V — объем распределения.
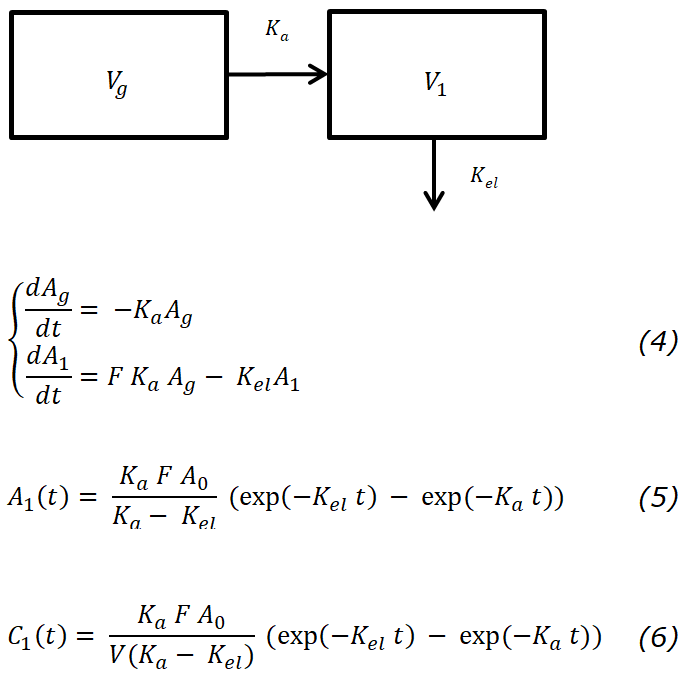
Более интересный случай — внесосудистое введение. В этом случае вещество сперва должно попасть в центральную камеру из камеры, которая отражает желудочно-кишечный тракт (Vg). Данную модель можно представить в виде системы дифференциальных уравнений 4. Решение относительно количества вещества в центральной камере представлено уравнением 5. Здесь появляется дополнительная константа F — биодоступность, которая отражает долю вещества, перешедшего в системный кровоток из ЖКТ. Используя выражение 1 можно вывести уравнение зависимости концентрации C от времени t — уравнение 6.
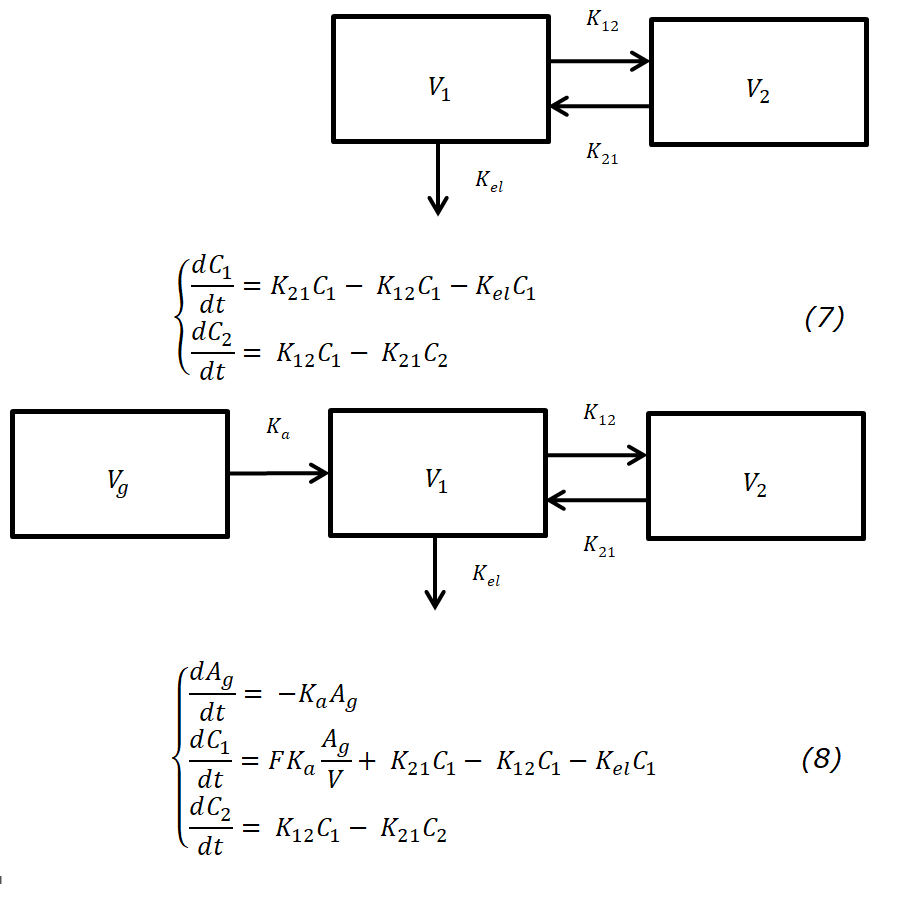
Еще более сложный (приближенный к реальности) вариант — двухкомпартментная модель. В этом случае кроме центральной камеры в модель включена периферическая камера — дополнительный объем, при этом перенос из центральной камеры в периферическую и обратно может происходить с разными скоростями (к примеру, липофильное вещество может из кровотока довольно быстро переходить в жировую ткань, а обратно значительно медленнее). Соответствующая система двух дифференциальных уравнений для болюсного внутривенного введения — выражение 7, для приема внутрь — выражение 8. Система уравнений 7 составлена относительно концентрации в камерах, что также справедливо. Так как измерить количество вещества в камере очень затруднительно, то построение модели относительно концентрации позволяет связать модель и фактические измерения. В выражении 8 первое уравнение приведено для количества вещества A, а последующие для концентрации с использованием константы F (биодоступности) и объема распределения V, что не должно вызывать смущения.
Решение этого уравнения возможно, но громоздко. Поэтому решать его будем при помощи DiffEquations.jl в Julia. Для чего определим функцию pkf! как отражение вышеуказанной системы дифференциальных уравнений. Значения начальных параметров определяет начальное состояние системы — для нас это доза вещества с которой начался процесс (в камере ЖКТ 3.0 условных единицы, в камерах 1, 2 — ноль)
#Функция
function pkf!(du, u, p, t)
Kₐ = p[1]
K₁₂= p[2]
K₂₁= p[3]
Kₑ = p[4]
Aᵍ = u[1]
C₁ = u[2]
C₂ = u[3]
Vf = p[5]
du[1] = - Kₐ * Aᵍ
du[2] = Kₐ * Aᵍ / Vf - Kₑ * C₁ - K₁₂ * C₁ + K₂₁ * C₂
du[3] = K₁₂ * C₁ - K₂₁ * C₂
end
#Начальное значение
u0 = [3.0, 0.0, 0.0]
#Параметры
p = [0.8, 0.35, 0.20, 0.15, 0.8]
#Отрезок времени
tspan = (0.0, 50.0)
#ODE problem
prob = ODEProblem(pkf!, u0, tspan, p)
#Решение
sol = solve(prob)
#Графики
plot(sol)При глубоком изучении может потребоваться построение моделей с несколькими камерами, с различными путями элиминации, а также с включением механизмов обработки событий. В таких случаях прямое решение может быть либо очень сложным, либо невозможным. В это время вышеуказанный подход позволяет получать решения уравнений с различными модификациями довольно быстро. К примеру, эту систему можно дополнить дополнительной камерой, которая будет накапливать вещество и в определенные моменты времени быстро выбрасывать его в начальную камеру имитируя энтерогепатическую рециркуляцию (Event Handling and Callback Functions). Возможно включение фармакодинамической части, влияющей на объем распределения определенной камеры или части описывающей кинетику растворения твердой лекарственной формы. Все эти модификации могут быть гибко и быстро учтены с помощью DiffEquations.jl и крайне сложно решаются аналитически.
В реальной жизни мы не знаем параметров модели, но можем располагать данными о концентрации исследуемых веществ, на основе которых можно подобрать наиболее подходящие параметры модели. Практические задачи фармакокинетического моделирования можно свести к определению параметров индивидуальных фармакокинетических моделей и их последующему анализу с помощью известных статистических методов и к определению популяционных фармакокинетических моделей с учетом изучения влияния различных интересующих факторов (пол, возраст, раса, сопутствующие заболевания, стадия течения заболевания и т.д.).
Для примера мы приведем способ подбора индивидуальной двухкомпартментной фармакокинетической модели для однократного внесосудистого применения лекарственного вещества.
Генерация индивидуальных данных с использованием решения выше:
x = [0.25, 0.5, 1.0, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 8.0, 12.0, 24.0, 36.0, 48.0, 60.0]
y = hcat(sol.(x)...)'[:,2] .* exp.(rand(Normal(), length(x)) ./ 8)Функция потерь необходима для оптимизации (минимизации). Обычно используется сумма квадратов отклонений реальных данных от модели, но могут быть использованы и другие. Чем меньше значение функции потерь, тем лучше подгонка (см. также методы максимального правдоподобия).
function loss_function(sol, x, y)
tot_loss = 0.0
if any((s.retcode != :Success for s in sol))
tot_loss = Inf
else
tot_loss = sum(value(L2DistLoss(), hcat(sol.(x)...)'[:,2], y))
#tot_loss = sum(value(LogitDistLoss(), hcat(sol.(x)...)'[:,2], y))
#tot_loss = sum(value(HuberLoss(mean(y)), hcat(sol.(x)...)'[:,2], y))
end
tot_loss
endОптимизация выполняется с помощью Optim.jl, для чего должна быть определена cost_function (подробно тут: Parameter Estimation and Bayesian Analysis).
cost_function = build_loss_objective(prob, Tsit5(), f -> loss_function(f, x, y))
result = optimize(cost_function, [0.4, 0.1, 0.1, 0.1, 1.0], NelderMead(),
Optim.Options(allow_f_increases = true, iterations = 5000, time_limit = 60.0))
#Можно пробовать разные методы:
#result = optimize(cost_function, [0.4, 0.1, 0.1, 0.1, 1.0], Newton(), Optim.Options(allow_f_increases = true, iterations = 5000, time_limit = 60.0))Проверка решения:
prob = ODEProblem(pkf!, u0, tspan, result.minimizer)
sol = solve(prob)
plot!(sol,vars=(2))Возможные затруднения в решении связаны с тем, что сложная модель может не сходиться или сходиться в локальных минимумах, в связи с чем оценка будет не верной. Что можно сделать?
- Адекватно оценить сложность модели и при необходимости упростить.
- Попробовать другие методы (Ньютона, LBFGS, Рой частиц).
- Изменить начальные значения. Можно провести начальную оценку внемодельными методами (NCA), упрощенной моделью, методом Монте-Карло.
- Задать интервалы параметров для оптимизации.
Послесловие.
Фармакокинетическое моделирование может выполняться с использованием двух основных подходов. Первый случай — полные данные. При этом данные каждого субъекта позволяют построить индивидуальную модель (как в рассмотренном примере). Для этого требуетcя, что бы от каждого субъекта было получено достаточное количество качественных наблюдений (под качественными наблюдениями понимаются такие наблюдения, которые получены строго по плану исследования с минимальными и зарегистрированными погрешностями). Примером таких данных служат клинические исследования I фазы, когда для каждого субъекта исследования получен полный фармакокинетических профиль. Как правило, в таких исследованиях регистрируются более 95% данных от планируемого, отклонения по времени составляю не более 5 минут, а погрешности биоаналитики не превышают 15% (обычно менее 5%). После построения моделей уже индивидуальные параметры модели для каждого субъекта могут подвергаться статистическому анализу. Несмотря на хорошее качество данных, могут возникать ситуации, когда для определенных субъектов модель не сможет быть построена, что создаст проблемы для целостности анализа.
Второй случай — разреженные данные. В этом случае всего несколько наблюдений (а иногда всего одно) в слабо регламентированное время могут быть получены от одного субъекта. Таким образом, индивидуальные профили не могут быть построены, но данное обстоятельство компенсируется большим количеством наблюдений. В этом случае данные могут быть стратифицированы, и модель может быть построена по обобщенным данным для каждой страты. Подобное популяционное моделирование может быть эффективно при большом количестве данных, когда индивидуальные параметры не представляют особого интереса. Данный подход не учитывает того, что некоторые наблюдения могут быть от одного субъекта и, следовательно, скоррелированы. Эта проблема решается применением нелинейных моделей со смешанными эффектами в которых можно учесть внутри- и меж-индивидуальную вариацию, а также ковариацию и применение сложных вариационно-ковариационных структур, но эта большая тема лежит за границами данной работы. Тем не менее, нельзя сказать, что в практике используется только нелинейное моделирование со смешанными эффектами. В зависимости от требований и обстоятельств могут быть применимы разные подходы к анализу, как простой анализ с фиксированными факторами, так и анализ параметров индивидуальных моделей.
Связка DiffEquations.jl и Optim.jl позволяет наглядно конструировать модель и проводить анализ. При этом возможно построение как индивидуальных, так и простых популяционных моделей.
Полный код:
using DifferentialEquations, Plots, Optim, LossFunctions, Random, Distributions, DiffEqParamEstim
#Function
function pkf!(du, u, p, t)
Kₐ = p[1]
K₁₂= p[2]
K₂₁= p[3]
Kₑ = p[4]
Aᵍ = u[1]
C₁ = u[2]
C₂ = u[3]
Vf = p[5]
du[1] = - Kₐ * Aᵍ
du[2] = Kₐ * Aᵍ / Vf - Kₑ * C₁ - K₁₂ * C₁ + K₂₁ * C₂
du[3] = K₁₂ * C₁ - K₂₁ * C₂
end
#Start value
u0 = [3.0, 0.0, 0.0]
#Parameters
p = [0.8, 0.35, 0.20, 0.15, 0.8]
#Time span
tspan = (0.0, 50.0)
#ODE problem
prob = ODEProblem(pkf!, u0, tspan, p)
#Solution
sol = solve(prob)
#Plots
#plot(sol)
#plot(sol,vars=(1))
plot(sol,vars=(2))
#plot!(sol,vars=(3))
#x = float.(append!(collect(0.25:0.25:3.75), collect(4:2:40)))
x = [0.25, 0.5, 1.0, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 8.0, 12.0, 24.0, 36.0, 48.0, 60.0]
y = hcat(sol.(x)...)'[:,2] .* exp.(rand(Normal(), length(x)) ./ 10)
scatter!(x,y)
function loss_function(sol, x, y)
tot_loss = 0.0
if any((s.retcode != :Success for s in sol))
tot_loss = Inf
else
tot_loss = sum(value(L2DistLoss(), hcat(sol.(x)...)'[:,2], y))
#tot_loss = sum(value(LogitDistLoss(), hcat(sol.(x)...)'[:,2], y))
#tot_loss = sum(value(HuberLoss(mean(y)), hcat(sol.(x)...)'[:,2], y))
end
tot_loss
end
cost_function = build_loss_objective(prob, Tsit5(), f -> loss_function(f, x, y))
result = optimize(cost_function, [0.4, 0.1, 0.1, 0.1, 1.0], NelderMead(), Optim.Options(allow_f_increases = true, iterations = 5000, time_limit = 60.0))
prob = ODEProblem(pkf!, u0, tspan, result.minimizer)
sol = solve(prob)
plot!(sol,vars=(2))Что почитать:
