[Из песочницы] BPF для самых маленьких, часть нулевая: classic BPF
Berkeley Packet Filters (BPF) — это технология ядра Linux, которая не сходит с первых полос англоязычных технических изданий вот уже несколько лет подряд. Конференции забиты докладами про использование и разработку BPF. David Miller, мантейнер сетевой подсистемы Linux, называет свой доклад на Linux Plumbers 2018 «This talk is not about XDP» (XDP — это один из вариантов использования BPF). Brendan Gregg читает доклады под названием Linux BPF Superpowers. Toke Høiland-Jørgensen смеется, что ядро это теперь microkernel. Thomas Graf рекламирует идею о том, что BPF — это javascript для ядра.
На Хабре до сих пор нет систематического описания BPF, и поэтому я в серии статей постараюсь рассказать про историю технологии, описать архитектуру и средства разработки, очертить области применения и практики использования BPF. В этой, нулевой, статье цикла рассказывается история и архитектура классического BPF, а также раскрываются тайны принципов работы tcpdump, seccomp, strace, и многое другое.
Разработка BPF контролируется сетевым сообществом Linux, основные существующие применения BPF связаны с сетями и поэтому, с позволения @eucariot, я назвал серию «BPF для самых маленьких», в честь великой серии «Сети для самых маленьких».
Краткий курс истории BPF (c)
Современная технология BPF — это улучшенная и дополненная версия старой технологии с тем же названием, называемой нынче, во избежание путаницы, classic BPF. На основе классического BPF были созданы всем известная утилита tcpdump, механизм seccomp, а также менее известные модуль xt_bpf для iptables и классификатор cls_bpf. В современном Linux классические программы BPF автоматически транслируются в новую форму, однако, с пользовательской точки зрения, API остался на месте и новые применения классического BPF, как мы увидим в этой статье, находятся до сих пор. По этой причине, а также потому, что следуя за историей развития классической BPF в Linux, станет яснее как и почему она эволюционировала в современную форму, я решил начать именно со статьи про классический BPF.
В конце восьмидесятых годов прошлого века инженеры из знаменитой Lawrence Berkeley Laboratory заинтересовались вопросом о том, как правильно фильтровать сетевые пакеты на современном для конца восьмидесятых годов прошлого века железе. Базовая идея фильтрации, реализованная изначально в технологии CSPF (CMU/Stanford Packet Filter), состояла в том, чтобы фильтровать лишние пакеты как можно раньше, т.е. в пространстве ядра, так как это позволяет не копировать лишние данные в пространство пользователя. Чтобы обеспечить безопасность времени выполнения для запуска пользовательского кода в пространстве ядра, использовалась виртуальная машина — песочница.
Однако виртуальные машины для существовавших фильтров были спроектированы для запуска на машинах со стековой архитектурой и на новых RISC машинах работали не так эффективно. В итоге усилиями инженеров из Berkeley Labs была разработана новая технология BPF (Berkeley Packet Filters), архитектура виртуальной машины которой была спроектирована на основе процессора Motorola 6502 — рабочей лошадки таких известных продуктов как Apple II или NES. Новая виртуальная машина увеличивала производительность фильтров в десятки раз по сравнению с существовавшими решениями.
Архитектура машины BPF
Мы познакомимся с архитектурой по-рабочему, разбирая примеры. Однако для начала все же скажем, что у машины было два доступных для пользователя 32-битных регистра, аккумулятор A и индексный регистр X, 64 байта памяти (16 слов), доступной для записи и последующего чтения, и небольшая система команд для работы с этими объектами. В программах были доступны и инструкции перехода для реализации условных выражений, однако для гарантии своевременного окончания работы программы переходить можно было только вперед, т.е., в частности, запрещалось создавать циклы.
Общая схема запуска машины следующая. Пользователь создает программу для архитектуры BPF и, при помощи какого-то механизма ядра (например, системного вызова), загружает и подключает программу к какому-то генератору событий в ядре (например, событие — это приход очередного пакета на сетевую карту). При возникновении события ядро запускает программу (например, в интерпретаторе), при этом память машины соответствует какому-то региону памяти ядра (например, данным пришедшего пакета).
Сказанного выше нам будет достаточно для того, чтобы начать разбирать примеры: мы познакомимся с системой и форматом команд по необходимости. Если же вам хочется сразу изучить систему команд виртуальной машины и узнать про все ее возможности, то можно прочитать оригинальную статью The BSD Packet Filter и/или первую половину файла Documentation/networking/filter.txt из документации ядра. Кроме этого, можно изучить презентацию libpcap: An Architecture and Optimization Methodology for Packet Capture, в которой McCanne, один из авторов BPF, рассказывает про историю создания libpcap.
Мы же переходим к рассмотрению всех существенных примеров применения классического BPF в Linux: tcpdump (libpcap), seccomp, xt_bpf, cls_bpf.
tcpdump
Разработка BPF велась параллельно с разработкой фронтенда для фильтрации пакетов — всем известной утилиты tcpdump. И, так как это самый старый и самый известный пример использования классического BPF, доступный на множестве операционных систем, с него мы изучение технологии и начнем.
(Все примеры в этой статье я запускал на Linux 5.6.0-rc6. Вывод некоторых команд отредактирован для большей удобочитаемости.)
Пример: наблюдаем IPv6 пакеты
Представим, что мы хотим смотреть на все IPv6 пакеты на интерфейсе eth0. Для этого мы можем запустить программу tcpdump с простейшим фильтром ip6:
$ sudo tcpdump -i eth0 ip6При этом tcpdump скомпилирует фильтр ip6 в байт-код архитектуры BPF и отправит его в ядро (см. подробности в разделе Tcpdump: загрузка). Загруженный фильтр будет запущен для каждого пакета, проходящего через интерфейс eth0. Если фильтр вернет ненулевое значение n, то до n байтов пакета будет скопировано в пространство пользователя и мы увидим его в выводе tcpdump.
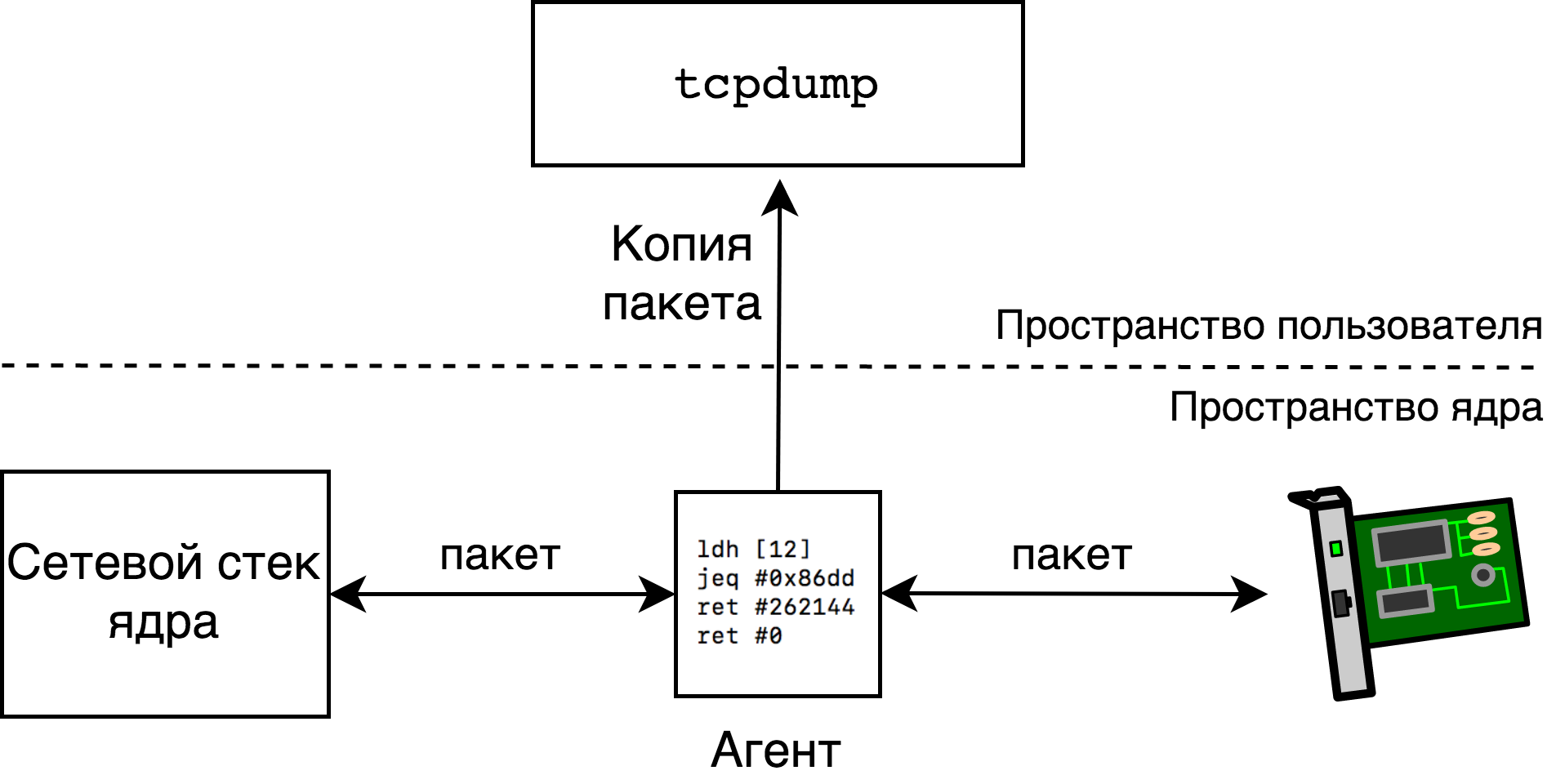
Оказывается, мы можем легко узнать какой именно байткод отправил в ядро tcpdump при помощи самого tcpdump, если запустим его с опцией -d:
$ sudo tcpdump -i eth0 -d ip6
(000) ldh [12]
(001) jeq #0x86dd jt 2 jf 3
(002) ret #262144
(003) ret #0На нулевой строчке мы запускаем команду ldh [12], которая расшифровывается как «загрузить в регистр A пол-слова (16 бит), находящиеся по адресу 12» и единственный вопрос — это что за память мы адресуем? Ответ заключается в том, что по адресу x начинается (x+1)-й байт анализируемого сетевого пакета. Мы читаем пакеты с Ethernet интерфейса eth0, а это означает, что пакет выглядит следующим образом (для простоты мы считаем, что в пакете нет VLAN тэгов):
6 6 2
|Destination MAC|Source MAC|Ether Type|...|Значит после выполнения команды ldh [12] в регистре A окажется поле Ether Type — тип передаваемого в данном Ethernet-фрейме пакета. На строчке 1 мы сравниваем содержимое регистра A (тип пакета) c 0x86dd, а это и есть интересующий нас тип IPv6. На строчке 1 кроме команды сравнения есть еще два столбца — jt 2 и jf 3 — метки, на которые нужно перейти в случае удачного сравнения (A == 0x86dd) и неудачного. Итак, в удачном случае (IPv6) мы переходим на строчку 2, а в неудачном — на строчку 3. На строчке 3 программа завершается с кодом 0 (не копируй пакет), на строчке 2 программа завершается с кодом 262144 (скопируй мне максимум 256 килобайт пакета).
Пример посложнее: смотрим на TCP пакеты по порту назначения
Посмотрим как выглядит фильтр, который копирует все TCP пакеты с портом назначения 666. Мы рассмотрим случай IPv4, так как случай IPv6 проще. После изучения данного примера, вы можете в качестве упражнения самостоятельно изучить фильтр для IPv6 (ip6 and tcp dst port 666) и фильтр для общего случая (tcp dst port 666). Итак, интересующий нас фильтр выглядит следующим образом:
$ sudo tcpdump -i eth0 -d ip and tcp dst port 666
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 10
(002) ldb [23]
(003) jeq #0x6 jt 4 jf 10
(004) ldh [20]
(005) jset #0x1fff jt 10 jf 6
(006) ldxb 4*([14]&0xf)
(007) ldh [x + 16]
(008) jeq #0x29a jt 9 jf 10
(009) ret #262144
(010) ret #0Что делают строчки 0 и 1 мы уже знаем. На строке 2 мы уже проверили, что это IPv4 пакет (Ether Type = 0x800) и загружаем в регистр A 24-й байт пакета. Наш пакет выглядит как
14 8 1 1
|ethernet header|ip fields|ttl|protocol|...|а значит мы загружаем в регистр A поле Protocol заголовка IP, что логично, ведь мы же хотим копировать только TCP пакеты. Мы сравниваем Protocol с 0x6 (IPPROTO_TCP) на строке 3.
На строках 4 и 5 мы загружаем полслова, находящиеся по адресу 20, и при помощи команды jset проверяем, не выставлен ли один из трех флагов — в маске выданной jset очищены три старшие бита. Два бита из трех говорят нам, является ли пакет частью фрагментированного IP пакета, и если да, то является ли он последним фрагментом. Третий бит зарезервирован и должен быть равен нулю. Мы не хотим проверять ни нецелые ни битые пакеты, поэтому и проверяем все три бита.
Строчка 6 — самая интересная в этом листинге. Выражение ldxb 4*([14]&0xf) означает, что мы загружаем в регистр X четыре младшие бита пятнадцатого байта пакета, умноженные на 4. Четыре младшие бита пятнадцатого байта — это поле Internet Header Length заголовка IPv4, в котором хранится длина заголовка в словах, поэтому и нужно потом умножить на 4. Интересно, что выражение 4*([14]&0xf) — это обозначение специальной схемы адресации, которое можно использовать только в таком виде и только для регистра X, т.е. мы не можем сказать ни ldb 4*([14]&0xf) ни ldxb 5*([14]&0xf) (мы можем только указать другой offset, например, ldxb 4*([16]&0xf)). Понятно, что эта схема адресации была добавлена в BPF ровно для того, чтобы получать в X (индексный регистр) длину заголовка IPv4.
Таким образом, на строчке 7 мы пытаемся загрузить пол-слова, по адресу (X+16). Вспомнив, что 14 байт занимает заголовок Ethernet, а X содержит длину заголовка IPv4, мы понимаем, что в A загружается порт назначения TCP:
14 X 2 2
|ethernet header|ip header|source port|destination port|Наконец, на строке 8 мы сравниваем порт назначения с искомым значением и на строчках 9 или 10 возвращаем результат — копировать пакет или нет.
Tcpdump: загрузка
В предыдущих примерах мы специально не останавливались подробно на том, как именно мы загружаем BPF байткод в ядро для фильтрации пакетов. Вообще говоря, tcpdump портирован на много систем и для работы с фильтрами tcpdump использует библиотеку libpcap. Вкратце, чтобы посадить фильтр на интерфейс при помощи libpcap, нужно сделать следующее:
- создать дескриптор типа
pcap_tиз имени интерфейса:pcap_create, - активировать интерфейс:
pcap_activate, - скомпилировать фильтр:
pcap_compile, - подключить фильтр:
pcap_setfilter.
Для того, чтобы посмотреть как функция pcap_setfilter реализована в Linux, мы используем strace (некоторые строчки были удалены):
$ sudo strace -f -e trace=%network tcpdump -p -i eth0 ip
socket(AF_PACKET, SOCK_RAW, 768) = 3
bind(3, {sa_family=AF_PACKET, sll_protocol=htons(ETH_P_ALL), sll_ifindex=if_nametoindex("eth0"), sll_hatype=ARPHRD_NETROM, sll_pkttype=PACKET_HOST, sll_halen=0}, 20) = 0
setsockopt(3, SOL_SOCKET, SO_ATTACH_FILTER, {len=4, filter=0xb00bb00bb00b}, 16) = 0
...На первых двух строчках вывода мы создаем raw сокет для чтения всех Ethernet фреймов и привязываем его к интерфейсу eth0. Из нашего первого примера мы знаем, что фильтр ip будет состоять из четырех BPF инструкций, и на третьей строчке мы видим, как при помощи опции SO_ATTACH_FILTER системного вызова setsockopt мы загружаем и подсоединяем фильтр длины 4. Это и есть наш фильтр.
Стоит отметить, что в классическом BPF загрузка и подсоединение фильтра всегда происходит как атомарная операция, а в новой версии BPF загрузка программы и привязка ее к генератору событий разделены по времени.
Чуть более полная версия вывода выглядит так:
$ sudo strace -f -e trace=%network tcpdump -p -i eth0 ip
socket(AF_PACKET, SOCK_RAW, 768) = 3
bind(3, {sa_family=AF_PACKET, sll_protocol=htons(ETH_P_ALL), sll_ifindex=if_nametoindex("eth0"), sll_hatype=ARPHRD_NETROM, sll_pkttype=PACKET_HOST, sll_halen=0}, 20) = 0
setsockopt(3, SOL_SOCKET, SO_ATTACH_FILTER, {len=1, filter=0xbeefbeefbeef}, 16) = 0
recvfrom(3, 0x7ffcad394257, 1, MSG_TRUNC, NULL, NULL) = -1 EAGAIN (Resource temporarily unavailable)
setsockopt(3, SOL_SOCKET, SO_ATTACH_FILTER, {len=4, filter=0xb00bb00bb00b}, 16) = 0
...Как было сказано выше, мы загружаем и подсоединяем к сокету наш фильтр на строке 5, но что происходит на строчках 3 и 4? Оказывается, это libpcap заботится о нас — для того, чтобы в вывод нашего фильтра не попали пакеты, ему не удовлетворяющие, библиотека подсоединяет фиктивный фильтр ret #0 (дропнуть все пакеты), переводит сокет в неблокирующий режим и пытается вычитать все пакеты, которые могли остаться от прошлых фильтров.
Итого, чтобы фильтровать пакеты на Linux при помощи классического BPF, необходимо иметь фильтр в виде структуры типа struct sock_fprog и открытый сокет, после чего фильтр можно присоединить к сокету при помощи системного вызова setsockopt.
Интересно, что фильтр можно присоединять к любому сокету, не только к raw. Вот пример программы, которая отрезает все, кроме двух первых байт у всех входящих UDP датаграмм. (Комментарии я добавил в коде, чтобы не загромождать статью.)
Подробнее про использование setsockopt для подсоединения фильтров см. в socket (7), а про написание своих фильтров вида struct sock_fprog без помощи tcpdump мы поговорим в разделе Программируем BPF при помощи собственных рук.
Классический BPF и XXI век
BPF был включен в Linux в 1997 году и долгое время оставался рабочей лошадкой libpcap без особых изменений (Linux-специфичные изменения, конечно, были, но они не меняли глобальной картины). Первые серьезные признаки того, что BPF будет эволюционировать появились в 2011 году, когда Eric Dumazet предложил патч, добавляющий в ядро Just In Time Compiler — транслятор для перевода байткода BPF в нативный x86_64 код.
JIT compiler был первым в цепочке изменений: в 2012 году появилась возможность писать фильтры для seccomp, используя BPF, в январе 2013 был добавлен модуль xt_bpf, позволяющий писать правила для iptables при помощи BPF, а в октябре 2013 был добавлен еще и модуль cls_bpf, позволяющий писать при помощи BPF классификаторы трафика.
Мы скоро рассмотрим все эти примеры подробнее, однако сначала нам будет полезно научиться писать и компилировать произвольные программы для BPF, так как возможности, предоставляемые библиотекой libpcap ограничены (простой пример: фильтр, сгенерированный libpcap может вернуть только два значения — 0 или 0×40000) или вообще, как в случае seccomp, неприменимы.
Программируем BPF при помощи собственных рук
Познакомимся с бинарным форматом инструкций BPF, он очень простой:
16 8 8 32
| code | jt | jf | k |Каждая инструкция занимает 64 бита, в которых первые 16 бит — это код команды, потом идут два восьмибитных отступа, jt и jf, и 32 бита для аргумента K, назначение которого меняется от команды к команде. Например, команда ret, завершающая работу программы имеет код 6, а возвращаемое значение берется из константы K. На языке C одна инструкция BPF представляется в виде структуры
struct sock_filter {
__u16 code;
__u8 jt;
__u8 jf;
__u32 k;
}а целая программа — в виде структуры
struct sock_fprog {
unsigned short len;
struct sock_filter *filter;
}Таким образом, мы уже можем писать программы (коды инструкций мы, допустим, знаем из [1]). Вот так будет выглядеть фильтр ip6 из нашего первого примера:
struct sock_filter code[] = {
{ 0x28, 0, 0, 0x0000000c },
{ 0x15, 0, 1, 0x000086dd },
{ 0x06, 0, 0, 0x00040000 },
{ 0x06, 0, 0, 0x00000000 },
};
struct sock_fprog prog = {
.len = ARRAY_SIZE(code),
.filter = code,
};Программу prog мы можем легально использовать в вызове
setsockopt(sk, SOL_SOCKET, SO_ATTACH_FILTER, &prog, sizeof(prog))Писать программы в виде машинных кодов не очень удобно, но иногда приходится (например, для отладки, создания юнит-тестов, написания статей на хабре и т.п.). Для удобства в файле
struct sock_filter code[] = {
BPF_STMT(BPF_LD|BPF_H|BPF_ABS, 12),
BPF_JUMP(BPF_JMP|BPF_JEQ|BPF_K, ETH_P_IPV6, 0, 1),
BPF_STMT(BPF_RET|BPF_K, 0x00040000),
BPF_STMT(BPF_RET|BPF_K, 0),
}Однако, и такой вариант не очень-то удобен. Так рассудили и программисты ядра Linux и поэтому в директории tools/bpf ядра можно найти ассемблер и дебагер для работы с классическим BPF.
Язык ассемблера очень похож на отладочный вывод tcpdump, но в дополнение мы можем указывать символические метки. Например, вот программа, которая дропает все пакеты, кроме TCP/IPv4:
$ cat /tmp/tcp-over-ipv4.bpf
ldh [12]
jne #0x800, drop
ldb [23]
jneq #6, drop
ret #-1
drop: ret #0По умолчанию ассемблер генерирует код в формате <количество инструкций>,, для нашего примера с TCP получится
$ tools/bpf/bpf_asm /tmp/tcp-over-ipv4.bpf
6,40 0 0 12,21 0 3 2048,48 0 0 23,21 0 1 6,6 0 0 4294967295,6 0 0 0,Для удобства C программистов можно использовать другой формат вывода:
$ tools/bpf/bpf_asm -c /tmp/tcp-over-ipv4.bpf
{ 0x28, 0, 0, 0x0000000c },
{ 0x15, 0, 3, 0x00000800 },
{ 0x30, 0, 0, 0x00000017 },
{ 0x15, 0, 1, 0x00000006 },
{ 0x06, 0, 0, 0xffffffff },
{ 0x06, 0, 0, 0000000000 },Этот текст можно скопировать в определение структуры типа struct sock_filter, как мы и проделали в начале этого раздела.
Расширения Linux и netsniff-ng
Кроме стандартных инструкций BPF, Linux и tools/bpf/bpf_asm поддерживают и нестандартный набор. В основном, инструкции служат для доступа к полям структуры struct sk_buff, описывающей сетевой пакет в ядре. Однако, есть и инструкции-помощники другого типа, например ldw cpu загрузит в регистр A результат запуска функции ядра raw_smp_processor_id(). (В новой версии BPF эти нестандартные расширения были расширены в виде предоставления программам набора kernel helpers для доступа к памяти, структурам, и генерации событий.) Вот интересный пример фильтра, в котором мы копируем в пространство пользователя только заголовки пакетов, используя расширение poff, payload offset:
ld poff
ret aРасширения BPF не получится использовать в tcpdump, но это хороший повод познакомиться с пакетом утилит netsniff-ng, который, кроме всего прочего, содержит продвинутую программу netsniff-ng, которая, кроме фильтрации при помощи BPF содержит также и эффективный генератор трафика, и более продвинутый, чем tools/bpf/bpf_asm, ассемблер BPF под названием bpfc. Пакет содержит довольно подробную документацию, см. также ссылки в конце статьи.
seccomp
Итак, мы уже умеем писать BPF программы произвольной сложности и готовы посмотреть на новые примеры, первый из которых — это технология seccomp, позволяющая при помощи фильтров BPF управлять множеством и набором аргументов системных вызовов, доступных данному процессу и его потомкам.
Первая версия seccomp была добавлена в ядро в 2005 году и не пользовалась большой популярностью, так как предоставляла лишь единственную возможность — ограничить множество системных вызовов, доступных процессу, следующим: read, write, exit и sigreturn, а процесс, нарушивший правила убивался при помощи SIGKILL. Однако в 2012 году в seccomp была добавлена возможность использовать BPF фильтры, позволяющие определять множество разрешенных системных вызовов и даже выполнять проверки над их аргументами. (Интересно, что одним из первых пользователей этой функциональности являлся Chrome, а в данный момент людьми из Chrome разрабатывается механизм KRSI, основанный на новой версии BPF и позволяющий кастомизировать Linux Security Modules.) Ссылки на дополнительную документацию можно найти в конце статьи.
Отметим, что на хабре уже были статьи про использование seccomp, может кому-то захочется прочитать их до (или вместо) чтения следующих подразделов. В статье Контейнеры и безопасность: seccomp приведены примеры использования seccomp, как версии 2007 года, так и версии с использованием BPF (фильтры генерируются при помощи libseccomp), рассказывается про связь seccomp с Docker, а также приведено много полезных ссылок. В статье Изолируем демоны с systemd или «вам не нужен Docker для этого!» рассказывается, в частности, о том, как добавлять черные или белые списки системных вызовов для демонов под управлением systemd.
Дальше мы посмотрим как писать и загружать фильтры для seccomp на голом C и при помощи библиотеки libseccomp и какие плюсы и минусы есть у каждого варианта, а напоследок посмотрим как seccomp используется программой strace.
Пишем и загружаем фильтры для seccomp
Мы уже умеем писать BPF программы и поэтому посмотрим сначала на программный интерфейс seccomp. Установить фильтр можно на уровне процесса, при этом все дочерние процессы будут ограничения наследовать. Делается это при помощи системного вызова seccomp(2):
seccomp(SECCOMP_SET_MODE_FILTER, flags, &filter)где &filter — это указатель на уже знакомую нам структуру struct sock_fprog, т.е. программу BPF.
Чем же отличаются программы для seccomp от программ для сокетов? Передаваемым контекстом. В случае сокетов, нам передавалась область памяти, содержащая пакет, а в случае seccomp нам передается структура вида
struct seccomp_data {
int nr;
__u32 arch;
__u64 instruction_pointer;
__u64 args[6];
};Здесь nr — это номер запускаемого системного вызова, arch — текущая архитектура (об этом ниже), args — до шести аргументов системного вызова, а instruction_pointer — это указатель на инструкцию в пространстве пользователя, которая сделала данный системный вызов. Таким образом, например, чтобы загрузить номер системного вызова в регистр A мы должны сказать
ldw [0]Для программ seccomp существуют и другие особенности, например, доступ к контексту возможен только по 32-битному выравниванию и нельзя загружать пол-слова или байт — при попытке загрузить фильтр ldh [0] системный вызов seccomp вернет EINVAL. Проверку загружаемых фильтров выполняет функция seccomp_check_filter() ядра. (Из смешного, в оригинальном коммите, добавляющем функциональность seccomp, в эту функцию забыли добавить разрешение на использование инструкции mod (остаток от деления) и теперь она недоступна для seccomp BPF программ, так как ее добавление сломает ABI.)
В принципе, мы уже знаем все, чтобы писать и читать seccomp программы. Обычно логика программы устроена как белый или черный список системных вызовов, например программа
ld [0]
jeq #304, bad
jeq #176, bad
jeq #239, bad
jeq #279, bad
good: ret #0x7fff0000 /* SECCOMP_RET_ALLOW */
bad: ret #0проверяет черный список из четырех системных вызовов под номерами 304, 176, 239, 279. Что же это за системные вызовы? Мы не можем сказать точно, так как мы не знаем для какой архитектуры писалась программа. Поэтому авторы seccomp предлагают начинать все программы с проверки архитектуры (текущая архитектура указывается в контексте как поле arch структуры struct seccomp_data). С проверкой архитектуры начало примера выглядело бы как:
ld [4]
jne #0xc000003e, bad_arch ; SCMP_ARCH_X86_64и тогда наши номера системных вызовов получили бы определенные значения.
Пишем и загружаем фильтры для seccomp при помощи libseccomp
Написание фильтров в машинных кодах или для ассемблера BPF позволяет получить полный контроль над результатом, но в то же время иногда предпочтительнее иметь переносимый и/или читаемый код. В этом нам поможет библиотека libseccomp, предоставляющая стандартный интерфейс для написания черных или белых фильтров.
Давайте, например, напишем программу, которая запускает бинарный файл по выбору пользователя, установив, предварительно, черный список системных вызовов из вышеупомянутой статьи (программа упрощена для большей читаемости, полный вариант можно найти тут):
#include
#include
#include
static int sys_numbers[] = {
__NR_mount,
__NR_umount2,
// ... еще 40 системных вызовов ...
__NR_vmsplice,
__NR_perf_event_open,
};
int main(int argc, char **argv)
{
scmp_filter_ctx ctx = seccomp_init(SCMP_ACT_ALLOW);
for (size_t i = 0; i < sizeof(sys_numbers)/sizeof(sys_numbers[0]); i++)
seccomp_rule_add(ctx, SCMP_ACT_TRAP, sys_numbers[i], 0);
seccomp_load(ctx);
execvp(argv[1], &argv[1]);
err(1, "execlp: %s", argv[1]);
} Вначале мы определяем массив sys_numbers из 40+ номеров системных вызовов для блокировки. Затем, инициализируем контекст ctx и говорим библиотеке, что мы хотим разрешить (SCMP_ACT_ALLOW) все системные вызовы по-умолчанию (строить черные списки проще). Затем, один за одним, мы добавляем все системные вызовы из черного списка. В качестве реакции на системный вызов из списка мы запрашиваем SCMP_ACT_TRAP, в этом случае seccomp пошлет процессу сигнал SIGSYS с описанием того, какой именно системный вызов нарушил правила. Наконец, мы загружаем программу в ядро при помощи seccomp_load, которая скомпилирует программу и подключит ее к процессу при помощи системного вызова seccomp(2).
Для успешной компиляции программу нужно слинковать с библиотекой libseccomp, например:
cc -std=c17 -Wall -Wextra -c -o seccomp_lib.o seccomp_lib.c
cc -o seccomp_lib seccomp_lib.o -lseccompПример успешного запуска:
$ ./seccomp_lib echo ok
okПример заблокированного системного вызова:
$ sudo ./seccomp_lib mount -t bpf bpf /tmp
Bad system callИспользуем strace, чтобы узнать подробности:
$ sudo strace -e seccomp ./seccomp_lib mount -t bpf bpf /tmp
seccomp(SECCOMP_SET_MODE_FILTER, 0, {len=50, filter=0x55d8e78428e0}) = 0
--- SIGSYS {si_signo=SIGSYS, si_code=SYS_SECCOMP, si_call_addr=0xboobdeadbeef, si_syscall=__NR_mount, si_arch=AUDIT_ARCH_X86_64} ---
+++ killed by SIGSYS (core dumped) +++
Bad system callоткуда мы можем узнать, что программа была завершена из-за использования запрещенного системного вызова mount(2).
Итого, мы написали фильтр при помощи библиотеки libseccomp, уместив нетривиальный код в четыре строчки. В примере выше при наличии большого количества системных вызовов время выполнения может заметно понизиться, так как проверка — это просто список сравнений. Для оптимизации недавно в libseccomp был включен патч, добавляющий поддержку атрибута фильтра SCMP_FLTATR_CTL_OPTIMIZE. Если установить этот атрибут равным 2, то фильтр будет преобразован в программу бинарного поиска.
Если хотите посмотреть как устроены фильтры с бинарным поиском, то взгляните на простой скрипт, генерирующий такие программы на ассемблере BPF по набору номеров системных вызовов, например:
$ echo 1 3 6 8 13 | ./generate_bin_search_bpf.py
ld [0]
jeq #6, bad
jgt #6, check8
jeq #1, bad
jeq #3, bad
ret #0x7fff0000
check8:
jeq #8, bad
jeq #13, bad
ret #0x7fff0000
bad: ret #0Ничего существенно более быстрое написать не получится, так как программы BPF не могут совершать переходы по отступу (мы не можем сделать, например, jmp A или jmp [label+X]) и поэтому все переходы статические.
seccomp и strace
Все знают утилиту strace — незаменимый инструмент при исследовании поведения процессов на Linux. Однако, многие также наслышаны про проблемы с производительностью при использовании данной утилиты. Дело в том, что strace реализован при помощи ptrace(2), а в этом механизме мы не можем указать, на каком именно множестве системных вызовов нам нужно остановить процесс, т.е., например, команды
$ time strace du /usr/share/ >/dev/null 2>&1
real 0m3.081s
user 0m0.531s
sys 0m2.073sи
$ time strace -e open du /usr/share/ >/dev/null 2>&1
real 0m2.404s
user 0m0.193s
sys 0m1.800sотрабатывают за примерно одно и то же время, хотя во втором случае мы хотим трейсить только один системный вызов.
Новая опция --seccomp-bpf, добавленная в strace версии 5.3, позволяет ускорить процесс многократно и время запуска под трассировкой одного системного вызова уже сравнимо со временем обычного запуска:
$ time strace --seccomp-bpf -e open du /usr/share/ >/dev/null 2>&1
real 0m0.148s
user 0m0.017s
sys 0m0.131s
$ time du /usr/share/ >/dev/null 2>&1
real 0m0.140s
user 0m0.024s
sys 0m0.116s(Тут, конечно, есть небольшой обман в том, что мы трейсим не основной системный вызов этой команды. Если бы мы трейсили, например, newfsstat, то strace тормозил бы так же сильно, как и без --seccomp-bpf.)
Как же работает эта опция? Без нее strace подключается к процессу и запускает его при помощи PTRACE_SYSCALL. Когда управляемый процесс запускает (любой) системный вызов, управление передается strace, который смотрит на аргументы системного вызова и запускает его при помощи PTRACE_SYSCALL. Через некоторое время процесс завершает системный вызов и при выходе из него управление опять передается strace, который смотрит на возвращаемые значения и запускает процесс при помощи PTRACE_SYSCALL, и т.п.

При помощи seccomp, однако, этот процесс можно оптимизировать именно так, как нам хотелось бы. Именно, если мы хотим смотреть только на системный вызов X, то мы можем написать BPF фильтр, который для X возвращает значение SECCOMP_RET_TRACE, а для не интересующих нас вызовов — SECCOMP_RET_ALLOW:
ld [0]
jneq #X, ignore
trace: ret #0x7ff00000
ignore: ret #0x7fff0000В этом случае strace изначально запускает процесс как PTRACE_CONT, на каждый системный вызов отрабатывает наш фильтр, если системный вызов не X, то процесс продолжает работу, но если это X, то seccomp передаст управление strace, который посмотрит на аргументы и запустит процесс как PTRACE_SYSCALL (так как в seccomp нет возможности запустить программу на выходе из системного вызова). Когда системный вызов вернется, strace перезапустит процесс при помощи PTRACE_CONT и будет ждать новых сообщений от seccomp.

При использовании опции --seccomp-bpf есть два ограничения. Во-первых, не получится присоединиться к уже существующему процессу (опция -p программы strace), так как это не поддерживается seccomp. Во-вторых, нет возможности не смотреть на дочерние процессы, так как seccomp фильтры наследуются всеми дочерними процессами без возможности отключить это.
Чуть больше подробностей о том как именно strace работает с seccomp можно узнать из недавнего доклада. Для нас же наиболее интересным фактом является то, что классический BPF в лице seccomp находит применения до сих пор.
xt_bpf
Отправимся теперь обратно в мир сетей.
Предыстория: давным-давно, в 2007 году, в ядро был добавлен модуль xt_u32 для netfilter. Он был написан по аналогии с еще более древним классификатором трафика cls_u32 и позволял писать произвольные бинарные правила для iptables при помощи следующих простых операций: загрузить 32 бита из пакета и проделать с ними набор арифметических операций. Например,
sudo iptables -A INPUT -m u32 --u32 "6&0xFF=1" -j LOG --log-prefix "seen-by-xt_u32"Загружает 32 бита заголовка IP, начиная с отступа 6, и применяет к ним маску 0xFF (взять младший байт). Это — поле protocol заголовка IP и мы его сравниваем с 1 (ICMP). В одном правиле можно комбинировать много проверок, а еще можно выполнять оператор @ — перейти на X байт вправо. Например, правило
iptables -m u32 --u32 "6&0xFF=0x6 && 0>>22&0x3C@4=0x29"проверяет, не равен ли TCP Sequence Number 0x29. Не буду дальше вдаваться в подробности, так как уже ясно, что руками такие правила писать не очень удобно. В статье BPF — the forgotten bytecode, есть несколько ссылок с примерами использования и генерации правил для xt_u32. См. также ссылки в конце этой статьи.
Начиная с 2013 года модуль вместо модуля xt_u32 можно использовать основанный на BPF модуль xt_bpf. Всем дочитавшим до сюда уже должен быть ясен принцип его работы: запускать байткод BPF в качестве правил iptables. Создать новое правило можно, например, так:
iptables -A INPUT -m bpf --bytecode <байткод> -j LOGздесь <байткод> — это код в формате вывода ассемблера bpf_asm по-умолчанию, например,
$ cat /tmp/test.bpf
ldb [9]
jneq #17, ignore
ret #1
ignore: ret #0
$ bpf_asm /tmp/test.bpf
4,48 0 0 9,21 0 1 17,6 0 0 1,6 0 0 0,
# iptables -A INPUT -m bpf --bytecode "$(bpf_asm /tmp/test.bpf)" -j LOGВ этом примере мы фильтруем все UDP пакеты. Контекст для BPF программы в модуле xt_bpf, конечно, указывает на данные пакета, в случае iptables — на начало заголовка IPv4. Возвращаемое значение из BPF программы булево, где false означает, что пакет не совпал.
Понятно, что модуль xt_bpf поддерживает более сложные фильтры, чем в примере выше. Давайте посмотрим на настоящие примеры от компании Cloudfare. До недавнего времени они использовали модуль xt_bpf для защиты от DDoS атак. В статье Introducing the BPF Tools они рассказывают как (и почему) они генерируют BPF фильтры и публикуют ссылки на набор утилит для создания таких фильтров. Например, при помощи утилиты bpfgen можно создать BPF программу, которая матчит DNS-запрос на имя habr.com:
$ ./bpfgen --assembly dns -- habr.com
ldx 4*([0]&0xf)
ld #20
add x
tax
lb_0:
ld [x + 0]
jneq #0x04686162, lb_1
ld [x + 4]
jneq #0x7203636f, lb_1
ldh [x + 8]
jneq #0x6d00, lb_1
ret #65535
lb_1:
ret #0В программе мы сначала загружаем в регистр X адрес начала строки \x04habr\x03com\x00 внутри UDP-датаграммы и потом проверяем запрос: 0x04686162 <-> "\x04hab" и т.д.
Немного позже Cloudfare опубликовала код компилятора p0f → BPF. В статье Introducing the p0f BPF compiler они рассказывают о том, что такое p0f и как преобразовывать p0f сигнатуры в BPF:
$ ./bpfgen p0f -- 4:64:0:0:*,0::ack+:0
39,0 0 0 0,48 0 0 8,37 35 0 64,37 0 34 29,48 0 0 0,
84 0 0 15,21 0 31 5,48 0 0 9,21 0 29 6,40 0 0 6,
...В настоящий момент Cloudfare больше не использует xt_bpf, так как они переехали на XDP — один из вариантов использования новой версии BPF, см. L4Drop: XDP DDoS Mitigations.
cls_bpf
Последний из примеров использования классического BPF в ядре — это классификатор cls_bpf для подсистемы контроля трафика в Linux, добавленный в Linux в конце 2013 года и концептуально заменивший древний cls_u32.
Мы, однако, не будем сейчас описывать работу cls_bpf, так как с точки зрения знаний о классическом BPF это нам ничего не даст — мы уже познакомились со всей функциональностью. К тому же, в последующих статьях, рассказывающих об Extended BPF, мы еще не раз встретимся с этим классификатором.
