[Из песочницы] Частотный анализ русского текста и облако слов на Python
Частотный анализ является одним из сравнительно простых методов обработки текста на естественном языке (NLP). Его результатом является список слов, наиболее часто встречающихся в тексте. Частотный анализ также позволяет получить представление о тематике и основных понятиях текста. Визуализировать его результаты удобно в виде «облака слов». Эта диаграмма содержит слова, размер шрифта которых отражает их популярность в тексте.
Обработку текста на естественном языке удобно производить с помощью Python, поскольку он является достаточно высокоуровневым инструментом программирования, имеет развитую инфраструктуру, хорошо зарекомендовал себя в сфере анализа данных и машинного обучения. Сообществом разработано несколько библиотек и фреймворков для решения задач NLP на Python. Мы в своей работе будем использовать интерактивный веб-инструмент для разработки python-скриптов Jupyter Notebook, библиотеку NLTK для анализа текста и библиотеку wordcloud для построения облака слов.
В сети представлено достаточно большое количество материала по теме анализа текста, но во многих статьях (в том числе русскоязычных) предлагается анализировать текст на английском языке. Анализ русского текста имеет некоторую специфику применения инструментария NLP. В качестве примера рассмотрим частотный анализ текста повести «Метель» А.С. Пушкина.
Проведение частотного анализа можно условно разделить на несколько этапов:
- Загрузка и обзор данных
- Очистка и предварительная обработка текста
- Удаление стоп-слов
- Перевод слов в основную форму
- Подсчёт статистики встречаемости слов в тексте
- Визуализация популярности слов в виде облака
Скрипт доступен по адресу github.com/Metafiz/nlp-course-20/blob/master/frequency-analisys-of-text.ipynb, исходный текст — github.com/Metafiz/nlp-course-20/blob/master/pushkin-metel.txt
Загрузка данных
Открываем файл с помощью встроенной функции open, указываем режим чтения и кодировку. Читаем всё содержимое файла, в результате получаем строку text:
f = open('pushkin-metel.txt', "r", encoding="utf-8")
text = f.read()
Длину текста — количество символов — можно получить стандартной функцией len:
len(text)
Строка в python может быть представлена как список символов, поэтому для работы со строками также возможны операции доступа по индексам и получения срезов. Например, для просмотра первых 300 символов текста достаточно выполнить команду:
text[:300]
Предварительная обработка (препроцессинг) текста
Для проведения частотного анализа и определения тематики текста рекомендуется выполнить очистку текста от знаков пунктуации, лишних пробельных символов и цифр. Сделать это можно различными способами — с помощью встроенных функций работы со строками, с помощью регулярных выражений, с помощью операций обработки списков или другим способом.
Для начала переведём символы в единый регистр, например, нижний:
text = text.lower()
Используем стандартный набор символов пунктуации из модуля string:
import string
print(string.punctuation)
string.punctuation представляет собой строку. Набор специальных символов, которые будут удалены из текста может быть расширен. Необходимо проанализировать исходный текст и выявить символы, которые следует удалить. Добавим к знакам пунктуации символы переноса строки, табуляции и другие символы, которые встречаются в нашем исходном тексте (например, символ с кодом \xa0):
spec_chars = string.punctuation + '\n\xa0«»\t—…'
Для удаления символов используем поэлементную обработку строки — разделим исходную строку text на символы, оставим только символы, не входящие в набор spec_chars и снова объединим список символов в строку:
text = "".join([ch for ch in text if ch not in spec_chars])
Можно объявить простую функцию, которая удаляет указанный набор символов из исходного текста:
def remove_chars_from_text(text, chars):
return "".join([ch for ch in text if ch not in chars])
Её можно использовать как для удаления спец.символов, так и для удаления цифр из исходного текста:
text = remove_chars_from_text(text, spec_chars)
text = remove_chars_from_text(text, string.digits)
Токенизация текста
Для последующей обработки очищенный текст необходимо разбить на составные части — токены. В анализе текста на естественном языке применяется разбиение на символы, слова и предложения. Процесс разбиения называется токенизация. Для нашей задачи частотного анализа необходимо разбить текст на слова. Для этого можно использовать готовый метод библиотеки NLTK:
from nltk import word_tokenize
text_tokens = word_tokenize(text)
Переменная text_tokens представляет собой список слов (токенов). Для вычисления количества слов в предобработанном тексте можно получить длину списка токенов:
len(text_tokens)
Для вывода первых 10 слов воспользуемся операцией среза:
text_tokens[:10]
Для применения инструментов частотного анализа библиотеки NLTK необходимо список токенов преобразовать к классу Text, который входит в эту библиотеку:
import nltk
text = nltk.Text(text_tokens)
Выведем тип переменной text:
print(type(text))
К переменной этого типа также применимы операции среза. Например, это действие выведет 10 первых токенов из текста:
text[:10]
Подсчёт статистики встречаемости слов в тексте
Для подсчёта статистики распределения частот слов в тексте применяется класс FreqDist (frequency distributions):
from nltk.probability import FreqDist
fdist = FreqDist(text)
Попытка вывести переменную fdist отобразит словарь, содержащий токены и их частоты — количество раз, которые эти слова встречаются в тексте:
FreqDist({'и': 146, 'в': 101, 'не': 69, 'что': 54, 'с': 44, 'он': 42, 'она': 39, 'ее': 39, 'на': 31, 'было': 27, ...})
Также можно воспользоваться методом most_common для получения списка кортежей с наиболее часто встречающимися токенами:
fdist.most_common(5)
[('и', 146), ('в', 101), ('не', 69), ('что', 54), ('с', 44)]
Частота распределения слов тексте может быть визуализирована с помощью графика. Класс FreqDist содержит встроенный метод plot для построения такого графика. Необходимо указать количество токенов, частоты которых будут показаны на графике. С параметром cumulative=False график иллюстрирует закон Ципфа: если все слова достаточно длинного текста упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n.
fdist.plot(30,cumulative=False)
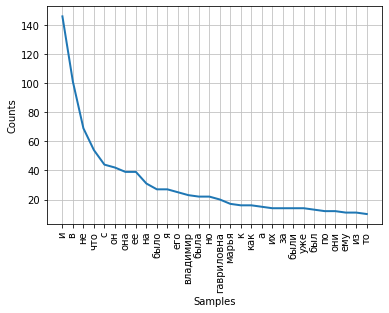
Можно заметить, что в данный момент наибольшие частоты имеют союзы, предлоги и другие служебные части речи, не несущие смысловой нагрузки, а только выражающие семантико-синтаксические отношения между словами. Для того, чтобы результаты частотного анализа отражали тематику текста, необходимо удалить эти слова из текста.
Удаление стоп-слов
К стоп-словам (или шумовым словам), как правило, относят предлоги, союзы, междометия, частицы и другие части речи, которые часто встречаются в тексте, являются служебными и не несут смысловой нагрузки — являются избыточными.
Библиотека NLTK содержит готовые списки стоп-слов для различных языков. Получим список сто-слов для русского языка:
from nltk.corpus import stopwords
russian_stopwords = stopwords.words("russian")
Следует отметить, что стоп-слова являются контекстно зависимыми — для текстов различной тематики стоп-слова могут отличаться. Как и в случае со спец.символами, необходимо проанализировать исходный текст и выявить стоп-слова, которые не вошли в типовой набор.
Список стоп-слов может быть расширен с помощью стандартного метода extend:
russian_stopwords.extend(['это', 'нею'])
После удаления стоп-слов частота распределения токенов в тексте выглядит следующим образом:
fdist_sw.most_common(10)
[('владимир', 23),
('гавриловна', 20),
('марья', 17),
('поехал', 9),
('бурмин', 9),
('поминутно', 8),
('метель', 7),
('несколько', 6),
('сани', 6),
('владимира', 6)]
Как видно, результаты частотного анализа стали более информативными и точнее стали отражать основную тематику текста. Однако, мы видим в результатах такие токены, как «владимир» и «владимира», которые являются, по сути, одним словом, но в разных формах. Для исправления этой ситуации необходимо слова исходного текста привести к их основам или изначальной форме — провести стемминг или лемматизацию.
Визуализация популярности слов в виде облака
В завершение нашей работы визуализируем результаты частотного анализа текста в виде «облака слов».
Для этого нам потребуются библиотеки wordcloud и matplotlib:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
Для построения облака слов на вход методу необходимо передать строку. Для преобразования списка токенов после предобработки и удаления стоп-слов воспользуемся методом join, указав в качестве разделителя пробел:
text_raw = " ".join(text)
Выполним вызов метода построения облака:
wordcloud = WordCloud().generate(text_raw)
В результате получаем такое «облако слов» для нашего текста:

Глядя на него, можно получить общее представление о тематике и главных персонажах произведения.
