[Перевод] Бенчмаркинг Linkerd и Istio

Фото с сайта linkerd.io
Пару лет назад ребята из Kinvolk сравнили производительность Linkerd и Istio и узнали, что Linkerd значительно быстрее и меньше Istio везде, кроме одной области. Linkerd использовала больше процессорных ресурсов в плоскости данных (data plane). Недавно мы повторили эти эксперименты с последними версиями обеих service mesh. Как показывают результаты, Linkerd не только по-прежнему заметно быстрее Istio, но и использует на порядок меньше ресурсов памяти и процессора в плоскости данных (data plane). Причем это происходит, даже если число запросов в секунду в три с лишним раза больше, чем в бенчмарке Kinvolk. Вы легко можете это повторить.
А теперь подробности.
Контекст
В 2019 году Kinvolk опубликовали цифры бенчмаркинга Linkerd и Istio. Это дало два результата. Во-первых, появился опенсорс-инструмент сравнения service mesh, с которым любой может воспроизвести бенчмаркинг. Прелесть этого инструмента в том, что он воспроизводит реальные сценарии: стабильный поток трафика проходит через простое приложение на микросервисах, используются вызовы gRPC и HTTP, измеряются затраченные ресурсы памяти и процессора, а также задержка при использовании service mesh. Задержка, что важно, измеряется с точки зрения клиента, а не внутренних процессов.
Во-вторых, Kinvolk представили результаты бенчмарка Linkerd и Istio на 2019 год. Цифры показали, что Linkerd куда быстрее и потребляет значительно меньше ресурсов, кроме одной сферы — плоскость данных (data plane) Linkerd (т. е. прокси) потребляла больше процессорных ресурсов, чем Istio, при очень высокой нагрузке.
Спустя два года и много новых релизов с обеих сторон мы решили повторить этот эксперимент.
Подготовка
Мы использовали инструмент бенчмаркинга от Kinvolk и последние стабильные релизы обоих проектов: Linkerd 2.10.2 (установка по умолчанию) и 1.10.0 (в минимальной конфигурации). Мы запустили последнюю версию инструмента бенчмаркинга на кластере Kubernetes v1.19 с дистрибутивом Lokomotive Kubernetes и использовали bare-metal оборудование, любезно предоставляемое Equinix Metal для проектов CNCF.
Первым делом мы принялись искать тестовую среду на Equinix Metal, которая обеспечивала бы стабильные результаты для каждого прогона. Это оказалось непросто: многие среды давали большую разницу в задержках, даже без service mesh (например, в одной из сред мы получали максимальную задержку от 26 до 159 мс для 200 запросов в секунду без service mesh!).
Наконец, мы нашли кластер в дата-центре Equinix Metal dfw2, который давал меньше расхождений. Кластер состоял из шести рабочих нод с конфигурацией s3.xlarge.x86 (Intel Xeon 4214 с 24 физическими ядрами, 2,2 ГГц и 192 ГБ ОЗУ), на которых мы запустили приложение. Еще одна нода с такой же конфигурацией генерировала нагрузку. Плюс там была мастер-нода Kubernetes с конфигурацией c2.medium.x86 config.
Затем мы стали настраивать параметры инструмента. Kinvolk оценивали производительность на 500 запросов в секунду (requests per second, RPS) и 600 RPS. Мы расширили диапазон и взяли 20 RPS, 200 RPS и 2000 RPS. На каждом уровне мы сделали шесть независимых прогонов со стабильной нагрузкой по 10 минут для Linkerd, Istio и конфигурации без service mesh. Все ресурсы бенчмарка и mesh мы переустанавливали между прогонами. Для каждого уровня мы отбрасывали прогон с максимальной задержкой, так что всего у нас оставалось пять значений. Если хотите, можете изучить наши необработанные данные.
Фреймворк Kinvolk измеряет поведение service mesh специфически:
- Он оценивает наивысшее потребление памяти для плоскостей управления и данных (control plane и data plane). То есть максимальное потребление памяти в плоскости управления (control plane) (в целом, со всеми компонентами) в любой момент прогона будет считаться значением для этого прогона.
- Точно так же происходит и с памятью для прокси плоскости данных (data plane).
- Для процессорных ресурсов значение рассчитывается так же, причем в качестве метрики используется процессорное время.
- Задержка измеряется с точки зрения клиента (генератора нагрузки) и включает время в сети кластера, время в приложении, время в прокси и т. д. Задержка выражается как перцентиль распределения — p50 (медианный), p99, p999 (99,9%) и т. д.
(См. раздел Итоги ниже.)
Цифры зависят как от самой service mesh, так и от инструмента и его среды. То есть это не абсолютные, а относительные значения, которые можно сравнивать, только если они получены одинаковым методом в одной и той же среде. Примечание автора: утверждения о том, что медианная задержка Linkerd была на X мс больше, чем у базовой конфигурации, не означают, что Linkerd увеличит медианную задержку на X мс в вашем приложении. Кроме того, это не означает, что отдельный прокси Linkerd увеличит задержку на X мс (медианная задержка отдельного прокси Linkerd составляет менее миллисекунды для большинства типов трафика).
Какие фичи service mesh мы тестировали
У service mesh много фич, но в наших экспериментах мы использовали только некоторые из них:
- У обеих service mesh был включен mTLS, трафик был зашифрован, а аутентификация выполнялась между всеми подами приложения.
- Обе service mesh отслеживали метрики, в том числе на L7, хотя мы не использовали эти метрики в нашем эксперименте.
- Обе service mesh логировали разные сообщения на уровне INFO по умолчанию. Логирование мы не настраивали.
- Обе service mesh могли добавлять повторные попытки и таймауты и перераспределять трафик разными способами, но мы не использовали эти фичи явным образом.
- Распределенную трассировку, взаимодействие между кластерами и другие функции в стиле mesh мы не включали.
Результаты
Результаты наших экспериментов показаны на графиках ниже. Каждая точка — это среднее значение за пять прогонов. «Усы» показывают одно стандартное отклонение от этого среднего. Голубой столбец — это Linkerd, оранжевый — Istio, желтый — конфигурация без service mesh.
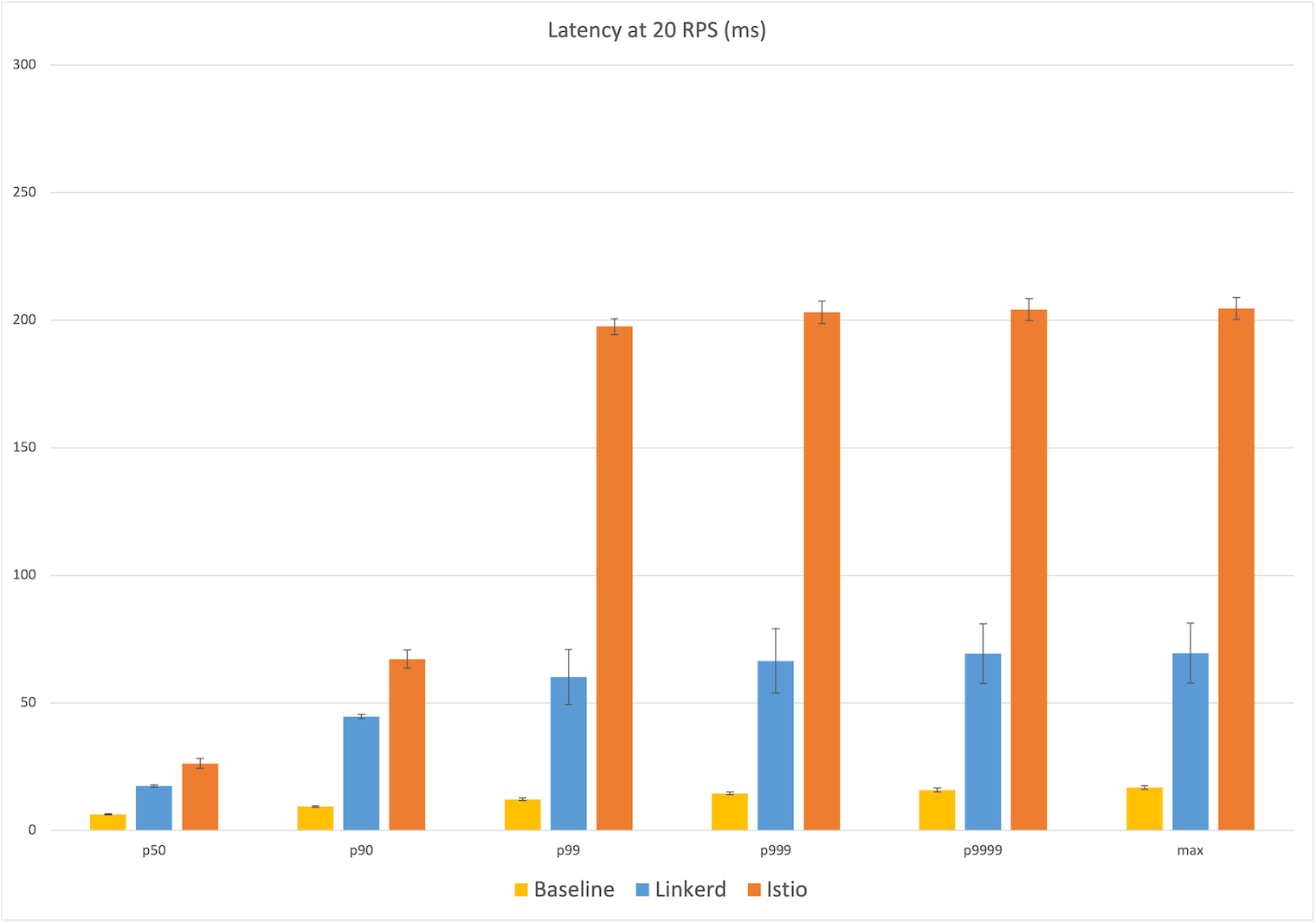
Задержка при 20 RPS
Мы начали с малого — 20 RPS, но даже здесь видна большая разница между задержками для пользователя. Медианная задержка у Linkerd — 17 мс, что на 11 мс больше, чем у базовой конфигурации (6 мс). У Istio медианная задержка — 26 мс, то есть дополнительная почти в два раза больше, чем у Linkerd. Максимальная дополнительные задержка у Linkerd — 53 мс от базовой конфигурации (17 мс), а у Istio — 188 мс, то есть в три с лишним раза больше, чем у Linkerd.
Если смотреть в перцентилях, у Istio столбик резко взлетает вверх на p99, почти до 200 мс, а у Linkerd повышение более плавное, до 70 мс. (Не забывайте, что задержка измеряется с точки зрения клиента, то есть мы видим, как это воспринимается пользователем приложения.)
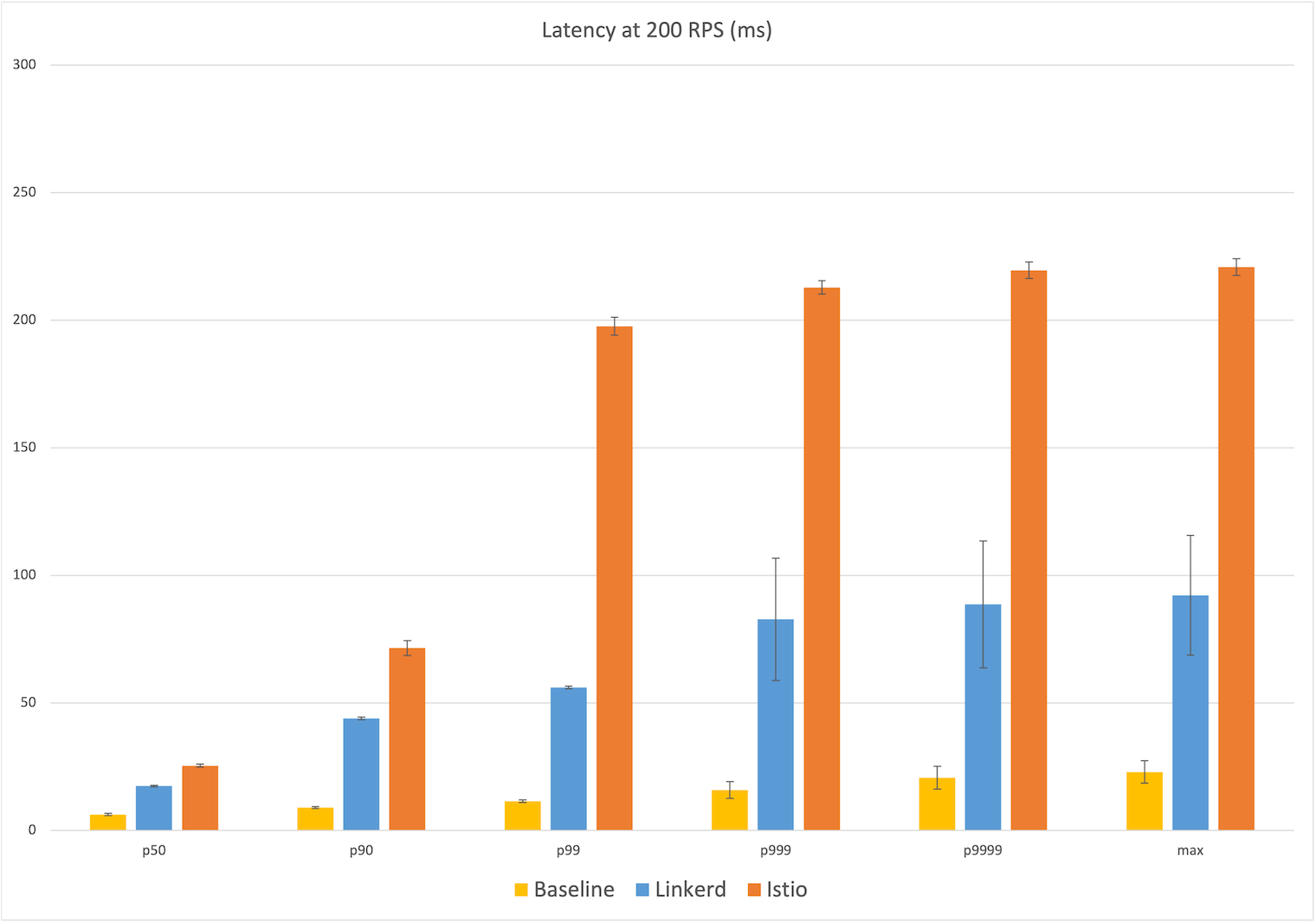
Задержка при 200 RPS
При 200 RPS мы видим похожий рисунок, и медианные задержки почти такие же: у Linkerd 17 мс и снова на 11 мс больше, чем у базы, а у Istio — 25 мс, то есть на 19 мс больше. На максимуме задержка у Istio составляет 221 мс, почти на 200 мс больше, чем у базовой конфигурации (23 мс), а у Linkerd — 92 мс в абсолютном выражении и 70 мс по сравнению с базой — в 2,5 раза меньше, чем у Istio. И снова на p99 задержка Istio резко увеличивается почти до 200 мс, тогда как у Linkerd — всего до 90 мс.
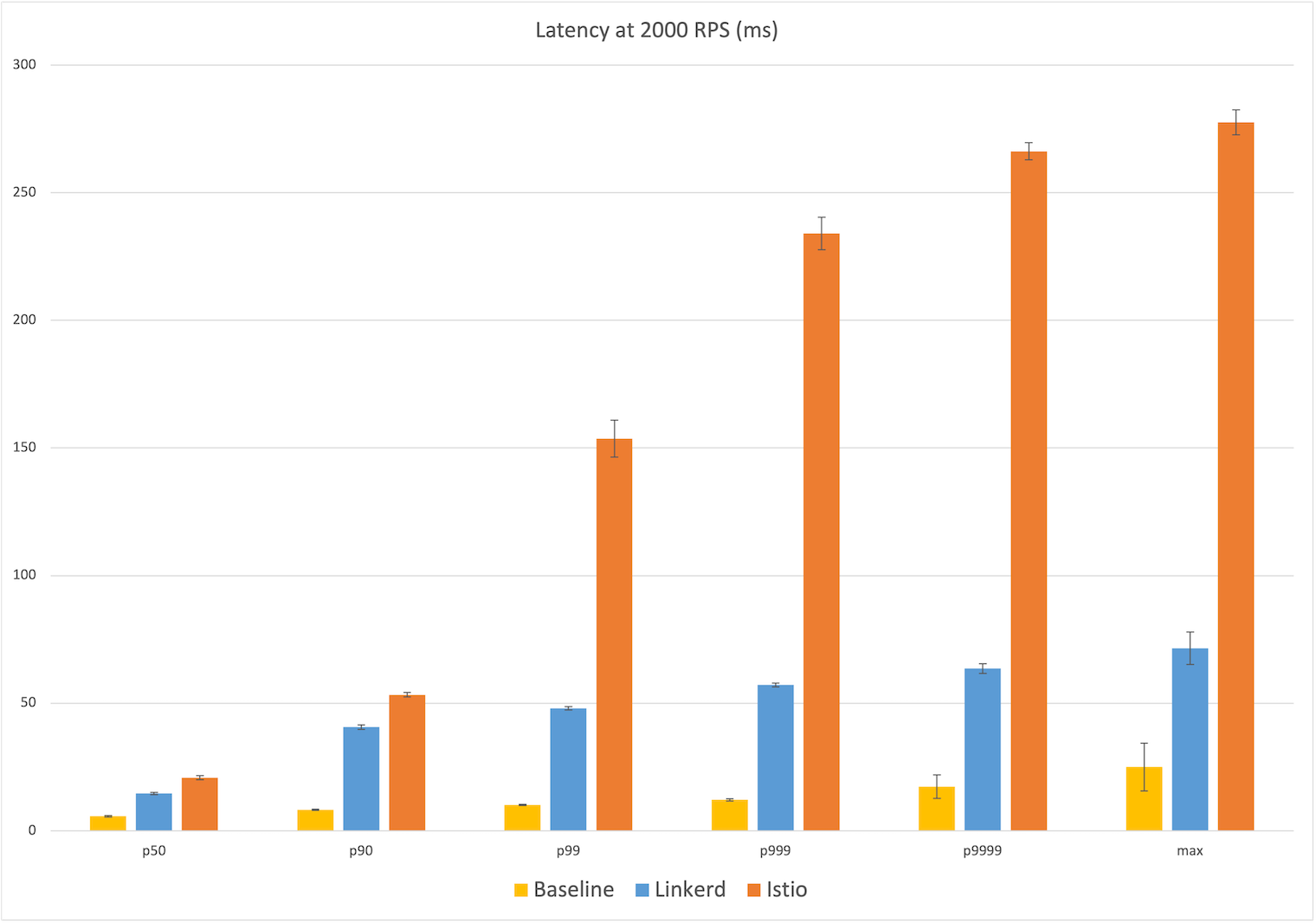
Задержка при 2000 RPS
Наконец, при 2000 RPS (это почти в три раза больше, чем было у Kinvolk) расклады примерно такие же — медианная задержка у Linkerd на 9 мс больше, чем у базовой конфигурации (6 мс), а у Istio — на 15 мс. На максимуме у Linkerd на 47 мс больше по сравнению с базовой конфигурацией (25 мс), а у Istio это значение больше почти в пять раз — 253 мс. В целом, на каждом перцентиле задержка у Istio было на 40–400% больше, чем у Linkerd.
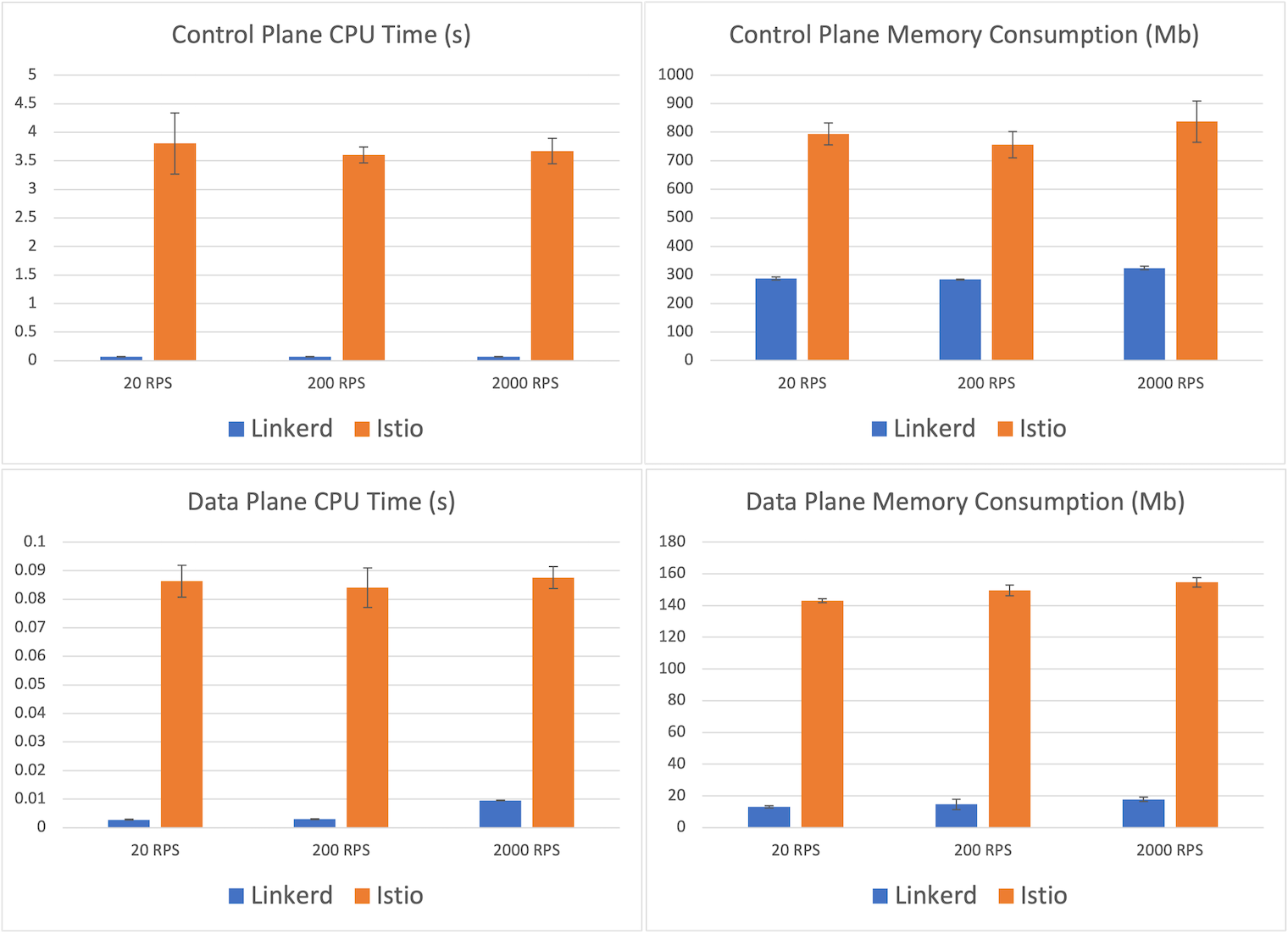
Потребление ресурсов
Теперь посмотрим на потребление ресурсов. Потребление памяти и процессорных ресурсов для обеих service mesh показано на графиках ниже. Цифры почти не зависят от числа запросов в секунду, так что мы подробно рассмотрим сценарий с наивысшей нагрузкой — 2000 RPS.
На плоскости управления (control plane) мы видим, что Istio потребляет, в среднем, 837 МБ памяти, почти в 2,5 раза больше, чем 324 МБ у Linkerd. Разница в потреблении процессорных ресурсов на плоскости управления (control plane) еще больше впечатляет — 71 мс у Linkerd против 3,7 с у Istio.
Но нас больше интересуют цифры для плоскости данных (data plane). Это как раз та часть mesh, которая должна масштабироваться вместе с приложением. Здесь отличие очень заметно: в среднем, максимальное потребление памяти у Linkerd — 17,8 МБ, а у прокси Istio Envoy — в восемь раз больше, 154,6. Максимальное процессорное время у Linkerd —10 мс, а у Istio почти на порядок больше — 88.
Итоги
Бенчмарки, имитирующие реальные сценарии, показывают, что Linkerd заметно превосходит Istio и потребляет в несколько раз меньше ресурсов на плоскости данных (data plane). При максимальном числе запросов в секунду Linkerd потребляет только девятую часть памяти и восьмую часть процессорного времени на плоскости данных (data plane) по сравнению с Istio, при этом медианная задержка всего на 75% больше по сравнению с базовой конфигурацией и составляет меньше одной пятой от дополнительной задержки, которую дает Istio.
Бенчмаркинг — это искусство. В этих экспериментах мы сознательно повторили то, что сделали Kinvolk, но в будущем хотим кое-что изменить. Например:
- Измерять общее, а не максимальное потребление ресурсов, чтобы лучше показать настоящие затраты.
- Измерять процессорные ресурсы в ядрах, а не во времени, чтобы это было больше похоже на способ измерения памяти.
- Рассчитывать перцентили задержки для всех данных за все прогоны, а не брать среднее значение для отдельных прогонов, чтобы получить более точные цифры.
Наши эксперименты были куда проще, чем у Kinvolk в 2019 году. У них было 30 минут стабильного трафика, разные кластеры, разные дата-центры и другие методы, чтобы учитывать разницу в оборудовании или сетях. Мы, со своей стороны, постарались сначала найти среду с минимальными расхождениями.
Почему Linkerd настолько быстрее и легче?
Такая разница в производительности и потреблении ресурсов между Linkerd и Istio, в основном, объясняется микропрокси на базе Rust, Linkerd2-proxy. Микропрокси лежит в основе плоскости данных (data plane) у Linkerd, и бенчмарки во многом отражают его производительность и потребление ресурсов.
Мы много писали о Linkerd2-proxy и причинах нашей любви к Rust еще в 2018 году. Любопытный факт: Linkerd2-proxy был разработан не для производительности, а по операционным соображениям. Чтобы использовать service mesh на базе Envoy, вроде Istio, нужно стать экспертом по Envoy. Мы решили не мучить этим пользователей Linkerd. Примечание автора: пожалуй, прокси — это самая интересная часть service mesh в техническом плане, но пользователей она интересует меньше всего. Мы считаем, что прокси service mesh должен быть незначительной частью реализации. Мы прилагаем все усилия, чтобы большинству пользователей Linkerd почти не пришлось что-то узнавать про Linkerd2-proxy .
По счастливой случайности Linkerd2-proxy дал большой выигрыш в производительности и эффективности. Он был задуман исключительно как sidecar-прокси service mesh, так что оказался невероятно эффективным на плоскости данных (data plane). Выбрав Rust, мы получили заодно все преимущества его экосистемы: при создании библиотек, вроде Tokio, Hyper и Tower, используются лучшие принципы проектирования и системного подхода.
Linkerd2-proxy — это не только невероятно быстрый, легкий и безопасный прокси. Он представляет одну из самых современных технологий во всем CNCF.
Планы на будущее
Как ни странно, несмотря на отличные результаты Linkerd в этих бенчмарках, мы еще не занимались всерьез производительностью прокси. Работая в этом направлении, мы собираемся еще больше улучшить показатели.
Мы внимательно наблюдаем за проектом SMP, который может представить стандарты бенчмаркинга. В идеале бенчмаркингом будут заниматься независимые третьи лица. Что приводит нас к следующей теме:
Как воспроизвести эти эксперименты
Чтобы самостоятельно воспроизвести эти эксперименты, следуйте инструкциям по бенчмаркингу.
Руководствуйтесь нашими комментариями о методологии. Обязательно найдите среду, которая дает стабильные результаты, особенно если вы хотите оценить максимальную задержку. Это значение во многом зависит от сетевого трафика, состязания за ресурсы и т. д. Помните, что вы получите относительные, а не абсолютные цифры.
Расскажите нам, что у вас получилось.
Благодарность
Выражаем особую благодарность ребятам из Equinix за предоставление среды Kubernetes; фонду CNCF, благодаря которому проект Linkerd смог провести эти эксперименты; и ребятам из Kinvolk, особенно Тило Фромму (Thilo Fromm) за отличный инструмент бенчмаркинга.
Linkerd для всех
Linkerd — это проект сообщества в Cloud Native Computing Foundation. Linkerd поддерживает открытое управление. Если у вас есть просьбы, вопросы или комментарии, присоединяйтесь к нашему быстро растущему сообществу! Linkerd размещается на GitHub. У нас есть обширные сообщества в Slack, Twitter и mailing list.
