[Перевод] Как портирование игры на PSVita повысило общую производительность
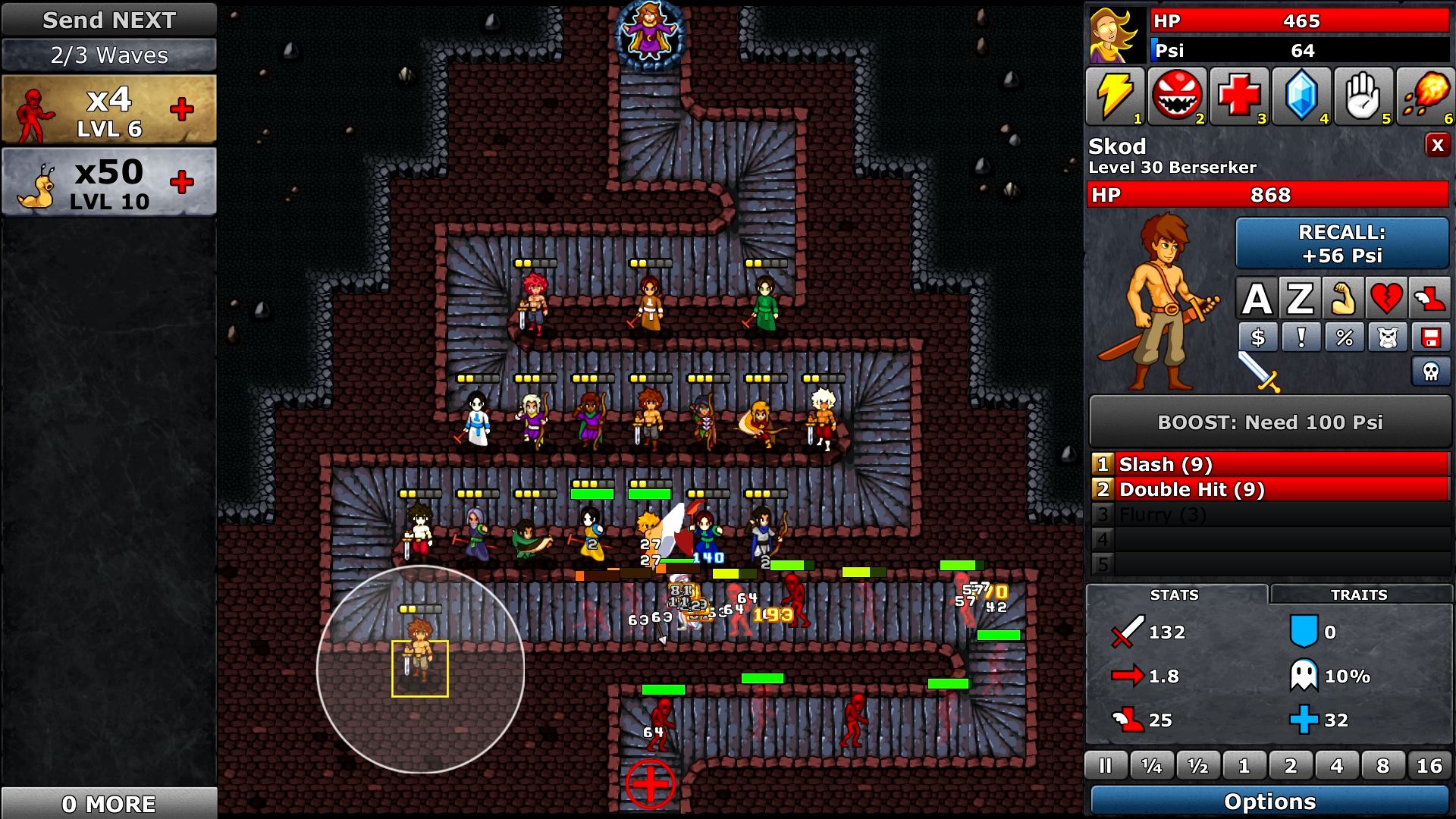
На уровне могут находиться тысячи врагов.
У игры Defender’s Quest: Valley of the Forgotten DX всегда были давние проблемы со скоростью, и мне наконец удалось их решить. Основным стимулом к масштабному повышению скорости стал наш порт на PlayStation Vita. Игра уже вышла на PC и хорошо, если не идеально, работала на Xbox One с PS4. Но без серьёзного усовершенствования игры нам ни за что бы не удалось запустить её на Vita.
Когда игра тормозит, комментаторы в Интернете обычно винят язык программирования или движок. Справедливо то, что языки наподобие C# и Java связаны с большими издержками, чем C и C++, а у инструментов наподобие Unity есть не решаемые проблемы, например со сборкой мусора. На самом деле люди придумывают такие объяснения потому, что язык и движок являются наиболее явными свойствами ПО. Но истинными убийцами производительности могут оказаться глупые крошечные детали, никак не связанные с архитектурой.
Существует единственный реальный способ сделать игру быстрее — выполнить профилирование. Выяснить, на что компьютер тратит слишком много времени и заставить его тратить на это меньше времени, или даже лучше — заставить его вообще не тратить время.
Простейший инструмент профилирования — это стандартный системный монитор (performance monitor) Windows:
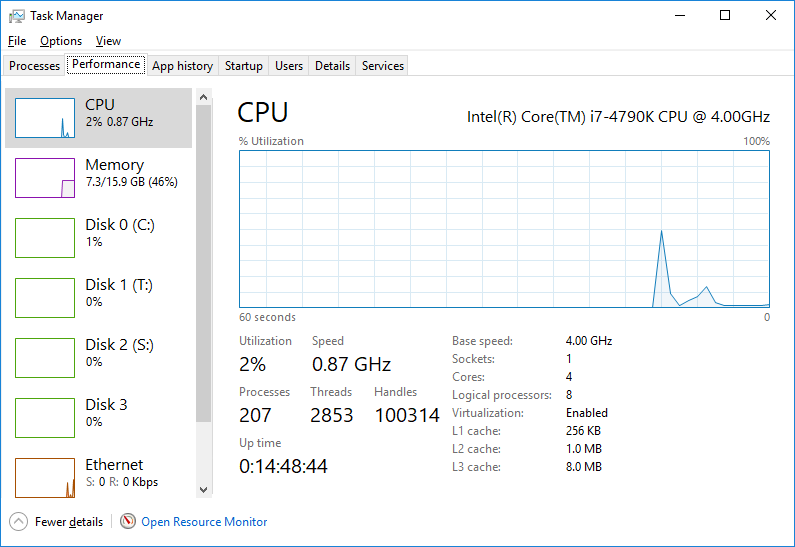
На самом деле это достаточно гибкий инструмент и с ним очень просто работать. Просто нажимаем Ctrl+Alt+Delete, открываем «Диспетчер задач» и нажимаем на вкладку «Производительность». При этом не запускайте слишком много других программ. Если внимательно смотреть, вы сможете легко обнаружить пики использования ЦП и даже утечки памяти. Это малоинформативный способ, зато он может стать первым шагом в поиске медленных мест.
Defender’s Quest написан на высокоуровневом языке Haxe, компилируемом на другие языки (моим основным целевым был C++). Это значит, что любой инструмент, способный профилировать C++, сможет профилировать и мой сгенерированный Haxe код C++. Поэтому когда я захотел разобраться в причинах возникновения проблем, я запустил Performance Explorer из Visual Studio:
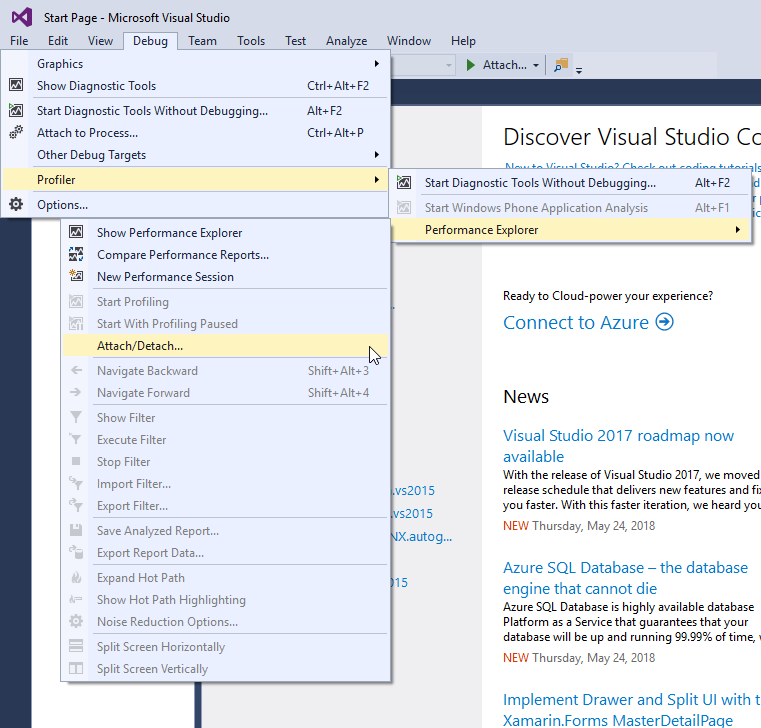
Кроме того, у разных консолей есть собственные инструменты профилирования, что очень удобно, но из-за NDA я не могу ничего вам о них рассказывать. Но если у вас есть к ним доступ, но обязательно пользуйтесь ими!
Вместо того, чтобы писать ужасный туториал о том, как пользоваться инструментами профилирования наподобие Performance Explorer, я просто оставлю ссылку на официальную документацию и перейду к основной теме — удивительным вещам, которые привели к огромному росту производительности, и к тому, как мне удалось их найти!
Производительность игры — это не только сама скорость, но и её восприятие. Defender’s Quest — это игра жанра tower defense, которая рендерится с частотой 60 FPS, но с переменной скоростью игрового процесса в интервале от 1/4x до 16x. Вне зависимости от скорости игры симуляция использует фиксированную метку времени с 60 обновлениями в секунду времени симуляции 1x. То есть если запустить игру на скорости 16x, то логика обновления на самом деле будет работать с частотой 960 FPS. Честно говоря, это слишком высокие запросы к игре! Но именно я создал этот режим, и если он окажется медленным, то игроки обязательно это заметят.
А ещё в игре есть вот такой уровень:
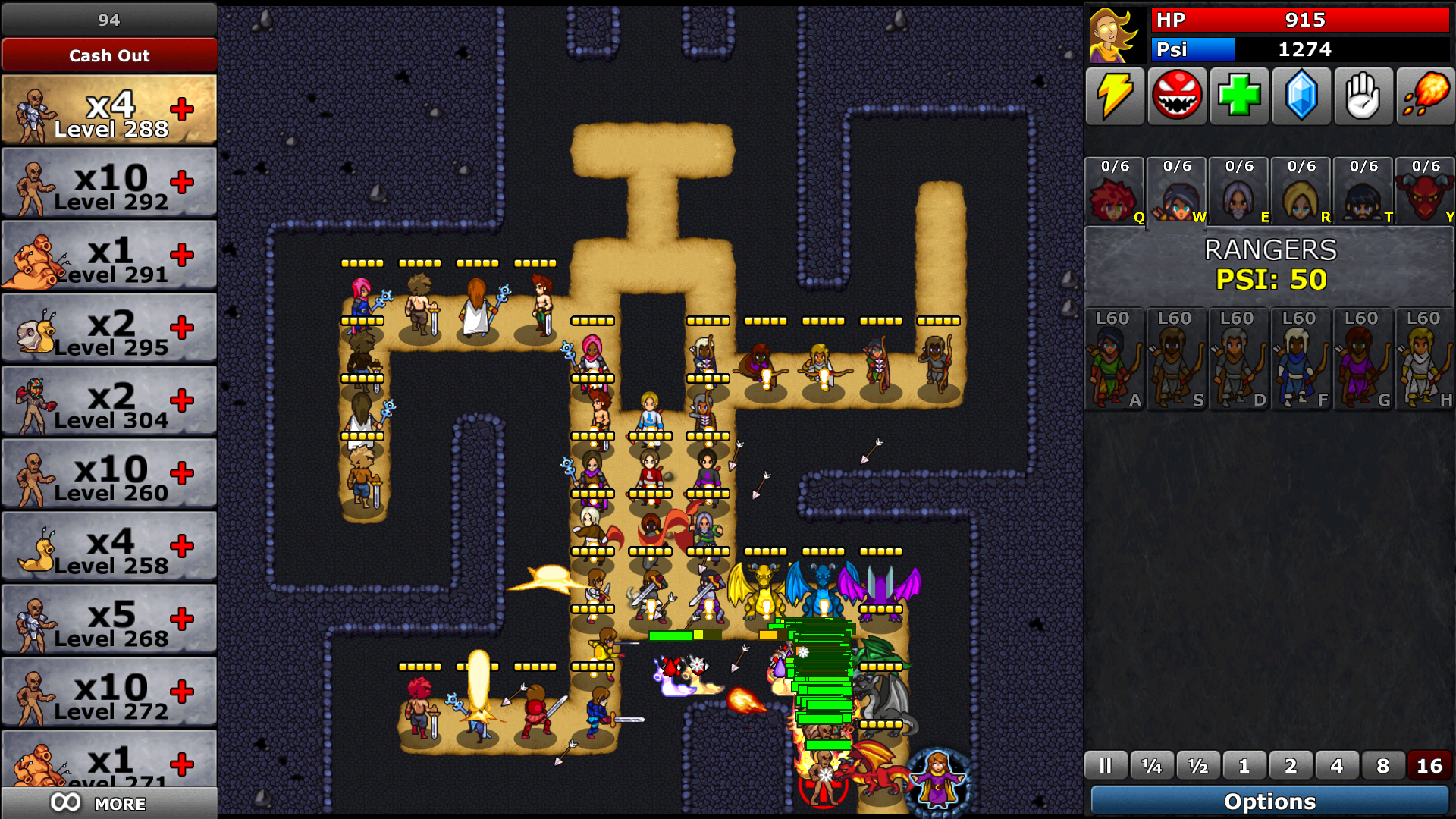
Это финальная бонусная битва «Endless 2», она же «мой личный кошмар». Скриншот сделан в режиме New Game+, в котором враги не только намного сильнее, но и имеют такие возможности, как восстановление здоровья. Любимая стратегия игроков здесь — прокачать драконов до максимального уровня Roar (AOE-атака, оглушающая врагов), а за ними поставить ряд рыцарей с прокачанным по максимуму Knockback, чтобы отталкивать всех, проходящих мимо драконов, обратно в область их действия. Кумулятивный эффект заключается в том, что огромная группа монстров бесконечно остаётся на одном месте, намного дольше, чем игрокам пришлось бы выживать, если бы они на самом деле убили их. Так как игрокам для получения наград и достижений нужно дожидаться волн, а не убивать их, такая стратегия абсолютно действенна и блестяща — именно такое поведение игроков я и стимулировал.
К сожалению, одновременно это оказывается и патологическим случаем для производительности, особенно когда игроки хотят играть на скорости 16x или 8x. Разумеется, только самые хардкорные игроки попытаются получить достижение «Сотая волна» в New Game+ на уровне Endless 2, но они оказываются как раз теми, кто громче всех говорит об игре, поэтому я хотел, чтобы они были довольны.
Это ведь всего лишь 2D-игра с кучкой спрайтов, что с ней может быть не так?
И в самом деле. Давайте разбираться.
Посмотрите на этот скриншот:
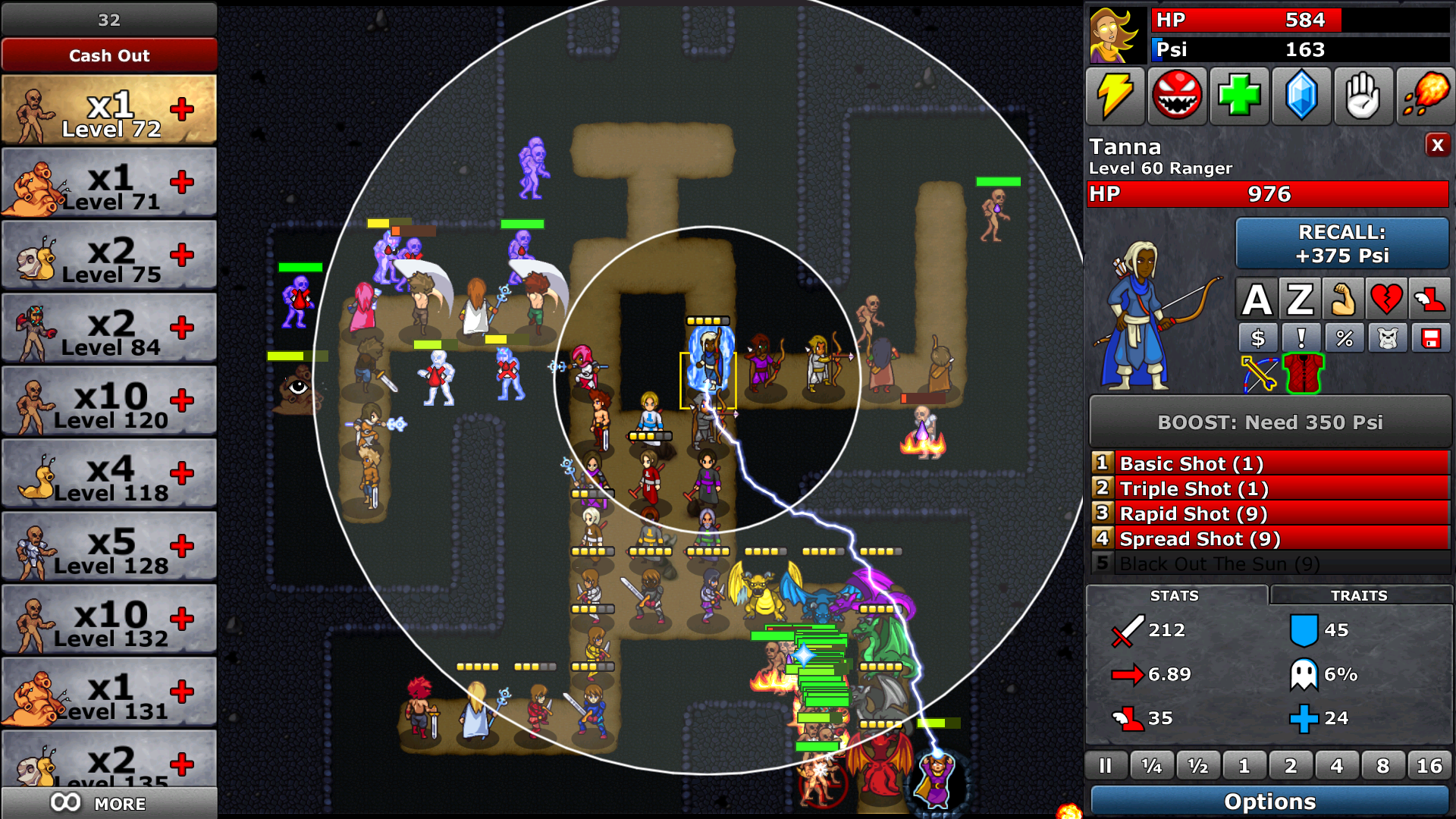
Видите этот бублик вокруг рейнджера? Это её область попадания — заметьте, что также есть мёртвая зона, в которой она не может попадать по целям. Каждый класс имеет собственную область атаки, и у каждого защитника область имеет разный размер, зависящий от уровня буста и личных параметров. И каждый защитник в теории может целиться в любого врага в области своей досягаемости. То же самое справедливо и для некоторых типов врагов. На карте может быть до 36 защитников (не включая главного героя Азру), а верхнего предела на количество врагов нет. Каждый защитник и враг имеет список возможных целей, создаваемый на основе вызовов проверки области при каждом шаге обновления (минус логичное отсечение тех, кто не может атаковать в данный момент и так далее).
Сегодня видеопроцессоры очень быстры — если вы не слишком напрягаете их, то они могу обработать практически любое количество полигонов. Но даже у самых быстрых ЦП очень легко возникают «бутылочные горлышки» в простых процедурах, особенно в тех, которые разрастаются экспоненциально. Именно поэтому 2D-игра может оказаться медленнее гораздо более красивой 3D-игры — не потому, что программист не справился (возможно, и это тоже, по крайней мере, в моём случае), а в принципе потому, чтоб логика иногда может быть затратнее, чем отрисовка! Вопрос не в том, сколько объектов есть на экране, а в том, что они делают.
Давайте исследуем и ускорим распознавание коллизий. Для сравнения скажу, что до оптимизации распознавание коллизий занимало до ~50% времени ЦП в основном цикле битвы. После оптимизации — меньше 5%.
Всё дело в деревьях квадрантов
Основным решением проблемы медленного распознавания коллизий является разбиение пространства — и мы с самого начала использовали качественную реализацию дерева квадрантов. По сути, оно эффективно разделяет пространство, чтобы можно было пропускать множество необязательных проверок коллизий.
В каждом кадре мы обновляем всё дерево квадрантов (QuadTree), чтобы отследить позицию каждого объекта, и когда враг или защитник хочет в кого-то нацелиться, он запрашивает у QuadTree список ближайших объектов. Но профайлер сказал нам, что обе эти операции гораздо медленее, чем должны быть.
Что же здесь не так?
Как оказалось — многое.
Стринговая типизация
Так как я хранил и врагов, и защитников в одном дереве квадрантов, мне нужно было указывать, что я ищу, и это выполнялось так:
var things:Array
На жаргоне программистов это называется кодом со стринговой типизацией, и, кроме других причин, он плох тем, что сравнение строк всегда медленнее, чем сравнение целых чисел.
Я быстро подобрал целочисленные константы и заменил код на такой:
var things:Array
(Да, вероятно, стоило использовать Enum Abstract для максимальной безопасности типов, но я торопился, и мне нужно было в первую очередь сделать работу.)
Одно это изменение внесло огромный вклад, потому что эта функция вызывается постоянно и рекурсивно, каждый раз, когда кому-нибудь нужен новый список целей.
Массив против вектора
Посмотрите на это:
var things:Array
Массивы Haxe очень похожи на массивы ActionScript и JS тем, что являются коллекциями объектов изменяемого размера, но в Haxe они обладают строгой типизацией.
Однако существует другая структура данных, более производительная в случае статических целевых языков, таким как cpp, а именно haxe.ds.Vector. Векторы Haxe — это по сути то же самое, что и массивы, за исключением того, что при создании они получают фиксированный размер.
Так как мои деревья квадрантов уже имели фиксированный объём, я заменил массивы векторами, чтобы добиться заметного повышения скорости.
Запрашивать только то, что тебе нужно
Раньше моя функция queryRange возвращала список объектов, экземпляров XY. В них содержались координаты x/y игрового объекта, на который выполняется ссылкам, и его уникальный целочисленный идентификатор (индекс поиска в основном массиве). Выполняющий запрос игровой объект получал эти XY, извлекал целочисленный идентификатор, чтобы получить свою цель, а затем забывал об остальном.
Так зачем мне передавать все эти ссылки на объекты XY для каждого узла QuadTree рекурсивно, да ещё по 960 раз за кадр? Мне достаточно возвращать список целочисленных идентификаторов.
ПОДСКАЗКА ПРОФЕССИОНАЛА: целые числа гораздо быстрее передавать, чем практически все другие типы данных!
По сравнению с другими исправлениями это было довольно простым, но рост производительности всё равно был заметным, потому что этот внутренний цикл использовался очень активно.
Оптимизация хвостовой рекурсии
Существует элегантная штука под названием оптимизация хвостовой рекурсии (Tail-call optimization). Её сложно объяснить, поэтому я лучше покажу на примере.
Было:
nw.queryRange(Range, -1, result);
ne.queryRange(Range, -1, result);
sw.queryRange(Range, -1, result);
se.queryRange(Range, -1, result);
return result;
Стало:
return se.queryRange(Range, filter,
sw.queryRange(Range, filter,
ne.queryRange(Range, filter,
nw.queryRange(Range, filter, result))));
Код возвращает одинаковые логические результаты, но согласно профайлеру второй вариант быстрее, по крайней мере, при трансляции в cpp. Оба примера выполняют абсолютно одинаковую логику — вносят изменения в структуру данных «result» и передают её в следующую функцию до возврата. Когда мы делаем это рекурсивно, то можем избежать того, чтобы компилятор генерировал временные ссылки, потому что он просто может возвращать результат предыдущей функции сразу же, а не придерживаться её на дополнительном шаге. Или что-то в этом духе. Я не полностью понимаю, как это работает, поэтому прочитайте пост по ссылке выше.
(Судя по тому, что я знаю, текущая версия компилятора Haxe не имеет функции оптимизации хвостовой рекурсии, то есть вероятно это работа компилятора C++ — поэтому не удивляйтесь, если этот трюк не сработает при трансляции кода Haxe не в cpp.)
Пулинг объектов
Если мне нужны точные результаты, то я должен разрушать и снова выстраивать QuadTree при каждом вызове обновления. Создание новых экземпляров QuadTree — достаточно обыденная задача, но при больших количествах новых объектов AABB и XY зависящие от них QuadTrees приводили к сильной перегрузке памяти. Поскольку это очень простые объекты, логично будет выделить множество таких объектов заранее и просто постоянно использовать их заново. Это называется пулом объектов.
Раньше я делал что-то такое:
nw = new QuadTree( new AABB( cx - hs2x, cy - hs2y, hs2x, hs2y) );
ne = new QuadTree( new AABB( cx + hs2x, cy - hs2y, hs2x, hs2y) );
sw = new QuadTree( new AABB( cx - hs2x, cy + hs2y, hs2x, hs2y) );
se = new QuadTree( new AABB( cx + hs2x, cy + hs2y, hs2x, hs2y) );
Но потом заменил код на такой:
nw = new QuadTree( AABB.get( cx - hs2x, cy - hs2y, hs2x, hs2y) );
ne = new QuadTree( AABB.get( cx + hs2x, cy - hs2y, hs2x, hs2y) );
sw = new QuadTree( AABB.get( cx - hs2x, cy + hs2y, hs2x, hs2y) );
se = new QuadTree( AABB.get( cx + hs2x, cy + hs2y, hs2x, hs2y) );
Мы используем фреймворк HaxeFlixel с открытым исходным кодом, поэтому реализовали это с помощью класса FlxPool HaxeFlixel. В случае таких узкоспециализированных оптимизаций я часто заменяю некоторые базовые элементы Flixel (например распознавание коллизий) своей собственной реализацией (как я сделал это с QuadTrees), но FlxPool лучше, чем всё, что я написал сам, и он выполняет ровно то, что нужно.
Специализация при необходимости
Объект XY — это простой класс, имеющий свойства x, y и int_id. Поскольку он применялся в особо активно используемом внутреннем цикле, я мог сэкономить множество команд выделения памяти и операций, переместив все эти данные в особую структуру данных, обеспечивающую тот же функционал, что и Vector. Я назвал этот новый класс XYVector и результат можно посмотреть здесь. Это очень узкоспециализированный случай применения и при этом совершенно не гибкий, но он обеспечил нам определённые улучшения скорости.
Встраиваемые функции
Теперь, после того, как мы выполнили широкую фазу распознавания коллизий, нам нужно провести множество проверок, чтобы выяснить, какие же объекты на самом деле сталкиваются. Где это возможно, я пытаюсь выполнять сравнение точки и фигуры, а не фигуры и фигуры, но иногда приходится делать последнее. В любом случае для всего этого требуются собственные особые проверки:
private static function _collide_circleCircle(a:Zone, b:Zone):Bool
{
var dx:Float = a.centerX - b.centerX;
var dy:Float = a.centerY - b.centerY;
var d2:Float = (dx * dx) + (dy * dy);
var r2:Float = (a.radius2) + (b.radius2);
return d2 < r2;
}
Всё это можно усовершенствовать единственным ключевым словом inline:
private static inline function _collide_circleCircle(a:Zone, b:Zone):Bool
{
var dx:Float = a.centerX - b.centerX;
var dy:Float = a.centerY - b.centerY;
var d2:Float = (dx * dx) + (dy * dy);
var r2:Float = (a.radius2) + (b.radius2);
return d2 < r2;
}
Когда мы добавляем «inline» к функции, то говорим компилятору копировать и вставлять этот код и вставлять переменные, когда он используется, а не делать внешний вызов к отдельной функции, который приводит к излишним затратам. Встраивание применимо не всегда (например, оно раздувает объём кода), но оно идеально для подобных ситуаций, когда маленькие функции вызываются снова и снова.
Доводим до ума коллизии
Настоящий урок здесь заключается в том, что в реальном мире оптимизации не всегда относятся к одному типу. Такие исправления являются смешением продвинутых техник, дешёвых хаков, применения логичных рекомендаций и устранения глупых ошибок. Всё это в целом даёт нам повышение производительности.
Но всё равно — семь раз измерь, один отрежь!
Два часа педантичной оптимизации функции, вызываемой раз в шесть кадров и занимающей 0,001 мс, не стоит усилий, несмотря на уродливость и глупость кода.
На самом деле это было одно из последних моих усовершенствований, но оно оказалось настолько выигрышным, что заслуживает собственного заголовка. Кроме того, оно было самым простым и многократно оправдало себя. Профайлер показывал мне процедуру, которую я никак не мог улучшить — основной цикл draw (), занимавший слишком много времени. Причиной была функция, которая перед отрисовкой сортировала все экранные элементы — именно, сортировка всех спрайтов занимала гораздо больше времени, чем их отрисовка!
Если вы посмотрите на скриншоты из игры, то увидите, что все враги и защитники сначала сортируются по y, а затем по x, чтобы элементы накладывались друг на друга сзади вперёд, слева направо, когда мы двигаемся из левого верхнего в правый нижний угол экрана.
Один из способов обхитрить сортировку — просто пропускать через кадр сортировку отрисовки. Это полезный трюк для некоторых затратных функций, но он сразу же привёл к очень заметным визуальным багам, поэтому не подошёл нам.
Наконец решение пришло от одного из мейнтейнеров HaxeFlixel Дженса Фишера. Он спросил: «А ты убедился, что используешь алгоритм сортировки, который быстр для почти отсортированных массивов?»
Нет! Оказалось, что нет. Я использовал сортировку массива из стандартной библиотеки Haxe (думаю, это была сортировка слиянием — хороший выбор для общих случаев. Но у меня был очень особый случай. При сортировке в каждом кадре изменяется позиция сортировки только очень малого количества спрайтов, даже если их много. Поэтому я заменил старый вызов сортировки на сортировку вставками, и бум! — скорость мгновенно возросла.
Распознавание коллизий и сортировка стали большими победами в логике update() и draw(), но в активно используемых внутренних циклах скрывалось ещё множество различных подводных камней.
Std.is () и cast
В разных «горячих» внутренних циклах у меня был подобный код:
if(Std.is(something,Type))
{
var typed:Type = cast(something,Type);
}
В языке Haxe Std.is() сообщает нам, принадлежит ли объект к определённому типу (Type) или классу (Class), а cast пытается привести его в процессе выполнения программы к определённому типу.
Существуют безопасная и незащищённая версии cast — безопасные cast приводят к снижению производительности, а незащищённые — нет.
Безопасные: cast(something, Type);
Незащищённые: var typed:Type = cast something;
Когда попытка незащищённого приведения завершается неудачей, мы получаем значение null, в то время как безопасное приведение выбрасывает исключение. Но если мы не собираемся отлавливать исключение, то какой смысл выполнения безопасного приведения? Без catch операция всё равно заканчивается неудачей, но работает медленнее.
Кроме того, бессмысленно предварять безопасное приведение проверкой Std.is(). Единственная причина использования безопасного приведения — гарантированное исключение, но если мы проверяем тип перед приведением, то мы уже гарантируем, что приведение не окончится неудачей!
Я могу немного ускорить работу с помощью незащищённого приведения после проверки Std.is(). Но зачем нам заново писать то же самое, если мне вообще не нужно проверять тип класса?
Допустим, у меня есть CreatureSprite, который может быть экземпляром подкласса или DefenderSprite, или EnemySprite. Вместо вызова Std.is(this,DefenderSprite) мы можем создать целочисленное поле в CreatureSprite со значениями наподобие CreatureType.DEFENDER или CreatureType.ENEMY, которые проверяются ещё быстрее.
Повторюсь, исправлять это стоит только в тех местах, где явно фиксируется значительное замедление.
Кстати, вы можете подробнее прочитать о безопасном и незащищённом приведении в мануале по Haxe.
Сериализация/десериализация вселенной
Раздражающе было находить такие места в коде:
function copy():SomeClass
{
return SomeClass.fromXML(this.toXML());
}
Ага. Для копирования объекта мы сериализуем его в XML, а затем парсим весь этот XML, после чего мгновенно отбрасываем XML и возвращаем новый объект. Это наверно самый медленный способ копирования объекта, кроме того, он перегружает память. Изначально я писал вызовы XML для сохранения и загрузки с диска, и думаю, что был слишком ленивым, чтобы написать правильные процедуры копирования.
Вероятно, всё было бы в порядке, если бы эта функция использовалась редко, но эти вызовы возникали в неподходящих местах посередине геймплея. Поэтому я сел и занялся написанием и тестированием правильной функции копирования.
Скажи «нет» Null
Проверка равенства на null используется достаточно часто, но при трансляции Haxe в cpp допускающий неопределённое значение объект приводит к излишним затратам, которые не возникают, если компилятор может предположить, что объект никогда не будет null. Это особенно справедливо для базовых типов наподобие Int — Haxe реализует допустимость неопределённого значения для них в статической целевой системе их «упаковкой», которая происходит не только для переменных, которые явно объявлены допускающими значение null (var myVar:Null), но и для таких вещей, как вспомогательные параметры (?myParam:Int). Кроме того, сами проверки на null вызывают излишние траты.
Я смог устранить некоторые из этих проблем, просто посмотрев на код и подумав над альтернативами — могу ли я выполнять более простую проверку, которая всегда будет истинна, когда объект имеет значение null? Могу ли я отлавливать null гораздо раньше в цепочке вызовов функций и передавать простое целое число или булев флаг вниз дочерним вызовам? Могу ли я структурировать всё таким образом, чтобы значение гарантированно никогда не становилось null? И так далее. Мы не можем полностью устранить проверки на null и значения, способные быть null, но мне очень помогло вынесение их из функций.
На PSVita у нас были особые серьёзные проблемы со временем загрузки некоторых сцен. При профилировании выяснилось, что причины в основном сводятся к растеризации текста, ненужному программному рендерингу, затратному рендерингу кнопок и другим вещам.
Текст
HaxeFlixel основан на OpenFL, у которого есть потрясающие и надёжные TextField. Но я использовал объекты FlxText неидеальным образом — у объектов FlxText есть внутреннее текстовое поле OpenFL, которое растеризируется. Однако оказалось, что мне не нужно большинство этих сложных текстовых функций, а из-за глупого способа настройки моей системы UI текстовые поля должны были рендериться перед расположением всех остальных объектов. Это приводило к небольшим, но заметным скачкам, например, при загрузке всплывающего окна.
Здесь я внёс три исправления — во-первых, заменил как можно больше текста на растровые шрифты. У Flixel есть встроенная поддержка различных форматов растровых шрифтов, в том числе AngelCode’s BMFont, который позволяет с лёгкостью работать с Unicode, стилем и кернингом, но API для растрового текста немного отличается от API обычного текста, поэтому мне пришлось написать небольшой класс-обёртку, чтобы упростить переход. (Я дал ему подходящее название FlxUITextHack).
Это немного улучшило работу — растровые шрифты рендерятся очень быстро —, но слегка увеличило сложность: мне пришлось специально подготавливать отдельные наборы символов и добавлять логику переключения между ними в зависимости от локали, вместо того, чтобы просто настроить текстовое поле, которое выполняло всю работу.
Второе исправление заключалось в создании нового объекта UI, который был простым заполнителем для текста, но имел все те же публичные свойства, что и текст. Я назвал его «областью текста» и создал для него в своей библиотеке UI новый класс, чтобы моя система UI могла использовать эти области текста так же, как настоящие текстовые поля, но не рендерила ничего, пока не вычислит размер и позицию для всего остального. Затем, когда моя сцена была подготовлена, я запускал процедуру замены этих областей текста настоящими текстовыми полями (или текстовыми полями растровых шрифтов).
Третье исправление касалось восприятия. Если между вводом и реакцией возникают паузы даже в полсекунды, игрок воспринимает это как торможение. Поэтому я попытался найти все сцены, в которых есть задержка ввода до следующего перехода, и добавил или полупрозрачный слой со словом «Loading…» или просто слой без текста. Такое простое исправление сильно улучшило восприятие отзывчивости игры, так как что-то происходит сразу же после того, как игрок прикасается к управлению, даже если на отображение меню требуется какое-то время.
Программный рендеринг
В большинстве меню используется сочетание программного масштабирования и композитинга 9-slice. Так получилось потому, что в версии для PC был независимый от разрешения UI, который мог работать при соотношении сторон 4:3 и 16:9, масштабируясь соответствующим образом. Но на PSVita мы уже знаем разрешение, то есть нам не нужны все эти излишние ресурсы высокого разрешения и алгоритмы масштабирования в реальном времени. Мы можем просто предварительно отрендерить ресурсы под точное разрешение и разместить их на экране.
Сначала я внёс в разметку UI для Vita условия, которые переключали игру на использование параллельного набора ресурсов. Затем мне нужно было создать эти подготовленные к одному разрешению ресурсы. Здесь очень полезным оказался отладчик HaxeFlixel — я добавил в него свой скрипт, чтобы он просто сбрасывал растровый кэш на диск. Затем я создал специальную конфигурацию сборки под Windows, имитирующую разрешение на Vita, открыл по очереди все меню игры, перешёл в отладчик и запустил команду экспорта отмасштабированных версий ресурсов в виде готовых PNG. Потом я просто переименовал их и использовал в качестве ресурсов для Vita.
Рендеринг кнопок
У моей системы UI была настоящая проблема с кнопками — при своём создании кнопки рендерили набор ресурсов по умолчанию, а мгновением позже они изменяли свой размер (и рендерились заново) кодом загрузки UI, а иногда даже и в третий раз, прежде чем завершится загрузка всего UI. Я решил эту проблему, добавив параметры, отложившие рендеринг кнопок на последний этап.
Необязательное сканирование текста
Особо медленно загружался журнал. Сначала я думал, что проблема в текстовых полях, но нет. В тексте журнала могли содержаться ссылки на другие страницы, что обозначалось особыми символами, встроенными в сам сырой текст. Позже эти символы вырезались и использовались для вычисления расположения ссылки.
Оказалось. что я сканировал каждое текстовое поле, чтобы найти и заменить эти символы правильно отформатированными ссылками, даже не проверяя сначала, есть ли в этом текстовом поле вообще специальный символ! Хуже того, в соответствии с дизайном ссылки использовались только на странице содержания, но я проверял их в каждом текстовом поле на каждой странице.
Мне удалось обойти все эти проверки с помощью конструкции if вида «использует ли вообще это текстовое поле ссылки». Ответом на этот вопрос обычно было «нет». Наконец страницей, загрузка которой занимала самое долгое время, оказалась страница индексов. Так как она никогда не меняется в меню журнала, то почему бы нам её не кэшировать?
Скорость — это не только ЦП. Память тоже может стать проблемой, особенно на слабых платформах наподобие Vita. Даже когда удалось избавиться от последней утечки памяти, у вас всё равно могут возникнуть проблемы с пилообразным использованием памяти в среде со сборкой мусора.
Что такое «пилообразное использование памяти»? Сборщик мусора работает следующим образом: данные и объекты, которые вы не используете, накапливаются со временем, и периодически очищаются. Но у вас нет чёткого контроля над тем, когда это происходит, поэтому график использования памяти выглядит как пила:
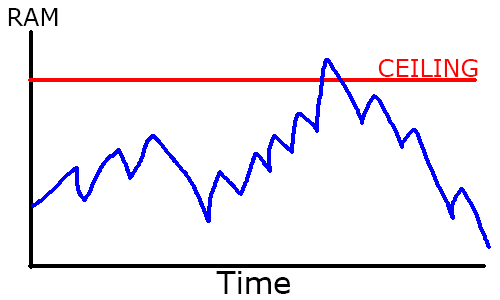
Выносим мусор
Поскольку очистка выполняется не мгновенно, общий используемый вами объём ОЗУ обычно больше, чем вам строго необходимо. Но если вы превысите общее количество ОЗУ системы, то может произойти одно из двух — на PC вы наверно просто используете файл подкачки, то есть временно преобразуете часть пространства жёсткого диска в виртуальную ОЗУ. Альтернатива в средах с ограниченной памятью (таких как консоли) — это вылет приложения, даже если не хватило всего жалких пары байтов. И так случится, даже если вы не используете эти байты и в них скоро будет выполнена сборка мусора!
В Haxe хорошо то, что он полностью open source, то есть вы не заперты в чёрном ящике, который не можете исправить, как в случае с Unity. А бэкенд hxcpp предоставляет широкие возможности управления сборкой мусора непосредственно из API!
Мы применяли их для мгновенной очистки памяти после большого уровня, чтобы оставаться в заданных пределах:
cpp.vm.Gc.run(false); //запускаем сборщик мусора (true/false - крупная/мелкая сборка мусора)
Не стоит использовать это поневоле, если не знаете, что вы делаете, но удобно, что существуют такие инструменты, когда они необходимы.
Всех этих улучшений производительности было более чем достаточно, чтобы оптимизировать игру для PC, но мы пытались ещё и выпустить версию для PSVita, и у нас были дальние планы на Nintendo Switch, поэтому нам нужно было выжать из кода всё до капли.
Но часто возникает «туннельное зрение», когда ты сосредотачиваешься только на технических хаках и забываешь, что сильно улучшить положение может простая смена дизайна.
Ускоряем эффекты на высокой скорости
При скорости 16x многие эффекты происходят так быстро, что игрок даже их не видит. У нас уже использовался один приём — молния Азры становилась всё проще с увеличением скорости игры, а количество частиц для AOE-атак — ниже. Мы дополнили этот приём отключением на высокой скорости чисел урона и другими подобными трюками.
Мы также осознали, что в какой-то момент скорость 16x может на самом деле оказаться медленнее скорости 8x, когда на экране есть слишком много объектов, поэтому когда количество врагов увеличивалось до определённого предела мы автоматически снижали скорость игры до 8x или 4x. На практике игрок скорее всего увидит это только в Endless Battle 2. Это позволяет обеспечивать плавную производительность и рендеринг, не слишком нагружая ЦП.
Также мы использовали ограничения специально для платформы. На Vita мы пропускаем эффект молнии, когда Азра вызывает или ускоряет персонажа, и использовали другие похожие приёмы.
Прячем тела
А как насчёт огромной кучи врагов в нижнем правом углу Endless Battle 2 — там в буквальном смысле сотни или даже тысячи врагов, отрисовывающихся один поверх другого. Почему бы нам просто не пропустить отрисовку тех из них, которых мы даже не сможем увидеть?
Это хитрый дизайнерский трюк, требующий хитрого программирования, потому что нам нужен умный алгоритм, определяющий скрываемые объекты.
Большинство подобных игр отрисовываются с помощью алгоритма художника — предыдущие объекты в списке отрисовки перекрываются всем, идущим после них.
Перевернув порядок отрисовки алгоритма художника, можно сгенерировать «карту сокрытия» и узнать, что должно быть скрыто. Я создал фальшивый «холст» с 8 уровнями «темноты» (просто двухмерный массив байтов) с гораздо более низким разрешением, чем настоящее поле боя. Начиная с конца списка отрисовки мы берём ограничивающий прямоугольник каждого объекта и «отрисовываем» его на холсте, увеличивая «темноту» точки на 1 для каждого «пикселя», закрываемого ограничивающим прямоугольником низкого разрешения. Одновременно мы считываем среднюю «темноту» области, в которой мы собираемся рисовать. По сути, мы предсказываем, сколько перерисовок испытает каждый объект при настоящем вызове отрисовки.
Если предсказанное количество перерисовок достаточно высоко, то я помечаю врага как «погребённого», с двумя пороговыми значениями — полностью погребённого, то есть совершенно невидимого, или частично погребённого, то есть он будет отрисовываться, но без отрисовки полосы здоровья.
(Кстати, вот функция проверки перерисовок.)
Чтобы это работало правильно, необходимо правильно настроить разрешение карты сокрытия. Если оно будет слишком большим, то нам придётся выполнять лишнюю кучу упрощённых вызовов отрисовки, если слишком маленьким — то мы будем скрывать объекты слишком агрессивно и получим визуальные баги. Если подобрать карту правильно, то эффект едва различим, но повышение скорости очень заметно — нет способа отрисовать что-то быстрее, чем вообще это не рисовать!
Лучше предварительная загрузка, чем тормоза
Посередине боёв я замечал частые торможения, которые, как я был уверен, вызваны паузой сборки мусора. Однако профилирование показало, что это не так. Дальнейшее тестирование выявило, что это происходит при начале спауна волны врагов, а позже я обнаружил, что это случается только когда это волна врагов, которых ещё не было раньше. Очевидно, что проблему вызывал какой-то код настройки врагов, и разумеется, при профилировании обнаружилась «горячая» функция в настройке графики. Я начал работать над сложной многопоточной настройкой загрузки, но затем понял, что просто могу засунуть все процедуры загрузки графики врагов в предварительную загрузку боя. По отдельности это были очень маленькие загрузки, даже на самых медленных платформах добавляющие меньше секунды к общему времени загрузки битвы, но они позволили избежать очень заметных торможений во время игрового процесса.
Оставляем запас на потом
Если вы работаете в среде с ограниченной памятью, то можно использовать древний трюк нашей индустрии — выделить большой фрагмент памяти просто так, а потом забыть о нём до конца проекта. В конце проекта, растратив весь доступный бюджет памяти, вы сможете спастись благодаря этой «заначке».
Мы оказались в такой ситуации — нам нам не хватало всего дюжины байтов, чтобы спасти сборку для PSVita, но чёрт возьми — мы забыли об этом трюке и потому застряли! Единственным оставшимся вариантом были недели отчаянной и мучительной хирургической операции на коде!
Но постойте! Одной из моих (неудачных) оптимизаций была загрузка как можно большего количества ресурсов и вечное хранение их в памяти, потому что я ошибочно предполагал, что большое время загрузки вызвано считыванием ресурсов в процессе выполнения программы. Оказалось, что это не так, поэтому почти все эти лишние вызовы для предварительной загрузки и вечного хранения можно было полностью удалить, и у меня оставалась свободная память!
Избавляемся от вещей, которые не используем
Работая над сборкой для PSVita, мы особо чётко осознали, что есть куча вещей, которые нам просто не нужны. Из-за низкого разрешения режим исходной графики и режим HD-графики были неразличимы, поэтому для всех спрайтов мы использовали исходную графику. Также нам удалось ул
