[Из песочницы] Add-on к Авито. Стартап или пример архитектуры
 Предыстория
ПредысторияЧестно говоря, никогда ранее не покупал б/у вещи на досках объявлений. Но когда случился очередной экономический кризис и нужда заставила, пришлось обратить свое внимание на Авито.
При осмотре предложений сразу бросилось в глаза, что часть объявлений выглядит сомнительными по ряду признаков: заниженная цена, неточное описание и т.п., по которым складывалось впечатление, что или продают не то, что предлагают, или сами не знают что продают. В памяти сразу возник образ из прошлого — барахолки 90-х годов, с которых можно было вернуться как с покупками, так и с пустыми карманами или порезанной сумкой.
Как известно, Авито не дает информацию о других объявлениях продавца, поэтому в тексте объявления часто используют ключевые слова или хэштеги, которые покупатель может использовать для поиска. Но надо заметить, что администрация Авито не приветствует наличие в тексте объявления любой информации, не относящейся к предмету продажи, о чем говорится в правилах размещения. При нарушении правил размещения Авито может заблокировать как объявление, так и аккаунт продавца.
Поисковик выдал мне несколько сайтов, паразитирующих на Авито и других досках объявлений, преимущественно связанных с подержанными автомобилями. В большинстве своем они предлагают поиск объявлений по номеру телефона продавца в базе предварительно скачанных объявлений. Все они имеют недостатки, немаловажные для меня: замысловатый интерфейс, платность услуги, обновление данных с определенным лагом.
Разделяя мнение Стивена Леви о свободном доступе к информации, было решено проанализировать Авито на предмет разработки собственного сервиса sravnito.ru с блэкджеком и всеми делами, а именно: с простым интерфейсом и бесплатным доступом.
На основании проведенного анализа были определены основные атрибуты объявления:
- название
- дата публикации
- цена
- местонахождение
- телефонный номер (либо изображение номера, либо хэш от него, либо распознанное OCR значение)
Архитектура
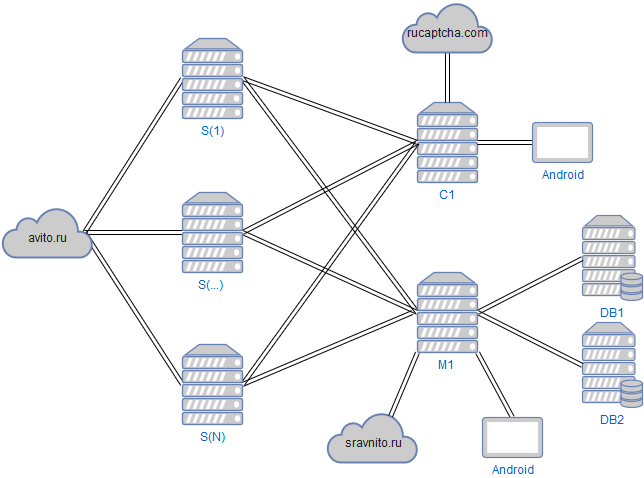
Теперь непосредственно об архитектуре программного комплекса, на котором основан сервис поиска всех объявлений продавца:
Хранилище
В качестве хранилища для хранения объявлений и их скриншотов используется MySQL (Maria DB) с движком InnoDB.
В DB1 хранятся объявления с основными атрибутами. Для сокращения объема памяти, занимаемого данными, для текстовых полей используется тип VARCHAR, так как их длина разнится от объявления к объявлению. Ежедневно добавляется примерно полмиллиона строк, среди которых как сами объявления, так и логи и служебная информация. При такой динамике хранилище по праву можно будет относить к Big Data. Из особенностей настройки можно выделить следующие параметры:
max_heap_table_size = 512M
innodb_buffer_pool_size = 3G
Таблицы в куче используются для оптимизации запросов из нескольких больших таблиц, когда сначала данные выбираются во временную таблицу:
CREATE TEMPORARY TABLE _temp_table ENGINE=MEMORY AS (
SELECT field
FROM table
WHERE key = i_key
LIMIT i_limit);
которая потом соединяется с другой:
SELECT table.*
FROM table
JOIN _temp_table
ON table.field = _temp_table.field;
В DB2 хранятся скриншоты объявлений как они выглядят для пользователя браузера. Перед записью скриншоты сжимаются в JPEG с quality = 5, что обеспечивает размер файла с изображением равный примерно 20Кб. Принято считать, что при размере BLOB не более 200Кб, производительность хранения файлов в MySQL ничем не уступает NoSQL-хранилищам, что позволяет оставаться в зоне комфорта реляционной СУБД со всеми ее преимуществами. Настолько сжатый скриншот, несмотря на минимальное качество изображения, позволяет пользователю убедиться, что заданное объявление действительно существовало, и разглядеть хотя бы схематично изображение товара.
Вся логика реализована в хранимых процедурах, чтобы инкапсулировать зависимый от структуры данных код в самой СУБД. Таким образом, клиенты СУБД имеют полномочия только для доступа к хранимым процедурам, которые являются идемпотентными. Как дополнительный плюс получаем отсутствие возможности осуществления SQL-инъекций.
API к хранилищу
Сервер M1 реализован как микросервис на golang и предоставляет RESTful API для сохранения объявлений, скриншотов, а также для чтения данных выводимых на странице сервиса поиска объявлений. Нет причин использовать какие-либо фреймворки или внешние библиотеки для реализации RESTful на golang, поэтому используются только стандартные библиотеки, кроме одной:
import (
"database/sql"
"encoding/json"
"net/http"
_ "github.com/go-sql-driver/mysql"
)
Обрабатываются GET и POST запросы от клиентов и вызываются соответствующие хранимые процедуры БД DB1, DB2.
Загрузчики объявлений
Объявления загружаются с сайта Авито загрузчиками S (1)-S (N), написанными на Java с использованием библиотеки Selenium WebDriver. Получив с Авито атрибуты объявления и скриншот, загрузчик обращается к серверу M1 для передачи данных. Также реализована обратная связь для управления загрузчиками, которые периодически опрашивают сервер M1 на предмет команд, например «стоп», «старт».
Captcha
Для разгадывания капчи, которую иногда запрашивает Авито, существует сервер C1, по аналогии с сервером M1 реализованный на golang и предоставляющий RESTful API. Разгадывание капчи осуществляется двумя способами:
- с помощью сервиса rucaptcha.com
- вручную в приложении для Android
Для связи с rucaptcha.com используется их API. Для ручного разгадывания используется написанное на Java приложение Android, которое выводит изображение и принимает ответ. Сервер C1 принимает решение о перенаправлении капчи на rucaptcha.com или в приложение Android в зависимости от количества запросов, накопившихся в очереди. Получив разгадку капчи, сервер C1 отправляет ответ запросившему его загрузчику.
Мониторинг
По аналогии с приложением Android для разгадывания капчи, существует приложение для мониторинга. Приложение Android для мониторинга обращается к серверу M1, который в свою очередь обращается к БД где агрегируются логи, на основе которых можно судить о количестве загруженных объявлений, сбоях в работе и т.п.
Заключение
Дальнейшее развитие сервиса может быть таким:
- Создание загрузчиков для других досок объявлений, что позволит делать кросс-поиск всех объявлений одного продавца
- Использование комплекса для обработки других данных, например загрузка из соцсетей для поиска всех постов по имени аккаунта
И в том и в другом случае разработке подлежат только загрузчики, которые легко интегрируются с серверами M1 и C1. Доработка других частей системы не потребуется.
Если сделать API серверов M1, C1 публичным с авторизацией и добавить в структуру БД ключевое поле для разделения по клиентам, то можно предоставлять услугу по хранению данных и обработке капчи как SaaS. Данные клиента можно хранить в BLOB в виде JSON, доработав при этом БД с хранимыми процедурами и интерфейс API.
Что можно сказать о выбранных технологиях:
- MySQL — классика жанра, без комментариев
- Java — загрузчики можно запускать на кофеварках и холодильниках
- golang — очень быстро разрабатываются микросервисы, легко деплоится путем копирования единственного бинарника на сервер
Буду признателен за комментарии и обсуждение.
Комментарии (17)
14 декабря 2016 в 15:47
+6↑
↓
> собственного сервиса sravnito.ruВы хотели сказать «собственного паразитирующего на авито сервиса sravnito.ru».
> с простым интерфейсом и бесплатным доступом
и бесплатной рекламой Google Adwords
14 декабря 2016 в 22:23
+1↑
↓
Паразитируют, когда просят 300 рублей за «пробивку».
Когда все бесплатно с рекламой для поддержки оплаты vps — не считаю что это так14 декабря 2016 в 22:31
0↑
↓
И чем же он вас паразитировал? Комментарий вида: лишь бы придраться к чему нибудь.14 декабря 2016 в 22:31
0↑
↓
Что плохого в бесплатной рекламе Google Adwords?
14 декабря 2016 в 17:51
0↑
↓
При такой динамике хранилище по праву можно будет относить к Big Data.
innodb_buffer_pool_size = 3G
Как то не стыкуется.14 декабря 2016 в 22:17
0↑
↓
Разве Big Data определяется именно размером кучи под данные, а не в целом объемами?14 декабря 2016 в 22:41
0↑
↓
Я не об определении Big Data, а о настройках mysql сервера, которые вы отдельно выделили. Думаю, что эта старая статья Петра Зайцева более точно пояснит мою мысль. Объем всех ваших данных в innodb таблицах явно больше 3Gb. И оперативной памяти на вашем DB сервере явно больше 4Gb.14 декабря 2016 в 22:47
0↑
↓
Спасибо за ссылку, почитаю и подумаю что ответить.
Данных именно по объявлениям без учета скриншотов в данный момент >50Gb, а оперативки 4 Gb. Понятно, что хранить все данные в оперативке нереально в данный момент.14 декабря 2016 в 23:15
0↑
↓
В части использования пула, такие данные, то есть видно, чтоYou need buffer pool a bit (say 10%) larger than your data (total size of Innodb TableSpaces) because it does not only contain data pages — it also contain adaptive hash indexes, insert buffer, locks which also take some time.
указанные данные вмещаются в пул с большим запасом
 marenkov
marenkov
14 декабря 2016 в 18:43
+1↑
↓
Вступительная часть статьи вводит в заблуждение — полный тест имеет мало общего со вступлением. Вы бы хотя бы написали, как будете бороться с мошенниками на своем сайте. Показывать все объявления продавца в этом не поможет.14 декабря 2016 в 22:19
0↑
↓
Смысл в том, что если по ссылке на объявление либо номеру телефона нашлось, допустим 5 топовых видеокарт в разных регионах, то очевидно, что здесь что то не чисто. Если же нашлось много объявлений, например про коллекционирование или детскую одежду,- то похоже на правду
14 декабря 2016 в 22:19
0↑
↓
Вбил ссылку на объявление, ничего не нашлось. Хотя с этим номером телефона есть еще объявления. По номеру телефона нашлось несколько объявлений, но не все.14 декабря 2016 в 22:20
0↑
↓
Для любительского проекта неплохо, что «нашлось несколько объявлений», так как не всегда хватает мощностей, чтобы успевать за всеми объявлениями
14 декабря 2016 в 22:24
0↑
↓
Хотелось бы услышать комментарии по архитектуре и технологиям, а не насчет того, что кто-то не нашел все объявления HellMaster_HaiL
HellMaster_HaiL
14 декабря 2016 в 22:31
0↑
↓
Если честно, ожидал что речь пойдет об каком либо плагине для браузера, который при открытии страницы с объявлением рядом с именем или аватаркой автора большими красными буквами пишет слово «мошенник» и ссылку на пруфы…14 декабря 2016 в 22:40
0↑
↓
Технически плагин к браузеру реализуем, так как все данные есть в БД, но понимать сомнительность объявлений возможно только косвенно непосредственно пользователю, по признакам указанным в комментарии выше
15 декабря 2016 в 02:14
0↑
↓
Java приложение Android, которое выводит изображение и принимает ответ.
Это вы сами набиваете?
