Смогут ли ИИ-модели Open Source обойти Google и OpenAI
Недавняя утечка внутренних документов Google вызвала всплеск интереса в ИТ-сообществе. Суть в том, что ИИ с открытым исходным кодом составит серьезную конкуренцию Google и OpenAI. Довольно тревожный сигнал для техногигантов, и мы в статье рассуждаем на эту тему.

Что говорится в документе
Пока Google и OpenAI пытались обогнать друг друга в гонке ИИ, на арену вышел третий неожиданный участник — разработки Open Source.
»Хотя наши модели все еще имеют небольшое преимущество в качестве, разрыв уменьшается удивительно быстро. Модели с открытым исходным кодом работают быстрее, их легче настраивать, они более конфиденциальны и весомее с точки зрения возможностей. Они делают с помощью 100 долларов и 13 миллиардов параметров то, с чем мы мучаемся, имея 10 миллионов долларов и 540 миллиардов параметров. И делают это за недели, а не месяцы», — говорится в документе.
Как все вышло из-под контроля
Все началось в начале марта 2023 года с утечки исходников LLaMA от Meta (признана экстремистской организацией и запрещена в России). ИТ-энтузиасты получили в свои руки базовую модель. Конечно, в той версии отсутствовали настройки инструкций и разговоров, а также обучение с подкреплением на основе отзывов людей (RLHF). Но и этого было достаточно для всплеска инноваций.
Да, согласно лицензии, использовать модель для коммерческих целей запрещено, но зато каждый желающий теперь мог экспериментировать: настраивать модель под конкретные задачи. И на это нужно было всего несколько сотен долларов. Но что еще более интересное, так это то, что обновления низкого ранга можно легко распространять отдельно от исходных весов, что делает их независимыми от оригинальной лицензии от Meta, то есть каждый может ими поделиться.
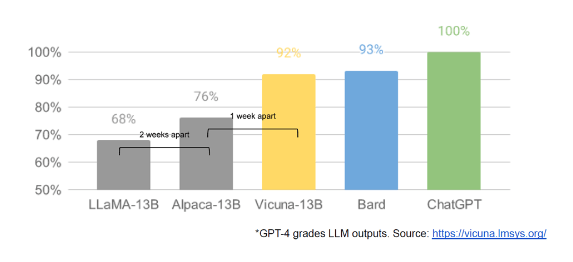
В документе представлена хронология:
- 24 февраля 2023 года — запуск LLaMA;
- 3 марта 2023 года — утечка LLaMA в общественное пространство;
- 13 марта 2023 года — выход Alpaca, который добавляет настройку инструкций в LLaMA, а также репозиторий alpaca-lora от Эрика Ванга, который использовал тонкую настройку низкого ранга для обучения модели в течение всего нескольких часов;
- 19 марта 2023 года — выпуск Vicuna, чат-бота с открытым исходным кодом, который был настроен с использованием около 70 000 общих разговоров пользователей, полученных с ShareGPT.com через общедоступные API (а стоимость обучения всего 300 долларов);
- 25 марта 2023 года — создан GPT4All, тоже чат-бот, но в отличие от Alpaca, которую дотренировали всего на 54 тыс. примерах из ChatGPT, эту модель тренировали на 437 тыс. примерах. За основу взяли все ту же LLaMA;
- 28 марта 2023 года — открытый исходный код GPT-3. Cerebras обучил архитектуру GPT-3. Появляются модели, которые обучены с нуля. А это означает, что ИТ-сообщество больше не зависит от LLaMA;
- 28 марта 2023 года — LLaMA-Adapter ввел мультимодальное обучение за один час;
- 3 апреля 2023 года — Университет Беркли запустил Koala, диалоговую модель, обученную полностью на свободно доступных данных, а люди не могут отличить открытую модель на 13 млрд параметров от ChatGPT. Стоимость обучения — 100 долларов;
- 15 апреля 2023 года — Open Assistant запустил модель и набор данных через обучение с подкреплением на основе отзывов. Их модель близка (48,3% против 51,7%) к ChatGPT с точки зрения предпочтений людей. Набор данных общедоступен, поэтому обучение с подкреплением на основе отзывов теперь становится доступным и простым для экспериментаторов.
Так есть ли конкуренция между моделями Open Source и версиями от техногигантов
Мы видим, что модели, настроенные буквально за вечер на ноутбуке средней мощности или планшете, принципиально не отличаются по функционалу от тех, что стоят десятки миллионов долларов и имеют по пол-триллиона параметров.
В чем преимущества ИИ-моделей Open Source:
- бесплатные;
- в открытом доступе и без ограничений;
- сопоставимы по качеству с моделями от крупных компаний.
С другой стороны, есть весомый аргумент в пользу того, что все эти модели на основе LLaMA и GPT-3 не смогут конкурировать с Google и OpenAI. Речь идет про инвестиции. Когда они станут системными в этой области и для разработчиков Open Source, только тогда можно вернуться к вопросу о конкуренции, а пока это чистый энтузиазм.
Но в чем проблема ИИ-разработок от Google и OpenAI? Большие модели замедляют развитие сферы, как считают в письме. В долгосрочной перспективе лучшими моделями являются те, над которыми можно быстро работать.
Выводы
Документ крайне точно передает стремительность развития ИИ. Утечка исходников LLaMA сродни тому, как выпустили джина из бутылки. OpenAI все еще оценивается в 29 миллиардов долларов, но с коммерческой точки зрения проект может превратиться в тыкву, так как его потеснят Open Source-разработки. В природе организм, который имеет доступ ко всем возможным патогенам, куда более устойчив, чем тот, что обитает в стерильных условиях. Это можно сказать и про ИИ-инструменты.
Полный текст статьи читайте на Компьютерра
