[Перевод] Пишем наш первый модуль для ядра Linux

Пожалуй, ядро Linux сегодня — это самый вездесущий (и по-прежнему недооцененный) программный код. На нем основаны все дистрибутивы Linux (что очевидно), но это далеко не все. Кроме того, на ядре Linux работает огромная масса встроенного ПО практически везде. У вас есть микроволновка? Вероятно, она работает на ядре Linux. Посудомоечная машина? Тоже. Вы состоятельный человек и приобрели автомобиль Tesla? Может быть, вы найдете в ней какие-то баги и исправите их, в таком случае, можете отправить патч им на Github, где лежит код для модели S и модели X. Электронная начинка МКС, благодаря которой станция не падает на Землю смертельно опасным и разрушительным огненным болидом — конечно же, тоже работает под Linux. Ядро легковесно. Наверное, именно поэтому оно так хорошо работает в условиях низкой гравитации.
Ядро Linux проходит такой цикл разработки, который, честно говоря, безумен. Есть статистика по патчу версии ядра 5.10, судя по которой, в этом релизе участвовали 252 новых автора, внесшие и зафиксировавшие изменения в репозитории (и это наименьшее количество контрибьюторов со времен версии ядра 5.6). А новые релизы выходят каждые 9 недель. С учетом всего сказанного, ядро Linux действительно является прочной основой для солидной части современной вычислительной техники, но оно ни в коем случае не архаично. Все это хорошо, но что делать, если вы хотите сами покопаться в ядре и, может быть, даже сами написать для него какой-либо код? Такая затея может оказаться несколько нудной, поскольку именно эта область программирования мало затрагивается в большинстве школ и буткэмпов. Кроме того, это не тот случай, как с любым фреймворком JavaScript, «вырвавшимся в топ» в текущем месяце. Он сваливается как снег на голову, поэтому нельзя просто так взять и зайти на StackOverflow, а там найти с добрый миллион записей, которые позволят вам распутать любые проблемы.
Так и живем. Итак, вас интересует собственный проект уровня «hello world», который положит начало самому долговечному опенсорсному проекту современности? Или вы хотите попробовать теорию операционных систем, хотя бы в малых дозах? Вам нравится программировать на языке, созданном в 1970-е, он наполняет вас чувством глубокого удовлетворения, когда можно сделать буквально что угодно — и оно заработает? Отлично, поскольку, честно говоря, я и придумать не могу лучшего времяпрепровождения.
Учтите: в этой статье я исхожу из того, что вы знаете, как настроить виртуальную машину на Ubuntu, и умеете это делать. В открытом доступе есть масса ресурсов, где изложен этот процесс, так что открывайте ваш любимый менеджер виртуальных машин и за дело. Также я полагаю, что вы хотя бы немного знакомы с C, ведь именно на этом языке написано ядро. Поскольку мы собираемся написать модуль уровня «hello world», никаким сложным программированием мы здесь заниматься не будем, но и я не буду давать какой-либо вводной информации о концепциях языка. Как бы то ни было, код планируется настолько простой, что должен быть самоочевидным. После всех этих преуведомлений — поехали!
Пишем простой модуль
Для начала нужно дать дефиницию модулю ядра. Типичный модуль, также именуемый драйвером, в некоторой степени похож на API, но занимает промежуточную нишу между хардом и софтом. Смотрите, в большинстве операционных систем все дела творятся всего в двух местах: пространство ядра и пользовательское пространство. Linux определенно устроен именно так, и Windows — тоже. В пользовательском пространстве делаются дела, касающиеся пользовательских занятий — например, прослушивание песни на Spotify. В пространстве ядра делаются все низкоуровневые вещи, подкапотная работа ОС. Если вы слушаете песню на Spotify, то компьютер должен установить соединение с серверами этого сайта, а на компьютере должен заработать механизм, принимающий пакеты с этого ресурса, извлекающий из них данные и, наконец, передающий их в динамик или наушники, так, чтобы вы услышали звук. Вот что происходит в пространстве ядра. Один из задействованных здесь драйверов — это программа, позволяющая пакетам проходить через ваш сетевой порт, после чего их содержимое преобразуется в музыку. У самого драйвера должен быть API-подобный интерфейс, через который приложения пользовательского пространства (или даже приложения из пространства ядра) могут вызывать его функции и извлекать эти пакеты.
К счастью, наш модуль будет устроен совершенно иначе, поэтому не огорчайтесь. Он даже не будет взаимодействовать ни с каким железом. Многие модули полностью основаны на софте. Хороший пример такого рода — используемый в ядре планировщик процессов, указывающий, сколько ядер вашего ЦП будут работать над каждым действующим процессом в любой конкретный момент. Модуль, работающий исключительно с софтом, также лучше всего подходит для первого ознакомления с темой. Запускайте виртуальную машину, открывайте окно консоли при помощи Ctrl+Alt+T, и дальше — дело техники.
sudo apt update && sudo apt upgrade
Так можно убедиться, что вы пользуетесь актуальной версией софта. Далее давайте получим новые программные пакеты, которые понадобятся нам для нашего дела. Выполняем
sudo apt install gcc make build-essential libncurses-dev exuberant-ctags
Теперь можно и приступать к программированию. Сначала все легко, мы просто вставляем следующий код в файл исходников. Мой я положил в папку Documents и назвал его dvt-driver.c
#include
#include
#include
#include
#include
// Module metadata
MODULE_AUTHOR("Ruan de Bruyn");
MODULE_DESCRIPTION("Hello world driver");
MODULE_LICENSE("GPL");
// Custom init and exit methods
static int __init custom_init(void) {
printk(KERN_INFO "Hello world driver loaded.");
return 0;
}
static void __exit custom_exit(void) {
printk(KERN_INFO "Goodbye my friend, I shall miss you dearly...");
}
module_init(custom_init);
module_exit(custom_exit); Обратите внимание: конкретно в данный момент нам не требуются все эти включения, но достаточно скоро мы все их задействуем. Далее этот код нужно скомпилировать. Создаем новый файл Makefile там же, где лежит исходный код, и записываем в этот файл следующее содержимое:
obj-m += dvt-driver.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) cleanОткройте окно консоли в том каталоге, где лежат два вышеупомянутых файла, и выполните make. В этот момент вы уже должны видеть в консоли некоторый вывод, описывающий, как компилируется ваш модуль, и весь этот процесс в итоге формирует файл dvt-driver.ko. Это ваш полнофункциональный скомпилированный модуль ядра. Давайте загрузим этот прорывной образец интеллектуальной собственности в ядро, попробуем? Сам по себе он тут погоды не сделает. В том же каталоге, где находится ваш код, выполните:
sudo insmod dvt-driver.ko
— и тогда ваш драйвер будет вставлен в ядро. Можно в этом убедиться, выполнив lsmod, эта команда выведет список всех модулей, в настоящее время находящихся в ядре. Среди них вы увидите dvt_driver. Обратите внимание: при загрузке в имени файла (вашего модуля) ядро заменяет дефисы на нижние подчеркивания. Если хотите от этого избавиться, можете выполнить:
sudo rmmod dvt_driver
В исходном коде мы также хотим организовать логирование, чтобы знать, нормально ли загрузился драйвер, поэтому выполним в окне терминала команду dmesg. Эта команда — шорткат, она позволяет вывести на экран логи ядра, а также немного их причесать для большей удобочитаемости. В самых последних строках вывода от dmesg должны быть сообщения драйвера, например, «hello world driver has been loaded» (драйвер hello world загружен) и т.д. Обратите внимание: случается запаздывание при выводе функциональных сообщений init и exit от драйверов, но, если дважды вставить и удалить модуль, то вы должны увидеть все эти сообщения записанными в логах. Если вы хотите посмотреть «вживую», как логируются эти сообщения, то откройте второе окно терминала и выполните в нем dmesg --follow. Далее, когда в другом окне терминала вы сначала вставите ваш драйвер, а затем удалите его — увидите, как начнут всплывать следующие сообщения.
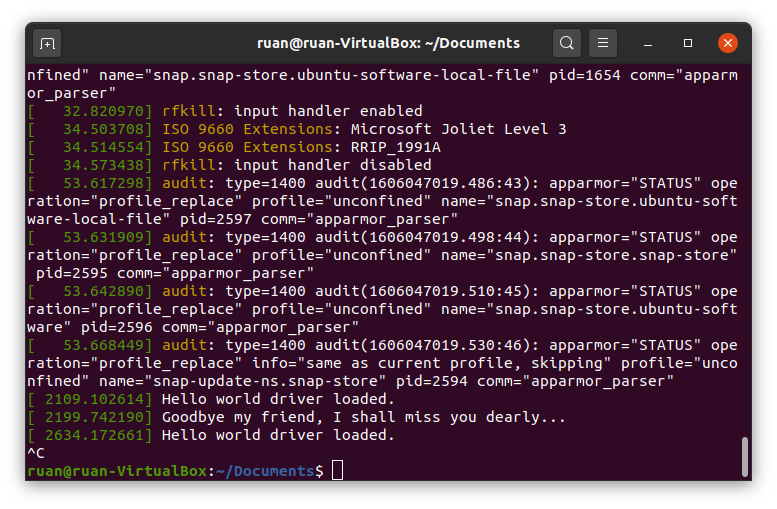
Мой вывод dmesg — follow после того, как я дважды вставил и удалил модуль
Итак, давайте отметим, что у нас уже наработано. Исходный код начинается с метаданных, описывающих модуль. Можно обойтись без указания автора и т.д., но вполне можете поставить там и свое имя. Компилятор также строго предупредит вас, если вы не включите код лицензии, а поскольку я всю жизнь патологически желаю одобрения и принятия практически от «всего, что движется», я просто обязан поставить вышеуказанный лицензионный код. Если вас не коробят такие психологические метания, то, пожалуй, еще не мешает отметить, что участники поддержки ядра весьма остерегаются брать код, не являющийся опенсорсным — и очень внимательны к таким деталям как лицензия. В прошлом большие компании не позволяли вставлять в исходный код ядра проприетарные модули. Фу такими быть. Будьте хорошими. Пишите свободное ПО. Пользуйтесь опенсорсными лицензиями.
Теперь сделаем наши собственные функции init и exit. Всякий раз, когда модуль загружается в ядро, выполняется функция init этого модуля — и наоборот, когда он удаляется из ядра, выполняется его функция exit. Наши функции не так много делают, просто записывают текст в логи ядра. Функция printk() — это используемая в ядре версия классической функции print из языка C. Очевидно, в ядре нет никакого терминала или экрана, куда можно было бы выводить произвольные вещи, поэтому именно функция printk() выводит логи ядра. Есть макрос KERN_INFO для логирования общей информации. Также можно воспользоваться таким макросом как KERN_ERROR в случае, если возникнет ошибка, этот макрос изменит форматирование вывода в dmesg. Как бы то ни было, две функции init и exit зарегистрированы в двух последних строках исходного кода. Это придется сделать; больше вашему драйверу никак не узнать, какие функции выполнять. Кроме того, можете назвать их как хотите, важно только, чтобы их сигнатура (аргументы и возвращаемый тип) были точно такими, как использовал я.
Наконец, есть еще и Makefile. Во многих опенсорсных проектах используется утилита GNU Make, при помощи которой компилируются библиотеки. Как правило, она используется с библиотеками, написанными на C/C++ и просто помогает вам автоматизировать компиляцию кода. Указанная здесь Makefile — это стандартный инструмент, позволяющий скомпилировать модуль. Первая строка прикрепляет тот файл.o, который еще предстоит скомпилировать, к переменной obj-m. Ядро также компилируется таким же образом и многократно прикрепляет файлы.o к этой переменной до компиляции. В следующей строке немного пошаманим. Видите, правила и команды для сборки модулей ядра уже определены в Makefile, которая поставляется вместе с ядром. Нам не приходится писать собственные правила, можем воспользоваться теми, что прописаны в ядре… и именно это мы и сделаем. В аргументе -C мы укажем на корневой каталог с нашими исходниками ядра. Затем прикажем нацелиться на рабочий каталог нашего проекта и скомпилировать модули. Вуаля. GNU Make — неожиданно мощный инструмент компиляции, с его помощью можно автоматизировать компиляцию какого угодно проекта, а не только написанного на C/C++. Если хотите поподробнее об этом почитать, вот книга, абсолютно безвозмездно (то есть даром).
Запись /proc
Переходим к самой сочной части этого поста. Записи логов о событиях в ядре — это, конечно, очень хорошо, но не ради этого пишутся модули-шедевры. Выше в этой статье я упоминал, что модули ядра обычно действуют в качестве API для программ пользовательского пространства. Прямо сейчас наш драйвер еще ничего подобного не делает. В Linux есть очень аккуратный способ обработки таких взаимодействий: работа с абстракцией «все есть файл».
Чтобы на это посмотреть, откройте еще одно окно терминала и выполните cd /proc. Выполнив ls, вы сразу увидите длинный список файлов. Теперь выполните cat modules — и увидите на экране текст. Знакомо выглядит? Должно; здесь присутствуют все модули, представленные командой lsmod, которые вы уже запускали ранее. Давайте попробуем cat meminfo. Теперь у нас есть информация о том, как виртуальная машина использует память. Круто. Последняя команда, которую мы попробуем: ls -sh. Она в виде списка выводит размер каждого файла, а также его имя и… подождите, что? Что это за бред?
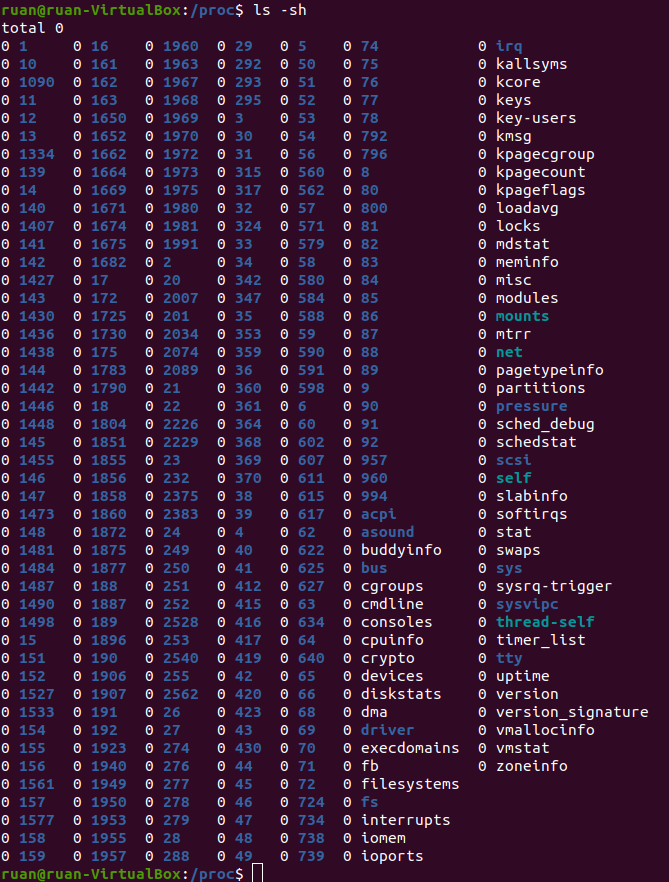
Все они размером по 0. Ноль — это ничто. И пусть даже на эти файлы не потрачено ни единого бита, мы просто читаем их содержимое?… Да, на самом деле, тут все верно. Смотрите, /proc — это каталог с процессами, можно сказать, центральное место, откуда приложения пользовательского пространства получают информацию о модулях ядра (а иногда могут получать контроль над ними). В Ubuntu аналог Task Manager называется System Monitor, его можно запустить, нажав клавишу с указанием ОС на клавиатуре и введя «system» — в этот момент уже должен отобразиться быстрый переход к System Monitor. System Monitor показывает статистику: например, какие процессы выполняются, как используется ЦП, память, т.д. Всю эту информацию он получает, считывая из каталога /proc специальные файлы, например, meminfo.
Давайте добавим в наш драйвер следующий функционал: сделаем, чтобы у нас была наша собственная запись в /proc. Мы поступим так, чтобы всякий раз, когда приложение из пользовательского пространства будет оттуда что-то считывать, оно станет выводить нам приветственное сообщение hello world. Замените весь код под метаданными нашего модуля на следующий:
static struct proc_dir_entry* proc_entry;
static ssize_t custom_read(struct file* file, char __user*
user_buffer, size_t count, loff_t* offset)
{
printk(KERN_INFO "calling our very own custom read method.");
char greeting[] = "Hello world!\n";
int greeting_length = strlen(greeting);
if (*offset > 0)
return 0;
copy_to_user(user_buffer, greeting, greeting_length);
*offset = greeting_length;
return greeting_length;
}
static struct file_operations fops =
{
.owner = THIS_MODULE,
.read = custom_read
};
// Наши собственные методы init и exit
static int __init custom_init(void) {
proc_entry = proc_create("helloworlddriver", 0666, NULL, &fops);
printk(KERN_INFO "Hello world driver loaded.");
return 0;
}
static void __exit custom_exit(void) {
proc_remove(proc_entry);
printk(KERN_INFO "Goodbye my friend, I shall miss you dearly...");
}
module_init(custom_init);
module_exit(custom_exit);Теперь удалите драйвер из ядра, перекомпилируйте и вставьте в ядро новый модуль.ko. Выполните cat /proc/helloworlddriver — и должны увидеть, как наш драйвер выводит в окно терминала приветственное сообщение hello world. Как по мне, очень симпатично. Но увы, команда cat, пожалуй, слишком проста, чтобы как следует донести смысл того, чем мы здесь занимаемся — поэтому давайте напишем для пользовательского пространства наше собственное приложение, которое будет взаимодействовать с этим драйвером. Поставьте следующий код Python в скрипт, который можете положить в любом каталоге (мой файл я назвал hello.py):
kernel_module = open('/proc/helloworlddriver')
greeting = kernel_module.readline();
print(greeting)
kernel_module.close()
Этот код должен быть самоочевидным: как видите, именно так файловый ввод/вывод выполнялся бы в любом языке программирования. Файл /proc/helloworlddriver — это наш API для того модуля ядра, который мы только что написали. Выполнив python3 hello.py, вы увидите, как наше приветствие выводится в окне терминала. Круть.
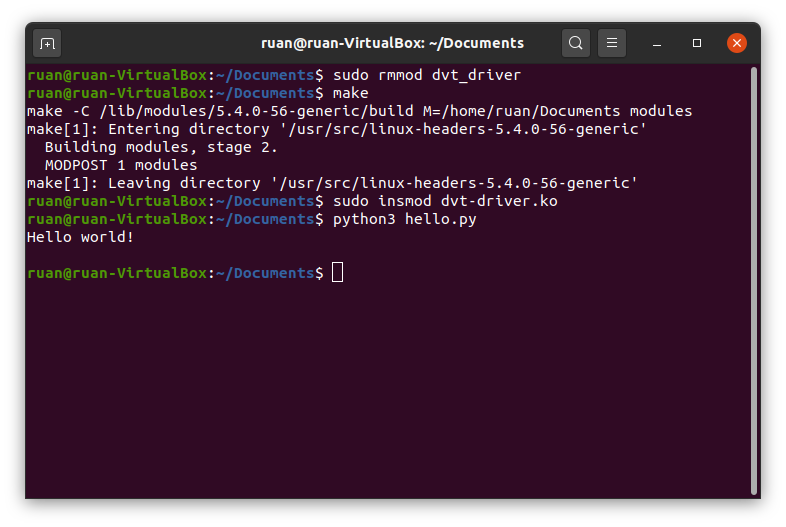
Результат выполнения скрипта Python после удаления, перекомпиляции и вставки модуля в ядро.
В нашем коде мы сделали собственную функцию read. Как вы уже догадываетесь, можно и просто переопределить функцию write, если вашему модулю требуется ввод из пользовательского пространства. Например, если у вас есть драйвер, управляющий скоростью вращения вентиляторов у вас в ПК, можете дать ему функцию write, в которой мы будем записывать в файл процентное значение в диапазоне от 0 до 100 — и, ориентируясь на него, ваш драйвер соответствующим образом откорректирует скорость вентилятора. Если вам интересно, как именно работает такое переопределение функции — читайте следующий раздел. Если нет — переходите прямо к заключительной части статьи.
Бонус-раздел — Как вообще все это работает?
В этом разделе я обрисую некоторые аспекты, которые могут быть вам любопытны: опишу, как именно устроено переопределение функций read/write для записи /proc. Чтобы изучить этот вопрос, нам нужно будет серьезно углубиться в теорию операционных систем и воспользоваться ассемблером в качестве аналогии.
В ассемблере у вашей программы есть стек, в котором отслеживается история переменных, создаваемых вами в процессе выполнения. Эта структура немного отличается от стека в том каноническом смысле, в каком он понимается в информатике; однако, поскольку в эту структуру можно задвигать элементы и выталкивать из нее элементы, также можно обращаться и к произвольным элементам в этом стеке –, а не только к верхнему –, а также изменять и считывать их. Хорошо, допустим, вы определяете в коде ассемблера функцию с двумя аргументами. Вы не просто передаете эти переменные при вызове функции, нет уж. Передача переменных в квадратных скобках к функциям — это задачка для любителей, копирующих код Python для чатбота, причем, код, взятый из онлайнового туториала. Программисты, работающие с ассемблером – это ребята совершенно иного масштаба, их ремесло позволило посадить Аполлон-11 на Луну. Как говорится, без труда не вытащишь рыбку из пруда. Прежде, чем вызвать функцию с двумя аргументами, требуется задвинуть эти аргументы в стек. Затем вызываете функцию, которая, как правило, читает аргументы, начиная с вершины стека и далее из конца в начало, а использует их по мере надобности. Здесь настоящее минное поле, так как ничего не стоит записать ваши аргументы в стек в неверном порядке и в результате ваша функция воспримет их как тарабарщину.
Упоминаю об этом, так как и в вашей операционной системе код выполняется примерно такими же способами. В операционной системе есть собственный стек, где отслеживаются переменные, а когда ядро вызывает функцию операционной системы, эта функция ищет аргументы в верхней части стека и затем выполняется. Если вы хотите считать файл с диска, то вызываете функцию считывания с несколькими аргументами, эти аргументы помещаются в стек ядра, а затем вызывается считывающая функция, чтобы полностью или частично считать файл с диска. Ядро ведет учет всех своих функций в огромной таблице, каждая из записей в которой содержит имя функции и адрес в памяти, по которому эта функция хранится. Именно здесь нам пригодятся наши собственные функции. Смотрите, пусть даже взаимодействия нашего модуля осуществляются через файлы, нет такого железного правила, согласно которому при считывании из этого файла должна была бы вызываться конкретная считывающая функция. Считывающая функция — это просто адрес в памяти, который подыскивается в таблице. Можно переопределить, какую именно функцию в памяти мы будем вызывать в ситуации, когда программа из пользовательского пространства будет считывать запись /proc в нашем модуле — и именно это мы делаем! В структуре file_operations мы присваиваем атрибут .read нашей функции custom_read, а затем регистрируем с ней запись /proc. Когда вызов считывающей функции приходит из приложения пользовательского пространства (приложение написано на Python), все может выглядеть так, будто вы считываете файл с диска, передаете все нужные аргументы в стек ядра, и в последний момент вместо нашей функции почему-то вызывается функция custom_read, расположенная в памяти по тому адресу, который мы сами сообщили ядру. Это работает, поскольку наша функция custom_read принимает в точности те же аргументы, что и при считывании с диска, поэтому из стека ядра считываются нужные аргументы в правильном порядке.
В данном случае необходимо помнить, что приложения пользовательского пространства будут расценивать нашу запись /proc так, словно это файл на диске, и считывать ее, и записывать в нее будут именно в таком ключе. Поэтому именно на нас ложится бремя обеспечить, что это взаимодействие будет соблюдаться. Наш модуль должен вести себя точно, как обычный файл на диске, хотя, он таким файлом и не является. В большинстве языков программирования считывание любого файла обычно идет по кусочкам. Допустим, программа считывает по 1024 байта за раз. Вы хотите прочитать из файла первые 1024 байта и поместить их в буфер, и после этой операции в буфере будут содержаться байты 0–1023. Операция считывания вернет 1024, тем самым сообщив нам, что 1024 байта было считано успешно. Затем будут считаны следующие 1024 байта, и в буфере будут содержаться байты 1024–2047. Рано или поздно мы достигнем конца нашего файла. Может быть, и в случае с последним фрагментом мы запросим 1024 байта, а останется там всего 800 байт. Поэтому считывающая функция вернет 800 и поместит в буфер эти последние 800 байт. Наконец, считывающая функция запросит следующий кусок, но содержимое нашего файла уже будет прочитано полностью. Тогда считывающая функция вернет 0. Когда это произойдет, программа «поймет», что достигнут конец файла, и прекратит попытки считывать из него далее.
Рассмотрев аргументы написанной нами функции custom_read, можно заметить, благодаря каким аргументам все это происходит. Структура file представляет тот файл, из которого считывает информацию наше приложение пользовательского пространства (хотя, на самом деле эта конкретная структура относится сугубо к ядру, что, впрочем, не важно в контексте этой статьи). Последние аргументы представляют буфер, счет и смещение. Здесь имеется в виду буфер пользовательского пространства, в принципе, его содержимое — это адрес в памяти, по которому расположен тот массив, в который мы записываем байты. Счет — это размер фрагмента. Смещение — это точка в файле, начиная с которой мы начинаем считывание фрагмента (как вы, вероятно, уже догадались). Давайте рассмотрим, что должно происходить при считывании из модуля. В пользовательское пространство мы возвращаем только «Hello world!». Считая переход на новую строку, расположенный в конце строки, у нас здесь всего 13 символов, которые отлично разместятся в практически любом фрагменте памяти. Когда мы пытаемся считывать информацию из нашей записи /proc, дела пойдут так: считываем первый фрагмент, записываем приветствие в буфер и возвращаем 13 (длина строки с приветствием) в приложение пользовательского пространства — ведь было считано всего 13 байт. Считывание второго фрагмента начнется со смещением 13, что соответствует «концу» нашего файла (больше нам совершенно нечего отправлять в ответ), поэтому мы вернем 0. Это отражено в логике нашей функции custom_read. Если переданное ей значение смещения больше 0, это означает, что мы уже получили искомое приветствие — поэтому далее мы просто возвращаем 0, и на этом все. В противном случае мы копируем нашу приветственную строку в буфер пользовательского пространства и соответствующим образом обновляем значение смещения.
По тем же принципам должны строиться и другие функции, например, переопределяющие функцию записи. Ваша функция может делать что угодно — до тех пор, пока она действует как файл, любые приложения из пользовательского пространства могут осуществлять с ней операции считывания и записи.
Заключение
Спасибо, что дочитали этот пост. Надеюсь, он показался вам достаточно интересным, и вдохновил вас немного покопаться в ядре самостоятельно. Хотя, в этой статье мы и пользовались виртуальной машиной, вам просто необходимо знать, как пишутся модули ядра, если вы собираетесь когда-либо писать код для встраиваемых систем (например, для устройств Интернета Вещей). В таком случае вам также стоит лучше разобраться в разработке для ядра, и я особенно рекомендую вам этот туториал. На тему ядра написано достаточно много книг, но при покупке обращайте внимание на дату выхода — книга должна быть как можно более свежей. В любом случае, вероятно, вы только что написали свой первый модуль для ядра Linux, так что можете этим гордиться.

