[Из песочницы] Что скрывают нейронные сети?
Статья является вольным переводом The Flaw Lurking In Every Deep Neural Net.Недавно опубликованная статья с безобидным заголовком является, вероятно, самый большой новостью в мире нейронных сетей с момента изобретения алгоритма обратного распространения. Но что же в ней написано?
В статье «Интригующие свойства нейронных сетей» за авторством Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow and Rob Fergus, команды, включающей авторов из проекта Google по глубокому обучению, кратко описываются два открытия в поведении нейронных сетей, противоречащие тому, что мы думали прежде. И одно из них, честно говоря, ошеломляет.Первое открытие ставит под сомнение предположение, которое мы так долго считали верным, что нейронные сети упорядочивют данные. Долгое время считалось, что в многослойных сетях на каждом уровне нейроны обучаются распознавать особенности для следующего слоя. Менее сильным было предположение, что последний уровень может распозновать существенные и обычно значимые особенности.
Стандартный способ выяснить, так ли это на самом деле, это найти для конкретного нейрона такое множество входных данных, которое максимизирует выходное значение. Какую бы особенность это множество ни выделяло, предполагается, что нейрон реагирует именно на неё. Например, в задаче распознавания лиц нейрон может реагировать на присутствие глаза или носа на изображении. Но заметьте — нет причины, по которой такие особенности должны совпадать с теми, которые выделает человек.
Было обнаружено, что особенность отдельного нейрона можно трактовать как содержательную не боллее, чем у случайного множества нейронов. То есть, если вы выберете случайным образом множество нейронов и найдёте изображения, максимизирующие выходное значение, эти изображения будут настолько же семантически похоже, как и в случае c одним нейроном.
Это значит, что нейронные сети не «дескремблируют» данные, отображая особенности на отдельные нейроны, например, выходного слоя. Информация, которую извлекает нейронная сеть, настолько же распределена между всеми нейронами, насколько она сосредоточена в одном из них. Это интересная находка, и она ведёт к другой, ещё более интересной…
В каждой нейронной сети есть «слепые пятна» в том смысле, что существуют наборы входных данных, очень близкие к тому, чтобы быть классифицированными правильно, которые при этом распознаются неверно.
С самого начала исследования нейронных сетей предполагалось, что нейронные сети умеют делать обобщения. То есть, если вы обучите сеть распознавать изображения котов, используя определённый набор их фотографий, она сможет, при условии, что была обучена правильно, распознавать котов, которых до этого не встречала.
Это предположение включало другое, ещё более «очевидное», согласно которому если нейронная сеть классифицирует фотографию кота как «кота», то она будет классифицировать так же и слегка изменённую версию этого изображения. Для создания такого изображения нужно немного изменить значения некоторых пикселей, и пока эти изменения небольшие, человек не заметит разницы. Предположительно, не заметит её и компьютер.
Как бы то ни было, это не такРаботой исследователей стало изобретение оптимизационного алгоритма, который начинает выполнение с правильно классифицированного примера и пытается найти небольшое изменение входных значений, которое приведёт к ложной классификации. Конечно, не гарантируется, что такое изменение вообще существует — и если предположение о последовательности работы нейронной сети, упомянутое ранее, верно, то поиск не приносил бы результатов.Однако, результаты есть.
Было доказано, что для различных наборов нейронных сетей и исходных данных можно с большой вероятностью сгенерировать такие «противоречащие примеры» из тех, что распознаются правильно. Цитируя статью:
Для всех сетей, которые мы изучали, и для каждого набора данных нам всегда удаётся сгенерировать очень похожие, визуально неотличимые, противоречащие примеры, которые распознаются неверно.
Чтобы было понятно, для человека исходное и противоречивое изображения выглядят одинаково, но сеть классифицирует их по-разному. У вас может быть две фотографии, на которых не просто изображены два кота, но даже один и тот же кот, с точки зрения человека, но компьютер будет разпозняет одного правильно, а другого — нет.
 Картинки справа классифицированы правильно, картинки слева — неправильно. Посередине изображены разности двух изображений, умноженые на 10, чтобы сделать отличия видимимы.
Картинки справа классифицированы правильно, картинки слева — неправильно. Посередине изображены разности двух изображений, умноженые на 10, чтобы сделать отличия видимимы.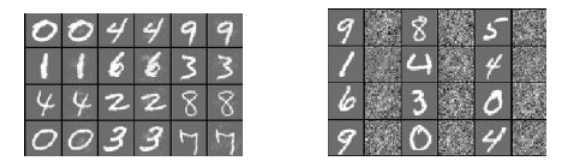 На левой картинке нечётные колонки классифицированы правильно, а чётные — нет. На правой картинке всё распознаётся верно, даже случайное искажение исходных изображений, представленное в чётных колонках. Это показывает, что изменения должны быть очень специфичными — нужно двигаться в строго определённом направлении, чтобы найти пример противоречия.Что ещё сильнее поражает, так это некая всеобщность, которая, кажется, объединяет все эти примеры. Относительно большая доля примеров распознаётся неверно как сетями, обученными на общих данных, но с разными параметрами (количество слоёв, регуляризация или начальные коэффициенты), так и сетями с одинаковыми параметрами, обученными на разных наборах данных.
На левой картинке нечётные колонки классифицированы правильно, а чётные — нет. На правой картинке всё распознаётся верно, даже случайное искажение исходных изображений, представленное в чётных колонках. Это показывает, что изменения должны быть очень специфичными — нужно двигаться в строго определённом направлении, чтобы найти пример противоречия.Что ещё сильнее поражает, так это некая всеобщность, которая, кажется, объединяет все эти примеры. Относительно большая доля примеров распознаётся неверно как сетями, обученными на общих данных, но с разными параметрами (количество слоёв, регуляризация или начальные коэффициенты), так и сетями с одинаковыми параметрами, обученными на разных наборах данных.
Наблюдения, описанные выше, наводят на мысль, что противоречивость примеров это что-то глобальное, а не просто результат переобучения.
Это, наверно, самая выдающаяся часть результата: для каждого правильно классифицированного примера существует другой такой пример, неотличимый от исходного, но классифицируемый неверно независимо от того, какая нейронная сеть или обучающая выборка были использованы.
Поэтому, если у вас есть фотография кота, существует набор небольших изменений, которые могут сделать так, что сеть будет распознавать кота как собаку — независимо от сети и её обучения.
Что всё это означает? Исследователи настроены позитивно и используют противоречащие примеры для обучения сети, добиваясь правильной её рабты. Они относят эти примеры к особенно сложным видам обучающих данных, которые могут быть использованы для улучшения сети и её способности обобщать.Однако, это открытие, кажется, есть нечто большее, чем просто улучшенная обучающая выборка.
Первое, о чём вы можете подумать «Ну и что, что кот может быть классифицирован как собака?». Но если вы немного измените ситуацию, вопрос может звучать как «Что, если беспилотный автомобиль, использующий глубокую нейронную сеть, не распознает пешехода перед собой и будет думать, что дорога свободна?».
Последовательность и стабильность глубоких нейронных сетей важна для их практического применения.
Возникает также философский вопрос относительно слепых областей, упомянутых ранее. Если основой глубоких нейронных сетей послужила биологическая модель, можно ли применить к ней полученый результат? Или, говоря проще, содержит ли человеческий мозг подобные встроенные ошибки? Если нет, то чем он так сильно отличается от нейронных сетей, пытающихся копировать его работу? В чём секрет его стабильности и последовательности?
Одним из объяснений может быть то, что это ещё одно проявление проклятия размерностеи. Известно, что с ростом размерности пространства объём гиперсферы экспоненциально концентрируется на её границе. Учитывая, что границы решений находятся в пространстве очень большой размерности, кажется логичным, что наиболее хорошо классифицированные примеры будут располагаться близко к границе. В этом случае возможность классифицировать пример неверно очень близка к возможности сделать это правильно — нужно лишь определить направление в сторону ближайшей границы.
Если это всё объясняет, то понятно, что даже человеческий мозг не может избежать подобного эффекта и должен как-то справляться с этим. Иначе, кошки превращались бы в собак с тревожной регулярностью.
Итог
Нейронные сети выявили новый тип нестабильности, и не похоже, что могут принимать решения последовательно. И вместо того, чтобы «латать дыры», включая противоречивые примеры в обучающие выборки, наука должна исследовать и устранить проблему. Пока этого не произойдёт, мы не может полагаться на нейронные сети там, где безопасность критически важна…
